November 2024
Intermediate to advanced
400 pages
11h 12m
French
Dans les chapitres précédents, tu as appris à utiliser des API structurées pour traiter des volumes de données très importants mais finis. Cependant, les données arrivent souvent en continu et doivent être traitées en temps réel. Dans ce chapitre, nous verrons comment les mêmes API structurées peuvent être utilisées pour traiter des flux de données.
Le traitement de flux se définit comme le traitement continu de flux de données sans fin. Avec l'avènement du big data, les systèmes de traitement de flux sont passés de moteurs de traitement à un seul nœud à des moteurs de traitement distribués à plusieurs nœuds. Traditionnellement, le traitement de flux distribué a été mis en œuvre avec un modèle de traitement enregistrement par enregistrement, comme illustré à la figure 8-1.
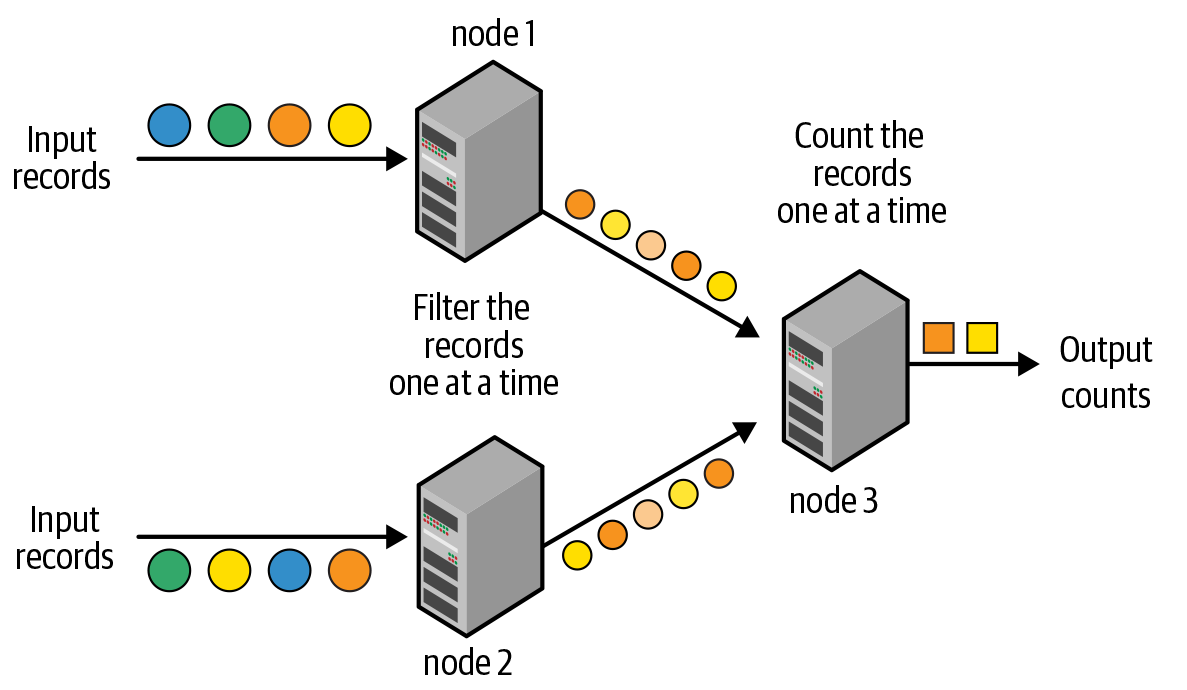
Le pipeline de traitement est composé d'un graphe dirigé de nœuds, comme le montre la figure 8-1; chaque nœud reçoit continuellement un enregistrement à la fois, le traite, puis transmet le(s) enregistrement(s) généré(s) au nœud suivant dans le graphe. Ce modèle de traitement permet d'obtenir des temps de latence très faibles, ...
Read now
Unlock full access






