Chapter 1. The Art of Software Design
What is software design? And why should you care about it? In this chapter, I will set the stage for this book on software design. I will explain software design in general, help you understand why it is vitally important for the success of a project, and why it is the one thing you should get right. But you will also see that software design is complicated. Very complicated. In fact, it is the most complicated part of software development. Therefore, I will also explain several software design principles that will help you to stay on the right path.
In “Guideline 1: Understand the Importance of Software Design”, I will focus on the big picture and explain that software is expected to change. Consequently, software should be able to cope with change. However, that is much easier said than done, since in reality, coupling and dependencies make our life as a developer so much harder. That problem is addressed by software design. I will introduce software design as the art of managing dependencies and abstractions—an essential part of software engineering.
In “Guideline 2: Design for Change”, I will explicitly address coupling and dependencies and help you understand how to design for change and how to make software more adaptable. For that purpose, I will introduce both the Single-Responsibility Principle (SRP) and the Don’t Repeat Yourself (DRY) principle, which help you to achieve this goal.
In “Guideline 3: Separate Interfaces to Avoid Artificial Coupling”, I will expand the discussion about coupling and specifically address coupling via interfaces. I will also introduce the Interface Segregation Principle (ISP) as a means to reduce artificial coupling induced by interfaces.
In “Guideline 4: Design for Testability”, I will focus on testability issues that arise as a result of artificial coupling. In particular, I will raise the question of how to test a private member function and demonstrate that the one true solution is a consequent application of separation of concerns.
In “Guideline 5: Design for Extension”, I will address an important kind of change: extensions. Just as code should be easy to change, it should also be easy to extend. I will give you an idea how to achieve that goal, and I will demonstrate the value of the Open-Closed Principle (OCP).
Guideline 1: Understand the Importance of Software Design
If I were to ask you which code properties are most important to you, you would, after some thinking, probably say things like readability, testability, maintainability, extensibility, reusability, and scalability. And I would completely agree. But now, if I were to ask you how to achieve these goals, there is a good chance that you would start to list some C++ features: RAII, algorithms, lambdas, modules, and so on.
Features Are Not Software Design
Yes, C++ offers a lot of features. A lot! Approximately half of the almost 2,000 pages of the printed C++ standard are devoted to explaining language mechanics and features.1 And since the release of C++11, there is the explicit promise that there will be more: every three years, the C++ standardization committee blesses us with a new C++ standard that ships with additional, brand-new features. Knowing that, it doesn’t come as a big surprise that in the C++ community there’s a very strong emphasis on features and language mechanics. Most books, talks, and blogs are focused on features, new libraries, and language details.2
It almost feels as if features are the most important thing about programming in C++, and crucial for the success of a C++ project. But honestly, they are not. Neither the knowledge about all the features nor the choice of the C++ standard is responsible for the success of a project. No, you should not expect features to save your project. On the contrary: a project can be very successful even if it uses an older C++ standard, and even if only a subset of the available features are used. Leaving aside the human aspects of software development, much more important for the question about success or failure of a project is the overall structure of the software. It is the structure that is ultimately responsible for maintainability: how easy is it to change code, extend code, and test code? Without the ability to easily change code, add new functionality, and have confidence in its correctness due to tests, a project is at the end of its lifecycle. The structure is also responsible for the scalability of a project: how large can the project grow before it collapses under its own weight? How many people can work on realizing the vision of the project before they step on one another’s toes?
The overall structure is the design of a project. The design plays a much more central role in the success of a project than any feature could ever do. Good software is not primarily about the proper use of any feature; rather, it is about solid architecture and design. Good software design can tolerate some bad implementation decisions, but bad software design cannot be saved by the heroic use of features (old or new) alone.
Software Design: The Art of Managing Dependencies and Abstractions
Why is software design so important for the quality of a project? Well, assuming everything works perfectly right now, as long as nothing changes in your software and as long as nothing needs to be added, you are fine. However, that state will likely not last for long. It’s reasonable to expect that something will change. After all, the one constant in software development is change. Change is the driving force behind all our problems (and also most of our solutions). That’s why software is called software: because in comparison to hardware, it is soft and malleable. Yes, software is expected to be easily adapted to the ever-changing requirements. But as you may know, in reality this expectation might not always be true.
To illustrate this point, let’s imagine that you select an issue from
your issue tracking system that the team has rated with an expected effort of 2.
Whatever a 2 means in your own project(s), it most certainly does not sound
like a big task, so you are confident that this will be done quickly.
In good faith, you first take some time to understand
what is expected, and then you start by making a change in some entity A.
Because of immediate feedback from your tests (you are lucky to have tests!), you
are quickly reminded that you also have to address the issue in entity B.
That is surprising! You did not expect that B was involved at all. Still, you go
ahead and adapt B anyway. However, again unexpectedly, the nightly build reveals
that this causes C and D to stop working. Before continuing, you now investigate
the issue a little deeper and find that the roots of the issue are spread
through a large portion of the codebase. The small, initially innocent-looking task has evolved into a large, potentially risky code modification.3 Your confidence in resolving the issue quickly is gone. And
your plans for the rest of the week are as well.
Maybe this story sounds familiar to you. Maybe you can even contribute a few war stories of your own. Indeed, most developers have similar experiences. And most of these experiences have the same source of trouble. Usually the problem can be reduced to a single word: dependencies. As Kent Beck has expressed in his book on test-driven development:4
Dependency is the key problem in software development at all scales.
Dependencies are the bane of every software developer’s existence. “But of course there are dependencies,” you argue. “There will always be dependencies. How else should different pieces of code work together?” And of course, you are correct. Different pieces of code need to work together, and this interaction will always create some form of coupling. However, while there are necessary, unavoidable dependencies, there are also artificial dependencies that we accidentally introduce because we lack an understanding of the underlying problem, don’t have a clear idea of the bigger picture, or just don’t pay enough attention. Needless to say, these artificial dependencies hurt. They make it harder to understand our software, change software, add new features, and write tests. Therefore, one of the primary tasks, if not the primary task, of a software developer is to keep artificial dependencies at a minimum.
This minimization of dependencies is the goal of software architecture and design. To state it in the words of Robert C. Martin:5
The goal of software architecture is to minimize the human resources required to build and maintain the required system.
Architecture and design are the tools needed to minimize the work effort in any project. They deal with dependencies and reduce the complexity via abstractions. In my own words:6
Software design is the art of managing interdependencies between software components. It aims at minimizing artificial (technical) dependencies and introduces the necessary abstractions and compromises.
Yes, software design is an art. It’s not a science, and it doesn’t come with a set of easy and clear answers.7 Too often the big picture of design eludes us, and we are overwhelmed by the complex interdependencies of software entities. But we are trying to deal with this complexity and reduce it by introducing the right kind of abstractions. This way, we keep the level of detail at a reasonable level. However, too often individual developers on the team may have a different idea of the architecture and the design. We might not be able to implement our own vision of a design and be forced to make compromises in order to move forward.
Tip
The term abstraction is used in different contexts. It’s used for the organization of functionality and data items into data types and functions. But it’s also used to describe the modeling of common behavior and the representation of a set of requirements and expectations. In this book on software design, I will primarily use the term for the latter (see in particular Chapter 2).
Note that the words architecture and design can be interchanged in the preceding quotes, since they’re very similar and share the same goals. Yet they aren’t the same. The similarities, but also differences, become clear if you take a look at the three levels of software development.
The Three Levels of Software Development
Software Architecture and Software Design are just two of the three levels of software development. They are complemented by the level of Implementation Details. Figure 1-1 gives an overview of these three levels.
To give you a feeling for these three levels, let’s start with a real-world example of the relationship among architecture, design, and implementation details. Consider yourself to be in the role of an architect. And no, please don’t picture yourself in a comfy chair in front of a computer with a hot coffee next to you, but picture yourself outside at a construction site. Yes, I’m talking about an architect for buildings.8 As such an architect, you would be in charge of all the important properties of a house: its integration into the neighborhood, its structural integrity, the arrangement of rooms, plumbing, etc. You would also take care of a pleasing appearance and functional qualities—perhaps a large living room, easy access between the kitchen and the dining room, and so on. In other words, you would be taking care of the overall architecture, the things that would be hard to change later, but you would also deal with the smaller design aspects concerning the building. However, it’s hard to tell the difference between the two: the boundary between architecture and design appears to be fluid and is not clearly separated.
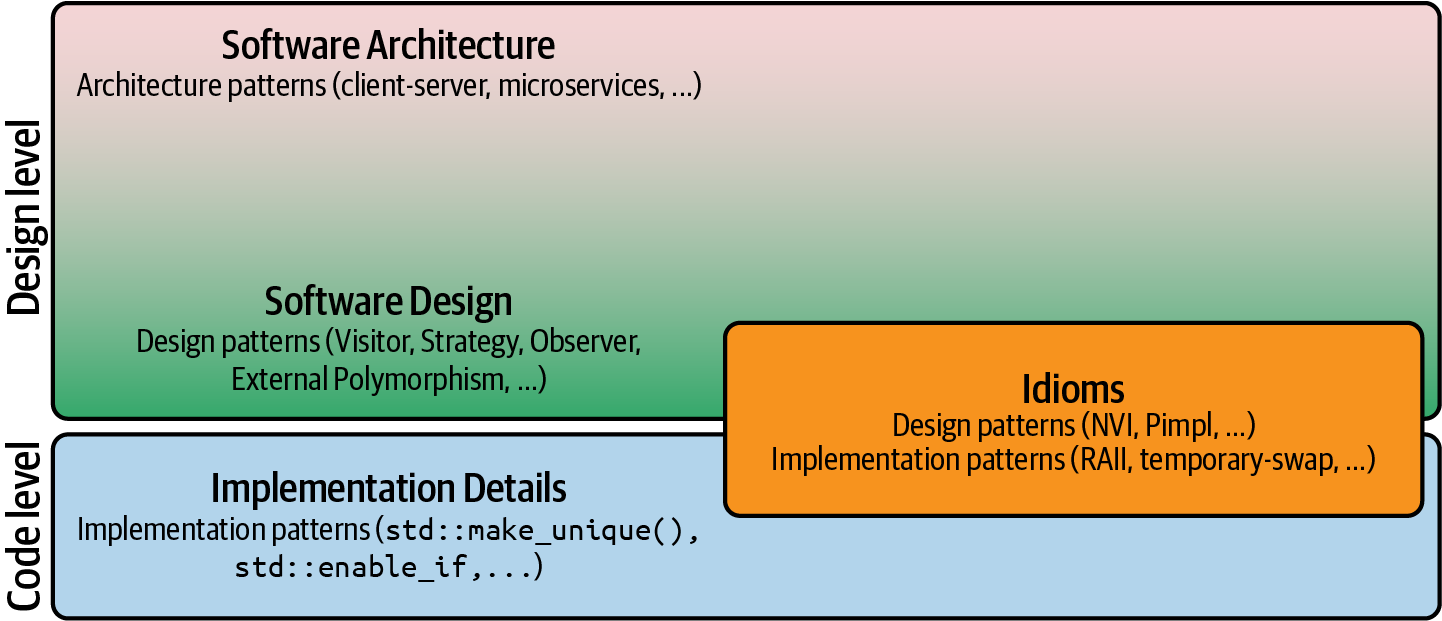
Figure 1-1. The three levels of software development: Software Architecture, Software Design, and Implementation Details. Idioms can be design or implementation patterns.
