Chapter 4. Introduction to Pig
In this chapter, we introduce the tools to teach analytic patterns in the chapters that comprise Part II of the book. To start, we’ll set you up with chains of MapReduce jobs in the form of Pig scripts, and then we’ll explain Pig’s data model and tour the different datatypes. We’ll also cover basic operations like LOAD and STORE. Next, we’ll learn about UFOs and when people most often report them, and we’ll dive into Wikipedia usage data and compare different projects. We’ll also briefly introduce the different kind of analytic operations in Pig that we’ll be covering in the rest of the book. Finally, we’ll introduce you to two libraries of user-defined functions (UDFs): the Apache DataFu project and the Piggybank.
By the end of this chapter, you will be able to perform basic data processing on Hadoop using Pig.
Pig Helps Hadoop Work with Tables, Not Records
Apache Pig is an open source, high-level language that enables you to create efficient MapReduce jobs using clear, maintainable scripts. Its interface is similar to SQL, which makes it a great choice for folks with significant experience there. It’s not identical, though, and things that are efficient in SQL may not be so in Pig (we will try to highlight those traps).
We use Pig, instead of Hive (another popular Hadoop tool), because it takes a procedural approach to data pipelines. A procedural approach lends itself to the implementation of complex data pipelines as clearly as possible, whereas nested SQL can get confusing, fast. A procedural approach also gives you the opportunity to optimize your data processing as you go, without relying on a magic query analyzer. When used in conjunction with Python, Pig forms the backbone of your data processing, while Python handles more complex operations.
You can run Pig in local mode with the following command:
pig -l /tmp -x local
Let’s dive in with an example using the UFO dataset to estimate whether aliens tend to visit in some months over others:
sightings=LOAD'/data/gold/geo/ufo_sightings/ufo_sightings.tsv.bz2'AS(sighted_at:chararray,reported_at:chararray,location_str:chararray,shape:chararray,duration_str:chararray,description:chararray,lng:float,lat:float,city:chararray,county:chararray,state:chararray,country:chararray);-- Take the 6th and 7th character from the original string,-- as in '2010-06-25T05:00:00Z', take '06'month_count=FOREACHsightingsGENERATESUBSTRING(sighted_at,5,7)ASmonth;-- Group by year_month,-- and then count the size of the 'bag' this creates to get a totalufos_by_month=FOREACH(GROUPmonth_countBYmonth)GENERATEgroupASmonth,COUNT_STAR(month_count)AStotal;STOREufos_by_monthINTO'./ufos_by_month.out';
In a Python streaming or traditional Hadoop job, the focus is on the record, and you’re best off thinking in terms of message passing or grouping. In Pig, the focus is much more on the structure, and you should think in terms of relational and set operations. In the preceding example, each line described an operation on the full dataset; we declared what change to make and Pig, as you’ll see, executes those changes by dynamically assembling and running a set of MapReduce jobs.
To run the Pig job, go into the example code repository and run:
pig examples/ch_04/ufos_by_month.pig
If you consult the Job Browser, you should see a single MapReduce job; the dataflow Pig instructed Hadoop to run is essentially similar to the Python script you ran. What Pig ran was, in all respects, a Hadoop job. It calls on some of Hadoop’s advanced features to help it operate, but nothing you could not access through the standard Java API.
To see the result of the Pig script, run the following:
cat ./ufos_by_month.out/*
You’ll see the following results (also shown in Figure 4-1):
01 4263
02 3644
03 4170
04 4120
05 4220
06 6745
07 7361
08 6641
09 5665
10 5421
11 4954
12 3933
256
Note that 256 records had no such value—data will often surprise you. You might filter these empty values, or look closer at the raw data to see what’s going on. Also, did you notice the output was sorted? That is no coincidence; as you saw in Chapter 2, Hadoop sorted the results in order to group them. Sorting in this case is free! We’ll learn how to explicitly sort data in Pig in a future chapter.
