Chapter 1. Hadoop Basics
Hadoop is a large and complex beast. It can be bewildering to even begin to use the system, and so in this chapter we’re going to purposefully charge through the minimum requirements for getting started with launching jobs and managing data. In this book, we will try to keep things as simple as possible. For every one of Hadoop’s many modes, options, and configurations that is essential, there are many more that are distracting or even dangerous. The most important optimizations you can make come from designing efficient workflows, and even more so from knowing when to spend highly valuable programmer time to reduce compute time.
In this chapter, we will equip you with two things: the necessary mechanics of working with Hadoop, and a physical intuition for how data and computation move around the cluster during a job.
The key to mastering Hadoop is an intuitive, physical understanding of how data moves around a Hadoop cluster. Shipping data from one machine to another—even from one location on disk to another—is outrageously costly, and in the vast majority of cases, dominates the cost of your job. We’ll describe at a high level how Hadoop organizes data and assigns tasks across compute nodes so that as little data as possible is set in motion; we’ll accomplish this by telling a story that features a physical analogy and by following an example job through its full lifecycle. More importantly, we’ll show you how to read a job’s Hadoop dashboard to understand how much it cost and why. Your goal for this chapter is to take away a basic understanding of how Hadoop distributes tasks and data, and the ability to run a job and see what’s going on with it. As you run more and more jobs through the remaining course of the book, it is the latter ability that will cement your intuition.
What does Hadoop do, and why should we learn about it? Hadoop enables the storage and processing of large amounts of data. Indeed, it is Apache Hadoop that stands at the middle of the big data trend. The Hadoop Distributed File System (HDFS) is the platform that enabled cheap storage of vast amounts of data (up to petabytes and beyond) using affordable, commodity machines. Before Hadoop, there simply wasn’t a place to store terabytes and petabytes of data in a way that it could be easily accessed for processing. Hadoop changed everything.
Throughout this book, we will teach you the mechanics of operating Hadoop, but first you need to understand the basics of how the Hadoop filesystem and MapReduce work together to create a computing platform. Along these lines, let’s kick things off by making friends with the good folks at Chimpanzee and Elephant, Inc. Their story should give you an essential physical understanding for the problems Hadoop addresses and how it solves them.
Chimpanzee and Elephant Start a Business
A few years back, two friends—JT, a gruff chimpanzee, and Nanette, a meticulous matriarch elephant—decided to start a business. As you know, chimpanzees love nothing more than sitting at keyboards processing and generating text. Elephants have a prodigious ability to store and recall information, and will carry huge amounts of cargo with great determination. This combination of skills impressed a local publishing company enough to earn their first contract, so Chimpanzee and Elephant, Incorporated (C&E for short) was born.
The publishing firm’s project was to translate the works of Shakespeare into every language known to man, so JT and Nanette devised the following scheme. Their crew set up a large number of cubicles, each with one elephant-sized desk and several chimp-sized desks, and a command center where JT and Nanette could coordinate the action.
As with any high-scale system, each member of the team has a single responsibility to perform. The task of each chimpanzee is simply to read a set of passages and type out the corresponding text in a new language. JT, their foreman, efficiently assigns passages to chimpanzees, deals with absentee workers and sick days, and reports progress back to the customer. The task of each librarian elephant is to maintain a neat set of scrolls, holding either a passage to translate or some passage’s translated result. Nanette serves as chief librarian. She keeps a card catalog listing, for every book, the location and essential characteristics of the various scrolls that maintain its contents.
When workers clock in for the day, they check with JT, who hands off the day’s translation manual and the name of a passage to translate. Throughout the day, the chimps radio progress reports in to JT; if their assigned passage is complete, JT will specify the next passage to translate.
If you were to walk by a cubicle mid-workday, you would see a highly efficient interplay between chimpanzee and elephant, ensuring the expert translators rarely had a wasted moment. As soon as JT radios back what passage to translate next, the elephant hands it across. The chimpanzee types up the translation on a new scroll, hands it back to its librarian partner, and radios for the next passage. The librarian runs the scroll through a fax machine to send it to two of its counterparts at other cubicles, producing the redundant, triplicate copies Nanette’s scheme requires.
