Chapter 1. Understanding Hypermedia
There is no end to the adventures that we can have if only we seek them with our eyes open.
- Nehru
Designing scalable, flexible implementations that live on the web relies on many concepts, technologies, and implementation details. Understanding the history behind the way the World Wide Web (WWW) works today and the various standards and practices created to support it is an essential part of developing skills as a web architect and hypermedia designer.
In addition to understanding the technologies behind the Web, designers also need to be aware of the differences between implementing applications on a distributed network that leverages coarse-grained message protocols like HTTP that span multiple platforms, programming languages, and storage systems, and more traditional local networked applications where most components in the network share similar storage, programming, and operating details. Programming for distributed hypermedia environments usually means that message transfers must carry more than just data; they must carry additional information including metadata and higher-level application flow control options. The Web thrives on this style of rich hypermedia, and it is important to design APIs that support this method of sharing understanding of the data sent between network participants.
The way in which hypermedia information is shared varies between data formats, but the actual hypermedia concepts—links, templated queries, idempotent updates, etc.—are the same across the Web. Having a clear understanding of the various hypermedia factors that can be expressed within a message is an essential part of developing the skills needed to implement successful hypermedia APIs.
Finally, the implementation details of creating hypermedia types include selecting an appropriate data format and state transfer style, expressing the application domain details properly within the format, and determining the way in which application flow control options are exposed in responses. These basics of hypermedia design are similar regardless of data to be shared or the application domain involved.
This chapter covers some key technologies that make the Web possible, the importance of hypermedia as an architectural approach, and the concepts and details of hypermedia designs. Armed with this understanding the reader will have the tools necessary to build scalable, flexible implementations that do not simply run on the Web but that actually exist in the web in a way that acknowledges, as stated by Richard Taylor, that the “WWW is fundamentally a distributed hypermedia application.”
HTTP, MIME, and Hypermedia
Designing hypermedia applications for the Web is just that: a design process. This process depends on a handful of important standards and technologies. Chief among these are the protocols, message standards, and message content that allows participants to drive the system forward, often toward some designated goal (completing a search, purchasing an item online, etc.).
The most commonly used protocol for transferring content on the Web today is HTTP. Initially designed as a read-only protocol for exchanging HTML documents, HTTP quickly expanded from a file-based transfer protocol into a more generalized protocol that supports both read and write operations across multiple intermediaries that allow real-time negotiation of representation formats for a wide range of information stored on servers.
The ability to represent data instead of just mirror files derives from HTTP’s use of the Multipurpose Internet Mail Extensions (MIME) media type system. Originally created for supporting electronic mail transfers, the MIME typing standard allows HTTP transfers to support a wide range of data formats including ones that are designed specifically for transferring application-related requests such as search parameters and data storage operations. Also important is the built-in ability to support new media types over time in order to support new, unanticipated uses for data transfer on the Web.
The creation of the Web was heavily influenced by the notion of hypermedia and the ability to link related material and easily follow these links in real time. To this end, media types have been designed to natively support hypermedia controls as a way to enable client applications to make selections found within responses and drive the state of the application to the desired outcome. This allows client applications to discover the specific controls within the media type message with which to modify the state of the Web (or at least that client’s view of the Web). It is hypermedia, and the design and implementation of it, that makes the Web a unique and powerful environment for building distributed network applications.
HTTP Is the Transfer Protocol
The first version of HTTP (documented in 1991 as HTTP/0.9) was a simple read-only protocol. It allowed clients to send a request string made up of the letters GET followed by a space and a document address (what we know as a URI today) and servers could then respond by returning the associated document. HTTP/0.9 had no metadata headers and the response was always assumed to be in HTML form.
By 1992, a Basic HTTP (considered a full specification) was documented. This version included several new methods including HEAD, PUT, POST, and DELETE. Other methods such as CHECKIN, CHECKOUT, LINK, UNLINK, SEARCH, and several others are no longer in the specification today. This document included the concept of response codes (1xx, 2xx, 3xx, 4xx, 5xx), an early form of content negotiation, and meta-information (later known as HTTP Headers).
Although the 1992 document was never officially released through a governing body (IETF, etc.), over the next few years, browser clients and web servers extended the read-only features of HTTP/0.9 to include many of the headers and additional request methods identified as Basic HTTP. The results of these additions were documented in 1996 in RFC1945 and named HTTP/1.0. Not long after RFC1945 was released, in January of 1997, HTTP/1.1 was documented and released as RFC2068. This refined many of the implementation details of HTTP as we know it today. An additional update was released in June of 1999 as RFC2616. This is the version of HTTP that is most commonly deployed today.
Throughout the history of specifying HTTP, the protocol was always designed to work as a client-initiated, stateless protocol for transferring messages between parties running over TCP/IP. There are other transfer protocols including FTP, BitTorrent, and rsync, but HTTP has remained the dominant transfer protocol for the Web. This focus on stateless transfer as well as HTTP’s support for negotiating the format used to represent server data (via the Accept and Content-Type headers) are key to understanding how to best utilize HTTP and design efficient and effective applications for the Web. Architects and developers who create applications that run counter to these design principles not only ignore the strengths of HTTP but also add unnecessary complexity and complications to their implementations.
MIME Is the Media Type Standard
HTTP’s standard for defining the body of the message sent between parties is based on the MIME standard (RFC2046). Although this standard was designed to support exchanging messages via email, MIME was adopted by HTTP in order to support the notion of resource representations and to allow for future extensibility.
One of HTTP’s important concepts is the idea that responses are only representations of the actual data. For example, under the FTP (File Transfer Protocol) specifications, the goal is to send an exact copy of the data between parties. However in HTTP, servers are free to represent the data in various ways and clients are encouraged to inform servers which representation formats are preferred. In order to support this additional feature, the MIME standard is used to indicate the current representation format.
HTTP’s support for varying response representations via a media type indicator opens the door to using the message as a key component in web architecture. Messages no longer need to be relegated to simply carrying raw data. Instead, designers and architects can leverage this opportunity to create new message formats and standards that can allow responses and requests to convey not just the raw data, but also metadata about the content. It also means that formats can be created to support very specific purposes independent of the application in use or the data that is transferred between parties.
For example, the same set of data points could be represented for use in a spreadsheet (text/csv), for display in a tabular view (text/html), or as a graphical pie chart display (image/png). Data sent from client to server can be represented as simple name-value pairs (application/x-www-formurlencoded), as plain text (text/plain), or even as part of a multiple-format collection (multipart/form-data).
Note
There are more than a dozen multipart media types registered with the Internet Assigned Numbers Authority (IANA). These types are designed to support multiple unique media types within the same message body, each separated by a boundary. The HTTP/1.1 spec also defines message/http and application/http as similar container media types. These container media types are not covered in this book, but their very existence and use is evidence of flexibility and extensibility of the MIME media type standard.
The reliance on MIME media types also points to an important aspect of HTTP’s message model: it was designed to send coarse-grained messages. Unlike some transfer protocols whose aim is to send the smallest data packets possible, HTTP is concerned with including as much descriptive information as possible with each message, even if this means the message is longer than it needs to be. While there are some efforts underway to reduce message sizes (mostly by shortening or compressing HTTP Headers), designers and architects are free to use the body of the message to carry whatever is deemed important.
This freedom to design new message bodies for HTTP via the MIME standard leads to another unique aspect of the use of HTTP on the Web: in-message hypermedia. HTTP and MIME together make it not only possible, but common to include hypermedia information such as links and forms directly in the body of the response message. It is this ability to include hypermedia controls within messages that makes HTTP so well suited for use in distributed networks like the World Wide Web.