These decisions would be the end of your responsibility, however. As an architect, you wouldn’t worry about where to place the refrigerator, the TV, or other furniture. You wouldn’t deal with all the nifty details about where to place pictures and other pieces of decoration. In other words, you wouldn’t handle the details; you would just make sure that the homeowner has the necessary structure to live well.
The furniture and other “nifty details” in this metaphor
correspond to the lowest and most concrete level of software development, the
implementation details. This level handles how a solution is implemented. You
choose the necessary (and available)
C++ standard or any subset of it, as well as the appropriate
features, keywords, and language specifics to use, and deal with aspects such
as memory acquisition, exception safety, performance, etc. This is also the level
of implementation patterns, such as std::make_unique() as a factory function,
std::enable_if as a recurring solution to explicitly benefit from SFINAE,
etc.9
In software design, you start to focus on the big picture. Questions about maintainability, changeability, extensibility, testability, and scalability are more pronounced on this level. Software design primarily deals with the interaction of software entities, which in the previous metaphor are represented by the arrangement of rooms, doors, pipes, and cables. At this level, you handle the physical and logical dependencies of components (classes, function, etc.).10 It’s the level of design patterns such as Visitor, Strategy, and Decorator that define a dependency structure among software entities, as explained in Chapter 3. These patterns, which usually are transferable from language to language, help you break down complex things into digestible pieces.
Software Architecture is the fuzziest of the three levels, the hardest to put into words. This is because there is no common, universally accepted definition of software architecture. While there may be many different views on what exactly an architecture is, there is one aspect that everyone seems to agree on: architecture usually entails the big decisions, the aspects of your software that are among the hardest things to change in the future:
Architecture is the decisions that you wish you could get right early in a project, but that you are not necessarily more likely to get them right than any other.11
Ralph Johnson
In Software Architecture, you use architectural patterns such as client-server architecture, microservices, and so on.12 These patterns also deal with the question of how to design systems, where you can change one part without affecting any other parts of your software. Similar to Software design patterns, they define and address the structure and interdependencies among software entities. In contrast to design patterns, though, they usually deal with the key players, the big entities of your software (e.g., modules and components instead of classes and functions).
From this perspective, Software Architecture represents the overall strategy of your software approach, whereas Software Design is the tactics to make the strategy work. The problem with this picture is that there is no definition of “big.” Especially with the advent of microservices, it becomes more and more difficult to draw a clear line between small and big entities.13
Thus, architecture is often described as what expert developers in a project perceive as the key decisions.
What makes the separation between architecture, design, and details a little more difficult is the concept of an idiom. An idiom is a commonly used but language-specific solution for a recurring problem. As such, an idiom also represents a pattern, but it could be either an implementation pattern or a design pattern.14 More loosely speaking, C++ idioms are the best practices of the C++ community for either design or implementation. In C++, most idioms fall into the category of implementation details. For instance, there is the copy-and-swap idiom that you may know from the implementation of a copy assignment operator, and the RAII idiom (Resource Acquisition Is Initialization—you should definitely be familiar with this; if not, please see your second-favorite C++ book15). None of these idioms introduce an abstraction, and none of them help to decouple. Still, they are indispensable to implement good C++ code.
I hear you ask, “Could you be a little more specific, please? Isn’t RAII also providing some form of decoupling? Doesn’t it decouple resource management from business logic?” You’re correct: RAII separates resource management and business logic. However, it doesn’t achieve this by means of decoupling, i.e., abstraction, but by means of encapsulation. Both abstraction and encapsulation help you make complex systems easier to understand and change, but while abstraction solves the problems and issues that arise at the Software Design level, encapsulation solves the problems and issues that arise at the Implementation Details level. To quote Wikipedia:
The advantages of RAII as a resource management technique are that it provides encapsulation, exception safety […], and locality […]. Encapsulation is provided because resource management logic is defined once in the class, not at each call site.
While most idioms fall into the category of Implementation Details, there are also idioms that fall into the category of Software Design. Two examples are the Non-Virtual Interface (NVI) idiom and the Pimpl idiom. These two idioms are based on two classic design patterns: the Template Method design pattern and the Bridge design pattern, respectively.16 They introduce an abstraction and help decouple and design for change and extensions.
The Focus on Features
If software architecture and software design are of such importance, then why are we in the C++ community focusing so strongly on features? Why do we create the illusion that C++ standards, language mechanics, and features are decisive for a project? I think there are three strong reasons for that. First, because there are so many features, with sometimes complex details, we need to spend a lot of time talking about how to use all of them properly. We need to create a common understanding on which use is good and which use is bad. We as a community need to develop a sense of idiomatic C++.
The second reason is that we might put the wrong expectations on features. As an example, let’s consider C++20 modules. Without going into details, this feature may indeed be considered the biggest technical revolution since the beginning of C++. Modules may at last put the questionable and cumbersome practice of including header files into source files to an end.
Due to this potential, the expectations for that feature are enormous. Some people even expect modules to save their project by fixing their structural issues. Unfortunately, modules will have a hard time satisfying these expectations: modules don’t improve the structure or design of your code but can merely represent the current structure and design. Modules don’t repair your design issues, but they may be able to make the flaws visible. Thus, modules simply cannot save your project. So indeed, we may be putting too many or the wrong expectations on features.
And last, but not least, the third reason is that despite the huge amount of features and their complexity, in comparison to the complexity of software design, the complexity of C++ features is small. It’s much easier to explain a given set of rules for features, regardless of how many special cases they contain, than it is to explain the best way to decouple software entities.
While there is usually a good answer to all feature-related questions, the common answer in software design is “It depends.” That answer might not even be evidence of inexperience, but of the realization that the best way to make code more maintainable, changeable, extensible, testable, and scalable heavily depends on many project-specific factors. The decoupling of the complex interplay between many entities may indeed be one of the most challenging endeavors that mankind has ever faced:
Design and programming are human activities; forget that and all is lost.17
To me, a combination of these three reasons is why we focus on features so much. But please, don’t get me wrong. That’s not to say that features are not important. On the contrary, features are important. And yes, it’s necessary to talk about features and learn how to use them correctly, but once again, they alone do not save your project.
The Focus on Software Design and Design Principles
While features are important, and while it is of course good to talk about
them, software design is more important. Software design is essential.
I would even argue that it’s the foundation of
the success of our projects. Therefore, in this book I will make the
attempt to truly focus on software design and design principles instead
of features. Of course I will still show good and up-to-date C++
code, but I won’t force the use of the latest and
greatest language additions.18 I will make use of
some new features when it is reasonable and beneficial, such as
C++20 concepts, but I will not pay attention to noexcept,
or use constexpr everywhere.19 Instead I will try to
tackle the difficult aspects of software. I will, for the most part,
focus on software design, the rationale behind design decisions, design
principles, managing dependencies, and dealing with abstractions.
In summary, software design is the critical part of writing software. Software developers should have a good understanding of software design to write good, maintainable software. Because after all, good software is low-cost, and bad software is expensive.
Guideline 2: Design for Change
One of the essential expectations for good software is its ability to change easily. This expectation is even part of the word software. Software, in contrast to hardware, is expected to be able to adapt easily to changing requirements (see also “Guideline 1: Understand the Importance of Software Design”). However, from your own experience you may be able to tell that often it is not easy to change code. On the contrary, sometimes a seemingly simple change turns out to be a week-long endeavor.
Separation of Concerns
One of the best and proven solutions to reduce artificial dependencies and simplify change is to separate concerns. The core of the idea is to split, segregate, or extract pieces of functionality:20
Systems that are broken up into small, well-named, understandable pieces enable faster work.
The intent behind separation of concerns is to better understand and manage complexity and thus design more modular software. This idea is probably as old as software itself and hence has been given many different names. For instance, the same idea is called orthogonality by the Pragmatic Programmers.21 They advise separating orthogonal aspects of software. Tom DeMarco calls it cohesion:22
Cohesion is a measure of the strength of association of the elements inside a module. A highly cohesive module is a collection of statements and data items that should be treated as a whole because they are so closely related. Any attempt to divide them up would only result in increased coupling and decreased readability.
In the SOLID principles,23 one of the most established sets of design principles, the idea is known as the Single-Responsibility Principle (SRP):
A class should have only one reason to change.24
Although the concept is old and is commonly known under many names, many attempts to explain separation of concerns raise more questions than answers. This is particularly true for the SRP. The name of this design principle alone raises questions: what is a responsibility? And what is a single responsibility? A common attempt to clarify the vagueness about SRP is the following:
Everything should do just one thing.
Unfortunately this explanation is hard to outdo in terms of vagueness. Just as the word responsibility doesn’t carry a lot of meaning, just one thing doesn’t help to shed any more light on it.
Irrespective of the name, the idea is always the same: group only those things that truly belong together, and separate everything that does not strictly belong. Or in other words: separate those things that change for different reasons. By doing this, you reduce artificial coupling between different aspects of your code and it helps you make your software more adaptable to change. In the best case, you can change a particular aspect of your software in exactly one place.
An Example of Artificial Coupling
Let’s shed some light on separation of concerns by means of a code example. And
I do have a great example indeed: I present to you the abstract Document class:
//#include <some_json_library.h> // Potential physical dependencyclassDocument{public:// ...virtual~Document()=default;virtualvoidexportToJSON(/*...*/)const=0;virtualvoidserialize(ByteStream&,/*...*/)const=0;// ...};
This sounds like a very useful base class for all kinds of documents,
doesn’t it? First, there is the exportToJSON() function
(![]() ).
All deriving classes will have to implement the
).
