3. Output from the Common Gateway Interface
3.1 Overview
As described in Chapter 3, Output from the Common Gateway Interface, CGI programs are requested like any other regular documents. The difference is that instead of returning a static document, the server executes a program and returns its output. As far as the browser is concerned, however, it expects to get the same kind of response that it gets when it requests any document, and it's up to the CGI program to produce output that the browser is comfortable with.
The most basic output for a CGI program is a simple document in either plain text or HTML, which the browser displays as it would any document on the Web. However, there are other things you can do, such as:
- Return graphics and other binary data
- Tell the browser whether to cache the virtual document
- Send special HTTP status codes to the browser
- Tell the server to send an existing document
Each of these techniques involves knowing a little bit about returning additional headers from the CGI program.
3.2 CGI and Response Headers
By now, you should be reasonably comfortable designing CGI programs that create simple virtual documents, like this one:
#!/usr/local/bin/perl print "Content-type: text/html", "\n\n"; print "<HTML>", "\n"; print "<HEAD><TITLE>Simple Virtual HTML Document</TITLE></HEAD>", "\n"; print "<BODY>", "\n"; print "<H1>", "Virtual HTML", "</H1>", "<HR>", "\n"; print "Hey look, I just created a virtual (yep, virtual) HTML document!", "\n"; print "</BODY></HTML>", "\n"; exit (0);
Up to this point, we have taken the line that outputs “Content-type” for granted. But this is only one type of header that CGI programs can use. “Content-type” is an HTTP header that contains a MIME content type describing the format of the data that follows. Other headers can describe:
- The size of the data
- Another document that the server should return (that is, instead of returning a virtual document created by the script itself)
- HTTP status codes
This chapter will discuss how HTTP headers can be used to fine-tune your CGI documents. First, however, Table 3.1 provides a quick listing of all the HTTP headers you might find useful.
| Header | Description |
| Content-length | The length (in bytes) of the output stream. Implies binary data. |
| Content-type | The MIME content type of the output stream. |
| Expires | Date and time when the document is no longer valid and should be reloaded by the browser. |
| Location | Server redirection (cannot be sent as part of a complete header). |
| Pragma | Turns document caching on and off. |
| Status | Status of the request (cannot be sent as part of a complete header). |
The following headers are “understood” only by Netscape-compatible browsers (i.e., Netscape Navigator and Microsoft Internet Explorer).
Table 3.2: Netscape-Compatible Headers
| Header | Description |
| Refresh | Client reloads specified document. |
| Set-Cookie | Client stores specified data. Useful for keeping track of data between requests. |
You can see a complete list of HTTP headers at http://www.w3.org/hypertext/WWW/Protocols/HTTP/Object_Headers.html
Also, there are a couple of things you should know about header syntax:
Header lines don't have to be in any special order.
In general, the headers you generate from a CGI program can be output in any order you like.
The header block has to end with a blank line.
HTTP is a very simple protocol. The way the server knows that you're done with your header information is that it looks for a blank line. Everything before the blank line is taken as header information; everything after the blank line is assumed to be data. In Perl, the blank line is generated by two newline characters (\n\n) that are output after the last line of the header. If you don't include the blank line after the header, the server will assume incorrectly that the entire information stream is an HTTP header, and will generate a server error.
3.3 Accept Types and Content Types
CGI applications can return nearly any type of virtual document, as long as the client can handle it properly. It can return a plain text file, an HTML file ... or it can send PostScript, PDF, SGML, etc.
This is why the client sends a list of “accept types” it supports, both directly and indirectly through helper applications, to the server when it issues a request. The server stores this information in the environment variable HTTP_ACCEPT, and the CGI program can check this variable to ensure that it returns a file in a format the browser can handle.
It's also why when you are returning a document, the CGI program needs to use the Content-type header to notify the client what type of data it is sending, so that the browser can format and display the document properly.
Here's a simple snippet of code that checks to see if the browser accepts JPEG or GIF images:
#!/usr/local/bin/perl
$gif_image = "logo.gif";
$jpeg_image = "logo.jpg";
$plain_text = "logo.txt";
$accept_types = $ENV{'HTTP_ACCEPT'};
if ($accept_types =~ m|image/gif|) {
$html_document = $gif_image;
} elsif ($accept_types =~ m|image/jpeg|) {
$html_document = $jpeg_image;
} else {
$html_document = $plain_text;
}
.
.
.
We use a regular expression to search the $accept_types variable for a MIME content type of image/gif and image/jpeg. Once that's done, you can open the file, read it, and output the data to standard output, like we've seen in previous examples.
3.4 The Content-length Header
As you've seen in previous examples, we are not limited to dealing just with HTML text (defined by the MIME type text/html) but we can also output documents formatted in numerous ways, like plain text, GIF or JPEG images, and even AIFF sound clips. Here is a program that returns a GIF image:
#!/usr/local/bin/perl
$gif_image = join ("/", $ENV{'DOCUMENT_ROOT'}, "icons/tiger.gif");
if (open (IMAGE, "<” . $gif_image)) {
$no_bytes = (stat ($gif_image))[7];
print "Content-type: image/gif", "\n";
print "Content-length: $no_bytes", "\n\n";
The first thing to notice is that the content type is image/gif. This signals the browser that a GIF image will be sent, so the browser knows how to display it.
The next thing to notice is the Content-length header. The Content-length header notifies the server of the size of the data that you intend to send. This prevents unexpected end-of-data errors from the server when dealing with binary data, because the server will read the specified number of bytes from the data stream regardless of any spurious end-of-data characters.