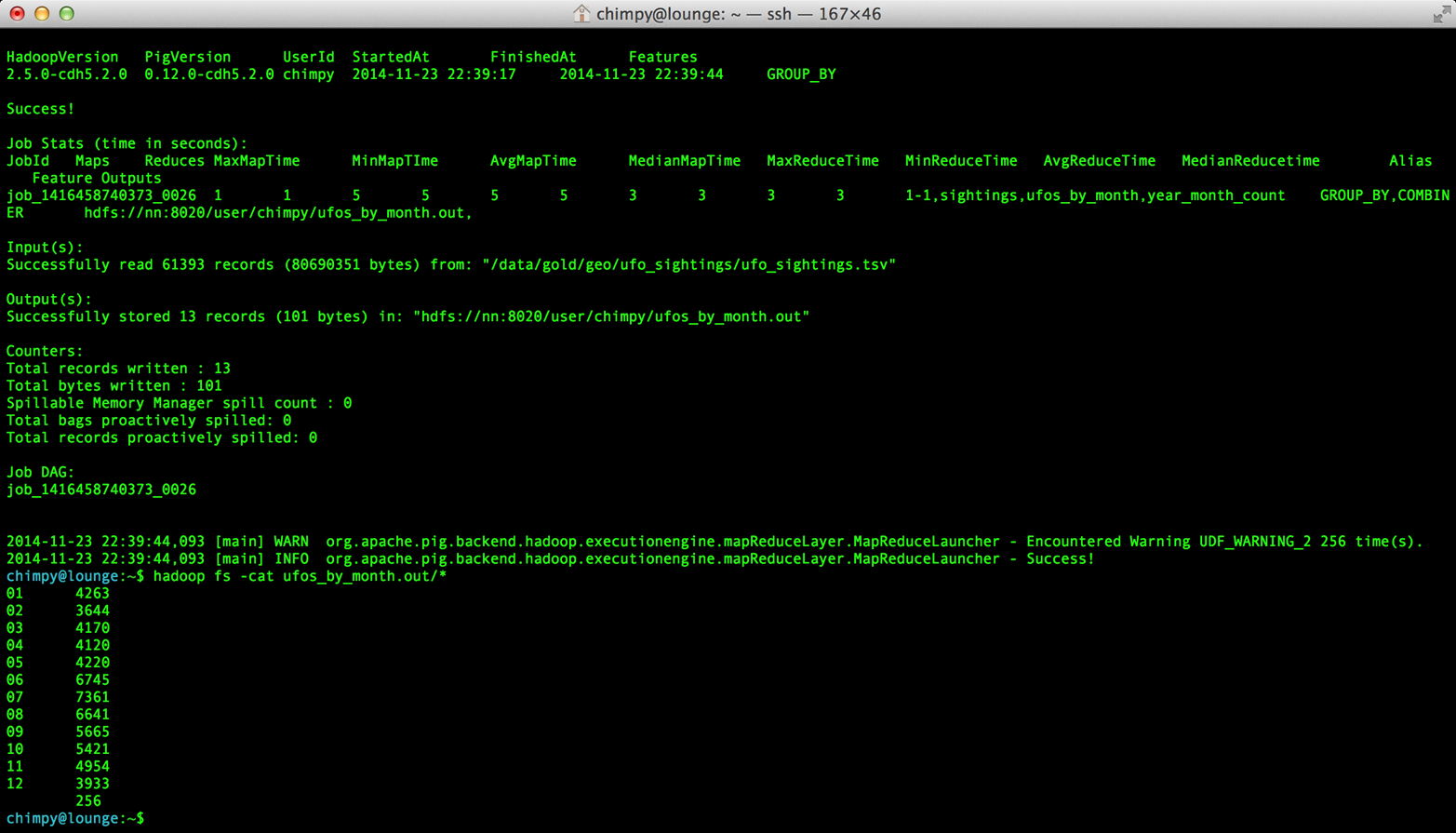
Figure 4-1. Running Pig on our Docker VM
Wikipedia Visitor Counts
Let’s put Pig to a sterner test. Here’s the same script from before, modified to run on the much-larger Wikipedia dataset, and this time to assemble counts by hour:
/* Wikipedia pagecounts data described at https://dumps.wikimedia.org/other/pagecounts-raw/ The first column is the project name. The second column isthe title of the page retrieved, the third column is the number of requests,and the fourth column is the size of the content returned. */-- LOAD the data, which is space-delimitedpageviews=LOAD'/data/rawd/wikipedia/page_counts/pagecounts-20141126-230000.gz'USINGPigStorage(' ')AS(project_name:chararray,page_title:chararray,requests:long,bytes:long);-- Group the data by project name, then count-- total pageviews & bytes sent per projectper_project_counts=FOREACH(GROUPpageviewsBYproject_name)GENERATEgroupASproject_name,SUM(pageviews.requests)AStotal_pageviews,SUM(pageviews.bytes)AStotal_bytes;-- Order the output by the total pageviews, in descending ordersorted_per_project_counts=ORDERper_project_countsBYtotal_pageviewsDESC;-- Store the data in our home directorySTOREsorted_per_project_countsINTO'sorted_per_project_counts.out';/*LOAD SOURCE FILEGROUP BY PROJECT NAMESUM THE PAGE VIEWS AND BYTES FOR EACH PROJECTORDER THE RESULTS BY PAGE VIEWS, HIGHEST VALUE FIRSTSTORE INTO FILE*/
Run the script just as you did in the previous section:
hadoop fs -cat sorted_per_project_counts.out/* | head -10
which should result in a top 10 list of Wikipedia projects by page views:
meta.m 14163318 42739631770 en 8464555 271270368044 meta.mw 8070652 10197686607 en.mw 4793661 113071171104 es 2105765 48775855730 ru 1198414 38771387406 es.mw 967440 16660332837 de 967435 20956877209 fr 870142 22441868998 pt 633136 16647117186
Until now, we have described Pig as authoring the same MapReduce job you would. In fact, Pig has automatically introduced the same optimizations an advanced practitioner would have introduced, but with no effort on your part. Pig instructed Hadoop to use a combiner. In the naive Python job, every mapper output record was sent across the network to the reducer; in Hadoop, the mapper output files have already been partitioned and sorted. Hadoop offers you the opportunity to do preaggregation on those groups. Rather than send every record for, say, September 26, 2014, 8 p.m., the combiner outputs the hour and sum of visits emitted by the mapper.
