Chapter 4. Amanda
The purpose of this chapter is to give a brief technical overview of Amanda. We want you to understand how Amanda works, how it is different from other backup software, and how it can help you solve your data protection requirements. On the other hand, we don’t want to overwhelm you with technical details that could be very specific to a particular setup or backup policy. Throughout this chapter, we provide links to the web sites where you can find up-to-date and easy to follow instructions and details about everything you need to know about deploying Amanda in production.
Tip
This chapter was contributed by Dmitri Joukovski and Stefan G. Weichinger.[1] Dmitri has been solving backup and recovery challenges since the early ’90s and he lives in Silicon Valley, California with his beautiful wife and children. Stefan loves to work in a collaborative environment and continues his quest to find one.
Amanda, the Advanced Maryland Automated Network Disk Archiver, is the most well-known open-source backup software. Amanda was initially developed at the University of Maryland in 1991 with the goal of protecting files on a large number of client workstations with a single backup server. James da Silva was one of its original developers.
The Amanda project was registered on SourceForge.net in 1999. Jean-Louis Martineau of the University of Montreal has been the gatekeeper and leader of Amanda development in recent years. Over the years more than 250 developers have contributed to the Amanda codebase, and thousands of users provided testing and feedback, resulting in a stable and robust package. Amanda is included with every major Linux distribution. As of April 2006, more than 20,000 sites worldwide use Amanda.
Originally, Amanda was used in production mostly by universities, technical labs, and research departments. Today with wide adoption of Linux in IT at large, Amanda is found in many other places, especially where the focus is on applications deployed on a LAMP[2] stack. Over the years, Amanda has received multiple awards from users. For example, in 2005 it received the Linux Journal Readers’ Choice Award for favorite backup system.
Amanda allows you to set up a single master backup server to back up multiple Linux, Unix, Mac OS X, and Windows hosts to a very large selection of tape, disk, and optical devices including tape libraries, autochangers, optical jukeboxes, RAID arrays, NAS devices, and many others. Figure 4-1 shows a typical Amanda network.

Here are a few real-life examples of Amanda in production. One company uses three Amanda servers on CentOS in three countries to protect more than 30 clients on Solaris, Linux, and Windows. Different versions of Amanda have been in production for 9 years as of this writing. The total amount of protected data is more than 500 GB and data grows at 8 GB per week on average. One of the sites performs backup to disk only, and the other two back up to both disk and LTO autoloaders. System administrators recover files at least once per week because of users erasing files by accident. A few times over the years, the company lost servers because of failed hard drives, and Amanda came to the rescue for bare-metal recovery.
A major university in the United Kingdom has two Amanda servers on Fedora Core with more than 100 Linux (Fedora Core, Red Hat Enterprise Linux), Mac OS X, and Solaris clients with more that 2 TB of data. One of the Amanda servers is dedicated to backup of SAP and Oracle on Solaris.
A cinematographic post-production company has three Debian Amanda servers at two sites protecting 84 Linux and IRIX clients with 26 TB of data. It recovers files about twice per week due to user error. In three years of production, it had three instances of total volume loss despite using RAID arrays, and Amanda was able to recover all three lost volumes.
Throughout this chapter, we use examples of real-life Amanda implementations. Based on feedback from many Amanda users with a variety of configurations and different levels of Amanda expertise, we believe that the key reasons for wide adoption of Amanda are:
Amanda simplifies your life as a system administrator because you can easily set up a single server to back up multiple networked clients to a tape, disk, or optical storage system.
Amanda is optimized for backup to disk and tape. Additionally, it enables you to write backups to tape and disk simultaneously. The very same data can be available online for quick restores from disk and off-site for disaster recovery and long-term retention.
Since Amanda does not use proprietary device drivers, any device supported by an operating system works well with Amanda. The system administrator does not have to worry about breaking support for a device when upgrading Amanda.
Amanda uses standard utilities such as dump and GNU
tar. Since these are not proprietary formats, data can
be recovered with readily available standard tools—even without Amanda.
Amanda’s unique scheduler optimizes backup levels for different clients in such a way that total backup time is about the same for every backup run. Amanda frees the system administrators from having to guess the rate of data change in their environments.
The Amanda project has attracted a large and active community that grows every day.
The total cost of ownership (TCO) for a backup solution based on Amanda is significantly lower than the TCO of any solution that uses proprietary backup software.
Amanda software has a source-code tarball and RPMs for most common versions of Linux, and is available from http://www.zmanda.com. Additionally, source code is available from SourceForge.net at http://sourceforge.net/projects/amanda. Some older (but stable) versions of Amanda are packaged with all common Linux distributions, including Fedora Core, Red Hat Enterprise Server, Debian, Ubuntu, OpenSUSE, and SUSE Linux Enterprise Server, including releases for Itanium, IBM p-Series and even IBM S/390 and z-Series mainframes.
