Chapter 4. Going Beyond Server-Side Rendering
Applications come in different shapes and sizes. In the introductory chapters we focused mainly on single-page applications that can also be rendered on the server. The server renders the initial page to improve perceived page load time and for search engine optimization (SEO). That discussion was focused around the classic application architecture, in which the client initiates a REST call and is routed to one of the stateless backend servers, which in turn queries the database and returns the data to the client (Figure 4-1).
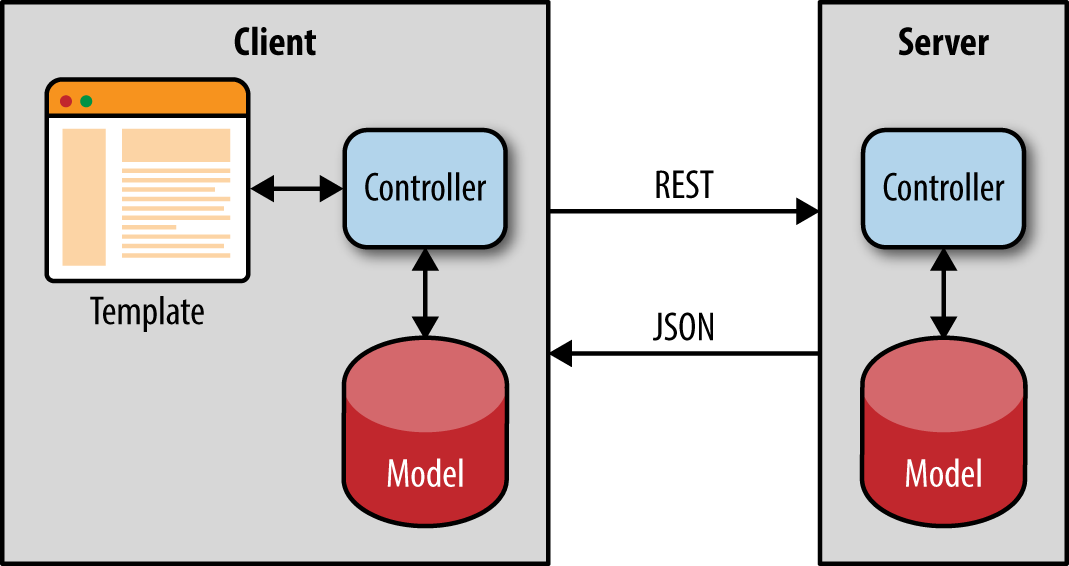
Figure 4-1. Classic web application architecture
This approach is great for classic ecommerce web applications. But there is another class of applications, often referred to as “real-time” applications. In fact, we can say that there are two classes of isomorphic JavaScript applications: single-page apps that can be server-rendered and apps that use isomorphic JavaScript for real-time, offline, and data-syncing capabilities.
Note
Matt Debergalis has described real-time applications as a natural evolutionary step in the rich history of application architectures. He believes that changes in application architecture are driven by new eras of cheap CPUs, the Internet, and the emergence of mobile. Each of these changes resulted in the development of new application architectures. However, even though we are seeing more complex, live-updating, and collaborative real-time applications, the majority of applications remain single-page apps that can benefit from server-side rendering. Nonetheless, we feel this subject is important to the future of application architecture and very relevant to our discussion of isomorphic JavaScript applications.
Real-Time Web Applications
Real-time applications have a rich interactive interface and a collaborative element that allows users to share data with other users. Think of a chat application like Slack; a shared document application like Google Docs; or a ride-share application like Uber, which shows all the available drivers and their locations in real time to all the users. For these kinds of applications we end up designing and implementing ways to push data from the server to the client to show other users’ changes as they happen. We also need a way to reactively update the screen on each client once that data comes from the server. Most of these real-time applications have similar functional pieces. These applications must have some mechanism for watching a database for changes, some kind of protocol that runs on top of a push technology like WebSockets to push data to the client (or emulate server data pushes using long polling—i.e., where the server holds the request open until new data is available and has been sent), and some kind of cache on the client to avoid the round-trips to the server when redrawing the screen.
In Figure 4-2 we can see how data flows from the user’s interaction with the view. We can also see how changes from other clients propagate to all users and how the view rerenders when data changes are sent from the server. There are three interesting isomorphic concepts that come up in this kind of architecture: isomorphic APIs, bidirectional data synchronization, and client simulation on the server.