Hypermedia Is the Engine
The concept of hypermedia has been with us for quite a while. Vannevar Bush’s 1945 article “As We May Think” envisioned a device (the “Memex”) that allowed researchers to discover and follow links between topics and phrases in projected documents. Doug Engelbart’s 1968 NLS (oN-Line System), one of the first graphical computer systems, used a new mechanical pointer device dubbed “the mouse” and allowed users to click on links to display related data on the screen. Similar examples of enabling links via computer display cropped up in the 1970s and 1980s. Ted Nelson coined the terms “hypertext” and “hypermedia” in the mid-1960s, and his work “Computer Lib/Deam Machines,” published in 1974, is considered by many to be the first to establish the notion of “surfing the ‘net” and cyberculture in general.
From links to controls
The initial concept for hypermedia was as a read-only link between related items and to this day, this is the most common way hypermedia is used on the Web. For example, many media types only support read-only links between elements. However, with the introduction of graphical user interfaces based on the use of Englebart’s mouse as a way to activate elements of the interface (including buttons), the idea of using links as a way to perform other actions (sending a message, saving data, etc.) became accepted.
The development of HTTP mirrored this development from read-only
(HTTP/0.9) to read/write linking (HTTP/1.0 and 1.1). Along the way,
the de facto media type for HTTP (HTML) developed to include controls
within messages that allowed users to supply arguments and send this
data to remote servers for processing. These hypermedia controls
included the FORM and INPUT
elements among others. This ability to support not only navigational
links (HTML anchor tags) and in-place rendering of related content
(e.g. the IMG tag) but also parameterized queries
and write operations helped HTML be become the lingua
franca of the Web.
Hypermedia types
HTML’s success as a media type on the web is due in large part to its unique status as a media type that supports a wide range of hypermedia controls. Unlike plain text, XML, JSON, and other common formats, HTML has native support for hypermedia. HTML is, in effect, a Hypermedia Type. There are other media types that share this distinction; ones that contain native support for some form of hypermedia linking. Other well-known types include SVG (read-only), VoiceXML, and Atom.
Note
A Hypermedia Type is a media type that contains native hyperlinking elements that can be used to control application flow.
Media types that exhibit native hypermedia controls can be used by client applications to control the flow of the application itself by activating one or more of these hypermedia elements. In this way, hypermedia types become, as Fielding stated, “the engine of application state.” This use of MIME media types to define how data is transferred and also how application flow control is communicated, is an essential aspect to building scalable, flexible applications using HTTP on the Web.
Programming the Web with Hypermedia APIs
Knowing about HTTP, MIME, and hypermedia is the easy part. Using them to design and implement stable, flexible applications on the Web is something else. The Web poses unique challenges to building long-lived applications that can safely evolve over time. Many web developers and architects have experienced these challenges firsthand:
Updating server-side web APIs only to learn that client applications no longer work as expected without undergoing code updates.
Moving long-lived server applications to a new DNS name (e.g. from www.example.org to www.new-example.org) and having to completely rewrite all of the API documentation as well as update all existing client code.
Implementing new or modified process flow within the server-side application and discovering that existing clients break when encountering the new rules, ignore the rules, or, worse, continue to execute their own code in a way that creates invalid results on the server.
These challenges are sometimes mistakenly attributed to the nature of HTTP (the most common transfer protocol in use on the Web to date). However, implementations that rely on SOAP-based messages sent directly over TCP/IP are just as likely to experience the failures listed here. Instead these difficulties, and others like them, stem from the way information is shared between parties on the network.
The most common pattern for crafting and shipping messages is to serialize existing programming objects (e.g. classes and structures) into a common format (XML, JSON, etc.) and send the content to another party. This results in an architecture based on simple data and smart applications. Applications that must be constantly kept in sync with each other to make sure their understanding of the data is always compatible.
This method of marshaling internal types over HTTP can easily lead to brittle and inflexible implementations on the Web. Often, introduction of new arguments for requesting data, new addressees to which requests must be targeted, and/or new data elements in the response messages will cause a mismatch between parties that can only be resolved by reprogramming one or more participants on the network. This is the antithesis of how the Web was designed to work. Reprogramming participants on the Web may be possible when there are only a few parties involved, but it does not scale up to the thousands and millions of participants that interact on the Web today.
In this section, the drawbacks of various forms of type-marshaling are explored and an alternative approach to message design based on hypermedia is identified.
The Type-Marshaling Dilemma
Probably the most common model for web programming today is to serialize internal object types (“customer,” “order,” “product,” etc.) in a common data format (XML, JSON, HTML, etc.) and pass them back and forth between client and server. Most of the available web frameworks encourage this style of programming with built-in serializers and other helpers that make it easy to publish internal objects. Examples of these type-marshaling helpers include schema documents that can be generated from existing source code; run-time services that automatically respond to URIs that include type names; response bodies that contain attributes or elements containing type names to aid in automated serialization selection; and routing rules that use the HTTP Accept and Content-Type headers as object type indicators.
While these patterns are convenient, they had a number of drawbacks. For example, they are very server-centric; they meet the needs of server developers but usually leave client programmers to fend for themselves. Also, by focusing on internal types kept on the server, these patterns introduce risks to client code that is built independent of the server code. Changes to any internal objects can easily introduce changes to public interfaces (shared schema, URIs, payload details, and/or media type definitions).
Below is a short review of each of these popular approaches to sharing data over HTTP along with some commentary on the appeal and shortcomings of these techniques.
Shared schema
Probably the best understood method is to publish a detailed schema document that lists arguments and interaction details. This is the way SOAP was designed to work. The advantage of this approach is that it provides clear description for all parties. The downside is that it most often is used as a way to express the details of private objects (almost always on the server). When these objects change, all previously deployed clients can become broken and must be rebuilt using the newly published schema document. While it is true that this compile-time binding is not a requirement of the SOAP model, to date no major web libraries exist for clients and servers that treat this schema information in a dynamic way that scales for the Internet.
<?xml version="1.0"?>
<definitions name="StockQuote"
targetNamespace="http://example.com/stockquote.wsdl"
xmlns:tns="http://example.com/stockquote.wsdl"
xmlns:xsd1="http://example.com/stockquote.xsd"
xmlns:soap="http://schemas.xmlsoap.org/wsdl/soap/"
xmlns="http://schemas.xmlsoap.org/wsdl/">
<types>
<schema
targetNamespace="http://example.com/stockquote.xsd"
xmlns="http://www.w3.org/2000/10/XMLSchema">
<element name="TradePriceRequest">
<complexType>
<all>
<element name="tickerSymbol" type="string"/>
</all>
</complexType>
</element>
.....
</definitions>URI construction
Another common solution is to try to make the URI carry type information. This is a popular solution since most frameworks can easily generate these URIs from metadata within the source code. This method also makes things relatively easy for frameworks that use templating and other processing based on the type. Of course the biggest drawback is that you lose control of your public URI space. Typing via URIs means private source code decides what your URIs look like and any change to source code threatens to invalidate previously published (and possibly cached) URIs.
http://www.example.org/orders/123 http://www.example.org/customer/big-co/orders/123 http://www.example.org/users/mike/address/home
Payload decoration
Developers who want to remain in control of their URIs can opt
for the another common typing option: decorating the payload. This is
usually done by adding a type element to the JSON or XML body or, in
rare cases, adding a <meta> tag or
profile attribute to HTML documents. This approach
has the distinct advantage of allowing frameworks to sniff the
contents of the payload in order to find the type hint and process the
data accordingly. The primary drawback of this method, however, is
that the payload is now tightly bound to source code and, again,
changes to the source code on the server will modify response payloads
and may invalidate incoming request payloads from clients who have no
idea the server has changed the details of the typed object.