The second script instructed Pig to explicitly sort the output by total page views or requests, an additional operation. We did not do that in the first example to limit it to a single job. As you will recall from Chapter 3, Hadoop uses a sort to prepare the reducer groups, so its output was naturally ordered. If there are multiple reducers, however, that would not be enough to give you a result file you can treat as ordered. By default, Hadoop assigns partitions to reducers using the RandomPartitioner, which is designed to give each reducer a uniform chance of claiming any given partition. This defends against the problem of one reducer becoming overwhelmed with an unfair share of records, but means the keys are distributed willy-nilly across machines. Although each reducer’s output is sorted, you will see early records at the top of each result file and later records at the bottom of each result file.
What we want instead is a total sort—the earliest records in the first numbered file in order, the following records in the next file in order, and so on until the last numbered file. Pig’s ORDER operator does just that. In fact, it does better than that. If you look at the JobTracker console, you will see Pig actually ran three MapReduce jobs. As you would expect, the first job is the one that did the grouping and summing, and the last job is the one that sorted the output records. In the last job, all the earliest records were sent to reducer 0, the middle range of records were sent to reducer 1, and the latest records were sent to reducer 2.
Hadoop, however, has no intrinsic way to make that mapping happen. Even if it figured out, say, that the earliest buckets were sooner and the latest buckets were later, if we fed it a dataset with skyrocketing traffic in 2014, we would end up sending an overwhelming portion of results to that reducer. In the second job, Pig sampled the set of output keys, brought them to the same reducer, and figured out the set of partition breakpoints to distribute records fairly.
In general, Pig offers many more optimizations beyond these. In our experience, as long as you’re willing to give Pig a bit of coaching, the only times it will author a dataflow that is significantly less performant are when Pig is overly aggressive about introducing an optimization. And in those cases, the impact is more like a bunch of silly piglets making things take 50% longer than they should, rather than a stampede of boars blowing up your cluster. The ORDER BY example is a case in point: for small- to medium-sized tables, the intermediate sampling stage to calculate partitions can have a larger time cost than the penalty for partitioning badly would carry. Sometimes you’re stuck paying an extra 20 seconds on top of each 1-minute job so that Pig and Hadoop can save you an order of magnitude off your 10-minute-and-up jobs.
