April 2016
Intermediate to advanced
70 pages
1h 11m
English
Factor 5, build, release, run, of the original 12 factors, calls for the strict separation of the build and run stages of development. This is excellent advice, and failing to adhere to this guideline can set you up for future difficulties. In addition to the twelve-factor build, release, run trio, the discrete design step is crucial.
In Figure 4-1, you can see an illustration of the flow from design to run. Note that this is not a waterfall diagram: the cycle from design through code and to run is an iterative one and can happen in as small or large a period of time as your team can handle. In cases where teams have a mature CI/CD pipeline, it could take a matter of minutes to go from design to running in production.
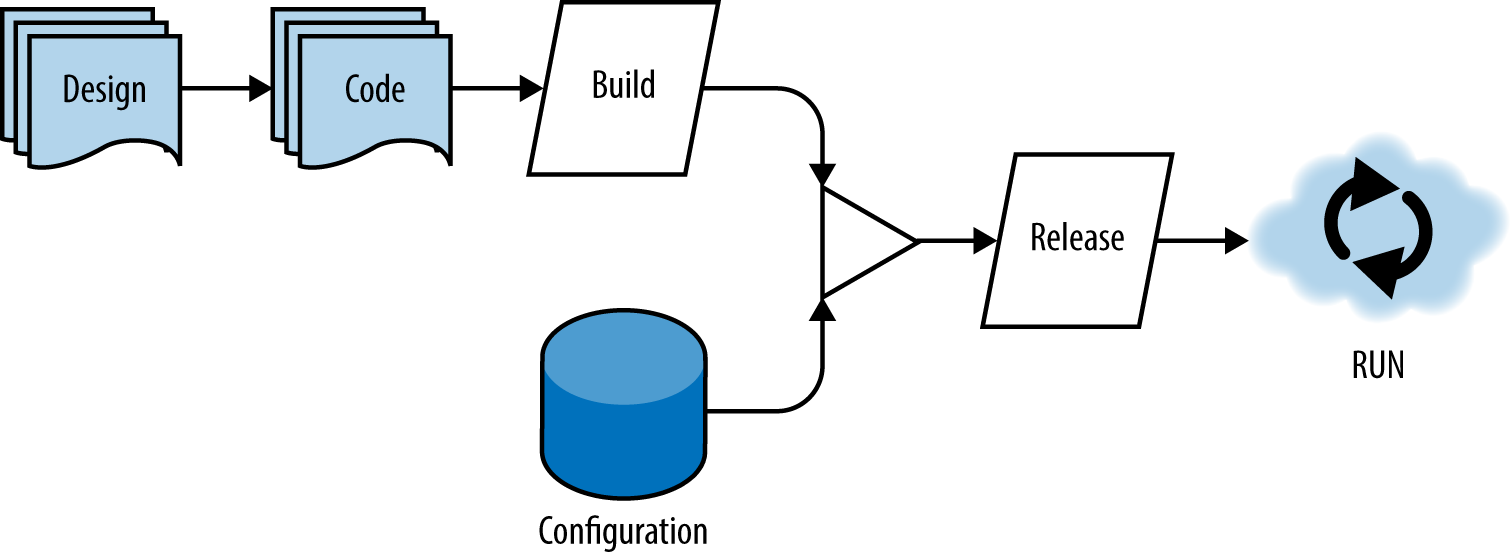
A single codebase is taken through the build process to produce a compiled artifact. This artifact is then merged with configuration information that is external to the application to produce an immutable release. The immutable release is then delivered to a cloud environment (development, QA, production, etc.) and run. The key takeaway from this chapter is that each of the following deployment stages is isolated and occurs separately.
In the world of waterfall application development, we spend an inordinate amount of time designing an application before a single line ...
Read now
Unlock full access