{
"__type":"Circle:#MyApp.Shapes",
"x":50,
"y":70,
"radius":10
}Narrow media types
Another solution is to create a custom public media type for each private object on the server. The advantage here is that you have full control over both the public URI and the payload (although most frameworks link a private class to these custom media types). The downfall of this approach is that it merely pushes the problem along; in this scenario a single application could generate dozens of new media types. It would be an incredible feat for an independent client application to try to keep up with recognizing and parsing the thousands of media types that might be produced in a single year.
...
@PUT
@Consumes("application/stockquote+xml")
public void createStock(Stock stock ) {
...
}
...
@Provider
@Produces("application/stockquote+xml")
Public class StockProvider implements MessageBodyWriter<Stock> {
...
}As is probably evident to the reader, type-marshaling is a difficult challenge for distributed networks where client and server applications are built, modified, and maintained independently, and where public-facing connectors may be expected to be maintained in production for a decade or more. The solutions illustrated above all fall short of supporting this kind of environment because they all suffer from the same flaw: they all attempt to solve the wrong problem.
The question architects and designers of distributed network applications need to ask themselves is not, “How can a server successfully export its private objects in a way that clients can see and use them?” Instead the question that should be asked is, “How can a server and client share a common understanding of the payloads passed between them?”
The short answer is to stop trying to keep clients and servers in sync by working out ways to share private types. Instead what is needed is a technique for describing data in a way that is not bound to any internal type, programming language, web framework, or operating system.
And one answer is to look beyond payloads based on marshaled types and toward payloads based on the principles of hypermedia.
The Hypermedia Solution
Relying on payloads based on hypermedia designs avoids the common pitfalls of the type-marshaling dilemma. That’s because hypermedia payloads carry more information than just the data stored on the server. Hypermedia payloads carry two types of vital metadata: metadata about the data itself and metadata about the possible options for modifying the state of the application at that moment. Both are important to enabling stable and flexible distributed network applications.
By committing to message designs without the constraints of a particular internal type system, designers are free to craft payloads to more directly address the needs of the problem domain. By creating messages that contain not just data points but also information about the data (e.g. shared labels, hierarchies and relationships), both client and server can increase the shared understanding of the information passed between them.
Finally, by crafting responses that include data (and its metadata); information about the current state of the application itself; and possible transitions available at the present moment, distributed network applications can offer interfaces—interfaces that take advantage of new state transitions and new information flows that may appear over the lifetime of the application—to both human and machine-driven agents. This type of message design places stability and flexibility at the forefront of the architecture.
Metadata about the data
Hypermedia messages contain not only the data requested but also metadata. To make this point clear, consider a server that offers data on users defined for a network application. The server might return the data in the following form:
darrel,admin,active mike,manager,suspended ... whartung,user,pending
Note that the data contains no descriptive information, or no metadata. This works if both the client and server have a complete shared understanding over all the possible requests and responses ahead of time. It works if a human is assumed to be able to infer the missing details. However, in a distributed network where independent individuals might be able to create new applications to access this same data—individuals that might not know all of the details of every shared request and response—this raw data can be a problem.
Hypermedia designs can send additional metadata that describes the raw data. Here is the same data marked up using the HTML hypermedia format:
...
<ul class="users">
<li class="user">
<a href="..." rel="user">darrel</a>
<span class="role">admin</span>
<span class="status">active</span>
</li>
<li class="user">
<a href="..." rel="user">mike</a>
<span class="role">manager</span>
<span class="suspended">suspended</span>
</li>
...
<li class="user">
<a href="..." rel="user">whartung</a>
<span class="role">user</span>
<span class="suspended">pending</span>
</li>
</ul>
...The example here is simplistic (this is just one possible way to add metadata to the reponse), but it conveys the idea. Hypermedia designs include more than raw data; they include metadata in a form easily consumed by both humans and machines. The details of selecting an appropriate data format to carry the metadata is part of the design process that will be explored later in this chapter (see Hypermedia Design Elements).
Metadata about the application
Marking up the raw data is only part of the process of designing hypermedia. Another important task is to include metadata about the state of the application itself. It is the availability of application metadata in the message that turns an ordinary media type into a hypermedia type. This metadata provides information to clients on what possible actions can be taken (“Can I create a new record?”, “Can I filter or sort the data?”, etc.). This kind of application metadata allows the client to modify the state of the application, and to drive the application forward in a way that gives the client the power to add, edit, and delete content, compute results, and submit filters and sorts on the available data. This is hypermedia. This is the engine of application state to which Fielding refers in his dissertation.
Below are some examples of application metadata in an HTML message. You can see a list of users (as in the previous example) along with navigation, filtering, and search options that are appropriate for this response (and the identified user making the request).
...
<ul class="users">
<li class="navigation">
<a href="..." rel="next-page">next-page</a>
</li>
<li class="navigation">
<a href="..." rel="last-page">last-page</a>
</li>
<li class="user">
<a href="..." rel="user">darrel</a>
<span class="role">admin</span>
<span class="status">active</span>
</li>
<li class="user">
<a href="..." rel="user">mike</a>
<span class="role">manager</span>
<span class="suspended">suspended</span>
</li>
<li class="user">
<a href="..." rel="user">whartung</a>
<span class="role">user</span>
<span class="suspended">pending</span>
</li>
...
</ul>
<!-- defined filters -->
<ul class="queries">
<li class="query"><a href="..." rel="admins">admins</a></li>
<li class="query"><a href="..." rel="pending">pending</a></li>
<li class="query"><a href="..." rel="suspended">suspended</a></li>
...
</ul>
<!-- user search -->
<form name="user-search" action="...">
<input name="search-name" value="" />
<input type="submit" />
</form>
...As can be seen in this example, a set of HTML anchor tags and an HTML form have been included in the server’s response. This information lets the client application know that there are ways to navigate through the list, filter the data, and search it by username. Note that the navigation links only include “next” and “last” options since “previous” and “first” are not appropriate at the start of the list. Good hypermedia designs make sure the application metadata is context-sensitive. Just as human users can become confused or frustrated when offered too many options, quality hypermedia design includes making decisions on the most appropriate metadata to provide with each response.
Note
Most of the examples in this section use the HTML media type, a well-known format. But HTML is not the only possible way to provide hypermedia to clients. In fact, HTML is lacking in some key hypermedia elements that might be important in your use cases. There are a handful of hypermedia elements that you can use to express application metadata. HTML has many; others appear in different media types. In order to allow clients to drive the application state, these elements must appear within the server responses. Fielding calls these “affordances.” In this book they are called “Hypermedia Factors.” These factors are the building blocks for hypermedia APIs.
Summary
This section identifies one of the common pitfalls of implementing applications on the Web: the type-marshaling dilemma. Many web applications today suffer from this problem, often because the programming languages, frameworks, and editors in use today encourage it. However, a more stable and flexible approach is available using hypermedia-rich messages as the primary way to share understanding between clients and servers. Unlike data-only messages based on type-marshaling, hypermedia messages contain the raw data, metadata about that data, and metadata about the state of the application.
The next section describes a set of abstract factors that make up a set of building blocks for designing hypermedia messages. These building blocks are called H-Factors.