Fundamental Data Operations
Pig’s operators (and fundamental Hadoop processing patterns) can be grouped into several families: control operations, pipelinable operations, and structural operations.
A control operation either influences or describes the dataflow itself. A pipelinable operation is one that does not require a reduce step of its own: the records can each be handled in isolation, and so they do not have to be expensively assembled into context. All structural operations must put records into context: placing all records for a given key into common context; sorting each record into context with the record that precedes it and the record that follows it; eliminating duplicates by putting all potential duplicates into common context; and so forth.
Pipelinable Operations
With no structural operations, these operations create a mapper-only job with the composed pipeline. When they come before or after a structural operation, they are composed into the mapper or reducer:
-
Transformation operations (
FOREACH,FOREACH..FLATTEN(tuple)) modify the contents of records individually. The count of output records is exactly the same as the count of input records, but the contents and schema of the records can change arbitrarily. -
Filtering operations (
FILTER,SAMPLE,LIMIT,ASSERT) accept or reject each record individually. These can yield the same or a fewer number of records, but each record has the same contents and schema as its input. -
Repartitioning operations (
SPLIT,UNION) don’t change records; they just distribute them into new tables or dataflows.UNIONoutputs exactly as many records as the sum of its inputs. BecauseSPLITis effectively severalFILTERs run simultaneously, its total output record count is the sum of what each of its filters would produce. -
Ungrouping operations (
FOREACH..FLATTEN(bag)) turn records that have bags of tuples into records with each such tuple from the bags in combination. It is most commonly seen after a grouping operation (and thus occurs within the reduce phase) but can be used on its own (in which case, like the other pipelinable operations, it produces a mapper-only job).FLATTENitself leaves the bag contents unaltered and substitutes the bag field’s schema with the schema of its contents. When you are flattening on a single field, the count of output records is exactly the count of elements in all bags (records with empty bags will disappear in the output). MultipleFLATTENclauses yield a record for each possible combination of elements, which can be explosively higher than the input count.
Structural Operations
The following jobs require a map and reduce phase:
-
Grouping operations (
GROUP,COGROUP,CUBE,ROLLUP) place records into context with each other. They make no modifications to the input records’ contents, but do rearrange their schema. You will often find them followed by aFOREACHthat is able to take advantage of the group context.GROUPandCOGROUPyield one output record per distinct GROUP value. -
Joining operations (
JOIN,CROSS) match records between tables.JOINis simply an optimizedCOGROUP/FLATTEN/FOREACHsequence, but it is important enough and different in use that we’ll cover it separately. (The same is true aboutCROSS, except for the “important” part: we’ll have very little to say about it and discourage its use). -
Sorting operations (
ORDER BY,RANK) perform a total sort on their input; every record in file 00000 is in sorted order and comes before all records in 00001 and so forth for the number of output files. These require two jobs: first, a light mapper-only pass to understand the distribution of sort keys, and next a MapReduce job to perform the sort. -
Uniquing and (
DISTINCT, specificCOGROUPforms) select/reject/collapse duplicates, or find records associated with unique or duplicated records. These are typically accomplished with specific combinations of the above, but can involve more than one MapReduce job. We’ll talk more about these later in Chapter 9.
That’s everything you can do with Pig—and everything you need to do with data. Each of those operations leads to a predictable set of map and reduce steps, so it’s very straightforward to reason about your job’s performance. Pig is very clever about chaining and optimizing these steps.
Pig is an extremely sparse language. By having very few operators and a very uniform syntax,1 the language makes it easy for the robots to optimize the dataflow and for humans to predict and reason about its performance.
We will not explore every nook and cranny of its syntax, only illustrate its patterns of use. The online Pig manual is quite good, and for a deeper exploration, consult Programming Pig by Alan Gates. If the need for a construction never arose naturally in a pattern demonstration or exploration,2 we omitted it, along with options or alternative forms of construction that are either dangerous or rarely used.3
In the remainder of this chapter, we’ll illustrate the mechanics of using Pig and the essentials of its control flow operations by demonstrating them in actual use. In Part II, we’ll cover patterns of both pipelinable and structural operations. In each case, the goal is to understand not only its use, but also how to implement the corresponding patterns in a plain MapReduce approach—and therefore how to reason about their performance.
