Chapter 1. The Causal-Behavioral Framework for Data Analysis
As we discussed in the preface, understanding what drives behaviors in order to change them is one of the key goals of applied analytics, whether in a business, a nonprofit, or a public organization. We want to figure out why someone bought something and why someone else didn’t buy it. We want to understand why someone renewed their subscription, contacted a call center instead of paying online, registered to be an organ donor, or gave to a nonprofit. Having this knowledge allows us to predict what people will do under different scenarios and helps us to determine what our organization can do to encourage them to do it again (or not). I believe that this goal is best achieved by combining data analysis with a behavioral science mindset and a causal analytics toolkit to create an integrated approach I have dubbed the “causal-behavioral framework.” In this framework, behaviors are at the top because understanding them is our ultimate goal. This understanding is achieved by using causal diagrams and data, which form the two supporting pillars of the triangle (Figure 1-1).
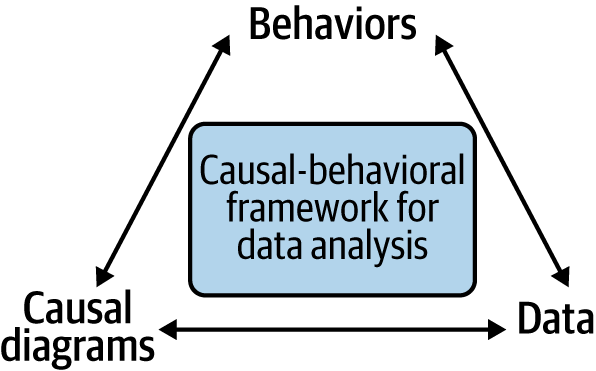
Figure 1-1. The causal-behavioral framework for data analysis
Over the course of the book, we’ll explore each leg of the triangle and see how they connect to each other. In the final chapter, we’ll see all of our work come together by achieving with one line of code what would be a daunting task with traditional approaches: measuring the degree to which customer satisfaction increases future customer spending. In addition to performing such extraordinary feats, this new framework will also allow you to more effectively perform common analyses such as determining the effect of an email campaign or a product feature on purchasing behavior.
Before getting to that, readers familiar with predictive analytics may wonder why I’m advocating for causal analytics instead. The answer is that even though predictive analytics have been (and will remain) very successful in business settings, they can fall short when your analyses pertain to human behaviors. In particular, adopting a causal approach can help us identify and resolve “confounding,” a very common problem with behavioral data. I’ll elaborate on these points in the rest of this first chapter.
Why We Need Causal Analytics to Explain Human Behavior
Understanding where causal analytics fits into the analytics landscape will help us better identify why it is needed in business settings. As we’ll see, that need stems from the complexity of human behavior.
The Different Types of Analytics
There are three different types of analytics: descriptive, predictive, and causal. Descriptive analytics provides a description of data. In simple terms, I think of it as “what is” or “what we’ve measured” analytics. Business reporting falls under that umbrella. How many customers canceled their subscriptions last month? How much profit did we make last year? Whenever we’re calculating an average or other simple metrics, we’re implicitly using descriptive analytics. Descriptive analytics is the simplest form of analytics, but it is also underappreciated. Many organizations actually struggle to get a clear and unified view of their operations. To see the extent of that problem in an organization, just ask the same question of the finance department and the operations department and measure how different the answers are.1
Predictive analytics provides a prediction. I think of it as “what will be, assuming current conditions persist” or “what we haven’t yet measured” analytics. Most machine learning methods (e.g., neural networks and gradient boosting models) belong to this type of analytics and help us answer questions like “How many customers will cancel their subscription next month?” and “Is that order fraudulent?” Over the past few decades, predictive analytics has transformed the world; the legions of data scientists employed in business are a testament to its success.