Identifying Hypermedia : H-Factors
Designing hypermedia messages involves deciding how to represent the requested data (including metadata about the requested data) as well as deciding how to represent application metadata such as possible filters, searches, and options for sending data to the server for processing and storage. The details of representing the application metadata is handled by hypermedia elements within the message. The actual message elements, attributes, etc. used to represent these options vary depending on the base format and the registered media type in use. However, despite these variances, the abstract options represented are the same across all media types and format. These are referred to in this book as “Hypermedia Factors” or “H-Factors.”
| Links | LE | Embed Links |
| LO | Outbound Links | |
| LT | Templated Links | |
| LI | Idempotent Links | |
| LN | Non-Idempotent Links | |
| Control Data | CR | Read Controls |
| CU | Update Controls | |
| CM | Method Controls | |
| CL | Link Annotation Controls |
There are nine H-Factors, and they can be placed into two groups: link factors (represented as LO, LE, LT, LI, and LN) and control factors (represented as CR, CU, CM, and CL). The five link factors denote specific linking interactions between client and server: Outbound, Embedded, Templated, Idempotent, and Non-Idempotent. The remaining four control factors provide support for customizing metadata details (e.g. HTTP Headers) of the hypermedia interaction: Reads, Updates, Method, and Link Annotations.
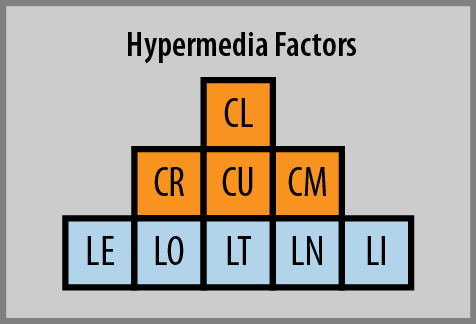
Each of the H-Factors provide unique support for hypermedia designs. In this way, H-Factors are the building blocks for adding application hypermedia to messages. It is not important that your design use every one of these factors. In fact, to date, there is no widely used hypermedia design that incorporates all of these factors. What is important, however, is knowing the role each factor plays and how it can be used to meet the needs of your particular implementation.
Below are brief descriptions of each of these factors along with examples from existing media types and formats.
Link Factors
Link factors represent opportunities for a client to advance the state of the application. This is done by activating a link. Some links are designed to update a portion of the display content with new material (LE) while other links are used to navigate to a new location (LO). Some links allow for additional inputs for read-only operations (LT), and some links are designed to support sending data to the server for storage (LI and LN).
Below are examples of each of the link factors identified here.
Embedding Links (LE)
The LE factor indicates to the client application that the accompanying URI should be de-referenced using the application level protocol’s read operation (e.g. HTTP GET), and the resulting response should be displayed within the current output window. In effect, this results in merging the current content display with that of the content at the other end of the resolved URI. This is sometimes called transclusion. A typical implementation of the LE factor is the IMG markup tag in HTML:
<img src="..." /> In the above example, the URI in the src
attribute is used as the read target and the resulting response is
rendered inline on the web page.
In XML, the same LE factor can be expressed using the
x:include element:
<x:include href"..." />
Outbound Links (LO)
The LO factor indicates to the client application that the accompanying URI should be de-referenced using the application level protocol’s read operation, and the resulting response should be treated as a complete display. Depending on additional control information, this may result in replacing the current display with the response or it may result in displaying an entirely new viewport/window for the response. This is also known as a traversal or navigational link.
An example of the LO factor in HTML is the A markup tag:
<a href="...">...</a>
In a common web browser, activating this control would result in replacing the current contents of the viewport with the response. If the intent is to indicate to the client application to create a new viewport/window in which to render the response, the following HTML markup (or a similar variation) can be used:
<a href="..." target="_blank">...</a>Templated Links (LT)
The LT factor provides a way to indicate one or more parameters that can be supplied when executing a read operation. Like the LE and LO factors, LT factors are read-only. However, LT factors offer additional information in the message to instruct clients on accepting additional inputs and including those inputs as part of the request.
The LT element is, in effect, a link template. Below is an
example LT factor expressed in HTML using the FORM markup
tag:
<form method="get" action="http://www.example.org/"> <input type="text" name="search" value="" /> <input type="submit" /> </form>
HTML clients understand that this LT requires the client to perform URI construction based on the provided inputs. In the example above, if the user typed “hypermedia” into the first input element, the resulting constructed URI would look like this:
http://www.example.org/?search=hypermedia
The details on how link templates (LT) are expressed and the rules for constructing URIs depends on the documentation provided within the media type itself.
Templated links can also be expressed directly using tokens within the link itself. Below is an example of a templated link using specifications from the URI Template Internet Draft:
<link href="http://www.example.org/?search={search}" />Idempotent Links (LI)
The LI factor provides a way for media types to define support
for idempotent submissions to the server. These types of requests in
the HTTP protocol are supported using the PUT and DELETE methods.
While HTML does not have direct support for idempotent submits within
markup (e.g. FORM method="PUT"), it is possible to
execute idempotent submits within an HTML client using downloaded
code-on-demand.
<script type="text/javascript">
function delete(id)
{
var client = new XMLHttpRequest();
client.open("DELETE", "http://example.org/comments/"+id);
}
</script>The Atom media type implements the LI factor using a link
element with a relation attribute set to “edit”
(rel="edit"):
<link rel="edit" href="http://example.org/edit/1"/>Clients that understand the Atom specifications know that any link decorated in this way can be used for sending idempotent requests (HTTP PUT, HTTP DELETE) to the server.
Non-Idempotent Links (LN)
The LN factor offers a way to send data to the server using a non-idempotent “submit.” This type of request is implemented in the HTTP protocol using the POST method. Like the LT factor, LN can offer the client a template that contains one or more elements that act as a hint for clients. These data elements can be used to construct a message body using rules defined within the media type documentation.
The HTML FORM element is an example of a
non-idempotent (LN) factor:
<form method="post" action="http://example.org/comments/"> <textarea name="comment"></textarea> <input type="submit" /> </form>
In the above example, clients that understand and support the HTML media type can construct the following request and submit it to the server:
POST /comments/ HTTP/1.1 Host: example.org Content-Type: application/x-www-form-urlencoded Length: XX comment=this+is+my+comment
It should be noted that the details of how clients compose valid payloads can vary between media types. The important point is that the media type identifies and defines support for non-idempotent operations.
Control Factors
Control factors provide support for additional metadata when executing link operations. The possible metadata elements (and their values) can vary between supported protocols (FTP, HTTP, etc.) as does the details for communicating this link metadata. For example, in HTTP, this is accomplished through HTTP Headers. Regardless of the mechanism, control factors fall into four categories: Read, Update, Method, and Link Annotation.
What follows is a brief discussion of Control Factors along with examples.
Read Controls (CR)
One way in which media types can expose control information to
clients is to support manipulation of control data for read operations
(CR). The HTTP protocol identifies a number of HTTP Headers for
controlling read operations. One example is the
Accept-Language header. Below is an example of XInclude
markup that contains a custom accept-language
attribute:
<x:include href="http://www.exmaple.org/newsfeed" accept-language="da, en-gb;q=0.8, en;q=0.7" />
In the example above, the hypermedia type adopted a direct
mapping between a control factor (the accept-language XML
attribute) and the HTTP protocol header
(Accept-Language). There does not need to be a direct
correlation in names as long as the documentation of the hypermedia
design provides details on how the message element and the protocol
element are associated.
Update Controls (CU)
Support for control data during send/update operations (CU) is
also possible. For example, in HTML, the FORM can be
decorated with the enctype attribute. The value for this
attribute is used to populate the Content-Type header
when sending the request to the server.
