Chapter 13. What Data Doesn't Do
DATA DOES A GREAT MANY THINGS: IT ALLOWS US TO SEPARATE SCIENCE FROM SUPERSTITION AND THE repeatable from the random. Over the past several decades, scientists have scaled tremendously the processes for collecting, collating, and storing data. From medical decision-making to soft drink marketing to supply chain management, we're relying more on fact and less on hunch. We're letting data drive.
But data doesn't drive everything. Over the past century, psychologists have poked holes in the theory that people interpret data with anything close to rational equanimity. In truth, we're biased in our interpretation of information. Moreover, the real world does not manifest itself with the easy probabilism of a game of dice. Rather, individuals must extract likelihoods from perceived patterns in experience.
This chapter is a discussion of the approximations and biases that stand between data and analysis. It describes a set of new experiments and tools to help people use data more effectively, and draws examples from the growing literature in medical, consumer, and financial decision-making.
Suppose I ask you to identify the odd one out from Figure 13-1.
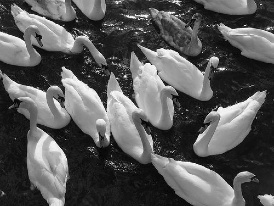
Figure 13-1. The human visual system is adept at identifying the odd one out.
The answer is immediate and trivial: the human eye can pick out the ugly duckling from the swans. For a computer, however, ...
Get Beautiful Data now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.