LOAD Locates and Describes Your Data
In order to analyze data, we need data to analyze. In this case, we’ll start by looking at a record of the outcome of baseball games using the LOAD statement in Pig. Pig scripts need data to process, and so your Pig scripts will begin with a LOAD statement and have one or many STORE statements throughout. Here’s a script to find all Wikipedia articles that contain the word Hadoop:
games=LOAD'/data/gold/sports/baseball/games_lite.tsv'AS(game_id:chararray,year_id:int,away_team_id:chararray,home_team_id:chararray,away_runs_ct:int,home_runs_ct:int);home_wins=FILTERgamesBYhome_runs_ct>away_runs_ct;STOREhome_winsINTO'./home_wins.tsv';
Note the output shows us how many records were read and written. This happens to tell us there are 206,015 games total, of which 111,890 (or 54.3%) were won by the home team. We have quantified the home field advantage!
Input(s): Successfully read 206015 records (6213566 bytes) from: "/data/gold/sports/baseball/games_lite.tsv" Output(s): Successfully stored 111890 records (3374003 bytes) in: "hdfs://nn:8020/user/chimpy/home_wins.tsv"
Simple Types
As you can see, in addition to telling Pig where to find the data, the LOAD statement also describes the table’s schema. Pig understands 10 kinds of simple type, 6 of which are numbers: signed machine integers, as int (32-bit) or long (64-bit); signed floating-point numbers, as float (32-bit) or double (64-bit); arbitrary-length integers, as biginteger; and arbitrary-precision real numbers, as bigdecimal. If you’re supplying a literal value for a long, you should append a capital L to the quantity: 12345L; if you’re supplying a literal float, use an f: 123.45f.
The chararray type loads text as UTF-8 encoded strings (the only kind of string you should ever traffic in). String literals are contained in single quotes: 'hello, world'. Regular expressions are supplied as string literals, as in the previous example: '.*[Hh]adoop.*'. The bytearray type does no interpretation of its contents whatsoever, but be careful—the most common interchange formats (tsv, xml, and json) cannot faithfully round-trip data that is truly freeform.
Lastly, there are two special-purpose simple types. Time values are described with datetime, and should be serialized in the ISO-8601 format: 1970-01-01T00:00:00.000+00:00
Boolean values are described with boolean, and should bear the values true or false.
boolean, datetime, and the biginteger/bigdecimal types are recent additions to Pig, and you will notice rough edges around their use.
Complex Type 1, Tuples: Fixed-Length Sequence of Typed Fields
Pig also has three complex types, representing collections of fields. A tuple is a fixed-length sequence of fields, each of which has its own schema. They’re ubiquitous in the results of the various structural operations you’re about to learn. Here’s how you’d load a listing of Major League ballpark locations (we usually don’t serialize tuples, but so far LOAD is the only operation we’ve taught you):
-- The address and geocoordinates are stored as tuples. Don't do that, though.ballpark_locations=LOAD'ballpark_locations'AS(park_id:chararray,park_name:chararray,address:tuple(full_street:chararray,city:chararray,state:chararray,zip:chararray),geocoordinates:tuple(lng:float,lat:float));ballparks_in_texas=FILTERballpark_locationsBY(address.state=='TX');STOREballparks_in_texasINTO'/tmp/ballparks_in_texas.tsv'
Pig displays tuples using parentheses. It would dump a line from the input file as:
BOS07,Fenway Park,(4 Yawkey Way,Boston,MA,02215),(-71.097378,42.3465909)
As shown here, you address single values within a tuple using tuple_name.subfield_name—for example, address.state will have the schema state:chararray. You can also create a new tuple that projects or rearranges fields from a tuple by writing tuple_name.(subfield_a, subfield_b, ...); for example, address.(zip, city, state) will have schema address_zip_city_state:tuple(zip:chararray, city:chararray, state:chararray) (Pig helpfully generated a readable name for the tuple).
Tuples can contain values of any type, even bags and other tuples, but that’s nothing to be proud of. We follow almost every structural operation with a FOREACH to simplify its schema as soon as possible, and so should you—it doesn’t cost anything and it makes your code readable.