<form method="post" action="http://example.org/comments/" enctype="text/plain"> <textarea name="comment"></textarea> <input type="submit" /> </form>
In the above example, clients that understand and support the HTML media type can construct the following request and submit it to the server:
POST /comments/ HTTP/1.1 Host: example.org Content-Type: text/plain Length: XX this+is+my+comment
Method Controls (CM)
Media types may also support the ability to change the control
data for the protocol method used for the request. HTML exposes this
CM factor via the method attribute of the
FORM element.
In the first part of the example below, the markup indicates a send operation (using the POST method). The second part uses the same markup with the exception that the GET method is indicated. This second example results in a read operation:
<!-- update operation --> <form method="post" action="..." /> <input name="keywords" type="text" value="" /> <input type="submit" /> </form> <!-- read operation --> <form method="get" action="..." /> <input name="keywords" type="text" value="" /> <input type="submit" /> </form>
Link Annotation Controls (CL)
In addition to the ability to directly modify control data for read and submit operations, media types can define CL factors that provide inline metadata for the links themselves. Link control data allows client applications to locate and understand the meaning of selected link elements with the document. These CL factors provide a way for servers to “decorate” links with additional metadata using an agreed-upon set of keywords.
For example, Atom documentation identifies a list of registered
Link Relation Values that clients may encounter within responses.
Clients can use these link relation values as explanatory remarks on
the meaning and possible uses of the provided link. In the example
below, the Atom entry element has a link child element with a link
relation attribute set to “edit” (rel="edit"):
<entry xmlns="http://www.w3.org/2005/Atom"> <title>Atom-Powered Robots Run Amok</title> <id>urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a</id> <updated>2003-12-13T18:30:02Z</updated> <author><name>John Doe</name></author> <content>Some text.</content> <link rel="edit" href="http://example.org/edit/1"/> </entry>
Clients that understand the Atom and AtomPub specifications know (based on the documentation) that the URI value of links decorated in this way can be used when executing idempotent submits (HTTP PUT, HTTP DELETE) to the server.
Another example of using CL factors is HTML’s use of the
rel="stylesheet" directive:
<link rel="stylesheet" href="..." />
In the above example, the client application (web browser) can
use the URI supplied in the href attribute as the source
of style rendering directives for the HTML document.
Summary
This section has identified a limited set of elements (H-Factors) that describe well-known protocol-related operations. These operations make up a complete set of hypermedia factors. These factors can be found, to some degree, in media types designed to support hypermedia on the Web. H-Factors are the building blocks for designing your own hypermedia APIs.
Hypermedia Design Elements
Along with knowing the set of hypermedia factors that can be expressed within a message, there are a number of basic design elements that need to be addressed when authoring hypermedia types. These elements are:
- Base Format
Every hypermedia design relies on a base-level message format; it’s the format that is used to express the hypermedia information. Typical base formats for hypermedia messages sent over HTTP are XML, JSON, and HTML. They each have their advantages and limitations, which will be covered in this section. It is also possible to design hypermedia types using other base formats (CSV, YAML, Markdown, Binary formats, etc.), but this book does not cover these additional base formats.
- State Transfer
Many hypermedia types allow client-initiated state transfer (sending data from the client to the server). In Identifying Hypermedia : H-Factors, several hypermedia factors were identified as supporting state transfer. Hypermedia designs typically have three styles of state transfer: None (i.e. read-only), Predefined (via external documentation), and Ad-Hoc (via in-message hypermedia controls).
- Domain Style
Hypermedia designs usually express some level of domain affinity. In this context, “domain” refers to the application domain, or the problem space. Domain styles can be categorized as Specific, General, or Agnostic.
- Application Flow
Hypermedia designs may also contain elements that express possible application flow options. This allows client applications to recognize and respond to possible options that allow for advancing the application through state transitions at the appropriate times. Application Flow styles for hypermedia can be identified as None, Intrinsic, or Applied.
These hypermedia design elements (minus the Base Format element) can be viewed as a matrix. (See Figure 1-2.)
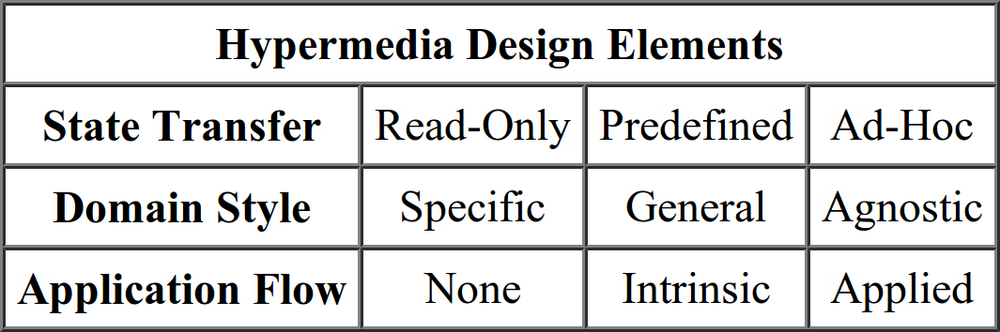
All hypermedia types can be inspected for these design elements (Format, State Transfer, Domain Style, and Application Flow) and their values identified. In this way, you can analyze existing hypermedia types and use the same information in making selections for your own hypermedia type designs.
Note
Just as the previous section (Identifying Hypermedia : H-Factors) identified a set of factors or building blocks for hypermedia, this section describes a set of design elements or techniques for applying those factors to a hypermedia design.
The following sections explore each of these design elements, provide examples, and offer some guidance on their use in your hypermedia designs.
Base Format
A critical element in any hypermedia design is the base-level message format. As of this writing, the most often used formats over HTTP are XML, JSON, and HTML. This section explores the advantages and limitations of these common formats.
XML
The XML media type is a common base format for designing hypermedia. There are several advantages to using XML as your base format. First, XML is a mature format and there are a number of supporting technologies including transformation (XSLT), querying (XPath, XQuery), validation (XSD, Schematron), and even transclusion (XPointer, XInclude). XML data types are also standardized. Even better, almost all programming environments support these technologies in a consistent way. It’s safe to bet that you can count on XPath to work the same way across platforms and languages.
Another nice aspect of XML is its element + attribute design. Designers can take advantage of this pattern in many ways, including using elements to define top-level data descriptors in the media type, and attributes as additional or metadata items.
One of the drawbacks of XML is that the original media type contains no native H-Factors: no predefined links, forms, etc. There are some related XML standards (XLink, XForms) that can be applied, but these may or may not be exactly what the use case requires and these additional standards may not be widely supported on all target platforms.
However, if your use cases require strong standardized support for your hypermedia type across a wide range of platforms and environments, XML can be an excellent choice as a base format.
JSON
The rise of the HTTP web as a platform has brought with it an increased use of JavaScript. Today it is possible to find JavaScript as the default programming language for clients (web browsers), servers (Node.js), data storage (CouchDB) and more. JavaScript’s language model supports a very simple and portable data structure based on name-value pairs and lists called JSON. This data structure has been standardized, and parsers are available for a wide range of languages outside JavaScript, too. Another advantage of JSON is that it is a very terse format. For example, unlike XML, whose design can end up using more bytes for element names than for the data these elements describe, JSON has relatively low overhead and this can make messages very small and easy to move about.