All deriving classes will have to implement the exportToJSON() function in order
to produce a JSON file from the document. That
will prove to be pretty useful: without having to know about a particular kind
of document (and we can imagine that we will eventually have PDF documents, Word
documents, and many more), we can always export in JSON format. Nice! Second, there
is a serialize() function
(![]() ).
This function lets you transform a
).
This function lets you transform a Document into bytes via a ByteStream. You
can store these bytes in some persistent system, like a file or a database.
And of course we can expect that there are many other, useful functions available
that will allow us to pretty much use this document for
everything.
However, I can see the frown on your face. No, you don’t look particularly convinced that this is good software design. It may be because you’re just very suspicious about this example (it simply looks too good to be true). Or it may be that you’ve learned the hard way that this kind of design eventually leads to trouble. You may have experienced that using the common object-oriented design principle to bundle the data and the functions that operate on them may easily lead to unfortunate coupling. And I agree: despite the fact that this base class looks like a great all-in-one package, and even looks like it has everything that we might ever need, this design will soon lead to trouble.
This is bad design because it contains many dependencies. Of course there are the obvious, direct dependencies, as for instance the dependency on the ByteStream class. However, this design also favors the introduction of artificial dependencies, which will make subsequent changes harder. In
this case, there are three kinds of artificial dependencies. Two of these
are introduced by the exportToJSON() function, and one by the serialize()
function.
First, exportToJSON() needs to be implemented in the derived classes. And yes,
there is no choice, because it is a
pure virtual function
(denoted by the sequence = 0, the so-called pure specifier). Since derived
classes will very likely not want to carry the burden of implementing JSON exports
manually, they will rely on an external, third-party JSON library:
json,
rapidjson, or
simdjson.
Whatever library you choose for that purpose, because of the exportToJSON()
member function, deriving documents would suddenly depend on this library. And,
very likely, all deriving classes would depend on the same library, for
consistency reasons alone. Thus, the deriving classes are not really independent;
they are artificially coupled to a particular design decision.25 Also, the
dependency on a specific JSON library would definitely limit the reusability
of the hierarchy, because it would no longer be lightweight. And switching to
another library would cause a major change because all deriving classes
would have to be adapted.26
Of course, the same kind of artificial dependency is introduced by the serialize() function. It’s likely that serialize() will also be implemented in terms of a third-party library, such as protobuf or Boost.serialization. This considerably worsens the dependency situation because it introduces a coupling between two orthogonal, unrelated design aspects (i.e., JSON export and serialization). A change to one aspect might result in changes to the other aspect.
In the worst case, the exportToJSON() function might introduce
a second dependency. The arguments expected in the exportToJSON() call
might accidentally reflect some of the implementation details of the chosen
JSON library. In that case, eventually switching to another library might
result in a change of the signature of the exportToJSON() function, which
would subsequently cause changes in all callers. Thus, the dependency on the
chosen JSON library might accidentally be far more widespread than intended.
The third kind of dependency is introduced by the serialize() function. Due
to this function, the classes deriving from Document depend on global
decisions on how documents are serialized. What format do we use? Do we use
little endian or big endian? Do we have to add the information that the bytes
represent a PDF file or a Word file? If yes (and I assume that is very likely),
how do we represent such a document? By means of an integral value? For
instance, we could use an enumeration for this purpose:27
enumclassDocumentType{,word,// ... Potentially many more document types};
This approach is very common for serialization. However, if this low-level
document representation is used within the implementations of the
Document classes, we would accidentally couple all the different kinds of
documents. Every deriving class would implicitly know about all the other
Document types. As a result, adding a new kind of document would
directly affect all existing document types. That would be a serious
design flaw, since, again, it will make change harder.
Unfortunately, the Document class promotes many different kinds of
coupling. So no, the Document class is not a great example of good
class design, since it isn’t easy to change. On the contrary, it is
hard to change and thus a great example of a violation of the SRP:
the classes deriving from Document and users of the Document class
change for many reasons because we have created a strong coupling
between several orthogonal, unrelated aspects. To summarize, deriving
classes and users of documents may change for any of the following reasons:
-
The implementation details of the
exportToJSON()function change because of a direct dependency on the used JSON library -
The signature of the
exportToJSON()function changes because the underlying implementation changes -
The
Documentclass and theserialize()function change because of a direct dependency on theByteStreamclass -
The implementation details of the
serialize()function change because of a direct dependency on the implementation details -
All types of documents change because of the direct dependency on the
DocumentTypeenumeration
Obviously, this design promotes more changes, and every single change
would be harder. And of course, in the general case, there is the danger that additional orthogonal aspects are artificially coupled
inside documents, which would further increase the complexity of
making a change. In addition, some of these changes are definitely
not restricted to a single place in the codebase. In particular,
changes to the implementation details of exportToJSON() and
serialize() would not be restricted to only one class, but likely
all kinds of documents (PDF, Word, and so on). Therefore, a change
would affect a significant number of places all over the codebase, which poses a maintenance risk.
Logical Versus Physical Coupling
The coupling isn’t limited to logical coupling but also extends
to physical coupling. Figure 1-2 illustrates that
coupling. Let’s assume that there is a User class on the
low level of our architecture that needs to use documents that
reside on a higher level of the architecture. Of course
the User class depends directly on the Document class, which is a necessary
dependency—an intrinsic dependency of the given problem. Thus, it
should not be a concern for us. However, the (potential) physical
dependency of Document on the
selected JSON library and the direct dependency on the ByteStream
class cause an indirect, transitive dependency of User to the
JSON library and ByteStream, which reside on the highest level of
our architecture. In the worst case, this means that changes to the JSON library or
the ByteStream class have an effect on User. Hopefully it’s easy to see that this is an artificial, not an intentional, dependency: a User shouldn’t have to depend on
JSON or serialization.
Note
I should explicitly state that there is
a potential physical dependency of Document on the select
JSON library. If the <Document.h> header file includes any
header from the JSON library of choice (as indicated in the code
snippet at the beginning of “An Example of Artificial Coupling”), for instance because the exportToJSON() function
expects some arguments based on that library, then there is a clear
dependency on that library. However, if the interface can properly
abstract from these details and the
<Document.h> header doesn’t
include anything from the JSON library, the physical dependency might
be avoided. Thus, it depends on how well the dependencies can be (and
are) abstracted.
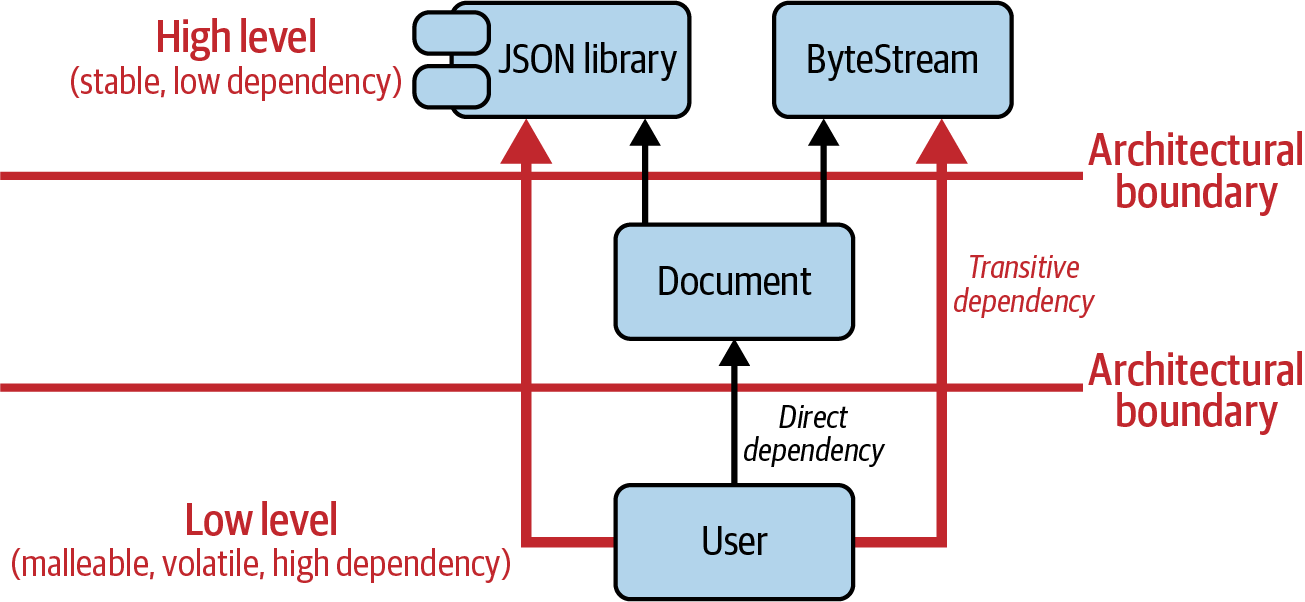
Figure 1-2. The strong transitive, physical coupling between User and orthogonal aspects like JSON and serialization.
“High level, low level—now I’m confused,” you complain. Yes, I know that these two terms usually cause some confusion. So before we move on, let’s agree on the terminology for high level and low level. The origin of these two terms relates to the way we draw diagrams in the Unified Modeling Language (UML): functionality that we consider to be stable appears on the top, on a high level. Functionality that changes more often and is therefore considered to be volatile or malleable appears on the bottom, the low level. Unfortunately, when we draw architectures, we often try to show how things build on one another, so the most stable parts appear at the bottom of an architecture. That, of course, causes some confusion. Independent of how things are drawn, just remember these terms: high level refers to stable parts of your architecture, and low level refers to the aspects that change more often or are more likely to change.
Back to the problem: the SRP advises that we should separate concerns and the things that do not truly belong, i.e., the noncohesive (adhesive) things. In other words, it advises us to separate the things that change for different reasons into variation points. Figure 1-3 shows the coupling situation if we isolate the JSON and serialization aspects into separate concerns.
