May 2021
Beginner to intermediate
333 pages
8h 45m
English
As we’ve mentioned several times in this book, large language models have had a big impact on the field of NLP, and current trends suggest that this isn’t going to stop any time soon, as Figure A-1 suggests.
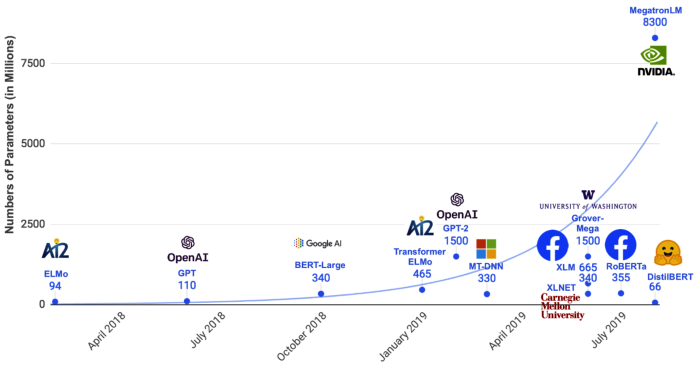
The great thing about this, even if you’re not particularly enthusiastic about training a large model yourself, is that most researchers are generally interested in open sourcing their code and releasing the trained model weights as well. Better language models trained on larger datasets for longer means that you, the developer building NLP applications, has a stronger baseline to work off of. It’s almost like a free performance boost!1
Because of this rapid progress and general interest in open sourcing the best models, we generally wouldn’t recommend training your own large language model from scratch. It is often counterproductive when many researchers have spents years of GPU time optimizing a specific language model on an existing large dataset. Our very first lesson in Chapter 2 was that being prudent with fine-tuning can reap huge rewards. In practice, you always want to use transfer learning wherever you can.
However, if you do have the luxury of being able to access large amounts of compute, there are some things you should know about scaling your model training to ensure optimal performance.
Read now
Unlock full access