Amanda documentation including a quick-start guide and FAQ, written by users for users, is available on the Amanda wiki at http://wiki.zmanda.com.
Summary of Important Features
Let’s start with a brief overview of Amanda’s architecture. This will help you understand the most important concepts in Amanda functionality.
Client/Server Architecture Using Nonproprietary Tools
Amanda is designed to handle large numbers of clients and data, yet is reasonably simple to install and maintain. As a matter of fact, it takes more time to order a pizza than to configure an Amanda server with two Linux clients and one Windows client and to start a test backup. A white paper available at http://amanda.zmanda.com/quick-backup-setup.html provides detailed information about configuring Amanda backup in less than 15 minutes.
Amanda scales well up and down, so small configurations—even a single client—are possible. Many users back up just a single client that is also the Amanda server. On the other hand, many Amanda users back up hundreds and even thousands of filesystems (there could be multiple filesystems per protected system) to a large tape library with multiple drives.
The Amanda code is written in C (with some Perl and shell scripts), and the code is portable to any flavor of Linux and Unix including Mac OS X. Windows clients can be backed up today via Samba or via a Cygwin client, which is a Linux-like environment for Windows. The Amanda community is actively working on providing a native client for Windows. The new Windows client will take advantage of Microsoft technologies such as Volume Shadow Copy Service (VSS) that provide snapshots of a system’s volumes, including snapshots of open files.
The biggest advantage of Amanda over
any other backup software is that Amanda does not use any proprietary data formats. It
uses standard operating system utilities such as dump
and tar, or open-source utilities available in many
operating systems such as GNU tar, smbtar, and Schily tar,
and uses the same archive format on the media. Depending on which one is the best match
for your filesystems, directories, and files, you can mix and match these utilities as
you wish. Since you use standard utilities, you can be confident that they will always
be available to you. Another advantage of using standard utilities is that in case of
disaster recovery or any other emergency, you can recover your data even without Amanda.
(We explain how to recover data without Amanda when we discuss Amanda restores.)
Because Amanda uses standard utilities, it provides the following:
Backup of sparse files
Backup of hard links
No changing of file timestamp during backup
Exclusions of files and directories
From the system-administrator perspective, it is very important that Amanda does not
use any proprietary device drivers. Any device supported by an operating system works
well with Amanda. In practical terms, this means that Amanda supports a wide range of
tape storage devices, and new devices are usually not difficult to add. Many tape
changers, stackers, jukeboxes, and tape libraries are supported by using special tape
changer scripts to provide truly hands-off and lights-out backup. Basically, if you can
read and write to your tape drive and move tapes in your tape library with standard
operating system commands such as mt, Amanda will
work with your tape library. Because Amanda doesn’t use proprietary device drivers,
another benefit is that you don’t have to worry about breaking support for a device when
upgrading to the latest version of Amanda.
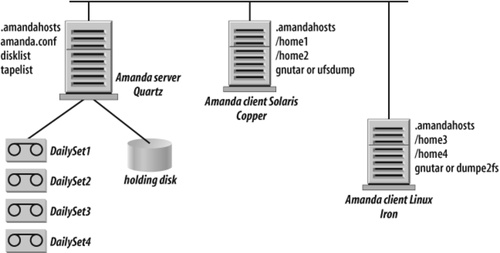
To understand Amanda architecture and inner workings, let’s take a look at a simplified Amanda configuration and review an example of a backup cycle, illustrated in Figure 4-2.

To simplify our discussion, let’s assume that we have only two Amanda clients that run on two workstations: workstation Copper running Solaris and workstation Iron running Linux. Each workstation has two filesystems with users’ data that we want to protect. Amanda server Quartz is installed on a different Linux host and, for simplicity’s sake, we don’t back up the Amanda server itself. (In your production and evaluation environments, you should always back up the Amanda server.) Let’s also assume that we want to run a full backup once every four days and incremental backups between full backups.
Amanda is designed as a traditional client/server architecture. The Amanda server, also historically known as the tape host, is connected either directly or over the Storage Area Network to a tape drive or tape changer. Each client backup program is instructed to write to standard output, which Amanda collects and transmits to the tape server. The client/server architecture provides these benefits:
It ensures scalability of Amanda from environments with a single client and CD-ROM to environments with hundreds of clients and large tape libraries with multiple tape drives and hundreds of tapes.
It allows all configurations to be done on the Amanda server. Once the initial configuration of Amanda is done, you can easily add clients without worrying about breaking your tested backup procedures.
It allows some CPU-intensive operations such as compression or encryption to be done on a client before sending backup images to the Amanda server. However, in some situations, for example when Amanda clients are running within virtual machines, these CPU-intensive operations can also be done on the Amanda server.
Considering the ever-increasing importance of security for backup data from a privacy and compliance perspective, let’s go over a brief overview of Amanda security.