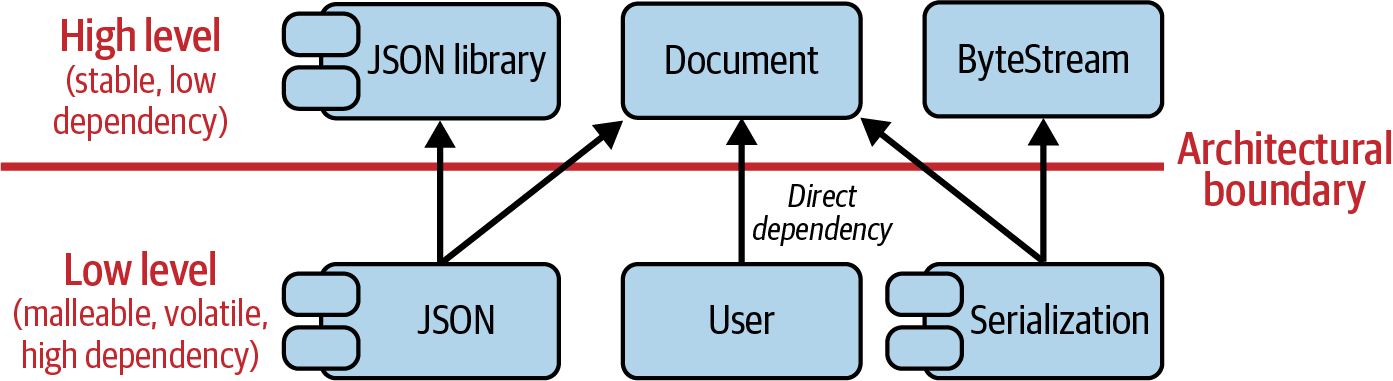
Figure 1-3. Adherence to the SRP resolves the artificial coupling between User and JSON and serialization.
Based on this advice, the Document class is refactored in the following
way:
classDocument{public:// ...virtual~Document()=default;// No more 'exportToJSON()' and 'serialize()' functions.// Only the very basic document operations, that do not// cause strong coupling, remain.// ...};
The JSON and serialization aspects are just not part of the fundamental
pieces of functionality of a Document class. The Document class should
merely represent the very basic operations of different kinds of documents.
All orthogonal aspects should be separated. This will make changes
considerably easier. For instance, by isolating the JSON aspect into a
separate variation point and into the new JSON component, switching
from one JSON library to another will affect only this one component.
The change could be done in exactly one place and would happen in
isolation from all the other, orthogonal aspects. It would also be easier
to support the JSON format by means of several JSON libraries. Additionally,
any change to how documents are serialized would affect only one component
in the code: the new Serialization component. Also, Serialization would
act as a variation point that enables isolated, easy change. That would
be the optimal situation.
After your initial disappointment with the Document example, I
can see you’re looking happier again. Perhaps there’s even an
“I knew it!” smile on your face. However, you’re not entirely
satisfied yet: “Yes, I agree with the general idea of separating
concerns. But how do I have to structure my software to separate
concerns? What do I have to do to make it work?” That is an
excellent question, but one with many answers that I’ll address in the upcoming chapters. The first and most important point,
however, is the identification of a variation point, i.e., some
aspect in your code where changes are expected. These variation points
should be extracted, isolated, and wrapped, such that there are no
longer any dependencies on these variations. That will ultimately
help make changes easier.
“But that is still only superficial advice!” I hear you say. And you’re correct. Unfortunately, there is no single answer and there is no simple answer. It depends. But I promise to give many concrete answers for how to separate concerns in the upcoming chapters. After all, this is a book on software design, i.e., a book on managing dependencies. As a little teaser, in Chapter 3 I will introduce a general and practical approach to this problem: design patterns. With this general idea in mind, I will show you how to separate concerns using different design patterns. For instance, the Visitor, Strategy, and External Polymorphism design patterns come to mind. All of these patterns have different strengths and weaknesses, but they share the property of introducing some kind of abstraction to help you to reduce dependencies. Additionally, I promise to take a close look at how to implement these design patterns in modern C++.
Tip
I will introduce the Visitor design pattern in “Guideline 16: Use Visitor to Extend Operations”, and the Strategy design pattern in “Guideline 19: Use Strategy to Isolate How Things Are Done”. The External Polymorphism design pattern will be the topic of “Guideline 31: Use External Polymorphism for Nonintrusive Runtime Polymorphism”.
Don’t Repeat Yourself
There is a second, important aspect to changeability. To explain this aspect, I will introduce another example: a hierarchy of items. Figure 1-4 gives an impression of this hierarchy.
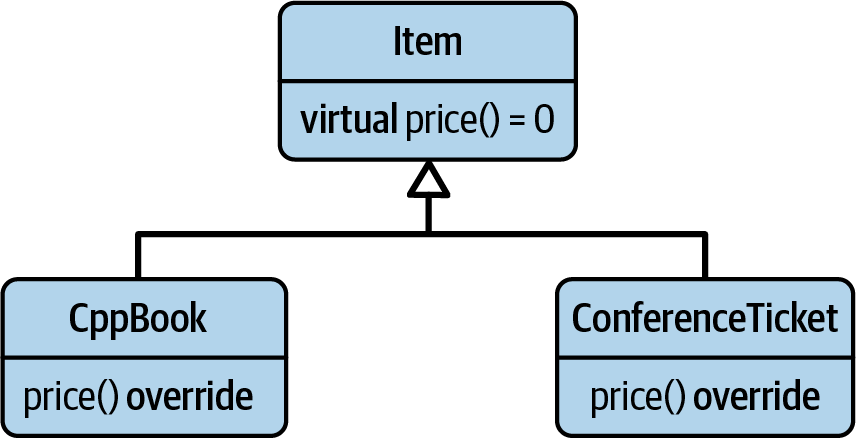
Figure 1-4. The Item class hierarchy.
At the top of that hierarchy is the Item base class:
//---- <Money.h> ----------------classMoney{/*...*/};Moneyoperator*(Moneymoney,doublefactor);Moneyoperator+(Moneylhs,Moneyrhs);//---- <Item.h> ----------------#include<Money.h>classItem{public:virtual~Item()=default;virtualMoneyprice()const=0;};
The Item base class represents an abstraction for any kind
of item that has a price tag (represented by the Money class).
Via the price() function, you can query for that price. Of course
there are many possible items, but for illustration purposes, we
restrict ourselves to CppBook and ConferenceTicket:
//---- <CppBook.h> ----------------#include<Item.h>#include<Money.h>#include<string>classCppBook:publicItem{public:explicitCppBook(std::stringtitle,std::stringauthor,Moneyprice):title_(std::move(title)),author_(std::move(author)),priceWithTax_(price*1.15)// 15% tax rate{}std::stringconst&title()const{returntitle_;}std::stringconst&author()const{returnauthor_;}Moneyprice()constoverride{returnpriceWithTax_;}private:std::stringtitle_;std::stringauthor_;MoneypriceWithTax_;};
The constructor of the CppBook class expects a title and author
in the form of strings and a price in the form of Money
(![]() ).28
Apart from that, it only allows you to access the title, the author, and
the price with the
).28
Apart from that, it only allows you to access the title, the author, and
the price with the title(), author(), and price() functions
(![]() ,
,
![]() , and
, and
![]() ).
However, the
).
However, the price() function is a little special: obviously, books are subject
to taxes. Therefore, the original price of the book needs to be adapted according to a given tax rate. In this example, I assume an imaginary tax rate of 15%.
The ConferenceTicket class is the second example of an Item:
//---- <ConferenceTicket.h> ----------------#include<Item.h>#include<Money.h>#include<string>classConferenceTicket:publicItem{public:explicitConferenceTicket(std::stringname,Moneyprice):name_(std::move(name)),priceWithTax_(price*1.15)// 15% tax rate{}std::stringconst&name()const{returnname_;}Moneyprice()constoverride{returnpriceWithTax_;}private:std::stringname_;MoneypriceWithTax_;};
ConferenceTicket is very similar to the CppBook class, but
expects only the name of the conference and the price in the constructor
(![]() ).
Of course, you can access the name and the price with the
).
Of course, you can access the name and the price with the
name() and price() functions, respectively. Most importantly,
however, the price for a C++ conference is also subject
to taxes. Therefore, we again adapt the original price according to the imaginary
tax rate of 15%.
With this functionality available, we can go ahead and create a couple of
Items in the main() function:
#include<CppBook.h>#include<ConferenceTicket.h>#include<algorithm>#include<cstdlib>#include<memory>#include<vector>intmain(){std::vector<std::unique_ptr<Item>>items{};items.emplace_back(std::make_unique<CppBook>("Effective C++","Meyers",19.99));items.emplace_back(std::make_unique<CppBook>("C++ Templates","Josuttis",49.99));items.emplace_back(std::make_unique<ConferenceTicket>("CppCon",999.0));items.emplace_back(std::make_unique<ConferenceTicket>("Meeting C++",699.0));items.emplace_back(std::make_unique<ConferenceTicket>("C++ on Sea",499.0));Moneyconsttotal_price=std::accumulate(begin(items),end(items),Money{},[](Moneyaccu,autoconst&item){returnaccu+item->price();});// ...returnEXIT_SUCCESS;}
In main(), we create a couple of items (two books and three conferences)
and compute the total price of all items.29 The total price will, of course, include
the imaginary tax rate of 15%.
That sounds like a good design. We have separated the specific
kinds of items and are able to change how the price of each
item is computed in isolation. It seems that we have fulfilled
the SRP and extracted and isolated the variation points.
And of course, there are more items. Many more. And all of
them will make sure that the applicable tax rate is
properly taken into account. Great! Now, while this Item
hierarchy will make us happy for some time, the design
unfortunately has a significant flaw. We might not realize
it today, but there’s always a looming shadow in the
distance, the nemesis of problems in software: change.
What happens if for some reason the tax rate changes? What
if the 15% tax rate is lowered to 12%? Or raised to 16%? I can
still hear the arguments from the day the initial design was
committed into the codebase: “No, that will never happen!”
Well, even the most unexpected thing may happen. For instance,
in Germany, the tax rate was lowered from 19% to 16% for half
a year in 2021. This, of course, would mean that we
have to change the tax rate in our codebase. Where do we
apply the change? In the current situation, the change
would pretty much affect every class deriving from the Item
class. The change would be all over the codebase!
Just as much as the SRP advises separating variation points, we should take care not to duplicate information throughout the codebase. As much as everything should have a single responsibility (a single reason to change), every responsibility should exist only once in the system. This idea is commonly called the Don’t Repeat Yourself (DRY) principle. This principle advises us to not duplicate some key information in many places—but to design the system such that we can make the change in only one place. In the optimal case, the tax rate(s) should be represented in exactly one place to enable you to make an easy change.
Usually the SRP and the DRY principles work together very nicely. Adhering the SRP will often lead to adhering to DRY as well, and vice versa. However, sometimes adhering to both requires some extra steps. I know you’re eager to learn what these extra steps are and how to solve the problem, but at this point, it’s sufficient to point out the general idea of SRP and DRY. I promise to revisit this problem and to show you how to solve it (see “Guideline 35: Use Decorators to Add Customization Hierarchically”).