The librarians in turn notify Nanette which copies of which translations they hold, which helps Nanette maintain her card catalog. Whenever a customer comes calling for a translated passage, Nanette fetches all three copies and ensures they are consistent. This way, the work of each monkey can be compared to ensure its integrity, and documents can still be retrieved even if a cubicle radio fails.
The fact that each chimpanzee’s work is independent of any other’s—no interoffice memos, no meetings, no requests for documents from other departments—made this the perfect first contract for the C&E crew. JT and Nanette, however, were cooking up a new way to put their million-chimp army to work, one that could radically streamline the processes of any modern paperful office.1 JT and Nanette would soon have the chance of a lifetime to try it out for a customer in the far north with a big, big problem (we’ll continue their story in “Chimpanzee and Elephant Save Christmas”).
Map-Only Jobs: Process Records Individually
As you’d guess, the way Chimpanzee and Elephant organize their files and workflow corresponds directly with how Hadoop handles data and computation under the hood. We can now use it to walk you through an example in detail.
The bags on trees scheme represents transactional relational database systems. These are often the systems that Hadoop data processing can augment or replace. The “NoSQL” (Not Only SQL) movement of which Hadoop is a part is about going beyond the relational database as a one-size-fits-all tool, and using different distributed systems that better suit a given problem.
Nanette is the Hadoop NameNode. The NameNode manages the HDFS. It stores the directory tree structure of the filesystem (the card catalog), and references to the data nodes for each file (the librarians). You’ll note that Nanette worked with data stored in triplicate. Data on HDFS is duplicated three times to ensure reliability. In a large enough system (thousands of nodes in a petabyte Hadoop cluster), individual nodes fail every day. In that case, HDFS automatically creates a new duplicate for all the files that were on the failed node.
JT is the JobTracker. He coordinates the work of individual MapReduce tasks into a cohesive system. The JobTracker is responsible for launching and monitoring the individual tasks of a MapReduce job, which run on the nodes that contain the data a particular job reads. MapReduce jobs are divided into a map phase, in which data is read, and a reduce phase, in which data is aggregated by key and processed again. For now, we’ll cover map-only jobs (we’ll introduce reduce in Chapter 2).
Note that in YARN (Hadoop 2.0), the terminology changed. The JobTracker is called the ResourceManager, and nodes are managed by NodeManagers. They run arbitrary apps via containers. In YARN, MapReduce is just one kind of computing framework. Hadoop has become an application platform. Confused? So are we. YARN’s terminology is something of a disaster, so we’ll stick with Hadoop 1.0 terminology.
Pig Latin Map-Only Job
To illustrate how Hadoop works, let’s dive into some code with the simplest example possible. We may not be as clever as JT’s multilingual chimpanzees, but even we can translate text into a language we’ll call Igpay Atinlay.2 For the unfamiliar, here’s how to translate standard English into Igpay Atinlay:
-
If the word begins with a consonant-sounding letter or letters, move them to the end of the word and then add “ay”: “happy” becomes “appy-hay,” “chimp” becomes “imp-chay,” and “yes” becomes “es-yay.”
-
In words that begin with a vowel, just append the syllable “way”: “another” becomes “another-way,” “elephant” becomes “elephant-way.”
Example 1-1 is our first Hadoop job, a program that translates plain-text files into Igpay Atinlay. This is a Hadoop job stripped to its barest minimum, one that does just enough to each record that you believe it happened but with no distractions. That makes it convenient to learn how to launch a job, how to follow its progress, and where Hadoop reports performance metrics (e.g., for runtime and amount of data moved). What’s more, the very fact that it’s trivial makes it one of the most important examples to run. For comparable input and output size, no regular Hadoop job can outperform this one in practice, so it’s a key reference point to carry in mind.