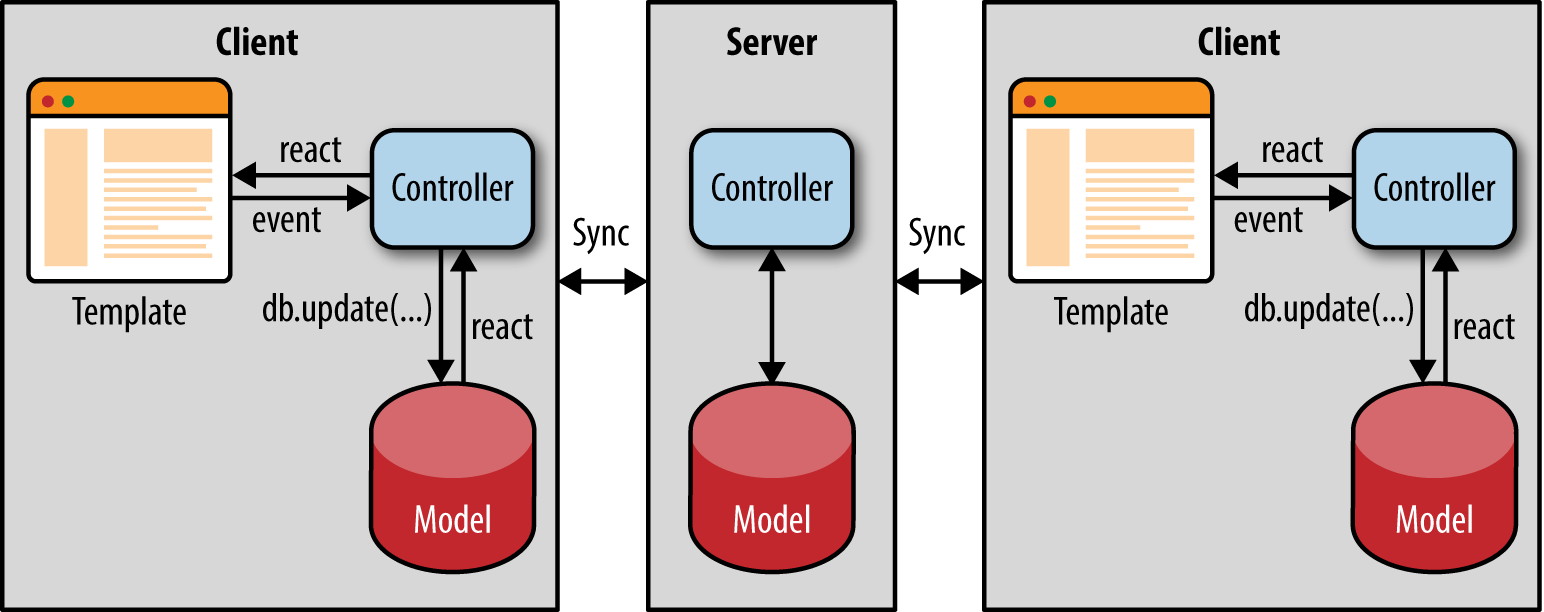
Figure 4-2. Real-time web application architecture
Isomorphic APIs
In an isomorphic real-time application, the client interacts with its local data cache similarly to how the server interacts with the backing database. The server code is executing a statement against a database. That same statement is executed on the client to fetch data out of an in-memory cache using the same database API. This symmetry between client and server APIs is often referred to as isomorphic APIs. Isomorphic APIs relieve the developer from having to juggle different strategies for accessing data. But more importantly, isomorphic APIs make it possible to run an application’s core business logic (especially across the model layer) and rendering logic on both the client and the server. Having an isomorphic API for accessing data allows us to share server code and the client application code for validating the updates to the data, accessing and storing the data, and transforming data. By using a consistent API, we remove the friction of having to write different variations of doing the same thing, having to test it in different ways, and having to update code twice when we need to change the data model. Isomorphic APIs are about being intelligent by following the DRY (Don’t Repeat Yourself) principle.
Bidirectional Data Synchronization
Another important aspect of real-time applications is the synchronization between the server’s database and the client’s local cache. Updates to the server from a client should be updated in the client’s local cache, and vice versa. Meteor.js is a good example of a real-time isomorphic framework that lets developers write JavaScript that runs on both the server and the client. Meteor has a “Database Everywhere” principle. Both the client and the server in Meteor use the same isomorphic APIs to access the database. Meteor also uses database abstractions, like minimongo, on the client and an observable collection over a DDP (dynamic data protocol) to keep the data in sync between the server and the client. It is the client database (not the server database) that drives the UI. The client database does lazy data synchronizing to keep the server database up to date. This allows the client to be offline and to still process user data changes locally. A write on the client can optionally be a speculative write to the client’s local cache before hearing a confirmation back from the server. Meteor has a built-in latency compensation mechanism for refreshing the speculative cache if any writes to the server’s database fail or are overwritten by another client.
Client Simulation on the Server
Taking isomorphic JavaScript to the extreme, real-time isomorphic applications may run separate processes on the server for each client session. This allows the server to look at the data that the application loads and proactively send data to the client, essentially simulating the UI on the server. This technique has been famously used by the Asana application. Asana is a collaborative project management tool built on an in-house, closed-source framework called Luna. Luna is tailored for writing real-time web applications and is similar to Meteor.js in providing a common isomorphic API for accessing data on the client and the server. However, what makes Luna unique is that it runs a complete copy of the application on the server. Luna simulates the client on the server by executing the same JavaScript code on the server that is running in the client. As a user clicks around in the Asana UI, the JavaScript events in the client are synchronized with the server. The server maintains an exact copy of the user state by executing all the views and events, but simply throws away the HTML.
A recent post on Asana’s engineering blog indicates that Asana is moving away from this kind of client/server simulation, though. Performance is an issue, especially when the server has to simulate the UI in multiple states so that it can anticipate and preload data on the client for immediate availability. The post also cites versioning as an issue for mobile clients that may run older versions of the code, which makes simulation tricky since the client and the server are not running exactly the same code.
Summary
Isomorphic JavaScript is an attempt to share an application on both sides of the wire. By looking at real-time isomorphic frameworks, we have seen different solutions to sharing application logic. These frameworks take a more novel approach than simply taking a single-page application and rendering it on the server. There has been a lot of discussion around these concepts, and we hope this has provided a good introduction to the many facets of isomorphic JavaScript. In the next part of the book, we will build on these key concepts and create our first isomorphic application.
Get Building Isomorphic JavaScript Apps now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