Avoid Premature Separation of Concerns
At this point, I’ve hopefully convinced you that adhering to SRP and DRY is a very reasonable idea. You might even be so committed that you plan to separate everything—all classes and functions—into the most tiny units of functionality. After all, that’s the goal, right? If this is what you’re thinking right now, please stop! Take a deep breath. And one more. And then please listen carefully to the wisdom of Katerina Trajchevska:30
Don’t try to achieve SOLID, use SOLID to achieve maintainability.
Both SRP and DRY are your tools for achieving better maintainability and simplifying change. They are not your goals. While both are of utmost importance in the long run, it can be very counterproductive to separate entities without a clear idea about what kind of change will affect you. Designing for change usually favors one specific kind of change but might unfortunately make other kinds of change harder. This philosophy is part of the commonly known YAGNI principle (You Aren’t Gonna Need It), which warns you about overengineering (see also “Guideline 5: Design for Extension”). If you have a clear plan, if you know what kind of change to expect, then apply SRP and DRY to make that kind of change simple. However, if you don’t know what kind of change to expect, then don’t guess—just wait. Wait until you have a clear idea about what kind of change to expect and then refactor to make the change as easy as possible.
Tip
Just don’t forget that one aspect of easily changing things is having unit tests in place that give you confirmation that the change did not break the expected behavior.
In summary, change is expected in software and therefore it’s vital to design for change. Separate concerns and minimize duplication to enable you to easily change things without being afraid to break other, orthogonal aspects.
Guideline 3: Separate Interfaces to Avoid Artificial Coupling
Let’s revisit the Document example from “Guideline 2: Design for Change”. I know, by now
you probably feel like you’ve seen enough documents, but believe me, we’re not done yet.
There’s still an important coupling aspect to address. This time we don’t focus
on the individual functions in the Document class but on the interface as a
whole:
classDocument{public:// ...virtual~Document()=default;virtualvoidexportToJSON(/*...*/)const=0;virtualvoidserialize(ByteStream&bs,/*...*/)const=0;// ...};
Segregate Interfaces to Separate Concerns
The Document requires deriving classes to handle both JSON exports and
serialization. While, from the point of view of a document, this may seem reasonable (after all, all documents should be exportable into JSON and
serializable), it unfortunately causes another kind of coupling. Imagine
the following user code:
voidexportDocument(Documentconst&doc){// ...doc.exportToJSON(/* pass necessary arguments */);// ...}
The exportDocument() function is solely interested in exporting a given
document to JSON. In other words, the exportDocument() function is not
concerned with serializing a document or with any other aspect that Document
has to offer. Still, as a result of the definition of the Document interface,
due to coupling many orthogonal aspects together, the exportDocument()
function depends on much more than just the JSON export. All of these dependencies
are unnecessary and artificial. Changing any of these—for instance, the ByteStream class or the signature of the serialize() function—has an effect on all users of Document, even those that do
not require serialization. For any change, all the users, including the
exportDocument() function, would need to be recompiled, retested, and, in the
worst case, redeployed (for instance, if delivered in a separate library).
The same thing happens, however, if the Document class is extended
by another function—for instance, an export to another document type. The problem gets bigger the more orthogonal functionality is coupled
in
Document: any change carries the risk of causing a rippling effect
throughout the codebase. Which is sad indeed, as interfaces should help to
decouple, not introduce artificial coupling.
This coupling is caused by a violation of the Interface Segregation Principle (ISP), which is the I in the SOLID acronym:
Clients should not be forced to depend on methods that they do not use.31
The ISP advises separating concerns by segregating (decoupling) interfaces. In our case, there should be two separate interfaces representing the two orthogonal aspects of JSON export and serialization:
classJSONExportable{public:// ...virtual~JSONExportable()=default;virtualvoidexportToJSON(/*...*/)const=0;// ...};classSerializable{public:// ...virtual~Serializable()=default;virtualvoidserialize(ByteStream&bs,/*...*/)const=0;// ...};classDocument:publicJSONExportable,publicSerializable{public:// ...};
This separation does not make the Document class obsolete. On the contrary,
the
Document class still represents the requirements posed on all documents.
However, this separation of concerns now enables you to minimize dependencies
to only the set of functions that is actually required:
voidexportDocument(JSONExportableconst&exportable){// ...exportable.exportToJSON(/* pass necessary arguments */);// ...}
In this form, by depending only on the segregated JSONExportable interface,
the exportDocument() function no longer depends on the serialization
functionality and thus no longer depends on the ByteStream class. Thus,
the segregation of interfaces has helped to reduce coupling.
“But isn’t that just a separation of concerns?” you ask. “Isn’t that
just another example of the SRP?” Yes, indeed
it is. I agree that we’ve essentially identified two
orthogonal aspects, separated them, and thus applied the SRP to the Document
interface. Therefore, we could say that ISP and SRP are the same. Or
at least that ISP is a special case of the SRP because of the focus
of the ISP on interfaces. This attitude seems to be the common opinion
in the community, and I agree. However, I still consider it
valuable to
talk about ISP. Despite the fact that ISP may only be a special case,
I would argue that it’s an important special case. Unfortunately, it is
often very tempting to aggregate unrelated, orthogonal aspects into
an interface. It might even happen to you that you couple separate aspects into an interface. Of course, I would never imply that you did this on
purpose, but unintentionally, accidentally. We often do not pay enough
attention to these details. Of course, you argue, “I would never do that.”
However, in “Guideline 19: Use Strategy to Isolate How Things Are Done”,
you’ll see an example that might convince you how easily this can happen.
Since changing interfaces later may be extremely difficult, I believe
it pays off to raise awareness of this problem with interfaces. For
that reason, I didn’t drop the ISP but included it as an important and
noteworthy case of the SRP.
Minimizing Requirements of Template Arguments
Although it appears as if the ISP is applicable only to base classes, and
although the ISP is mostly introduced by means of object-oriented programming,
the general idea of minimizing the dependencies introduced by interfaces can
also be applied to templates. Consider the std::copy() function, for instance:
template<typenameInputIt,typenameOutputIt>OutputItcopy(InputItfirst,InputItlast,OutputItd_first);
In C++20, we could apply concepts to express the requirements:
template<std::input_iteratorInputIt,std::output_iteratorOutputIt>OutputItcopy(InputItfirst,InputItlast,OutputItd_first);
std::copy() expects a pair of input iterators as the range to copy
from, and an output iterator to the target range. It explicitly requires
input iterators and output iterators, since it does not need any other
operation. Thus, it minimizes the requirements on the passed arguments.
Let’s assume that std::copy() requires std::forward_iterator
instead of std::input_iterator and std::output_iterator:
template<std::forward_iteratorForwardIt>ForwardItcopy(ForwardItfirst,ForwardItlast,ForwardItd_first);
This would unfortunately limit the usefulness of the std::copy()
algorithm. We would no longer be able to copy from input streams, since they don’t generally provide the multipass guarantee and do not enable us to write.
That would be unfortunate. However, focusing on dependencies, std::copy() would
now depend on operations and requirements it doesn’t need. And iterators
passed to std::copy() would be forced to provide additional operations,
so std::copy() would force dependencies on them.
This is only a hypothetical example, but it illustrates how important the separation of concerns in interfaces is. Obviously, the solution is the realization that input and output capabilities are separate aspects. Thus, after separating concerns and after applying the ISP, the dependencies are significantly reduced.
Guideline 4: Design for Testability
As discussed in “Guideline 1: Understand the Importance of Software Design”, software changes. It’s expected to change. But every time you change something in your software, you run the risk of breaking something. Of course, not intentionally but accidentally, despite your best efforts. The risk is always there. As an experienced developer, however, you don’t lose any sleep over that. Let there be risk—you don’t care. You have something that protects you from accidentally breaking things, something that keeps the risk at a minimum: your tests.
The purpose of having tests is to be able to assert that all of your software functionality still works, despite constantly changing things. So obviously, tests are your protection layer, your life vest. Tests are essential! However, first of all, you have to write the tests. And in order to write tests and set up this protective layer, your software needs to be testable: your software must be written in a way that it is possible, and in the best case even easily possible, to add tests. Which brings us to the heart of this guideline: software should be designed for testability.
How to Test a Private Member Function
“Of course I have tests,” you argue. “Everyone should have tests. That’s common knowledge, isn’t it?” I completely agree. And I believe you that your codebase is equipped with a reasonable test suite.32 But surprisingly, despite everyone agreeing to the need for tests, not every piece of software is written with this awareness in mind.33 In fact, a lot of code is hard to test. And sometimes this is simply because the code is not designed to be tested.
To give you an idea, I have a challenge for you. Take a look at the
following Widget class. Widget holds a collection of Blob objects, which once in a
while need to be updated. For that purpose, Widget provides the updateCollection()
member function, which we now assume is so important that we need to write a test for
it. And this is my challenge: how would you test the updateCollection() member function?
classWidget{// ...private:voidupdateCollection(/* some arguments needed to update the collection */);std::vector<Blob>blobs_;/* Potentially other data members */};
I assume that you immediately see the real challenge: the updateCollection() member
function is declared in the private section of the class. This means that there is no
direct access from the outside and therefore no direct way of testing it.
So take a few seconds to think about this…
“It’s private, yes, but this is still not much of a challenge. There are multiple ways
I can do that,” you say. I agree, there are multiple ways you could try. So please,
go ahead. You weigh your options, then you come up with your first idea: “Well,
the easiest approach would be to test the function via some other, public member
function that internally calls the updateCollection() function.” That sounds like
an interesting first idea. Let’s assume that the collection needs to be updated
when a new Blob is added to it. Calling the addBlob() member function would
trigger the
updateCollection() function:
classWidget{public:// ...voidaddBlob(Blobconst&blob,/*...*/){// ...updateCollection(/*...*/);// ...}private:voidupdateCollection(/* some arguments needed to update the collection */);std::vector<Blob>blobs_;/* Potentially other data members */};
Although this sounds like a reasonable thing to do, it’s also something you should
avoid if possible. What you are suggesting is a so-called white box test. A white box
test knows about the internal implementation details of some function
and tests based on that knowledge. This introduces a dependency of the
test code on the implementation details of your production code. The problem with this approach
is that software changes. Code changes. Details change. For instance, at some point in the
future, the addBlob() function might be rewritten so it does not have to update the collection
anymore. If this happens, your test no longer performs the task it was written to do. You
would lose your updateCollection() test, potentially without even realizing it. Therefore,
a white box test poses a risk. Just as much as you should avoid and reduce dependencies in
your production code (see “Guideline 1: Understand the Importance of
Software Design”), you should also
avoid dependencies between your tests and the details of your production code.