We’ve written this example in Python, a language that has become the lingua franca of data science. You can run it over a text file from the command line—or run it over petabytes on a cluster (should you for whatever reason have a petabyte of text crying out for pig-latinizing).
Example 1-1. Igpay Atinlay translator, pseudocode
for each line,
recognize each word in the line
and change it as follows:
separate the head consonants (if any) from the tail of the word
if there were no initial consonants, use 'w' as the head
give the tail the same capitalization as the word
thus changing the word to "tail-head-ay"
end
having changed all the words, emit the latinized version of the line
end#!/usr/bin/python
import sys, re
WORD_RE = re.compile(r"\b([bcdfghjklmnpqrstvwxz]*)([\w\']+)")
CAPITAL_RE = re.compile(r"[A-Z]")
def mapper(line):
words = WORD_RE.findall(line)
pig_latin_words = []
for word in words:
original_word = ''.join(word)
head, tail = word
head = 'w' if not head else head
pig_latin_word = tail + head + 'ay'
if CAPITAL_RE.match(pig_latin_word):
pig_latin_word = pig_latin_word.lower().capitalize()
else:
pig_latin_word = pig_latin_word.lower()
pig_latin_words.append(pig_latin_word)
return " ".join(pig_latin_words)
if __name__ == '__main__':
for line in sys.stdin:
print mapper(line)
It’s best to begin developing jobs locally on a subset of data, because they are faster and cheaper to run. To run the Python script locally, enter this into your terminal’s command line:
cat /data/gold/text/gift_of_the_magi.txt|python examples/ch_01/pig_latin.py
The output should look like this:
Theway agimay asway youway owknay ereway iseway enmay onderfullyway iseway enmay owhay oughtbray iftsgay otay ethay Babeway inway ethay angermay Theyway inventedway ethay artway ofway ivinggay Christmasway esentspray Beingway iseway eirthay iftsgay ereway onay oubtday iseway onesway ossiblypay earingbay ethay ivilegepray ofway exchangeway inway asecay ofway uplicationday Andway erehay Iway avehay amelylay elatedray otay youway ethay uneventfulway oniclechray ofway otway oolishfay ildrenchay inway away atflay owhay ostmay unwiselyway acrificedsay orfay eachway otherway ethay eatestgray easurestray ofway eirthay ousehay Butway inway away astlay ordway otay ethay iseway ofway esethay aysday etlay itway ebay aidsay atthay ofway allway owhay ivegay iftsgay esethay otway ereway ethay isestway Ofway allway owhay ivegay andway eceiveray iftsgay uchsay asway eythay areway isestway Everywhereway eythay areway isestway Theyway areway ethay agimay
That’s what it looks like when run locally. Let’s run it on a real Hadoop cluster to see how it works when an elephant is in charge.
Note
Besides being faster and cheaper, there are additional reasons for why it’s best to begin developing jobs locally on a subset of data: extracting a meaningful subset of tables also forces you to get to know your data and its relationships. And because all the data is local, you’re forced into the good practice of first addressing “what would I like to do with this data?” and only then considering “how shall I do so efficiently?” Beginners often want to believe the opposite, but experience has taught us that it’s nearly always worth the upfront investment to prepare a subset, and not to think about efficiency from the beginning.
Setting Up a Docker Hadoop Cluster
We’ve prepared a docker image you can use to create a Hadoop environment with Pig and Python already installed, and with the example data already mounted on a drive. You can begin by checking out the code. If you aren’t familiar with Git, check out the Git home page and install it. Then proceed to clone the example code Git repository, which includes the docker setup:
git clone --recursive http://github.com/bd4c/big_data_for_chimps-code.git \ bd4c-code cd bd4c-code ls
You should see:
Gemfile README.md cluster docker examples junk notes numbers10k.txt vendor
Now you will need to install VirtualBox for your platform, which you can download from the VirtualBox website. Next, you will need to install Boot2Docker, which you can find from https://docs.docker.com/installation/. Run Boot2Docker from your OS menu, which (on OS X or Linux) will bring up a shell, as shown in Figure 1-1.