While JSON is a standard, it is still relatively new. There are no RFC-level standards for querying and validating JSON although there are some commonly used approaches. For example, JSONPath is a query pattern similar to XPath and JSON Schema provides an XSD-like validator service to JSON. Finding implementations of JSONPath and JSON Schema may be difficult for environments where JavaScript is not the chosen programming language.
Another downside for using JSON is that, like XML, JSON has no native H-Factors and there are no established standards to rely upon for expressing links and forms. Designing a hypermedia type with JSON requires the definition of all the H-Factor elements from scratch, including figuring out the best way to express control data information such as language preferences and protocol method names, etc.
Despite these drawbacks, if your target audience is made up of web browsers and other environments where JavaScript is common, JSON may be a good fit as the base format for your hypermedia type design.
HTML
HTML can be an excellent choice as a base format for your hypermedia design for a number of reasons. First, it is a mature and stable technology that is more than twenty years old. Second, HTML has one of the most ubiquitous client applications (common web browsers) available on almost any platform. Third, browsers support code-on-demand via JavaScript, which adds a power dimension to delivering hypermedia via HTML.
However, HTML (and its cousins, XHTML and HTML5) is often overlooked when designing hypermedia types for a use case. This is probably because HTML suffers from an unfair assumption that it is an old-school, bloated technology appropriate only for cases where a human is driving a web browser client.
HTML does have some drawbacks. As of this writing, HTML still only supports a subset of the HTTP method set (GET, HEAD, and POST). If your use case relies on using HTTP PUT and/or DELETE, plain HTML will not be a good fit. One of the biggest downsides to using HTML as your base format is that it is domain-agnostic (see Agnostic). That means it can be a bit more work to define elements and attributes that match closely to your application domain, but it is certainly possible, as you will see in Chapter 4.
But these limitations are usually outweighed by the advantages of HTML. HTML is the only base format considered here that has a rich set of native hypermedia controls to support LO H-Factors (via links), and LT and LN H-Factors (via forms). Since web browsers can easily render HTML links and forms, defining your hypermedia API using HTML usually means that humans can easily surf your API[1] by stepping through the HTML as it is rendered in a browser. There are now a number of libraries capable of parsing HTML, XHTML, and HTML5 that are available for several platforms and environments. That means it is relatively easy to use HTML for use cases that do not require web browsers (e.g. command-line tools, desktop applications, etc.).
Since HTML can be used in wide number of client environments including web browsers, HTML can be a very good choice as a base format for your hypermedia designs.
Others
As mentioned at the start of the section, XML, JSON, and HTML are not the only possible base formats for hypermedia designs. Markdown, YAML, CSV, even binary formats (i.e. Protocol Buffers) can be used in hypermedia designs. However, many of these formats lack not only native hypermedia controls, but the document structure needed to define them. For example, XML offers element names and attributes to hold your application-specific metadata. JSON has hash tables and arrays that can be given meaningful names to match your application domain. HTML has a number of attributes especially designed to hold domain-specific information. Most of the alternate base formats mentioned here do not have these types of allowances. For the purposes of this book, attention will remain on the three most commonly used base formats today. If your use case calls for supporting hypermedia using one of these other formats, you may have some additional challenges, but you should still be able to apply the same design ideas shown here.
State Transfer
Another key aspect of hypermedia design is supporting the transfer of information (i.e. state) from the client to the server. This client-initiated state transfer is really the heart of hypermedia messaging. There are many media type designs focused on efficient transfer of data from servers to clients, but not many do a good job of defining how clients can send data to servers. In some cases, read-only designs are appropriate for the task. For example, bots that search for and index specific data on the Web usually have no reason to send data to other servers. However, in cases where client applications are expected to collect inputs (e.g. from human users or by other means) and store them on a remote server; these same client applications will need to know how to locate and use hypermedia-enabled link controls (the LT, LI, and LN H-Factors).
For the purposes of this book, we can divide the work of expressing client-initiated state transfer for hypermedia types into three types: read-only, predefined, and ad-hoc.
Read-only
As was already mentioned, there are a number of scenarios where hypermedia types do not need to support client-initiated state transfers. In these cases, the media types are, essentially, read-only. That does not mean that the messages are devoid of hypermedia controls. For example, the SVG SVG11 media type is a read-only design that uses outbound links (LO) and embedding links (LE). The CSS media type supports the LE H-Factor.
If your use case does not require clients to transfer data directly to servers, using a media type design that supports no client-initiated state transfer is a perfectly valid design choice.
Predefined
Another common approach to handling client-initiated state transfer is to rely on predefined transfer bodies that clients learn and then use when indicated. Media types that rely on this design pattern usually provide documentation detailing the required and/or optional elements for valid transfers, encoding rules, etc. The AtomPub (RFC5023) protocol relies on predefined state transfers to support creating and updating resources via the Atom (RFC4287) media type.
Note
The AtomPub/Atom RFC pair is an interesting example of one RFC defining the format (RFC4287) and another, related RFC defining the state-transfer rules (RFC5023).
One of the advantages of using predefined state transfers is that client-coding can be relatively straightforward. Client applications can be pre-loaded with the complete set of valid state transfer bodies along with rules regarding required elements, supported data types, message encoding, etc. The only remaining task is to teach clients to recognize state transfer opportunities with response messages, and to know which transfer body is appropriate.
In the case of the AtomPub protocol, there are two basic client-initiated state transfers defined in the specification:
- Entry resources
These transfers represent entries in an Atom feed document and can be treated as a stand-alone resource.
- Media resources
These transfers support binary uploads (images, etc.) to the server that are automatically associated with an Entry Resource.
The details on how clients can recognize when state transfers
are supported (e.g. identifying predefined rel attributes
on link elements), how clients should compose valid state
transfer requests (e.g. which protocol method to use, etc.), and how
servers should respond to these requests are outlined in the AtomPub
RFC.
In cases where your media type only needs to support a limited set of possible state transfers from the client, it can be a good design choice to define these state transfer bodies within documentation and encourage client applications to embed the rules for handling this limited set directly in the client code.
Ad-Hoc
A very familiar method for handling client-initiated state
transfers is to use an ad-hoc design pattern. In this pattern, the
details about what elements are valid for a particular state transfer
are sent within the hypermedia message itself. Since each message can
have one or more of these control sets, clients must not only know how
to recognize the hypermedia controls but also how to interpret the
rules for composing valid transfers as they appear. The HTML media
type relies on this ad-hoc design pattern using the form,
input, and other elements to support LT and LN link
H-Factors.
The primary advantage of adopting the ad-hoc style is flexibility. Document authors are free to include any number of transfer elements (inputs) needed to fulfill the immediate requirements. This also means that client applications must be prepared to recognize and support the state transfer rules as they appear in each response.
Warning
For human-driven clients, ad-hoc state transfers can be handled by rendering the inputs and waiting for activation. However, for clients that have no human to intervene, the ad-hoc style can be an added challenge. If your primary use case is for automated client applications, the ad-hoc state transfer style may not be the best design choice.
The HTML documentation identifies the hypermedia elements (e.g.
form, input, select,
textarea, etc.) that client applications should support
along with encoding rules on how to convert values associated with
these controls into valid state transfer bodies. Once client
applications know how to handle the designated elements, they will be
prepared to handle a wide range of hypermedia messages.
If your use case requires the power and flexibility of ad-hoc state transfers, this is probably the best choice for your media type design.