Complex Type 2, Bags: Unbounded Collection of Tuples
A bag is an arbitrary-length collection of tuples, all of which are expected to have the same schema. Just like with tuples, they’re ubiquitous yet rarely serialized. In the following code example, we demonstrate the creation and storing of bags, as well as how to load them again. Here we prepare, store, and load a dataset for each team listing the year and park ID of the ballparks it played in:
park_team_years=LOAD'/data/gold/sports/baseball/park_team_years.tsv'USINGPigStorage('\t')AS(park_id:chararray,team_id:chararray,year:long,beg_date:chararray,end_date:chararray,n_games:long);team_park_seasons=FOREACH(GROUPpark_team_yearsBYteam_id)GENERATEgroupASteam_id,park_team_years.(year,park_id)ASpark_years;DESCRIBEteam_park_seasonsSTOREteam_park_seasonsINTO'./bag_of_park_years.txt';team_park_seasons=LOAD'./bag_of_park_years.txt'AS(team_id:chararray,park_years:bag{tuple(year:int,park_id:chararray)});DESCRIBEteam_park_seasons
A DESCRIBE of the data looks like this:
team_park_seasons:{team_id:chararray,park_years:{(year:long,park_id:chararray)}}
Let’s look at a few lines of the relation team_park_seasons:
a = limit team_park_seasons 5; dump a
They look like this:
(BFN,{(1884,BUF02),(1882,BUF01),(1883,BUF01),(1879,BUF01),(1885,MIL02),...})
(BFP,{(1890,BUF03)})
(BL1,{(1872,BAL02),(1873,BAL02),(1874,BAL02)})
(BL2,{(1887,BAL03),(1883,BAL03),(1889,BAL06),(1885,BAL03),(1888,BAL03),...})
(BL3,{(1891,BAL06),(1891,BAL07),(1890,BAL06)})
Defining the Schema of a Transformed Record
You can also address values within a bag using bag_name.(subfield_a, subfield_b), but this time the result is a bag with the given projected tuples. You’ll see examples of this shortly when we discuss FLATTEN and the various group operations. Note that the only type a bag holds is tuple, even if there’s only one field—a bag of just park IDs would have schema bag{tuple(park_id:chararray)}.
It is worth noting the way schema are constructed in the preceding example: using a FOREACH. The FOREACH in the snippet emits two fields of the elements of the bag park_team_years, and supplies a schema for each new field with the AS <schema> clauses.
STORE Writes Data to Disk
The STORE operation writes your data to the destination you specify (typically and by default, the HDFS). The current working directory and your home directory on HDFS is referenced by ./:
STOREmy_recordsINTO'./bag_of_park_years.txt';
As with any Hadoop job, Pig creates a directory (not a file) at the path you specify; each task generates a file named with its task ID into that directory. In a slight difference from vanilla Hadoop, if the last stage is a reduce, the files are named like part-r-00000 (r for reduce, followed by the task ID); if a map, they are named like part-m-00000.
Try removing the STORE line from the preceding script, and run it again. You’ll see nothing happen! Pig is declarative: your statements inform Pig how it could produce certain tables, rather than command Pig to produce those tables in order.
Note that we can view the files created by STORE using ls:
ls ./bag_of_park_years.txt
which gives us:
part-r-00000 _SUCCESS
The behavior of only evaluating on demand is an incredibly useful feature for development work. One of the best pieces of advice we can give you is to checkpoint all the time. Smart data scientists iteratively develop the first few transformations of a project, then save that result to disk; working with that saved checkpoint, they develop the next few transformations, then save it to disk; and so forth. Here’s a demonstration:
great_start=LOAD'...'AS(...);-- ...-- lots of stuff happens, leading up to-- ...important_milestone=JOIN[...];-- reached an important milestone, so checkpoint to disk.STOREimportant_milestoneINTO'./important_milestone.tsv';important_milestone=LOAD'./important_milestone.tsv'AS(...schema...);
In development, once you’ve run the job past the STORE important_milestone line, you can comment it out to make Pig skip all the preceding steps. Because there’s nothing tying the graph to an output operation, nothing will be computed on behalf of important_milestone, and so execution will start with the following LOAD. The gratuitous save and load does impose a minor cost, so in production, comment out both the STORE and its following LOAD to eliminate the checkpoint step.