Figure 1-1. Boot2Docker for OS X
We use Ruby scripts to set up our docker environment, so you will need Ruby v. >1.9.2 or >2.0. Returning to your original command prompt, from inside the bd4c-code directory, let’s install the Ruby libraries needed to set up our docker images:
gem install bundler # you may need to sudo bundle install
Next, change into the cluster directory, and repeat bundle install:
cd cluster bundle install
You can now run docker commands against this VirtualBox virtual machine (VM) running the docker daemon. Let’s start by setting up port forwarding from localhost to our docker VM. From the cluster directory:
boot2docker down bundle exec rake docker:open_ports
While we have the docker VM down, we’re going to need to make an adjustment in VirtualBox. We need to increase the amount of RAM given to the VM to at least 4 GB. Run VirtualBox from your OS’s GUI, and you should see something like Figure 1-2.
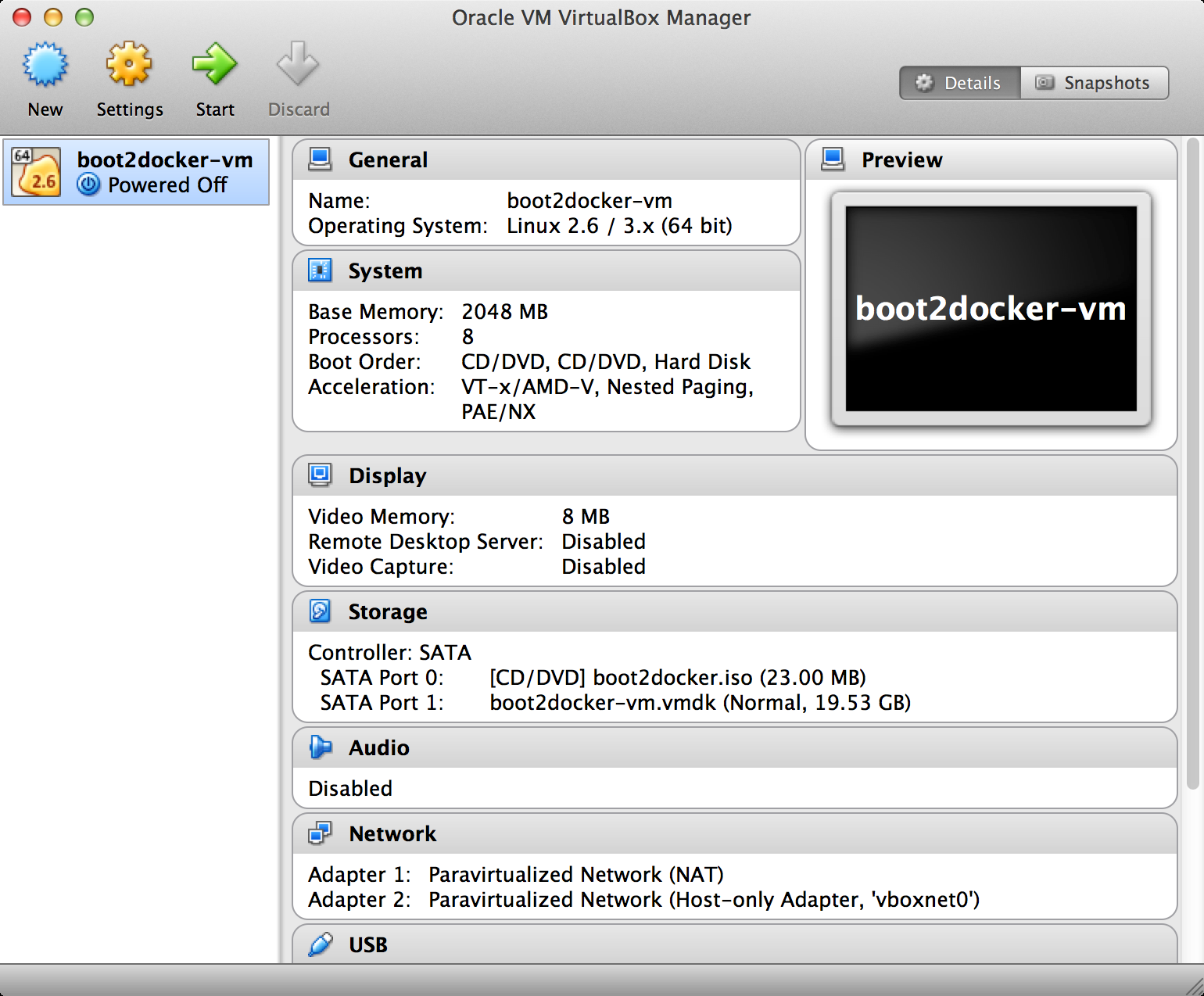
Figure 1-2. Boot2Docker VM inside VirtualBox
Select the Boot2Docker VM, and then click Settings. As shown in Figure 1-3, you should now select the System tab, and adjust the RAM slider right until it reads at least 4096 MB. Click OK.