Amanda Security
Amanda clients communicate with the Amanda server via its own network protocols on
top of TCP and UDP. Amanda’s client/server communications do not suffer from the
security holes
inherent in the traditional rmt approach used by
dump, such as using an .rhosts file in root’s home directory.
As in every other client/server setup, you should ensure that only your own and trusted Amanda server is able to communicate with Amanda clients. Amanda achieves that by using the file .amandahosts. You can see that in Figure 4-2, there are three .amandahosts files, one on the Amanda server Quartz and one for each Amanda client. On the client side, you have to add the name of the Amanda server (or Amanda servers if you prefer the same host to be protected by multiple Amanda servers) and the Amanda user that is allowed to back up the client. For example, the . amandahosts file for Linux client Iron in Figure 4-2 should have the following entry:
quartz.zmanda.com amandabackup
That tells the Amanda client Iron to let Amanda server Quartz communicate with user amandabackup.
During restores, you need access to an Amanda server. For the configuration presented in Figure 4-2, the .amandahosts file on the tape server Quartz should have the following entries:
iron.zmanda.com root copper.zmanda.com root
These entries tell the Amanda server to allow the root user on each client to run restores. For security reasons, Amanda was designed to allow only the root user to restore data.
For stronger data transport security, Amanda can also use OpenSSH. This allows Amanda to protect the transfer of data between clients and backup servers with strong authentication and authorization mechanisms. Amanda also features an abstracted secure communication API that enables developers to easily add different communication plug-ins between backup server and client. Even with a single backup server, Amanda can use different communication mechanisms for different clients.
To protect data on the backup media itself, Amanda provides the ability to encrypt
backup data with symmetric or asymmetric encryption algorithms (using either aespipe or gpg).
Encryption is very expensive in terms of CPU utilization, which is why the Amanda
encryption can be done either on the server or the client. (Do it wherever you have more
CPU cycles available.) In addition to relieving the Amanda server CPU, client site
encryption also ensures security of data on a wire, which could be important for backing
up remote clients. Because of CPU constraints, you might choose to encrypt only certain
data. Amanda is flexible enough to configure data encryption for a single directory or
even for a single file. If aespipe and gpg don’t match your encryption requirements, Amanda will
work with your custom encryption utilities.
Warning
Amanda does not manage encryption keys. A system administrator should take care to safeguard the keys and make them available during restore.
Amanda works with Security-Enhanced Linux (SELinux), and it also works reasonably well with common types of firewalls between Amanda servers and clients as long as you select UDP and TCP port ranges during the initial setup. Please check installation and configuration details for firewall setup at http://wiki.zmanda.com.
To conclude this brief overview of Amanda security, we want to emphasize that the flexibility of the security configurations allows Amanda to fit well into the security policies and processes of most IT environments, including organizations with strict security requirements.
Holding Disk
You might recall that Amanda is actually an acronym, and D in Amanda stands for disk. To explain how Amanda moves data from the client to its final destination on tape or disk, you need to know the holding disk.
Figure 4-2 shows that the Amanda server Quartz has a holding disk attached. A holding disk is one or several directories on any filesystem that is accessible from the Amanda server. It could be as small as a single 10 GB directory on the Amanda server drive or as large as 5 to 10 TB on a fibre-attached RAID array. As the name suggests, the holding disk is used as a cache to store backup data from all Amanda clients. Each set of backup data from a client filesystem or a client directory is just a bunch of files on the holding disk. Later, an independent Amanda process flushes individual backup images from the holding disk to tape or virtual tape at the maximum throughput possible to keep the tape drive streaming. Using a holding disk as a staging area for backups has several benefits.
Modern tape drives are very fast. Even gigabit networks cannot feed backup data from a single client through the Amanda server to modern tape drives fast enough to avoid shoe-shining, which reduces throughput and shortens the life of both the media and the drive (see Chapter 9 for details on shoe-shining). The holding disk collects data from all clients and as soon as the first backup is complete, it starts feeding data to tape as fast as the Amanda server can push it. However, many users prefer to complete backups of all clients before they start flushing data to tape.
A holding disk can accept data streams from multiple clients in parallel to overcome the sequential nature of a tape. Instead of writing one backup to tape after another, you can configure multiple backups running in parallel and make full use of your available network bandwidth, thus reducing total backup time. If the network becomes your bottleneck for performance, you can reduce total backup time by adding another NIC to the backup server or dedicating a separate network for backups. The use of multiple holding disks can also improve overall backup performance.
Using a holding disk provides additional safety in case you have a bad or wrong tape—or no available tape at all. Your backup is complete even if you forget to insert a new tape before taking the day off. It also provides a backup when a media error occurs during a backup run or the backup media runs out of space.
Amanda supports different algorithms to move the data from the holding disk to the media. Of course, your chosen algorithm will impact the effective use of the tape.
Amanda supports multiple holding disks so that backup images from different clients can be sent to different holding disks. This increases the scalability of Amanda and provides better load balancing for I/O because holding disks can be on different controllers.
