The Internet is driving an unprecedented demand for access to information. Seduced by the convenience of paying bills, booking flights, tracking stocks, checking prices, and getting everything from gifts to groceries online, consumers are hungry for more. Compelled by the lower costs of online outsourcing and the ability to inquire, day or night, “What’s the status?,” businesses are ramping up to reap the rewards. Excited by improved efficiency and universal public access, governments are considering how all kinds of raw data, from financial reports to federally funded research, can be published online in an easily reusable format.
More than ever before, database-savvy web application developers working to capitalize on these exciting Internet-inspired opportunities need to rapidly acquire, integrate, and repurpose information, as well as exchange it with other applications both inside and outside their companies. XML dramatically simplifies these tasks.
As with any new technology, you first need to understand what XML is, what you can do with it, and why you should use it. With all the new terms and acronyms to understand, XML can seem like a strange new planet to the uninitiated, so let’s walk before we run. This chapter introduces “Planet XML” and the “moons” that orbit it, and provides a high-level overview of the tools and technology Oracle offers to exploit the combined strengths of XML and the Oracle database in your web applications.
First, let’s look at some basic XML definitions and examples.
XML, which stands for the “Extensible Markup Language,” defines a universal standard for electronic data exchange. It provides a rigorous set of rules enabling the structure inherent in data to be easily encoded and unambiguously interpreted using human-readable text documents. Example 1.1 shows what a stock market transaction might look like represented in XML.
Example 1-1. Stock Market Transaction Represented in XML
<?xml version="1.0"?>
<transaction>
<account>89-344</account>
<buy shares="100">
<ticker exch="NASDAQ">WEBM</ticker>
</buy>
<sell shares="30">
<ticker exch="NYSE">GE</ticker>
</sell>
</transaction>
After an initial line that identifies the
document as an XML document, the example begins with a
<transaction> tag. Nested inside this opening tag and its
matching </transaction> closing tag, other
tags and text encode
nested structure and data values respectively. Any tag can carry a
list of one or more named
attribute="value"
entries as well, like
shares="
nn
"
on <buy> and <sell> and
exch="
xxx
"
on <ticker>.
XML’s straightforward “text with tags” syntax
should look immediately familiar if you have ever worked with HTML,
which also uses tags, text, and attributes. A key difference between
HTML and XML, however, lies in the kind of data each allows you to
represent. What you can represent in an HTML document is constrained
by the fixed set of HTML tags at your disposal—like
<table>, <img>, and <a> for tables, images, and
anchors. In contrast, with XML you can invent any set of meaningful
tags to suit your current data encoding needs, or reuse an existing
set that someone else has already defined. Using XML and an
appropriate set of tags, you can encode data of any kind, from highly
structured database query results like the following:
<?xml version="1.0"?>
<ROWSET>
<ROW num="1">
<ENAME>KING</ENAME>
<SAL>5000</SAL>
</ROW>
<ROW num="2">
<ENAME>SCOTT</ENAME>
<SAL>3000</SAL>
</ROW>
</ROWSET>to unstructured documents like this one:
<?xml version="1.0"?> <DamageReport> The insured's <Vehicle Make="Volks">Beetle</Vehicle> broke through the guard rail and plummeted into a ravine. The cause was determined to be <Cause>faulty brakes</Cause>. Amazingly there were no casualties. </DamageReport>
and anything in between.
A set of XML tags designed to encode data of a particular kind is known as an XML vocabulary. If the data to be encoded is very simple, it can be represented with an XML vocabulary consisting of as little as a single tag:
<?xml version="1.0"?> <OrderConfirmed/>
For more complicated cases, an XML vocabulary can comprise as many tags as necessary, and they can be nested to reflect the structure of data being represented:
<?xml version="1.0"?>
<Planet Name="Earth">
<Continent Name="North America">
<Country Name="USA">
<State Name="California">
<City Name="San Francisco"/>
</State>
</Country>
</Continent>
</Planet>As we’ve seen in the few examples above, an XML document is just a sequence of text characters that encodes data using tags and text. Often, this sequence of characters will be the contents of a text file, but keep in mind that XML documents can live anywhere a sequence of characters can roost. An XML document might be the contents of a string-valued variable in a running computer program, a stream of data arriving in packets over a network, or a column value in a row of a database table. While XML documents encoding different data may use different tag vocabularies, they all adhere to the same set of general syntactic principles described in the XML specification, which is discussed in the next section.