Now you can close VirtualBox, and bring Boot2Docker back up:
boot2docker up boot2docker shellinit
This command will print something like the following:
Writing /Users/rjurney/.boot2docker/certs/boot2docker-vm/ca.pem
Writing /Users/rjurney/.boot2docker/certs/boot2docker-vm/cert.pem
Writing /Users/rjurney/.boot2docker/certs/boot2docker-vm/key.pem
export DOCKER_TLS_VERIFY=1
export DOCKER_HOST=tcp://192.168.59.103:2376
export DOCKER_CERT_PATH=/Users/rjurney/.boot2docker/certs/boot2docker-vm
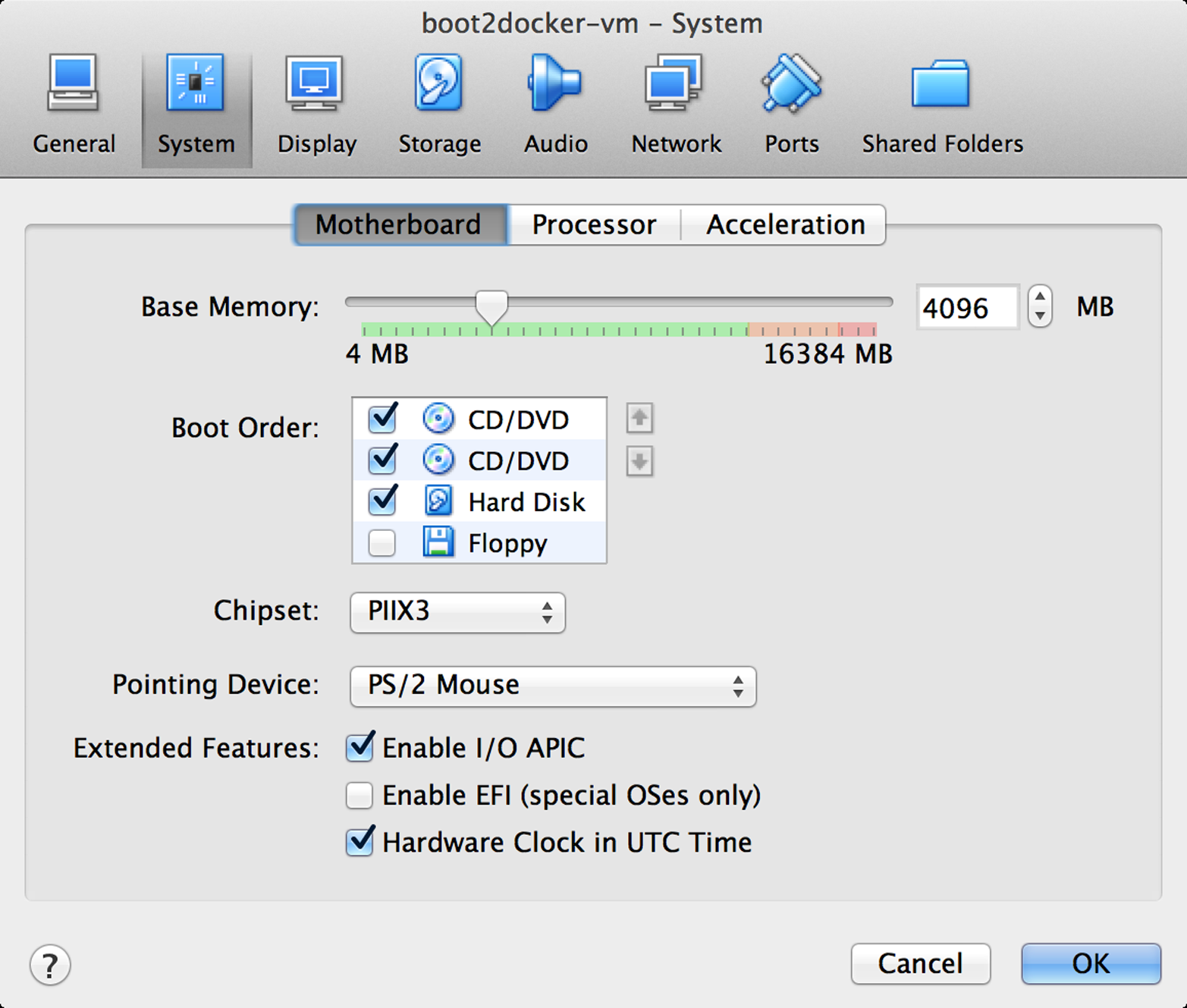
Figure 1-3. VirtualBox interface
Now is a good time to put these lines in your ~/.bashrc file (make sure to substitute your home directory for <home_directory>):
export DOCKER_TLS_VERIFY=1 export DOCKER_IP=192.168.59.103 export DOCKER_HOST=tcp://$DOCKER_IP:2376 export DOCKER_CERT_PATH=/<home_directory>/.boot2docker/certs/boot2docker-vm
You can achieve that, and update your current environment, via:
echo 'export DOCKER_TLS_VERIFY=1' >> ~/.bashrc echo 'export DOCKER_IP=192.168.59.103' >> ~/.bashrc echo 'export DOCKER_HOST=tcp://$DOCKER_IP:2376' >> ~/.bashrc echo 'export DOCKER_CERT_PATH=/<home_dir>/.boot2docker/certs/boot2docker-vm' \ >> ~/.bashrc source ~/.bashrc
Check that these environment variables are set, and that the docker client can connect, via:
echo $DOCKER_IP echo $DOCKER_HOST bundle exec rake ps
Now you’re ready to set up the docker images. This can take a while, so brew a cup of tea after running:
bundle exec rake images:pull
Once that’s done, you should see:
Status: Image is up to date for blalor/docker-hosts:latest
Now we need to do some minor setup on the Boot2Docker virtual machine. Change terminals to the Boot2Docker window, or from another shell run boot2docker ssh, and run these commands:
mkdir -p /tmp/bulk/hadoop # view all logs there # so that docker-hosts can make container hostnames resolvable sudo touch /var/lib/docker/hosts sudo chmod 0644 /var/lib/docker/hosts sudo chown nobody /var/lib/docker/hosts exit
Now exit the Boot2Docker shell.
Back in the cluster directory, it is time to start the cluster helpers, which set up hostnames among the containers:
bundle exec rake helpers:run
If everything worked, you can now run cat /var/lib/docker/hosts on the Boot2Docker host, and it should be filled with information. Running bundle exec rake ps should show containers for host_filer and nothing else.