New Amanda users often ask how large the holding disk should be. In a typical “full and incrementals” backup cycle, most backups are small incrementals, so even a modest amount of holding disk space can provide better flow of backup images to a tape. A good rule of thumb is that there should be enough holding disk space for the two largest backup images at the same time, so that one image can be coming into the holding disk while the other is being written to tape. For example, if in Figure 4-2 the full backup of both filesystems for Copper is 50 GB and the full backup of both filesystems for Iron is 30 GB, the optimal capacity of holding disk on Quartz should be at least 80 GB. If that is not practical, any amount that holds at least a few of the smaller incremental backups is better than no holding disk at all. With today’s low disk prices, a good-sized holding disk is well worth the investment.
On the other hand, some Amanda users have significantly larger capacities for their holding disks. For example, a very large Japanese manufacturing company has four Amanda servers running on Solaris and BSD protecting more than a hundred Amanda clients on BSD, Windows, Linux, HP-UX, and Solaris running Oracle. One of its holding disks is on a RAID array with total capacity of 4 TB. Fast arrays and Amanda servers with high I/O allow streaming throughput from holding disk to tapes at approximately 120 Mb per second.
The flexibility of Amanda allows configurations without a holding disk, but then backups can be written to tape only sequentially instead of in parallel to the holding disk. Obviously, the lack of holding disk significantly reduces backup performance.
If the holding disk is for temporary storage of backup files, how does Amanda decide what to send to the holding disk in the first place? Let’s take a look at Amanda’s unique way of scheduling backups.
Backup Scheduling
Most backup products provide basically the same backup scheduling. The system administrator configures software to perform a full backup on Sunday, every other Sunday, or the last day of the month, with different levels of incrementals between full backups. The biggest problem with this approach is that it does not provide any load balancing. You have to make sure that enough resources are available to manage peak demand for backup server CPU, network, and I/O during full backups. Since you perform full backups only once in a while, your resources are underutilized most of the time. More often than anybody wants to admit, the system administrator finds out on Monday morning that Sunday’s full backup did not complete because there were not enough tapes available in a library. Other Mondays you might find that your full backups are still running, and users are calling you to kill all backups. Of course, you can figure out yourself how to achieve load balancing by instructing your backup software to distribute full backups among your clients throughout the week or month, but then you have to make sure that there are no changes in your environment; new clients break down your balancing schema.
Amanda’s unique approach to scheduling optimizes load balancing of backups and simplifies your life. Instead of giving Amanda the exact instruction “Do a full backup every Sunday for clients A, B, and C, full backups on Wednesday for clients D, E, and F, and incrementals all other times,” you just set up a few ground rules that control Amanda scheduling. For example, you might give Amanda the rule “Do at least one full backup within a 7-day period, and do incrementals all other days with a maximum time between full backups of 7 days.” The maximum time between full backups is called the dump cycle.
For any dump cycle you specify, Amanda finds an optimal combination of full and incremental backups from all clients to make the total amount of backup data per backup run as small as possible and consistent from one backup run to another. To find such a balance, Amanda uses the following considerations:
The total amount of data to be backed up as reported by each client based on the amount of data changed since last backup
The maximum time between full backups (dump cycle) you specified
The size of backup media (tape or disk) available for each backup run
To calculate the optimal backup level, Amanda starts every backup run with an estimate phase. Every Amanda client runs a special process to determine which files have changed and the total size of all changed files. The estimate phase can take some time, especially with many clients and filesystems. If some filesystems are not very dynamic and files don’t change much, you can tell Amanda that, thus saving time during the estimate phase. After collecting data from all clients, Amanda goes into the planning phase and calculates the optimal combination of full and incremental backups for all clients.
Figure 4-3 shows how Amanda schedules backups for the clients from Figure 4-2, assuming that each home directory is 100 GB, the data change rate is 15 percent, and the dump cycle is 4 days. For simplicity, let’s assume that Amanda writes each backup run to a new tape labeled DailySet1 through DailySet4 and that all incrementals are level 1 (level 0 is usually defined as a full backup), meaning everything that changed since the last full backup.

For each run, Amanda schedules a full backup for the total amount of data divided by the number of days in the dump cycle. Since the dump cycle is 4 days, for DailySet1, Amanda does the full backup for 1/4 of the data, in this case /home1. For DailySet2, Amanda does a full backup for another 1/4 of data, in this case /home2, and an incremental backup for /home1 which is 15 GB (15 percent of 100 GB). For DailySet3, Amanda does a full backup of /home3 and incrementals for /home1 and / home2. After the initial startup period of four days, Amanda runs a full backup for one of the /home directories and incremental backups for all the others. Let’s calculate the total amount of data on each DailySet tape (see Table 4-1).