These checkpoints bring another benefit: an inspectable copy of your data at that checkpoint. Many newcomers to big data processing resist the idea of checkpointing often. It takes a while to accept that a terabyte of data on disk is cheap—but the cluster time to generate that data is far less cheap, and the programmer time to create the job to create the data is most expensive of all. We won’t include the checkpoint steps in the printed code snippets of the book, but we’ve left them in the example code.
Development Aid Commands
Pig comes with several helper commands that assist you in writing Pig scripts, which we will now introduce: DESCRIBE, ASSERT, EXPLAIN, LIMIT..DUMP, and ILLUSTRATE.
DUMP
DUMP shows data on the console, with great peril. The DUMP directive is actually equivalent to STORE, but (gulp) writes its output to your console. That’s very handy when you’re messing with data at your console, but a trainwreck when you unwittingly feed it a gigabyte of data. So you should never use a DUMP statement except as in the following stanza:
dumpable = LIMIT table_to_dump 10; DUMP dumpable;
SAMPLE
SAMPLE pulls a certain ratio of data from a relation. The SAMPLE command does what it sounds like: given a relation and a ratio, it randomly samples the proportion of the ratio from the relation. SAMPLE is useful because it gives you a random sample of your data—as opposed to LIMIT/DUMP, which tends to give you a small, very local sorted piece of the data. You can combine SAMPLE, LIMIT, and DUMP:
-- Sample 5% of our data, then view 10 records from the samplesampled=SAMPLElarge_relation0.05limited=LIMITsampled10;DUMPlimited
ILLUSTRATE
ILLUSTRATE magically simulates your script’s actions, except when it fails to work. The ILLUSTRATE directive is one of our best-loved, and most-hated, Pig operations. When it works, it is amazing. Unfortunately, it is often unreliable.
Even if you only want to see an example line or two of your output, using a DUMP or a STORE requires passing the full dataset through the processing pipeline. You might think, “OK, so just choose a few rows at random and run on that, but if your job has steps that try to match two datasets using a JOIN, it’s exceptionally unlikely that any matches will survive the limiting. (For example, the players in the first few rows of the baseball players table belonged to teams that are not in the first few rows from the baseball teams table.) ILLUSTRATE previews your execution graph to intelligently mock up records at each processing stage. If the sample rows would fail to join, Pig uses them to generate fake records that will find matches. It solves the problem of running on ad hoc subsets, and that’s why we love it.
However, not all parts of Pig’s functionality work with ILLUSTRATE, meaning that it often fails to run. When is the ILLUSTRATE command most valuable? When applied to less widely used operations and complex sequences of statements, of course. What parts of Pig are most likely to lack ILLUSTRATE support or trip it up? Well, less widely used operations and complex sequences of statements, of course. And when it fails, it does so with perversely opaque error messages, leaving you to wonder if there’s a problem in your script or if ILLUSTRATE has left you short. If you, eager reader, are looking for a good place to return some open source karma, consider making ILLUSTRATE into the tool it could be. Until somebody does, you should checkpoint often (as described in “STORE Writes Data to Disk”).
EXPLAIN
EXPLAIN shows Pig’s execution graph. This command writes the “execution graph” of your job to the console. It’s extremely verbose, showing everything Pig will do to your data, down to the typecasting it applies to inputs as they are read. We mostly find it useful when trying to understand whether Pig has applied some of the optimizations you’ll learn about later.
Pig Functions
Pig functions act on fields. Pig wouldn’t be complete without a way to act on the various fields. It offers a sparse but essential set of built-in functions as well as a rich collection of user-defined functions (UDFs) in the Piggybank and the Apache DataFu project. Part II is devoted to examples of Pig and MapReduce programs in practice, so we’ll just list the highlights here:
-
Math functions for all the things you’d expect to see on a good calculator:
LOG/LOG10/EXP,RANDOM,ROUND/ROUND_TO/FLOOR/CEIL,ABS, trigonometric functions, and so forth. -
String comparison:
-
Compare strings directly using
==.EqualsIgnoreCasedoes a case-insensitive match, whileSTARTSWITH/ENDSWITHtest whether one string is a prefix or suffix of the other, respectively. -
SIZEreturns the number of characters in achararray, and the number of bytes in abytearray. Remember that characters often occupy more than one byte: the string Motörhead has 9 characters, but because of its umlauted ö, the string occupies 10 bytes. You can useSIZEon other types, too; but to find the number of elements in a bag, useCOUNT_STARand notSIZE. -
INDEXOFfinds the character position of a substring within achararray.