Next, let’s set up our example data. Run the following:
bundle exec rake data:create show_output=true
At this point, you can run bundle exec rake ps and you should see five containers, all stopped. Start these containers using:
bundle exec rake hadoop:run
This will start the Hadoop containers. You can stop/start them with:
bundle exec rake hadoop:stop bundle exec rake hadoop:start
Now ssh to your new Hadoop cluster:
ssh -i insecure_key.pem chimpy@$DOCKER_IP -p 9022 # Password chimpy
You can see that the example data is available on the local filesystem:
chimpy@lounge:~$ ls /data/gold/ airline_flights/ demographic/ geo/ graph/ helpers/ serverlogs/ sports/ text/ twitter/ wikipedia/ CREDITS.md README-archiver.md README.md
Now you can run Pig, in local mode:
pig -l /tmp -x local
And we’re off!
Run the Job
First, let’s test on the same tiny little file we used before. The following command does not process any data but instead instructs Hadoop to process the data. The command will generate output that contains information about how the job is progressing:
hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar \ -Dmapreduce.cluster.local.dir=/home/chimpy/code -fs local -jt local \ -file ./examples/ch_01/pig_latin.py -mapper ./examples/ch_01/pig_latin.py \ -input /data/gold/text/gift_of_the_magi.txt -output ./translation.out
You should see something like this:
WARN fs.FileSystem: "local" is a deprecated filesystem name. Use "file:///"...
WARN streaming.StreamJob: -file option is deprecated, please use generic...
packageJobJar: [./examples/ch_01/pig_latin.py] [] /tmp/...
INFO Configuration.deprecation: session.id is deprecated. Instead, use...
INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker...
INFO jvm.JvmMetrics: Cannot initialize JVM Metrics with...
INFO mapred.FileInputFormat: Total input paths to process : 1
INFO mapreduce.JobSubmitter: number of splits:1
INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local292160259_0001
WARN conf.Configuration: file:/tmp/hadoop-chimpy/mapred/staging/...
WARN conf.Configuration: file:/tmp/hadoop-chimpy/mapred/staging/...
INFO mapred.LocalDistributedCacheManager: Localized file:/home/chimpy/...
WARN conf.Configuration: file:/home/chimpy/code/localRunner/chimpy/...
WARN conf.Configuration: file:/home/chimpy/code/localRunner/chimpy/...
INFO mapreduce.Job: The url to track the job: http://localhost:8080/
INFO mapred.LocalJobRunner: OutputCommitter set in config null
INFO mapreduce.Job: Running job: job_local292160259_0001
INFO mapred.LocalJobRunner: OutputCommitter is...
INFO mapred.LocalJobRunner: Waiting for map tasks
INFO mapred.LocalJobRunner: Starting task:...
INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
INFO mapred.MapTask: Processing split: file:/data/gold/text/...
INFO mapred.MapTask: numReduceTasks: 1
INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
INFO mapred.MapTask: soft limit at 83886080
INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
INFO mapred.MapTask: kvstart = 26214396; length = 6553600
INFO mapred.MapTask: Map output collector class =...
INFO streaming.PipeMapRed: PipeMapRed exec [/home/chimpy/code/./pig_latin.py]
INFO streaming.PipeMapRed: R/W/S=1/0/0 in:NA [rec/s] out:NA [rec/s]
INFO streaming.PipeMapRed: R/W/S=10/0/0 in:NA [rec/s] out:NA [rec/s]
INFO streaming.PipeMapRed: R/W/S=100/0/0 in:NA [rec/s] out:NA [rec/s]
INFO streaming.PipeMapRed: Records R/W=225/1
INFO streaming.PipeMapRed: MRErrorThread done
INFO streaming.PipeMapRed: mapRedFinished
INFO mapred.LocalJobRunner:
INFO mapred.MapTask: Starting flush of map output
INFO mapred.MapTask: Spilling map output
INFO mapred.MapTask: bufstart = 0; bufend = 16039; bufvoid = 104857600
INFO mapred.MapTask: kvstart = 26214396(104857584); kvend =...
INFO mapred.MapTask: Finished spill 0
INFO mapred.Task: Task:attempt_local292160259_0001_m_000000_0 is done. And is...
INFO mapred.LocalJobRunner: Records R/W=225/1
INFO mapred.Task: Task 'attempt_local292160259_0001_m_000000_0' done.