Domain Style
Hypermedia designs usually express some level of domain affinity. In this context, “domain” refers to the application domain, or the problem space. The process of selecting element and attribute names, deciding where hierarchies should exist, and so on, is the essence of translating the problem domain into message form. Modeling the problem domain focuses on the information that needs to be shared, stored, computed, etc. There are many ways to accomplish this task, and the common approach is to model domain data by declaring meaningful elements and/or attributes. These elements are then passed between parties where they can be processed, computed, stored, and passed again when requested. Achieving a desirable domain model for messaging is the art of hypermedia design.
The closer a design is to modeling the problem space, the easier it is to use the design to accurately express important activities over a distributed network. However, the more closely tied a message design is to a single problem domain, the less likely it is that the design can be applied to a wide range of problems. This balance between specificity and generality is at the core of hypermedia design.
It can be helpful to view this issue (like others covered here) in three broad categories: specific, general, and agnostic.
Specific
It is very common to use a very domain-specific design when creating a custom message. Domain-specific designs usually incorporate name and collection patterns that exist within the problem space itself. For example, consider a typical design for an Order in a message:
<!-- domain-specific design --> <order> <id>...</id> <shipping-address>...</shipping-address> <billing-address>...</billing-address> ... </order>
In the example shown above, it is very easy to identify the domain-specific elements (order, order-id, customer-name, shipping-address, etc.). The primary advantage of a domain-specific design is that it is easy for humans working with the design to determine the meaning and infer the use of the various elements. This is one the many reasons XML is a popular format for custom message implementations: XML does an excellent job of supporting domain-specific designs.
There are drawbacks to this style of message design, too. The more specific your design, the more closely tied it is to a single problem domain. If your problem domain is quite large, your message design becomes very large, too. If your domain space changes frequently over time, your message design must do the same. Finally, if your problem domain is rather small and very specific, it’s not likely that your design can be applied to many other use cases.
If your domain space is well-established and stable (not likely to change over time) or if your use case is relatively short-lived, domain-specific style designs can be a good choice.
General
An alternate approach to domain-specific designs is to adopt a domain-general style. In this style, elements are given generally understood names. Optionally, elements are decorated with attributes that qualify the general name with something more domain-specific. In this way, general style designs strike a balance between specificity and generality.
Here is one possible domain-general style design for the Order message shown earlier:
/* domain-general design */
{
"order":
{
"id" : "...",
"address" : {"type" : "shipping", "street-address" : "..."},
"address" : {"type" : "billing", "street-address" : "..."}
}
}You can see that the domain-specific address elements from the first example have been replaced by general “address” elements carry a “type” indicator to provide additional domain-specific information. The advantage of this design style is that the “address” elements could be applied to many other use cases within the problem domain (customer address, user address, supplier address, etc.) without having to modify the actual message design itself. In this way, your design takes on a level of modularity and reuse that makes supporting new domain-specific elements easier over time. In addition, client applications can create code that: 1) supports reusing these modular elements of your message design, and 2) is able to adjust to evolving use cases in the domain space more easily.
There are still downsides to this approach. First, creating domain-general designs adds a level of indirection to implementations. It usually takes more coding logic to parse both the element (“address”) and the domain-specific indicator (“type”). This can make finding the right address element in a particular message a bit more complicated. On the other hand, domain-general messages can still suffer from enough specificity to limit their wide use and adoption.
Warning
Care should be taken when employing a domain-general style since it is possible to design a message that takes on the limitation and frustrations of both domain-specific and domain-agnostic styles.
In cases where your domain has a core set of reusable elements and relatively simple messages that are not likely to make for complicated parsing due to a high level of reuse in the same message, a domain-general approach can be the best selection.
Agnostic
The most flexible and evolveable domain style is domain-agnostic. In this style, all the element names are generic (i.e. “data” or “item,” etc.) and there is a strong reliance on context-setting values (usually attributes) to establish the meaning of these generic elements. The following example of a domain-agnostic design should look familiar to the reader:
<!-- domain-agnostic design -->
<ul class="order">
<li class="id">...</li>
<ul class="shipping-address">
<li class="street-address">...</li>
...
</ul>
<ul class="billing-address">
<li class="street-address">...</li>
...
</ul>
...
</ul>The primary advantage of the domain-agnostic style is that you
can usually express a wide range of domain-specific information using
every few elements. A domain-agnostic message design can usually get
by with just a few key elements used to express collections,
individual items in a collection, and one or more properties of a
single item. The trick to designing domain-agnostic messages is to
employ a rich set of decorators (attributes) that can be applied to
almost any element in the design. HTML, for example, supports the
id and class attributes on almost all
elements. HTML also uses the name and rel
attributes on key state transition elements.
Note
An important aspect of HTML design is that some decorators
support only a single value (id="this-element") and
others support multiple values (class="important order
pending"). This distinction in decorators can be very handy
when designing domain-agnostic hypermedia types.
Of course, the domain-agnostic style has its limitations. Chief among these is that overly generic markup can pose a challenge to clients attempting to parse the message. This includes humans, too. We naturally desire clear statements of meaning in messages and using an agnostic approach that relies on one or more levels of indirection via attribute decorators can be confusing and frustrating at times. There is also the possibility that a design can be too agnostic, where there is almost no meaning in the elements themselves and all interesting information is tucked out of the way in decorators. This can lead to overly complex coding for applications creating the messages as well as those receiving, parsing, and rendering the results.
Ultimately, domain-agnostic messages require a slightly different approach to hypermedia design; one that separates the semantics of the data with the message markup itself. This notion of a dual-level design (the message markup and the domain-specific design) will be explored more fully in Chapter 4.
For use cases where a single message design needs to be used across a wide range of problem domains and/or where the problem domain is likely to change and evolve over time, a domain-agnostic style can be very effective.
Application Flow
Hypermedia designs may also contain elements that express possible application flow options. This allows client applications to recognize and respond to possible options that allow for advancing the application through state transitions at the appropriate times. Designing support for application flow in hypermedia types is more than just including links and forms in responses. Application flows require identifications for the various possible options for changing the state of the application.
In many existing media types, this is done using decorators on
links (rel="edit" in AtomPub) and forms
(name="payment" in HTML). However, in VoiceXML, a
domain-specific design for telephony services, there are a number of
application flow elements such as goto, exit,
return, help, log, and others.
Other logical applications flow identifiers could be “write”, “update”,
“remove”, “add”, “save”, and a whole host of nouns and activities that
are domain-specific (e.g. payment, order, customer, etc.).
Some media types define application flow identifiers as native to the media type (e.g. HTML’s link relation values). Other designs rely on a public registry of values such as the IANA Link Relation Registry, Microformats Existing Rel Values, and Dublin Core Terms.
Whether the application flow is identified using unique elements, attributes, or unique values for existing attributes, application flow styles for hypermedia can be categorized into three general groups:
- None
This hypermedia type contains no identifiers for application flow. Designs that are read-only and/or cover a very limited domain may not support any application flow identifiers.
- Intrinsic
The application flow identifiers are defined within the hypermedia type itself. Atom and AtomPub define a small set of link relations to indicate application flow (“edit”, “edit-media”, and “self”).
- Applied
The application flow identifiers are not part of the hypermedia type, but the type designs contain allowances (usually element decorators or attributes) for applying external values to indicate application flow. HTML supports a number of attributes that can be used to add application flow information including the
profile,id,name,rel, andclassattributes.
None
There are several cases where your hypermedia design does not require any application flow identifiers. Usually this is when the problem space covered is rather limited and/or read-only in nature. Hypermedia type designs for automated services (bots, machine-to-machine interactions, etc.) are a good candidate for designs that do not contain application flow identifiers.