What we really need is a black box test. A black box test does not make any assumptions about internal implementation details, but tests only for expected behavior. Of course, this kind of test can also break if you change something, but it shouldn’t break if some implementation details change—only if the expected behavior changes.
“OK, I get your point,” you say. “But you don’t suggest making the updateCollection()
function public, do you?” No, rest assured that isn’t what I’m suggesting. Of course,
sometimes this may be a reasonable approach. But in our case, I doubt that this would be
a wise move. The updateCollection() function should not be called just for
fun. It should be called only for a good reason, only at the right time, and probably
to preserve some kind of invariant. This is something we should not entrust a user with. So
no, I don’t think that the function would be a good candidate for the public section.
“OK, good, just checking. Then let’s simply make the test a friend of the Widget class.
This way it would have full access and could call the private member function unhindered”:
classWidget{// ...private:friendclassTestWidget;voidupdateCollection(/* some arguments needed to update the collection */);std::vector<Blob>blobs_;/* Potentially other data members */};
Yes, we could add a friend. Let’s assume that there is the TestWidget
test fixture, containing all the tests for the Widget class. We could make this test
fixture a friend of the Widget class. Although this may sound like another reasonable
approach, I unfortunately have to be the spoilsport again. Yes, technically this would solve
the problem, but from a design perspective, we’ve just introduced an artificial dependency
again. By actively changing the production code to introduce the friend declaration, the
production code now knows about the test code. And while the test code should of course know
about the production code (that’s the point of the test code), the production code should
not have to know about the test code. This introduces a cyclic dependency, which is an unfortunate and artificial dependency.
“You sound like this is the worst thing in the world. Is it really that bad?” Well,
sometimes this may actually be a reasonable solution. It definitely is a simple and quick
solution. However,
since right now we have the time to discuss all of our options, there definitely must
be something better than adding a friend.
Note
I don’t want to make things worse, but in C++ we don’t have a lot of
friends. Yes, I know, this sounds sad and lonely, but of course I mean the keyword
friend: in C++, friend is not your friend. The reason is that friends
introduce coupling, mostly artificial coupling, and we should avoid coupling. Of course,
exceptions can be made for the good friends, the ones you cannot live without, such as
hidden friends, or
idiomatic uses of friend, such as the
Passkey idiom. A test is more like a friend
on social media, so declaring a test a friend does not sound like a good choice.
“OK, then let’s switch from private to protected and make the test derive from
the
Widget class,” you suggest. “This way, the test would gain full access to the
updateCollection() function”:
classWidget{// ...protected:voidupdateCollection(/* some arguments needed to update the collection */);std::vector<Blob>blobs_;/* Potentially other data members */};classTestWidget:privateWidget{// ...};
Well, I have to admit that technically this approach would work. However, the fact that you’re suggesting inheritance to solve this issue tells me that we definitely have to talk about the meaning of inheritance and how to use it properly. To quote the two pragmatic programmers:34
Inheritance is rarely the answer.
Since we’ll be focusing on this topic fairly soon, let me just say that it feels like
we’re abusing inheritance for the sole reason of gaining access to nonpublic member
functions. I’m pretty certain this isn’t why inheritance was invented. Using
inheritance to gain access to the protected section of a class is like the bazooka
approach to something that should be very simple. It is, after all, almost identical to
making the function public, because everyone can easily gain access. It seems we
really haven’t designed the class to be easily testable.
“Come on, what else could we do? Or do you really want me to use the preprocessor and
define all private labels as public?”:
#define private publicclassWidget{// ...private:voidupdateCollection(/* some arguments needed to update the collection */);std::vector<Blob>blobs_;/* Potentially other data members */};
OK, let’s take a deep breath. Although this last approach may
seem funny, keep in mind that we have now left the range of reasonable
arguments.35
If we seriously consider using the preprocessor to hack our way into the
private section of the Widget class, then all is lost.
The True Solution: Separate Concerns
“OK then, what should I do to test the private member function? You
have already discarded all the options.” No, not all the options. We have not yet discussed
the one design approach that I highlighted in “Guideline 2: Design for Change”: separation of
concerns. My approach would be to extract the private member function from the class
and make it a separate entity in our codebase. My preferred solution in this case is to
extract the member function as a free function:
voidupdateCollection(std::vector<Blob>&blobs,/* some arguments needed to update the collection */);classWidget{// ...private:std::vector<Blob>blobs_;/* Potentially other data members */};
All calls to the previous member function could be replaced with a call to the free
updateCollection() function by just adding blobs_ as the first function argument.
Alternatively, if there is some state attached to the function, we extract it in the form
of another class. Either way, we design the resulting code such that it’s easy, perhaps
even trivial, to test:
namespacewidgetDetails{classBlobCollection{public:voidupdateCollection(/* some arguments needed to update the collection */);private:std::vector<Blob>blobs_;};}// namespace widgetDetailsclassWidget{// ...private:widgetDetails::BlobCollectionblobs_;/* Other data members */};
“You cannot be serious!” you exclaim. “Isn’t this the worst of all options?
Aren’t we artificially separating two things that belong together? And isn’t the
SRP telling us that we should keep the things that
belong together close to one another?” Well, I don’t think so. On the contrary, I firmly
believe that only now are we adhering to the SRP: the SRP states that we should
isolate the things that do not belong together, the things that can change for different
reasons. Admittedly, at first sight, it may appear as if Widget and updateCollection()
belong together, since after all, the blob_ data member needs to be updated once in a
while. However, the fact that the updateCollection() function isn’t properly testable
is a clear indication that the design does not fit yet: if anything that needs explicit
testing can’t be tested, something is amiss. Why make our lives so much harder and hide
the function to test in the
private section of the Widget class? Since testing plays
a vital role in the presence of change, testing represents just another way to help
decide which things belong together. If the updateCollection()
function is important enough that we want to test it in isolation, then apparently it
changes for a reason other than
Widget. This indicates that Widget and
updateCollection() do not belong together. Based on the SRP, the updateCollection()
function should be extracted from the class.
“But isn’t this against the idea of encapsulation?” you ask. “And don’t you
dare wave away encapsulation. I consider encapsulation to be very important!” I agree,
it is very important, fundamentally so! However, encapsulation
is just one more reason to separate concerns. As Scott Meyers claims in his book,
Effective C++, extracting
functions from a class is a step toward increasing
encapsulation. According to Meyers, you should generally prefer nonmember non-friend
functions to member functions.36 This is because every member function has full access to every member of a class, even the private
members. However, in the extracted form, the
updateCollection() function is restricted to
just the public interface of the Widget class and is not able to access the private
members. Therefore, these private members become a little more encapsulated. Note that the same
argument holds true for extracting the BlobCollection class: the BlobCollection class
is not able to touch the nonpublic members of the Widget class, and therefore Widget
also becomes a little more encapsulated.
By separating concerns and extracting this piece of functionality, you now gain several
advantages. First, as just discussed, the Widget class becomes more encapsulated.
Fewer members can access the private members. Second, the extracted
updateCollection() function is easily, even trivially, testable. You don’t even
need a Widget for that but instead can either pass std::vector<Blob> as the first
argument (not the implicit first argument of any member function, the this pointer)
or call the public member function. Third, you don’t have to change any other
aspect in the
Widget class: you simply pass the blobs_ member to the updateCollection()
function whenever you need to update the collection. No need to
add any other public getter. And, probably most importantly, you can now change
the function in isolation, without having to deal with Widget. This indicates
that you have reduced dependencies. While in the initial setup the updateCollection()
function was tightly coupled to the Widget class (yes, the this pointer), we have
now severed these ties. The
updateCollection() function is now a separate service that
might even be reused.
I can see that you still have questions. Maybe you’re concerned that this means
you shouldn’t have any member functions anymore. No, to be clear, I did not suggest
that you should extract each and every member function from your classes. I merely
suggested you take a closer look at those functions that need to be tested but are
placed in the private section of your class. Also, you might wonder how this works
with virtual functions, which cannot be extracted in the form of a free function. Well,
there’s no quick answer for that, but it’s something that we will deal with in many
different ways throughout this book. My objective will always be to reduce coupling
and to increase testability, even by separating virtual functions.
In summary, do not hinder your design and testability with artificial coupling and artificial boundaries. Design for testability. Separate concerns. Free your functions!
Guideline 5: Design for Extension
There is an important aspect about changing software that I haven’t highlighted yet: extensibility. Extensibility should be one of the primary goals of your design. Because, frankly speaking, if you’re no longer able to add new functionality to your code then your code has reached the end of its lifetime. Thus, adding new functionality—extending the codebase—is of fundamental interest. For that reason, extensibility should indeed be one of your primary goals and a driving factor for good software design.
The Open-Closed Principle
Design for extension is unfortunately not something that just falls into your lap or magically materializes. No,
you will have to explicitly take extensibility into account when
designing software. We’ve already seen
an example of a naive approach of serializing documents in
“Guideline 2: Design for Change”. In that context, we used a Document base
class with a pure virtual serialize() function:
classDocument{public:// ...virtual~Document()=default;virtualvoidserialize(ByteStream&bs,/*...*/)const=0;// ...};
Since serialize() is a pure virtual function, it needs to be
implemented by all deriving classes, including the PDF class:
class:publicDocument{public:// ...voidserialize(ByteStream&bs,/*...*/)constoverride;// ...};
So far, so good. The interesting question is: how do we implement the
serialize() member function? One requirement is that at a later point
in time we are able to convert the bytes back into a PDF instance (we want to deserialize bytes back to a PDF). For that purpose, it is
essential to store the information that the bytes represent. In
“Guideline 2: Design for Change”, we accomplished this with an
enumeration:
enumclassDocumentType{,word,// ... Potentially many more document types};
This enumeration can now be used by all derived classes to put the type
of the document at the beginning of the byte stream. This way, during
deserialization, it’s easy to detect which kind of document is stored.
Sadly, this design choice turns out to be an unfortunate decision.
With that enumeration, we have accidentally coupled all kinds of
document: the PDF class knows
about the Word format. And of course the corresponding Word class would
know about the PDF format. Yes, you are correct—they don’t know about
the implementation details, but they are still aware of each other.
This coupling situation is illustrated in Figure 1-5.