| Directory | DailySet1 | DailySet2 | DailySet3 | DailySet4 | DailySet1 | DailySet2 | DailySet3 | DailySet4 |
| /home1 | 100.0 | 15.0 | 27.75 | 40.84 | 100.0 | 15.0 | 27.75 | 40.84 |
| /home2 | 100.0 | 15.0 | 27.75 | 40.84 | 100.0 | 15.0 | 27.75 | |
| /home3 | 100.0 | 15.0 | 27.75 | 40.84 | 100.0 | 15.0 | ||
| /home4 | 100.0 | 15.0 | 27.75 | 40.84 | 100.0 | |||
| Total | 100.0 | 115.0 | 142.75 | 183.59 | 183.59 | 183.59 | 183.59 | 183.59 |
It is trivial to calculate the total amount of data for DailySet1 and DailySet2. For the third backup run of /home1, we have to consider that 15 percent of data was backed up on DailySet2, which means 15 percent of 100 GB has changed again (see Figure 4-4).

To avoid double counting, we have to subtract the small overlap area from 30 GB. So for DailySet3, the size of the incremental for /home1 is 30 GB – (15 GB×15 percent) or 27.75 GB. Following the same logic, for DailySet4 the incremental for /home1 is not 45 GB. It’s 45 GB – (27.75 GB×15 percent) or 40.84 GB. This example is admittedly a mathematical oversimplification. In reality, Amanda uses all nine levels of incremental backups to optimize the total amount of data on tape.
In addition to a traditional schema with full backups and incrementals in between, Amanda also supports:
Periodic archival backup, such as taking full backups off-site
Incremental-only backups with full backups done outside of Amanda, such as very active areas that must be taken offline or no full backups at all for areas that can easily be recovered from vendor media (such as the installation CD for an operating system)
Always doing full backups of databases that change completely between each run or any other critical areas that are easier to deal with during an emergency if they are a single-restore operation
It’s easy to support multiple configurations on the same Amanda server, such as doing traditional full backups and incrementals on a weekly basis and also doing additional monthly full backups for off-site storage. Multiple configurations can run simultaneously on the same tape server if there are multiple tape drives.
When choosing the length of your dump cycle, remember that shorter dump cycles such as three to four days make restores easier because there are fewer incrementals, but they use more tape and require more time to back up. Longer dump cycles allow Amanda to spread the load better over multiple tapes but may require more steps during a restore. More information about how to choose a reasonably balanced dump cycle depending on amount of data, tape drive capacity, and so on is available at http://wiki.zmanda.com.
Now, let’s take a look at Amanda tape management.
Tape Management
Each tape
should be labeled before use with the command amlabel. There is a default template for labels, and you can define your own
label templates. Labeling prevents overwriting of tapes with valid backup images and
allows the Amanda server to keep track of all tapes that were labeled. Amanda starts a
new tape for each backup run (for example, each nightly backup) and does not provide a
mechanism to append a new run to the same tape as a previous run.
Based on your backup retention policy, Amanda keeps track of the expiration date for each labeled tape, and Amanda reuses that tape for new backups after it has expired. However, you can configure Amanda not to reuse specific tapes. You might choose to never expire some backup images and use Amanda for creating archives. (Amanda’s support for optical media is very useful for archiving.)
For backups of large amounts of data, Amanda supports using multiple tapes in a single backup run. For example, backups from clients A, B, and C can be written on one tape, and backups from clients E, F, and G can be written to another tape.
In the past, Amanda could not span multiple tapes for a single backup image and system administrators had to break large filesystems into smaller chunks, such as several directories. As of version 2.5, Amanda can span multiple tapes. The size of the backed-up images is no longer restricted to a single tape, and there is no need for the system administrator to artificially segment data into parts that can fit into a single tape.
Device Management
Amanda does not use any proprietary drivers for tape or optical devices. You have to make sure your tape devices are configured as nonrewinding devices (for example, /dev/nst0 and /dev/nst1). You also have to select the tapetype definition specific to your tape-drive technology. Many default tape definitions are provided with Amanda. Here is an example of tapetype definition for LTO-3:
define tapetype LTO3-400-HWC {
comment "LTO Ultrium 3 400/800, compression on"
length 401408 mbytes
filemark 0 kbytes
speed 74343 kps
}Note that Amanda does not use the length of the tape value. It tries to write to the tape until it gets an error.
You have to select a tape changer script for your tape changer. Examples of tape definitions for most commonly used tape drives and details about configuring tape drives and tape changer scripts are available at http://wiki.zmanda.com.
For a long time, Amanda has provided the ability to use disk as the target media for backup. Dedicated directories are used as virtual tapes called vtapes. You work with vtapes exactly the same way you work with real tapes. For example, you have to label vtapes before they can be used by Amanda. You might use vtapes and backup to disk as a way to test and evaluate Amanda before you decide to invest in an expensive tape library. Furthermore, backup to disk is now a viable option for production from a cost perspective. You get all the benefits of having a backup of your data without the challenges of managing finicky tape drives.