INFO mapred.LocalJobRunner: Finishing task:...
INFO mapred.LocalJobRunner: map task executor complete.
INFO mapred.LocalJobRunner: Waiting for reduce tasks
INFO mapred.LocalJobRunner: Starting task:...
INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
INFO mapred.ReduceTask: Using ShuffleConsumerPlugin:...
INFO mapreduce.Job: Job job_local292160259_0001 running in uber mode : false
INFO mapreduce.Job: map 100% reduce 0%
INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=652528832...
INFO reduce.EventFetcher: attempt_local292160259_0001_r_000000_0 Thread...
INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map...
INFO reduce.InMemoryMapOutput: Read 16491 bytes from map-output for...
INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 16491...
INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning
INFO mapred.LocalJobRunner: 1 / 1 copied.
INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs...
INFO mapred.Merger: Merging 1 sorted segments
INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of...
INFO reduce.MergeManagerImpl: Merged 1 segments, 16491 bytes to disk to...
INFO reduce.MergeManagerImpl: Merging 1 files, 16495 bytes from disk
INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into...
INFO mapred.Merger: Merging 1 sorted segments
INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of...
INFO mapred.LocalJobRunner: 1 / 1 copied.
INFO mapred.Task: Task:attempt_local292160259_0001_r_000000_0 is done. And is...
INFO mapred.LocalJobRunner: 1 / 1 copied.
INFO mapred.Task: Task attempt_local292160259_0001_r_000000_0 is allowed to...
INFO output.FileOutputCommitter: Saved output of task...
INFO mapred.LocalJobRunner: reduce > reduce
INFO mapred.Task: Task 'attempt_local292160259_0001_r_000000_0' done.
INFO mapred.LocalJobRunner: Finishing task:...
INFO mapred.LocalJobRunner: reduce task executor complete.
INFO mapreduce.Job: map 100% reduce 100%
INFO mapreduce.Job: Job job_local292160259_0001 completed successfully
INFO mapreduce.Job: Counters: 33
File System Counters
FILE: Number of bytes read=58158
FILE: Number of bytes written=581912
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=225
Map output records=225
Map output bytes=16039
Map output materialized bytes=16495
Input split bytes=93
Combine input records=0
Combine output records=0
Reduce input groups=180
Reduce shuffle bytes=16495
Reduce input records=225
Reduce output records=225
Spilled Records=450
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=11
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=441450496
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=11224
File Output Format Counters
Bytes Written=16175
INFO streaming.StreamJob: Output directory: ./translation.out
This is the output of the Hadoop streaming JAR as it transmits your files and runs them on the cluster.
Wrapping Up
In this chapter, we’ve equipped you with two things: the necessary mechanics of working with Hadoop, and a physical intuition for how data and computation move around the cluster during a job. We started with a story about JT and Nanette, and learned about the Hadoop JobTracker, NameNode, and filesystem. We proceeded with a Pig Latin example, and ran it on a real Hadoop cluster.
We’ve covered the mechanics of the Hadoop Distributed File System (HDFS) and the map-only portion of MapReduce, and we’ve set up a virtual Hadoop cluster and run a single job on it. Although we are just beginning, we’re already in good shape to learn more about Hadoop.
In the next chapter, you’ll learn about MapReduce jobs—the full power of Hadoop’s processing paradigm. We’ll start by continuing the story of JT and Nannette, and learning more about their next client.
1 Some chimpanzee philosophers have put forth the fanciful conceit of a “paperless” office, requiring impossibilities like a sea of electrons that do the work of a chimpanzee, and disks of magnetized iron that would serve as scrolls. These ideas are, of course, pure lunacy!
2 Sharp-eyed readers will note that this language is really called Pig Latin. That term has another name in the Hadoop universe, though, so we’ve chosen to call it Igpay Atinlay—Pig Latin for “Pig Latin.”
Get Big Data for Chimps now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

