Part II. Build a Working Pipeline
Since researching, training, and evaluating models is a time-consuming process, going in the wrong direction can be very costly in ML. This is why this book focuses on reducing risk and identifying the highest priority to work on.
While Part I focused on planning in order to maximize our speed and chances of success, this chapter will dive into implementation. As Figure II-1 shows, in ML like in much of software engineering, you should get to a minimum viable product (MVP) as soon as possible. This section will cover just that: the quickest way to get a pipeline in place and evaluating it.
Improving said model will be the focus of Part III of this book.
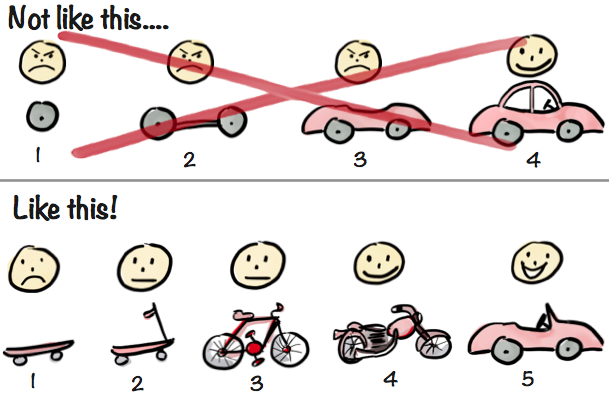
Figure II-1. The right way to build your first pipeline (reproduced with permission from Henrik Kniberg)
We will build our initial model in two steps:
- Chapter 3
-
In this chapter, we will build the structure and scaffolding of our application. This will involve building a pipeline to take user input and return suggestions, and a separate pipeline to train our models before we use them.
- Chapter 4
-
In this chapter, we will focus on gathering and inspecting an initial dataset. The goal here is to quickly identify patterns in our data and predict which of these patterns will be predictive and useful for our model.
Get Building Machine Learning Powered Applications now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