A most interesting scenario is the use of tapes and disk at the same time. Amanda provides a functionality called RAIT (Redundant Array of Inexpensive Tapes). Initially RAIT was designed to increase redundancy. This is the same technology as RAID, where data is striped over several disks. Amanda supports RAIT with two-, three-, and five-tape sets.
A three-drive RAIT set writes two data streams and one parity stream and gives you twice the capacity, twice the throughput, and the square of the failure rate (for example, a 1/100 failure rate becomes 1/10,000 because you lose data only if two tapes are faulty or not available). Similarly, a five-drive RAIT set gives you four times the capacity and four times the throughput. A two-drive RAIT set duplicates the output stream, and each output stream can have either the same or different media targets. If you have the same media targets (for example, two tape drives), you get exact copies of your backup data, called clones. You can keep one clone on-site for occasional restores and take another clone off-site for disaster recovery.
If you have different media targets, you can keep your backup data on disk for two to three weeks for occasional restores. For long-term retention, you have a copy on tape. Most restores happen within 10 days after a file has been lost, and the ability to restore data quickly from disk becomes very important.
Configuring Amanda
Now let’s take a look at how to configure Amanda backup. Detailed instructions about how to install and configure the Amanda client and server are available from http://wiki.zmanda.com. Here we provide a configuration roadmap. The preferred way to install Amanda is from RPMs found at http://www.zmanda.com, but if you want to compile from source, this section presents the basic procedures for installing the client and the server.
Tip
While one machine can be both a client and a server, there is no need to perform both procedures; installing the server normally installs the client.
To compile the Amanda client from source:
Create an amandabackup user in the disk group. This user must be the same as the backup user.
Unpack, compile, and install Amanda from the source archive. Specify configure options for a client-only compile, and install.
Add Amanda-related entries to /etc/services and the /etc/xinetd.d directory, and restart
xinetd.Specify which servers are allowed to connect by editing the .amandahosts file to enable authentication between client and server.
To install the Amanda server, you can also use RPMs. If you want to compile the server from source:
Create an amandabackup user in the disk group. The backup user should belong to the user group that has read and write access to the media.
Unpack, compile, and install from the source archive. Specify options for a client-and-server install.
Add Amanda-related entries to the /etc/xinetd.d directory, and restart
xinetd.
Once the server is installed, configure the Amanda server:
Create the Amanda configuration directory /etc/amanda/<config name> (in case you use Zmanda packages).
Copy a sample of amanda.conf into /etc/amanda/<config name>.
Create a disklist file in /etc/amanda/<config name>.
Edit the .amandahosts file to enable authentication between client and server.
Edit configuration files amanda.conf and disklist.
Add client configuration to the disklist file.
Set up the device (create device nodes or directories) if you are using virtual tapes.
Label the media (tapes or vtapes) using
amlabel.Configure a
cronjob to schedule Amanda backup runs.Run
amcheckto verify that there are no problems with configuration, client/server communications, the holding disk, or the tape.
Figure 4-5 shows the configuration files for our sample network.
The most important file for configuring Amanda setup is amanda.conf. The example file is quite large (more than 700 lines, which is why we don’t include an example here; see http://wiki.zmanda.com for details), but fairly self-explanatory. This file defines how you do your backups, using settings that include:
Local settings, such as name of your organization, email address to send backup completion report and warnings, and location of Amanda directories
Device and network settings, such as names of your tape devices, tape type definitions, tape changer script, tape labeling template, and network bandwidth for Amanda to use
Backup policy settings such as dump cycle, specifics about incremental backups, number of backup runs per dump cycle, and number of tapes in rotation
Holding disk locations with capacities available to Amanda
Instructions for how to perform backups, such as whether to use
dumpor GNUtarand details about indexing data, encryption, and compression
The disklist file specifies what to back up. For example, to back up the /home directories for clients Iron and Copper in Figure 4-5 requires the following disk list entries (DLEs):
# hostname diskname dumptype Copper /home1 stable Copper /home2 stable Iron /home3 normal Iron /home4 normal
Dumptypes are defined in the amanda.conf file. They specify backup-related parameters, such as whether to
compress the backups, whether to record backup results in /
etc/dumpdates, the disk’s relative priority, and
exclude lists. Here are sample definitions for the dumptypes normal and stable that we used for
Copper and Iron entries in the disklist file:
define dumptype normal {
comment "gnutar backup"
holdingdisk yes # (on by default)
index yes
program "GNUTAR"
priority medium
}
define dumptype stable {
comment "ufsdump backup"
holdingdisk yes # (on by default)
index yes
program "DUMP"
priority medium
}Many parameters in amanda.conf have default values, but the wide variety of parameters available for editing gives you full control over your backup environment.