From an architectural point of view, the DocumentType enumeration
resides on the same level as the PDF and Word classes. Both
types of documents use (and thus depend on) the DocumentType
enumeration.
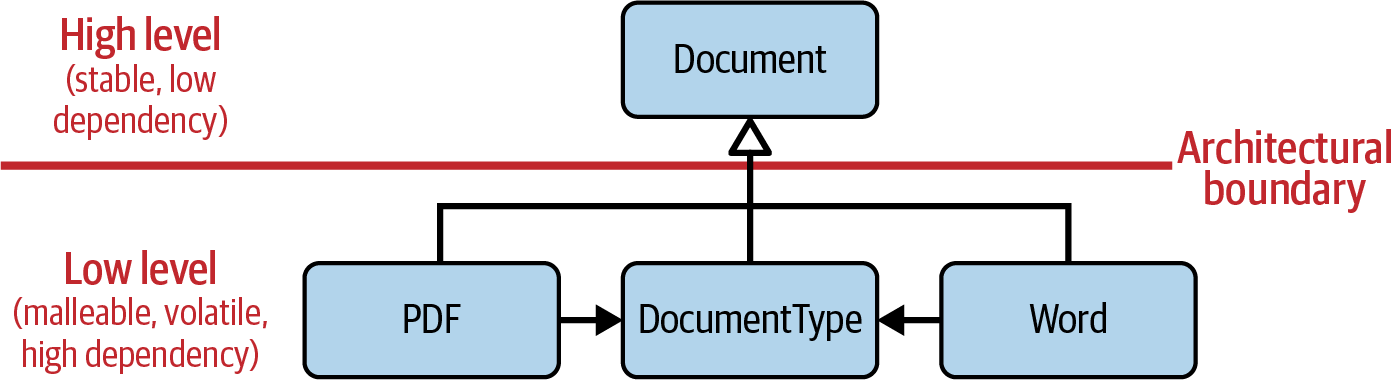
Figure 1-5. Artificial coupling of different document types via the DocumentType
enumeration.
The problem with this becomes obvious if we try to extend the functionality.
Next to PDF and Word, we now also want to support a plain XML format. Ideally, all we should have to do is add the XML class as deriving from the Document class. But, unfortunately, we also
have to adapt the DocumentType enumeration:
enumclassDocumentType{,word,xml,// The new type of document// ... Potentially many more document types};
This change will at least cause all the other document types (PDF,
Word, etc.) to recompile. Now you may just shrug your shoulders and think, “Oh well! It just needs to recompile.” Well, note that I said at least. In the worst case, this design has significantly limited others to extend the code—i.e., to add new kinds of documents—because not everyone is able to extend the DocumentType enumeration. No, this kind of coupling just doesn’t feel right: PDF and Word should be entirely unaware of the new XML format. They shouldn’t see
or feel a thing, not even a recompilation.
The problem in this example can be explained as a violation of the Open-Closed Principle (OCP). The OCP is the second of the SOLID principles. It advises us to design software such that it is easy to make the necessary extensions:37
Software artifacts (classes, modules, functions, etc.) should be open for extension, but closed for modification.
The OCP tells us that we should be able to extend our software (open for extension). However, the extension should be easy and, in the best case, possible by just adding new code. In other words, we shouldn’t have to modify existing code (closed for modification).
In theory, the extension should be easy: we should only have to add the
new derived class XML. This new class alone would not require any
modifications in any other piece of code. Unfortunately, the
serialize() function artificially couples the different kinds of
documents and requires a modification of the DocumentType enumeration.
This modification, in turn, has an impact on the other types of Document,
which is exactly what the OCP advises against.
Luckily, we’ve already seen a solution for how to achieve that for the
Document example. In this case, the right thing to do is to separate
concerns (see Figure 1-6).
By separating concerns, by grouping the things that truly belong together,
the accidental coupling between different kinds of documents is gone. All
code dealing with serialization is now properly grouped inside the
Serialization component, which can logically reside on another level of
the architecture. Serialization depends on all types of documents (PDF,
Word, XML, etc.), but none of the document types depend on
Serialization. In addition, none of the documents are aware of
any other type of document (as it should be).
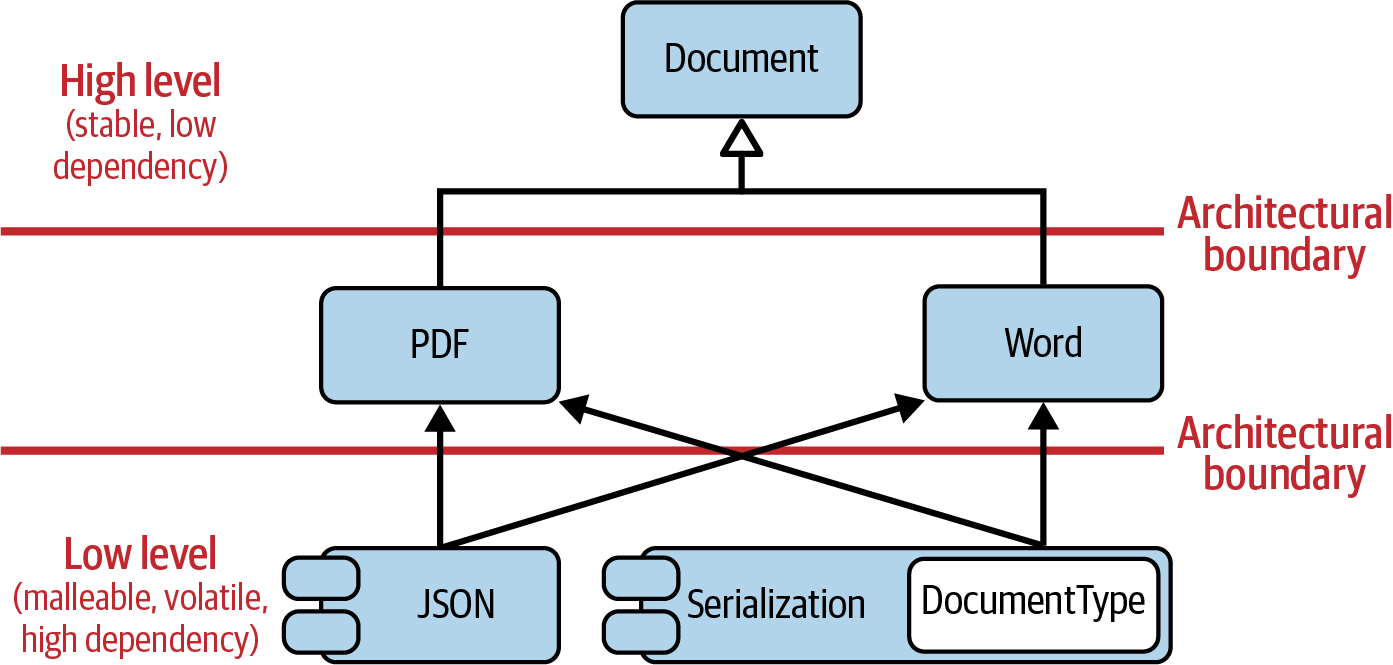
Figure 1-6. Separation of concerns resolves the violation of the OCP
“Wait a second!” you say. “In the code for the serialization, we still
need the enumeration, don’t we? How else would I store the information
about what the stored bytes represent?” I’m glad you’re making this
observation. Yes, inside the
Serialization component we will still (very
likely) need something like the DocumentType enumeration. However, by separating concerns, we have properly resolved this dependency problem. None
of the different types of documents depends on the DocumentType enumeration
anymore. All dependency arrows now go from the low level (the
Serialization
component) to the high level (PDF and Word). And that property is essential
for a proper, good architecture.
“But what about adding a new type of document? Doesn’t that require a
modification in the Serialization component?” Again, you are absolutely
correct. Still, this is not a violation of OCP, which advises that we
should not have to modify existing code on the same architectural level or
on higher levels. However, there is no way you can control or prevent
modifications on the lower levels. Serialization must depend on all
types of documents and therefore must be adapted for every new type of
document. For that reason, Serialization must
reside on a lower level (think depending level) of our architecture.
As also discussed in “Guideline 2: Design for Change”, the solution in this example is the separation of concerns. Thus, it appears as if the real solution is to adhere to the SRP. For that reason, there are some critical voices that don’t consider the OCP a separate principle but the same as the SRP. I admit that I understand this reasoning. Very often the separation of concerns already leads to the desired extensibility. It’s something we will experience multiple times throughout this book, in particular when we talk about design patterns. Thus, it stands to reason that SRP and OCP are related or even the same.
On the other hand, in this example we have seen that there are some specific, architectural considerations about the OCP that we didn’t take into account while talking about the SRP. Also, as we will experience in “Guideline 15: Design for the Addition of Types or Operations”, we will often have to make explicit decisions about what we want to extend and how we want to extend it. That decision can significantly influence how we apply the SRP and the way we design our software. Therefore, the OCP seems to be more about the awareness of extensions and conscious decisions about extensions than the SRP. As such, it is perhaps a little more than just an afterthought of the SRP. Or perhaps it just depends.38
Either way, this example indisputably demonstrates that extensibility should be explicitly considered during software design, and that the desire for extending our software in a specific way is an excellent indication for the need to separate concerns. It is important to understand how software will be extended, to identify such customization points, and to design so that this kind of extension can be performed easily.
Compile-Time Extensibility
The Document example may give the impression that all of these design
considerations apply to runtime polymorphism. No, absolutely
not: the same considerations and the same arguments also apply to compile-time
problems. To illustrate this, I now reach for a couple
of examples from the Standard Library. Of course, it is of utmost interest
that you’re able to extend the Standard Library. Yes, you’re supposed to
use the Standard Library, but you are also encouraged to build on it and
add your own pieces of functionality. For that reason, the Standard Library
is designed for extensibility. But interestingly, it isn’t using base classes
for that purpose, but primarily builds on function overloading, templates,
and (class) template specialization.
An excellent example of extension by function overloading is the
std::swap() algorithm. Since C++11, std::swap() has been defined
in this way:
namespacestd{template<typenameT>voidswap(T&a,T&b){Ttmp(std::move(a));a=std::move(b);b=std::move(tmp);}}// namespace std
Due to the fact that std::swap() is defined as a function template,
you can use it for any type: fundamental types like int and double,
Standard Library types like std::string, and, of course, your own
types. However, there may be some types that require special attention,
some types that cannot or should not be swapped by means of std::swap()
(for instance, because they cannot be efficiently moved) but could still
be swapped efficiently by different means. But still, it’s expected that
value types can be swapped, as it is also expressed by
Core Guideline C.83:39
For value-like types, consider providing a
noexceptswap function.
