The previous chapter talked about dynamically updating your home page to show the latest updates long after the page had been loaded. The examples used many of the same technologies most web developers have used for years. Although this works well for some things, it has limitations that quickly become clear. If you want to give your users a truly realtime experience in the web browser, you need to push content to them. In this chapter, I’ll show you how to build a simple river of content feed. The most obvious use for this would be for a truly realtime live blog application.
During big events, many blogs will provide a link to a separate page where they will “liveblog” the whole thing. They’ll post quick text updates, “this new product could save the company, too bad it doesn’t support bluetooth.” They’ll also post images as quickly as they can take them. However, the pages serving these “live” blogs tend to be nothing more than a regular web page that automatically refreshes every 30 seconds. Users will often refresh their browser by hand to ensure they’re seeing the latest content. Getting your content to users faster, even if it’s just a couple of seconds, can mean the difference between users staying on your site all day and leaving as soon as they feel they’re getting old news.
Using a liveblog as an example, I’ll show you how to build a river of content that pushes out updates as soon as they are available. This will help keep users from clicking away, save wear and tear on your server, and most importantly, it’s not that hard to build.
There are several forms of server push technology. This idea is not new and has existed in several different forms throughout the years. However, these days when people talk about server push technologies, they tend to refer to a technology called long polling.
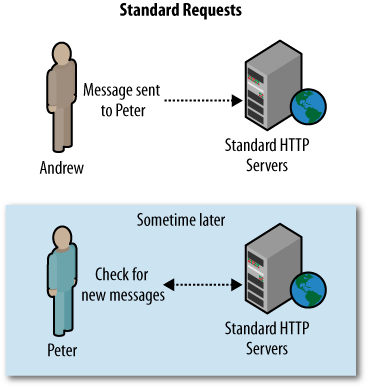
Long polling is a method of server push technology that cleverly uses traditional HTTP requests to create and maintain a connection to the server, allowing the server to push data as it becomes available. In a standard HTTP request, when the browser requests data, the server will respond immediately, regardless of whether any new data is available (see Figure 4-1). Using long polling, the browser makes a request to the server and if no data is available, the server keeps the connection open, waiting until new data is available. If the connection breaks, the browser reconnects and keeps waiting. When data does become available, the server responds, closes the connection, and the whole process is repeated (see Figure 4-2).
Technically, there is no difference between this kind of request and standard pull requests. The difference, and advantage, is in the implementation. Without long polling, the client connects and checks for data; if there is none, the client disconnects and sleeps for 10 seconds before reconnecting again. With long polling, when the client connects and there is no data available, it will just hang on until data arrives. So if data arrives five seconds into the request, the client accepts the data and shows it to the user. The normal request wouldn’t see the new data until its timer was up and it reconnected again several seconds later.
This method of serving requests opens up a lot of doors to what is possible in a web application, but it also complicates matters immensely.
For example, on an application where users can send messages to one another, checking for new messages has always been a rather painless affair. When the browser requests new messages for Peter, the server checks and has no messages. The same transaction is made again a few seconds later, and the server has a message for Peter.
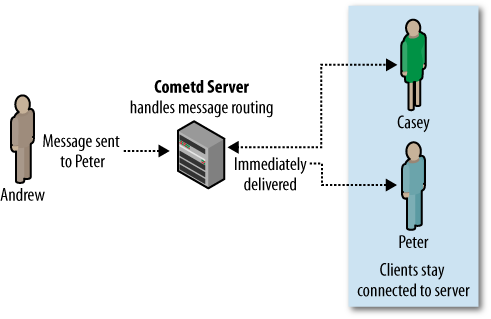
However, in long polling, when Peter connects that first time, he never disconnects. So when Andrew sends him a new message, that message must be routed to Peter’s existing connection. Where previously the message would be stored in a database and retrieved on Peter’s next connection, now it must be routed immediately.
This routing and delivery of these messages to clients that are already connected is a very complicated problem. Thankfully, it’s already been solved by a number of groups. Amongst others, the Dojo Foundation (http://www.dojofoundation.org) has developed a solution in the form of the Cometd server and the Bayeux protocol.
At its heart, Bayeux is a messaging protocol. Messages (or events, as they’re sometimes called) can be sent from the server to the client (and vice versa) as well as from one client to another after a trip through the server. It’s a complicated protocol solving a complicated problem, but for both the scope of this book and most use cases, the details are not that important.
Aside from the handshakes and housekeeping involved, the protocol
describes a system that actually is quite simple for day-to-day uses. A
client subscribes to a channel by name, which tends to be something like
/foo, /foo/bar, or
/chat. Channel globbing is also supported, so a user
can subscribe to /foo/**, which would include
channels such as /foo, /foo/bar,
and /foo/zab.
Messages are then sent to the different named channels. For
example, a server will send a message to /foo/bar and
any client that has subscribed to that channel will receive the message.
Clients can also send messages to specific channels and, assuming the
server passes them along, these messages will be published to any other
clients subscribed to that channel.
Channel names that start with /meta are
reserved for protocol use. These channels allow the client and server to
handle tasks such as figuring out which client is which and protocol
actions such as connecting and disconnecting.
One of the fields often sent along with these meta requests is an
advice statement. This is a message from the server
to the client about how the client should act. This allows the server to
tell clients at which interval they should reconnect
to the server after disconnecting. It can also tell them which operation
to perform when reconnecting. The server commonly tells the client to
retry the same connection after the standard server timeout, but it may
request that the client retries the handshake process all together, or
the server may tell the client not to reconnect at all.
"advice": {
"reconnect": "retry",
"interval": 0,
"timeout": 120000
}The protocol specifies a number of other interesting things that are outside the scope of this book. I encourage you to find out more about the protocol and how to leverage it for more advanced applications, but you don’t actually need to worry about how it works underneath the hood during your day-to-day coding. Most client and server libraries, including the ones listed in this text, handle the vast majority of these details.
The Dojo Foundation started this project in order to provide implementations of the Bayeux protocol in several different languages. At the time of this writing, only the JavaScript and Java implementations are designated as stable. There are also implementations in Python, Perl, and several other languages that are in varying stages of beta.
The Java version includes both a client and a server in the form
of the org.cometd package. This package has already
been bundled with the Jetty web server and, no doubt, other Java servers
will implement this as well.
Get Building the Realtime User Experience now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