A new Amanda user should plan on a learning curve of about two to four weeks before having a full production backup. It does not mean that a novice user will spend the whole month studying the Amanda wiki and reading the source code. As a matter of fact, it takes less than 15 minutes to configure an Amanda server with two Linux clients and one Windows client and to start a test backup. A white paper available at http://amanda.zmanda.com/quick-backup-setup.html provides detailed information about the “Start Amanda backup in 15 minutes” benchmark. However, you should plan to allocate some time to get comfortable with Amanda functionality and to test your restores several times before going into production. For large sites, it is a good idea to add one or two clients every day until all clients are protected by Amanda.
So far, we have described the most typical situation: an Amanda client configured on the system to be protected. However, a system administrator may decide to mount a filesystem via NFS or Samba on the Amanda server and have the Amanda client running on the server back up these networked filesystems.
Backing Up Clients via NFS or Samba
Compared to the traditional approach of using an Amanda client on the system to be protected, there are several advantages of backing up via the Network File System (NFS) or Samba:[3]
You don’t need to install and configure Amanda client software on the system to be protected. More systems can be added to the list of protected systems by modifying files on one system.
A native Amanda client may not be available for a particular operating system. An NFS/SMB approach gives you the ability to back up such an operating system.
You use significantly less CPU and memory resources on the protected system.
If the important data from the protected systems is already available via NFS or CIFS, this approach provides better integration with the company IT policy.
However, consider the trade-offs of this approach:
Think about the security issues of the mounting mechanism, whether SMB or NFS. You will not be able to use the mechanism provided by Amanda to encrypt the data in transit from the client to the server. You will also need to understand the security implications of running NFS or Samba on the system you want to protect in the first place. For example, if you do not want to run an NFS server all of the time on the system you want to back up, you will need to craft a synchronization scheme in which the NFS server on the system starts running just before the backup starts.
Access privileges need to be carefully worked out. The Amanda server needs both read and write privileges on the NFS mount point. Read permission is necessary during the backup phase. Write permission is necessary during a restore.
You will not be able to use local filesystem-based mechanisms for optimizing the backup process. For example, you will not be able to use
dumporxfsdumpon a filesystem being accessed over the network.You cannot back up any open files being accessed via Samba. You cannot back up extended file attributes via Samba.
Backing Up Using NFS
To back up using NFS, you need to install and configure an NFS server on the target
system, and an NFS client on the Amanda server. At this point, export the filesystems to
be backed up (by listing them in the /etc/exports
file of the client system). Make sure that the Amanda server can access all the files
that need to be backed up. In many cases, this means turning on the no_root_squash option on the NFS share being backed up so
that the Amanda server can access all files. Note that the hostname in the corresponding
disk list entry should be the system where the NFS share is being mounted (not the
client system). For example, in the sample network in Figure 4-6, the hostname in the disk
list entry would be Quartz.

Backing Up via Samba
To back up using Samba, install the Samba client on the Amanda server. You don’t
have to explicitly mount the remote filesystem. Amanda is well integrated with the
smbclient utility (an ftp-like client that is used to access SMB/CIFS resources on servers). It
uses the -T option to create tar-compatible backups of all the files on an SMB/CIFS share. Amanda clears
the archive bit of the files on the Windows-based target it backs up, enabling the
incremental backup process.
A user must be created on the Windows system with full access rights (read/write) to the share. (In the example network in Figure 4-7, the user is amandabackup.) Amanda connects to the share as this user. If the user does not have full access, incremental backups will not work, and the whole share will be backed up every time (because the archive bits are never reset). Note that if any other program on the Windows system resets the archive bit of a file, Amanda will not back up that file during an incremental backup.

In addition to the standard Amanda configuration, you need to create the file
/etc/amandapass on the system running the
smbclient utility. This file contains
authentication information to access specific Windows shares. Also note that the
hostname in the corresponding disk list entry refers to the system running smbclient, not the Windows system being backed up. In Figure 4-7, it would be Amanda server
Quartz.
Many Amanda installations protect Windows servers and PCs in production. For example, the Radiology Department at a large Midwestern university has been using Amanda since 1999. In the past, their Amanda server ran on IRIX, AIX, and Solaris, but the current Amanda server runs on Linux with indices replicated to another server. They back up more than 70 Linux, Solaris, IRIX, Mac OS X, and Windows clients with around 4 TB of backup data. The holding disk is 1.4 TB, and the dump cycle is 90 days. All Windows clients are protected using Samba. Several times per month, they recover files because of user error or hard-drive failures and have never lost data because Amanda was always able to recover lost files. The next section describes Amanda recovery.
Amanda Recovery
amrecover and amrestore restore Amanda backups. amrecover restores files using an interface that allows browsing of the
backup file index to a certain date and selecting files to restore. Of course, to use
amrecover, you should enable indexing of backup files
when you specify the dumptype in
amanda.conf. After you select files, Amanda finds the required tape, looks
for the backup image, decompresses the image if required, brings the image over the
network to the client, and pipes it into the appropriate restore program with the
arguments needed to extract the requested files. In case you have to restore your files
from incremental backups, Amanda specifies the correct order of the tapes. For security,
amrecover must run as root on the client, and you
should list root as the remote user in .amandahosts
on the Amanda server.