For example, the text/uri-list media type is designed to hold a list of URIs only. It is a read-only media type that supports the LO H-Factor and can be used for presenting lists of URIs to bots and other automated services. There is no need for application flow since the only work is to resolve the list of presented URIs.
# urn:isbn:0-201-08372-8 http://www.huh.org/books/foo.html http://www.huh.org/books/foo.pdf ftp://ftp.foo.org/books/foo.txt
Another hypermedia type that has no need for application flow is the OpenSearch specification. Designed to support searching web indexes, the OpenSearch specification uses the XML base format and supports only the LO H-Factor in responses.
<?xml version="1.0" encoding="UTF-8"?>
<OpenSearchDescription xmlns="http://a9.com/-/spec/opensearch/1.1/">
<ShortName>Web Search</ShortName>
<Description>Use Example.com to search the Web.</Description>
<Tags>example web</Tags>
<Contact>admin@example.com</Contact>
<Url type="application/rss+xml"
template="http://example.com/?q={searchTerms}&pw={startPage?}&format=rss"/>
</OpenSearchDescription>If your use case covers a relatively narrow problem domain and/or your hypermedia will be used primarily by automated systems, a design that has no application flow can be a good option.
Intrinsic
If you want to design a hypermedia type that supports
application flow, one way to do this is to define the application flow
identifiers as part of your media type directly. This can be done in
two primary ways: 1) by identifying specific elements or attributes in
your design that represent options for application flow (e.g.
<update>...</update> or <store
type="update">...</store>); and 2) by identifying
unique decorator values that can be applied to existing elements and
attributes (e.g. <link rel="update" ... />). In
these examples, the rules for application flow are intrinsic to the
media type definition itself.
The AtomPub media type uses this intrinsic style of application
flow. The specification identifies a few elements and link relations
that clients can use to activate application flow. For example, the
AtomPub spec identifies the href attribute of the
app:collection element as the URI to use to create new
entries:
<?xml version="1.0" encoding='utf-8'?>
<service xmlns="http://www.w3.org/2007/app"
xmlns:atom="http://www.w3.org/2005/Atom">
<workspace>
<atom:title>Main Site</atom:title>
<collection
href="http://example.org/blog/main" >
<atom:title>My Blog Entries</atom:title>
<categories
href="http://example.com/cats/forMain.cats" />
</collection>
</workspace>
...
</service>It also states that the href attribute of the
atom:link element marked with rel="edit"
contains the URI for use when updating or deleting individual
entries:
<?xml version="1.0"?> <entry xmlns="http://www.w3.org/2005/Atom"> <title>Atom-Powered Robots Run Amok</title> <id>urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a</id> <updated>2003-12-13T18:30:02Z</updated> <author><name>John Doe</name></author> <content>Some text.</content> <link rel="edit" href="http://example.org/edit/first-post.atom"/> </entry>
Intrinsic application flow works well when you want your design to stand alone and not depend on any external specifications or definitions, and when your application flow options can be expressed with a limited set of elements, attributes, and/or values. This works well for hypermedia types that cover a relatively limited set of use cases where the options are not likely to change over time, or types that provide support for a general use case (e.g. writing blog entries, etc.). Intrinsic application flow is also very helpful if you are working to define a hypermedia type that might be implemented by a wide range of servers all attempting to support the same use cases.
Applied
When your hypermedia design needs to support application flow that can change over time, or has a wide range of possible use cases, you may need to consider a design that relies on external identifiers that can be applied consistently to specific elements and attributes of your hypermedia type.
The HTML media type uses this approach to support application
flow. There are a handful of HTML attributes that can be used to
define application flow options including rel,
class, name, and id. By
supplying predefined values to these attributes, designers can apply
details about application flow options that may appear in a
message.
The key to making the applied style work is to publish a set of
predefined values along with their meaning and purpose at a stable
URI. This external application flow specification can then be accessed
and used by client and server implementors to guide the creation,
parsing, and interpretation of hypermedia messages using the specified
rules. A pointer to this specification can be shared as a link header
and/or as a part of the entity body. This can be done in HTML using
the profile attribute or the meta
element.
In the following HTML example, the response indicates the
application flow specification in use (see the meta tag).
You can see several places in the document where elements are
decorated with rel, and name attributes
indicating application flow options:
<html>
<head>
<title>Payment Options</title>
<meta name="profile" content="http://www.example.com/profiles/payment.html" />
</head>
<body>
<h1>Payment Options</h1>
<p>
<a href="..." rel="cancel-order">Cancel Order</a>
</p>
<form href="..." name="credit-card" method="post">
<input name="card-number" value="" />
...
<input type="submit" />
</form>
<form href="..." name="purchase-order" method="post">
<input name="po-number" value="" />
...
<input type="submit" />
</form>
<form href="..." name="bank-draft" method="post">
<input name="routing-number" value="" />
...
<input type="submit" />
</form>
...
</html>The applied style of application flow offers the most flexibility since it allows designers an almost unlimited number of possibilities. This also allows designers to define application flow specifications that are independent of a particular media type; the rules can be applied to any base format (XML, JSON, etc.) or existing hypermedia type that supports it (similar to the way CSS and XSLT work for HTML today).
There are also a number of drawbacks to the applied style. First, by creating an external document that holds the application flow details, clients and servers will be required to support not only the primary media type but also a second rule document. This can put an added burden on client and server implementors. Second, clients and servers may ignore the rule specifications completely, which can cause problems, especially for server implementors who may have to deal with clients who are not following the rules laid out in the application profile. Additionally, when the profile document is updated over time with new application flow options, there is no guarantee that clients using that profile will recognize and honor the changes without additional coding updates. There are ways to mitigate these problems, but there are no standards for doing so.
Despite these drawbacks, in cases where your design must support a wide-ranging, flexible set of applications flow options that can change over time, the applied style may be your best option.
Summary
In this chapter, four key topics were discussed: 1) the underlying technologies behind the Web, 2) the importance of adopting hypermedia as the basis for sharing data on the Web, 3) the identification of nine H-Factors used in all hypermedia designs, and 4) four basic design elements used in implementing a functioning hypermedia type.
Today the Web relies on HTTP as the transfer protocol for sending messages. These messages are used to represent data using MIME media types. The representation model for the Web allows clients and servers to negotiate for preferred data formats including support for future extensibility through the design of new data formats. The development of the Web follows the introduction of hypermedia links as a method of not only navigating between documents but also through the use of hypermedia controls that support sending parameterized queries and write instructions to remote servers.
The essence of programming the Web is designing hypermedia-rich messages that can be understood and passed between parties on the network. Unlike object-serialization patterns that simply convert internal private data structures into bytes that can be passed between client and server, the Web encourages the use of coarse-grained messages that include metadata that describes not only the data being passed but also the state of the application at time of the request. The set of hypermedia elements that can be used to communicate application state changes (H-Factors) is the same regardless of the data format used to transfer the message. The design of these hypermedia messages depends on four key elements including data format, state transfer style, application domain style, and flow control.
What’s Next?
The following three chapters illustrate the process of designing and implementing hypermedia APIs. Each chapter is devoted to a particular application domain and shows how choices are made in the process of the hypermedia design (which H-Factors are needed, what data format is selected, etc.) in order to achieve the desired outcome. The hypermedia designs that follow are all based upon the concepts and techniques described in this chapter.
Let’s design some hypermedia APIs!
[1] I first heard the term “surfing your API” from Jonathan Moore in his presentation at Oredev in 2010, where he demonstrated using browsers to explore hypermedia types based on XHTML.
Get Building Hypermedia APIs with HTML5 and Node now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