In such a case, you can overload std::swap() for your own type:
namespacecustom{classCustomType{/* Implementation that requires a special form of swap */};voidswap(CustomType&a,CustomType&b){/* Special implementation for swapping two instances of type 'CustomType' */}}// namespace custom
If swap() is used correctly, this custom function will perform a
special kind of swap operation on two instances of CustomType:40
template<typenameT>voidsome_function(T&value){// ...Ttmp(/*...*/);usingstd::swap;// Enable the compiler to consider std::swap for the// subsequent callswap(tmp,value);// Swap the two values; thanks to the unqualified call// and thanks to ADL this would call 'custom::swap()'// ... // in case 'T' is 'CustomType'}
Obviously, std::swap() is designed as a customization point, allowing
you to plug in new custom types and behavior. The same is true of all
algorithms in the Standard Library. Consider, for instance, std::find()
and std::find_if():
template<typenameInputIt,typenameT>constexprInputItfind(InputItfirst,InputItlast,Tconst&value);template<typenameInputIt,typenameUnaryPredicate>constexprInputItfind_if(InputItfirst,InputItlast,UnaryPredicatep);
By means of the template parameters, and implicitly, the corresponding concepts,
std::find() and std::find_if() (just as all other algorithms) enable
you to use your own (iterator) types to perform a search. In addition,
std::find_if() allows you to customize how the comparison of
elements is handled. Thus, these functions are definitely designed for
extension and customization.
The last kind of customization point is template specialization. This
approach is, for instance, used by the std::hash class template. Assuming
the CustomType from the std::swap() example, we can specialize
std::hash explicitly:
template<>structstd::hash<CustomType>{std::size_toperator()(CustomTypeconst&v)constnoexcept{return/*...*/;}};
The design of std::hash puts you in a position to adapt its behavior
for any custom type. Most noteworthy, you are not required
to modify any existing code; it’s enough to provide this separate
specialization to adapt to special requirements.
Almost the entire Standard Library is designed for extension and customization. This shouldn’t come as a surprise, however, because the Standard Library is supposed to represent one of the highest levels in your architecture. Thus, the Standard Library cannot depend on anything in your code, but you depend entirely on the Standard Library.
Avoid Premature Design for Extension
The C++ Standard Library is a great example of designing for extension. Hopefully it gives you a feeling for how important extensibility really is. However, although extensibility is important, this doesn’t mean that you should automatically, without reflection, reach for either base classes or templates for every possible implementation detail just to guarantee extensibility in the future. Just as you shouldn’t prematurely separate concerns, you should also not prematurely design for extension. Of course, if you have a good idea about how your code will evolve, then by all means, go ahead and design it accordingly. However, remember the YAGNI principle: if you do not know how the code will evolve, then it may be wise to wait, instead of anticipating an extension that will never happen. Perhaps the next extension will give you an idea about future extensions, which puts you in a position to refactor the code such that subsequent extensions are easy. Otherwise you might run into the problem that favoring one kind of extension makes other kinds of extensions much more difficult (see, for instance, “Guideline 15: Design for the Addition of Types or Operations”). That is something you should avoid, if possible.
In summary, designing for extension is an important part of design for change. Therefore, explicitly keep an eye out for pieces of functionality that are expected to be extended and design the code so that extension is easy.
1 But of course you would never even try to print the current C++ standard. You would either use a PDF of the official C++ standard or use the current working draft. For most of your daily work, however, you might want to refer to the C++ reference site.
2 Unfortunately, I can’t present any numbers, as I can hardly say that I have a complete overview of the vast realm of C++. On the contrary, I might not even have a complete overview of the sources I’m aware of! So please consider this as my personal impression and the way I perceive the C++ community. You may have a different impression.
3 Whether or not the code modification is risky may very much depend on your test coverage. A good test coverage may actually absorb some of the damage bad software design may cause.
4 Kent Beck, Test-Driven Development: By Example (Addison-Wesley, 2002).
5 Robert C. Martin, Clean Architecture (Addison-Wesley, 2017).
6 These are indeed my own words, as there is no single, common definition of software design. Consequently, you may have your own definition of what software design entails and that is perfectly fine. However, note that this book, including the discussion of design patterns, is based on my definition.
7 Just to be clear: computer science is a science (it’s in the name). Software engineering appears to be a hybrid form of science, craft, and art. And one aspect of the latter is software design.
8 With this metaphor, I’m not trying to imply that architects for buildings work at the construction site all day. Very likely, such an architect spends as much time in a comfy chair and in front of a computer as people like you and me. But I think you get the point.
9 Substitution Failure Is Not An Error (SFINAE) is a basic template mechanism commonly used as a substitute for C++20 concepts to constrain templates. For an explanation of SFINAE and std::enable_if in particular, refer to your favorite textbook about C++ templates. If you don’t have any, a great choice is the C++ template bible: David Vandevoorde, Nicolai Josuttis, and Douglas Gregor’s C++ Templates: The Complete Guide (Addison-Wesley).
10 For a lot more information on physical and logical dependency management, see John Lakos’s “dam” book, Large-Scale C++ Software Development: Process and Architecture (Addison-Wesley).
11 Martin Fowler, “Who Needs an Architect?” IEEE Software, 20, no. 5 (2003), 11–13, https://doi.org/10.1109/MS.2003.1231144.
12 A very good introduction to microservices can be found in Sam Newman’s book Building Microservices: Designing Fine-Grained Systems, 2nd ed. (O’Reilly).
13 Mark Richards and Neal Ford, Fundamentals of Software Architecture: An Engineering Approach (O’Reilly, 2020).
14 The term implementation pattern was first used in Kent Beck’s book Implementation Patterns (Addison-Wesley). In this book, I’m using that term to provide a clear distinction from the term design pattern, since the term idiom may refer to a pattern on either the Software Design level or the Implementation Details level. I will use the term consistently to refer to commonly used solutions on the Implementation Details level.
15 Second-favorite after this one, of course. If this is your only book, then you might refer to the classic Effective C++: 55 Specific Ways to Improve Your Programs and Designs, 3rd ed., by Scott Meyers (Addison-Wesley).
16 The Template Method and Bridge design patterns are 2 of the 23 classic design patterns introduced in the so-called Gang of Four (GoF) book by Erich Gamma et al., Design Patterns: Elements of Reusable Object-Oriented Software. I won’t go into detail about the Template Method in this book, but you’ll find good explanations in various textbooks, including the GoF book itself. I will, however, explain the Bridge design pattern in “Guideline 28: Build Bridges to Remove Physical Dependencies”.
17 Bjarne Stroustrup, The C++ Programming Language, 3rd ed. (Addison-Wesley, 2000).
18 Kudos to John Lakos, who argues similarly and uses C++98 in his book, Large-Scale C++ Software Development: Process and Architecture (Addison-Wesley).
19 Yes, Ben and Jason, you have read correctly, I will not constexpr ALL the things. See Ben Deane and Jason Turner, “constexpr ALL the things”, CppCon 2017.
20 Michael Feathers, Working Effectively with Legacy Code (Addison-Wesley, 2013).
21 David Thomas and Andrew Hunt, The Pragmatic Programmer: Your Journey to Mastery, 20th Anniversary Edition (Addison-Wesley, 2019).
22 Tom DeMarco, Structured Analysis and System Specification (Prentice Hall, 1979).
23 SOLID is an acronym of acronyms, an abbreviation of the five principles described in the next few guidelines: SRP, OCP, LSP, ISP, and DIP.
24 The first book on the SOLID principles was Robert C. Martin’s Agile Software Development: Principles, Patterns, and Practices (Pearson). A newer and much cheaper alternative is Clean Architecture, also from Robert C. Martin (Addison-Wesley).
25 Don’t forget that the design decisions taken by that external library may impact your own design, which would obviously increase the coupling.
26 That includes the classes that other people may have written, i.e., classes that you do not control. And no, the other people won’t be happy about the change. Thus, the change may be really difficult.
27 An enumeration seems to be an obvious choice, but of course there are other options as well. In the end, we need an agreed-upon set of values that represent the different document formats in the byte representation.
28 You might be wondering about the explicit use of the explicit keyword for this constructor. Then you might also be aware that Core Guideline C.46 advises using explicit by default for single-argument constructors. This is really good and highly recommended advice, as it prevents unintentional, potentially undesirable conversions. While not as valuable, the same advice is also reasonable for all the other constructors, except for the copy and move constructors, which don’t perform a conversion. At least it doesn’t hurt.
29 You might realize I’ve picked the names of the three conferences I regularly attend: CppCon, Meeting C++, and C++ on Sea. There are many more C++ conferences, though. To give a few examples: ACCU, Core C++, pacific++, CppNorth, emBO++, and CPPP. Conferences are a great and fun way to stay up to date with C++. Make sure to check out the Standard C++ Foundation home page for any upcoming conferences.
30 Katerina Trajchevska, “Becoming a Better Developer by Using the SOLID Design Principles”, Laracon EU, August 30–31, 2018.
31 Robert C. Martin, Agile Software Development: Principles, Patterns, and Practices.
32 If you don’t have a test suite in place, then you have work to do. Seriously. A very coherent reference to get started is Ben Saks’s talk on unit tests, “Back to Basics: Unit Tests”, from CppCon 2020. A second, very good reference to wrap your mind around the whole topic of testing and test-driven development in particular is Jeff Langr’s book, Modern C{plus}{plus} Programming with Test-Driven Development (O’Reilly).
33 I know, “everyone agrees” is unfortunately far from reality. If you need proof that the seriousness of tests has not yet reached every project and every developer, take a look at this issue from the OpenFOAM issue tracker.
34 David Thomas and Andrew Hunt, The Pragmatic Programmer: Your Journey to Mastery.
35 We may even have entered the scary realm of undefined behavior.
36 You can find this compelling argument in item 23 of Scott Meyers’s Effective C++.
37 Bertrand Meyer, Object-Oriented Software Construction, 2nd ed. (Pearson, 2000).
38 The answer “It depends!” will of course satisfy even the strongest critics of the OCP.
39 The C++ Core Guidelines are a community effort to collect and agree on a set of guidelines for writing good C++ code. They best represent the common sense of what idiomatic C++ is. You can find these guidelines on GitHub.
40 The abbreviation ADL refers to Argument Dependent Lookup. See the CppReference or my CppCon 2020 talk for an introduction.
Get C++ Software Design now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