The XML 1.0 specification became a World Wide Web Consortium (W3C) Recommendation in February 1998. Before a W3C specification reaches this final status, it must survive several rounds of public scrutiny and be tempered by feedback from the early implementation experience of multiple vendors. Only then will the W3C Director declare it a “Recommendation” and encourage its widespread, public adoption as a new web standard. In the short time since February 1998, hundreds of vendors and organizations around the world have delivered support for XML in their products. The list includes all of the big-name software vendors like Oracle, IBM, Microsoft, Sun, SAP, and others, as well as numerous influential open source organizations like the Apache Software Foundation. XML’s apparent youth belies its years; the W3C XML Working Group consciously designed it as a simplified subset of the well-respected SGML (Standard Generalized Markup Language) standard.
In order to be as generally applicable as possible, the XML 1.0 specification does not define any particular tag names; instead, it defines general syntactic rules enabling developers to create their own domain-specific vocabularies of tags. Since XML allows you to create virtually any set of tags you can imagine, two common questions are:
How do I understand someone else’s XML?
How do I ensure that other people can understand my XML?
The answer lies in the document type definition you can associate with your XML documents.
A document type definition (DTD) is a text document that formally defines the lexicon of legal names for the tags in a particular XML vocabulary, as well as the meaningful ways that tags are allowed to be nested. The DTD defines this lexicon of tags using a syntax described in the DTD specification, which is an integral part of the XML 1.0 specification described earlier. An XML document can be associated with a particular DTD to enable supporting programs to validate the document’s contents against that document type definition; that is, to check that the document’s syntax conforms to the syntax allowed by the associated DTD. Without an associated DTD, an XML document can at best be subjected to a “syntax check.”
Recall our transaction example from Example 1.1. For this transaction vocabulary, we might want to reject a transaction that looks like this:
<?xml version="1.0"?>
<transaction>
<buy>
<ticker exch="NASDAQ">WEBM</ticker>
<sell shares="30">
<ticker exch="NYSE">GE</ticker>
</sell>
</buy>
</transaction>because it’s missing an account number, doesn’t indicate
how many shares to buy, and incorrectly lists the <sell> tag
inside the <buy> tag.
We can enable the rejection of this erroneous transaction document by
defining a DTD for the transaction vocabulary. The DTD can define the
set of valid tag names (also known as
element names) to include
<transaction>, <account>, <buy>, <sell>, and <ticker>. Furthermore, it can assert additional constraints on
a <transaction> document. For example, it can require that:
A
<transaction>should be comprised of exactly one<account>element and one or more occurrences of<buy>or<sell>elementsA
<buy>or<sell>element should carry an attribute namedshares, and contain exactly one<ticker>elementA
<ticker>element should carry an attribute namedexch
With a <transaction> DTD such as this in
place, we can use tools we’ll learn about in the next section
to be much more picky about the transaction documents we accept.
Figure 1.1 summarizes the relationships between the
XML specification, the DTD specification, the XML document, and the
DTD.
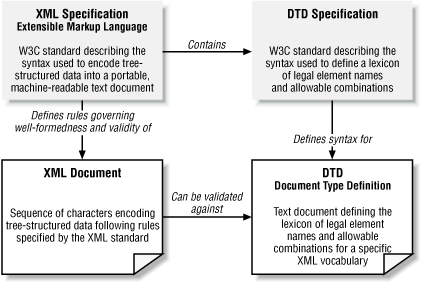
If an XML document passes the strict XML syntax check, it is known as a well-formed document. If in addition, its contents conform to all the constraints in a particular DTD, the document is known as “well-formed and valid " with respect to that DTD.
Get Building Oracle XML Applications now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