-
Transform strings:
-
CONCATconcatenates all its inputs into a new string;SPRINTFuses a supplied template to format its inputs into a new string;BagToStringjoins the contents of a bag into a single string, separated by a supplied delimiter. -
LOWERconverts a string to lowercase characters;UPPERto all uppercase. -
TRIMstrips leading and trailing whitespace. -
REPLACE(string, 'regexp', 'replacement')substitutes the replacement string wherever the given regular expression matches, as implemented byjava.string.replaceAll. If there are no matches, the input string is passed through unchanged. -
REGEX_EXTRACT(string, regexp, index)applies the given regular expression and returns the contents of the indicated matched group. If the regular expression does not match, it returnsNULL. TheREGEX_EXTRACT_ALLfunction is similar, but returns a tuple of the matched groups. -
STRSPLITsplits a string at each match of the given regular expression. -
SUBSTRINGselects a portion of a string based on position.
-
-
Datetime functions, such as
CurrentTime,ToUnixTime,SecondsBetween(duration between two given datetimes) -
Aggregate functions that act on bags:
-
Bag functions:
-
Extremal -
FirstTupleInBag -
BagConcat -
Stitch/Over -
SUBTRACT(bag_a, bag_b)returns a new bag having all the tuples that are in the first but not in the second, andDIFF(bag_a, bag_b)returns a new bag having all tuples that are in either but not in both. These are rarely used, as the bags must be of modest size—in general, use an innerJOIN, as described in Chapter 7. -
TOP(num, column_index, bag)selects the topnumof elements from each tuple in the given bag, as ordered bycolumn_index. This uses a clever algorithm that doesn’t require an expensive total sort of the data.
-
-
Conversion functions to perform higher-level type casting:
TOTUPLE,TOBAG,TOMAP
Pig has two libraries that add lots of features: Piggybank and Apache DataFu.
Piggybank
Piggybank comes with Pig—all you have to do to access it is REGISTER /usr/lib/pig/piggybank.jar;. To learn more about Pig, check the Piggybank documentation. At the time of writing, the Piggybank has the following Pig UDFs:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
To use a UDF, you must call on its full classpath. The DEFINE command can help you make a shortcut to the UDF. DEFINE can also add any initialization parameters the UDF requires:
REGISTER/usr/lib/pig/piggybank.jarDEFINEReverseorg.apache.pig.piggybank.evaluation.string.Reverse();b=FOREACHaGENERATEReverse(char_field)ASreversed_char_field;
Apache DataFu
Apache DataFu is a collection of libraries for Pig that includes statistical and utility functions. To learn more about DataFu, check out the website. At the time of writing, Apache DataFu has the following Pig UDFs:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
As in Piggybank, you must register the DataFu JAR and then call on the full classpath of the UDF, or use DEFINE to make a shortcut:
REGISTER/usr/lib/pig/datafu.jarDEFINECOALESCEdatafu.pig.util.Coalesce();b=FOREACHaGENERATECOALESCE(field1,field2)AScoalesced;
Wrapping Up
This chapter was a gentle introduction to Pig and its basic operations. We introduced Pig’s basic syntax: LOAD, STORE, SAMPLE, DUMP, ILLUSTRATE, and EXPLAIN. We listed Pig’s basic operations. We introduced the Apache DataFu and Piggybank libraries of Pig UDFs. Using this knowledge, you can now write and run basic Pig scripts.
We used this new ability to dive in and perform some basic queries: we determined in which months people report the most UFOs, as well as which projects are most popular on Wikipedia. We’ve been able to do a lot already with very basic knowledge!
In the next two chapters, we’ll build on what we’ve learned and see Pig in action, doing more with the tool as we learn analytics patterns.
Get Big Data for Chimps now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