Full filesystem recovery should
be done with amrestore, which retrieves whole
filesystem images from tape.
amrecover can be done on any client
including the Amanda server. amrestore can be done only
on the Amanda server. You have to use amrestore when
you don’t have a backup index.
If your backup policy specifies backup of everything including the operating system, you can do bare-metal recoveries with Amanda. Here’s the procedure:
The Amanda tape format is simple so that in case of emergency, you can restore data without any Amanda tools. The first tape file is a volume label with the tape volume serial number and date it was written. It is in plain text. Each file after that contains one image using 32 KB blocks. The first block is an Amanda header with the client, area, and options used to create the image. As with the volume label, the header is plain text. The image follows, starting at the next tape block, until end of file.
Because the image header is text, it may be viewed with these commands:
#mt rewind#mt fsf NN#dd if=$TAPE bs=32k count=1
In addition to describing the image, the Amanda tape format contains text showing the
commands needed to do a restore. Here’s a typical entry for the /home2 filesystem on iron.zmanda.com. It is a level 1
dump done without compression using Solaris ufsdump:
AMANDA: FILE 20060418 copper.zmanda.com /home2 lev 1 comp N program /usr/sbin/ufsdump
To restore, position the tape at start of file and run:
# dd if=$TAPE bs=32k skip=1 | /usr/sbin/ufsrestore -f... -To retrieve an image with standard Unix utilities if amrestore is not available, position the tape to the image, then use dd to read it:
#mt rewind#mt fsf NN#dd if=$TAPE bs=32k skip=1 of=dump_image
The skip=1 option tells dd to skip over the Amanda file header. Without the of= option, dd writes the image to
standard output, which can be piped to a decompression program, if needed, and then to the
client restore program.
If RAIT is used as the media, a shell script using the commands dd and mt must be used to
restore data from the tapes without using Amanda commands. As with any backup system, you
should test and retest your restore procedures so you know exactly what to do when
disaster strikes.
Community and Support Options
We’ve described Amanda’s core functionality, but there is more to learn. For in-depth information about Amanda monitoring, reporting, self-checking, encryption, and many other features, see the following resources.
Amanda is the only open-source backup software with enterprise support, available as a subscription from Zmanda, Inc. (http://www.zmanda.com). Zmanda also offers indemnification to select buyers of its Amanda Enterprise Edition subscription from any intellectual property infringement issues. In addition, professional services are available from Zmanda and several other organizations for installing and configuring Amanda.
Amanda documentation written by users for users is available at the Amanda wiki at http://wiki.zmanda.com. Ease of remote editing by multiple users, an ongoing archival of changes, and search capability are key features of this wiki. The Amanda community uses various collaboration tools including Amanda forums at http://forums.zmanda.com. Amanda users also have a very friendly mailing list at amanda-users@amanda.org with archives available at http://groups.yahoo.com/group/amanda-users.
Future Plans
One of the main challenges in IT today is the overall security of systems. Since security is such a fundamental part of backup (especially when people lose unencrypted tapes), the Amanda community plans to continue hardening all aspects of Amanda security.
There is a fundamental shift in the backup industry, with disk becoming the primary media for backups. Even though Amanda was designed for backup-to-disk from the very beginning, the Amanda team plans many backup-to-disk improvements, such as providing multiple simultaneous backups and restores from disk.
Many Amanda users have a constant battle with overwhelming data growth. Amanda has to be up to the task, and the Amanda team is working on increasing scalability and performance.
Wide adoption of open-source products (especially Linux) brings Amanda to production environments with Oracle, MySQL, SAP, and many other applications. Many users successfully deploy Amanda in such demanding environments, and the Amanda team is working on an application API that will simplify backup of those applications.
Amanda has always strived to simplify the life of the system administrator, and the project continues to work on the simplification of installation, administration, and recovery while giving the system administrator full control of how to do backups.
As you can see from this short list, the development of Amanda continues addressing of real-world requirements of real people. The Amanda development team and the Amanda community will further maintain and enhance this powerful and well-known software suite.
Tip
BackupCentral.com has a wiki page for every chapter in this book. Read or contribute updated information about this chapter at http://www.backupcentral.com.
[1] Because so many technical writers before us wrote excellent articles about Amanda, we want to give due credit to John R. Jackson, Alexandre Oliva, →leen Frisch, Paul Bijnens, and many others who contributed to the wealth of published knowledge about Amanda. Many of their ideas made it into this chapter.
[2] The acronym LAMP refers to a set of open-source software tools commonly used together to run dynamic web sites or servers. LAMP stands for Linux, Apache, MySQL, Perl, PHP, Python.
[3] Samba is an open-source implementation of the SMB protocol, which is also called Common Internet File System (CIFS). SMB/CIFS is commonly used on Windows systems.
Get Backup & Recovery now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