Finally, causal analytics provides the causes of data. I think of it as “what if?” or “what will be, under different conditions” analytics. It answers questions such as “How many customers will cancel their subscription next month unless we send them a coupon?” The most well-known tool of causal analytics is the A/B test, a.k.a. a randomized experiment or randomized controlled trial (RCT). That’s because the simplest and most effective way to answer the preceding question is to send a coupon to a randomly selected group of customers and see how many of them cancel their subscription compared to a control group.
We’ll cover experimentation in Part IV of the book, but before that, in Part II, we’ll look at another tool from that toolkit, namely causal diagrams, which can be used even when we can’t experiment. Indeed, it is one of my goals to get you to think more broadly about causal analytics rather than just equate it with experimentation.
Note
While these labels may give the impression of a neat categorization, in reality, there is more of a gradient between these three categories, and questions and methods get blurred between them. You may also encounter other terms, such as prescriptive analytics, that further blur the lines and add other nuances without dramatically altering the overall picture.
Human Beings Are Complicated
If predictive analytics has been so successful and causal analytics uses the same data analysis tools like regression, why not stick with predictive analytics? In short, because human beings are more complicated than wind turbines. Human behavior:
- Has multiple causes
-
A turbine’s behavior is not influenced by its personality, the social norms of the turbine community, or the circumstances of its upbringing, whereas the predictive power of any single variable on human behavior is almost always disappointing because of those factors.
- Is context-dependent
-
Minor or cosmetic alterations to the environment, such as a change in the default option of a choice, can have large impacts on behavior. This is a blessing from a behavioral design perspective because it allows us to drive changes in behaviors, but it’s a curse from a behavioral analytics perspective because it means that every situation is unique in ways that are hard to predict.
- Is variable (scientists would say nondeterministic)
-
The same person may behave very differently when placed repeatedly in what seems like exactly the same situation, even after controlling for cosmetic factors. This may be due to transient effects, such as moods, or long-term effects, such as getting bored with having the same breakfast every day. Both of these can dramatically change behavior but are hard to capture.
- Is innovative
-
When conditions in the environment change, a human can switch to a behavior they have literally never exhibited before, and it happens even under the most mundane circumstances. For example, there’s a car accident ahead on your normal commuting path and so you decide at the last minute to take a right turn.
- Is strategic
-
Humans infer and react to the behaviors and intentions of others. In some cases, that can mean “repairing” a cooperation that was derailed by external circumstances, making it more robustly predictable. But in other cases, it can involve voluntarily obfuscating one’s behavior to make it unpredictable when playing a competitive game like chess (or fraud!).
All these aspects of human behavior make it less predictable than that of physical objects. To find regularities that are more reliable for analysis, we must go one level deeper to understand and measure the causes of behavior. The fact that someone had oatmeal for breakfast and took a certain route on Monday doesn’t mean that they will do the same on Tuesday, but you can be more confident that they’ll have some breakfast and will take some route to their work.
Conclusion
Predictive analytics has been extremely successful over the past few decades and will remain so. On the other hand, when trying to understand and—more importantly—change human behavior, causal analytics offers a compelling alternative.
Causal analytics, however, demands a different approach than what we are used to with predictive analytics. Hopefully, the examples in this chapter have convinced you that you can’t just throw a bunch of variables in a linear or logistic regression and hope for the best (which we might think of as the “include them all, God will recognize His own” approach). You may still wonder, though, about other types of models and algorithms. Are gradient boosting or deep learning models somehow immune to confounders, multicollinearity, and spurious correlations? Unfortunately, the answer is no. If anything, the “black box” nature of these models means that confounders can be harder to catch.
In the next chapter, we will explore how to think about the behavioral data itself.
1 To be fair, in many circumstances, they should be different, because the data is used for different purposes and obeys different conventions. But even questions that you would expect to have a single true answer (e.g., “How many employees do we have right now?”) will generally show discrepancies.
2 In case you’re wondering, the aforementioned statistician is Donald Rubin.
3 Technically speaking, this is a slightly different situation, because there is a threshold effect instead of two linear (or logistic) relationships, but the underlying principle that including the wrong variable can create artificial correlations still applies.
Get Behavioral Data Analysis with R and Python now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