To get the content length, we use the stat command, which returns a 13-element array containing the statistics for a given file, to determine the size of the file. The eighth element of this array (index number 7, because arrays are zero-based in Perl) represents the size of the file in bytes. The remainder of the script follows:
print <IMAGE>;
} else {
print "Content-type: text/plain", "\n\n";
print "Sorry! I cannot open the file $gif_image!", "\n";
}
exit (0);
As is the case with binary files, one read on the file handle will retrieve the entire file. Compare that to text files where one read will return only a single line. As a result, this example is fine when dealing with small graphic files, but is not very efficient with larger files. Now, we'll look at an example that reads and displays the graphic file in small pieces:
#!/usr/local/bin/perl
$gif_image = join ("/", $ENV{'DOCUMENT_ROOT'}, "icons/tiger.gif");
if (open (IMAGE, "<” . $gif_image)) {
$no_bytes = (stat ($gif_image))[7];
$piece_size = $no_bytes / 10;
print "Content-type: image/gif", "\n";
print "Content-length: $no_bytes", "\n\n";
for ($loop=0; $loop <= $no_bytes; $loop += $piece_size) {
read (IMAGE, $data, $piece_size);
print $data;
}
close (IMAGE);
} else {
print "Content-type: text/plain", "\n\n";
print "Sorry! I cannot open the file $gif_image!", "\n";
}
exit (0);
The loop iterates through the file reading and displaying pieces of data that are one-tenth the size of the entire binary file.
As you will see in the following section, you can use server redirection to return existing files much more quickly and easily than with CGI programs like the ones described earlier.
3.5 Server Redirection
Thus far we've seen CGI examples that return virtual documents created on the fly. However, another thing CGI programs can do is to instruct the server to retrieve an existing document and return that document instead. This is known as server redirection.
To perform server redirection, you need to send a Location header to tell the server what document to send. The server will retrieve the specified document from the Web, giving the appearance that the client had not requested your CGI program, but that document (see Figure 3.1).
Figure 3.1: Server redirection
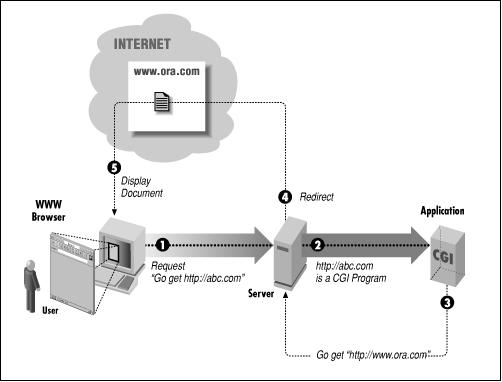
A common use for this feature is to return a generic document that contains static information. For example, say you have a form for users to fill out, and you want to display a thank-you message after someone completes the form. You can have the CGI program create and display the message each time it is called. But a more efficient way would be for the program to send instructions to the server to redirect and retrieve a file that contains a generic thank-you message.
Suppose you have an HTML file (thanks.html) like the one below, that you want to display after the user fills out one of your forms:
<HTML> <HEAD><TITLE>Thank You!</TITLE></HEAD> <BODY> <H1>Thank You!</H1> <HR> Thank You for filling out this form. We will be using your input to improve our products. Thanks again, WWW Software, Inc. </BODY> </HTML>
You could use the programs discussed earlier to return static documents, but it would be counterproductive to do it in that manner. Instead, it is much quicker and simpler to do the following:
#!/usr/local/bin/perl print "Location: /thanks.html", "\n\n"; exit (0);
The server will return the HTML file thanks.html located in the document root directory. You don't have to worry about returning the MIME content type for the document; it is taken care of by the server. An important thing to note is that you cannot return any content type headers when you are using server redirection.
You can use server redirection to your advantage and design CGI applications like the following:
#!/usr/local/bin/perl
$uptime = `/usr/ucb/uptime`;
($load_average) = ($uptime =~ /average: ([^,]*)/);
$load_limit = 10.0;
$simple_document = "/simple.html";
$complex_document = "/complex.html";
if ($load_average >= $load_limit) {
print "Location: $simple_document", "\n\n";
} else {
print "Location: $complex_document", "\n\n";
}
exit (0);
This program checks the load average of the host system with the uptime command (see Chapter 1, The Common Gateway Interface (CGI) for an explanation of the regular expression). Depending on the load average, one of two documents is returned; a rich, complicated HTML document with graphics if the system is not “busy,” or a simple text-only document otherwise.
And the last thing to note is that you are not limited to returning documents on your own server. You can also return a document (static or virtual) located elsewhere on the Internet, so long as it has a valid URL:
print "Location: http://www.ora.com", "\n\n";
For example, this statement will return the home page for O'Reilly and Associates.
3.6 The “Expires” and “Pragma” Headers
Most browsers cache (or store internally) the documents you access. This is a very positive feature that saves a lot of resources; the browser doesn't have to retrieve the document every time you look at it. However, it can be a slight problem when you are dealing with virtual documents created by CGI programs. Once the browser accesses a virtual document produced by a CGI program, it will cache it. The next time you try to access the same document, the browser will not make a request to the server, but will reload the document from its cache. To see the effects of caching, try running the following program:
#!/usr/local/bin/perl
chop ($current_date = `/bin/date`);
$script_name = $ENV{'SCRIPT_NAME'};
print "Content-type: text/html", "\n\n";
print "<HTML>", "\n";
print "<HEAD><TITLE>Effects of Browser Caching</TITLE></HEAD>", "\n";
print "<BODY><H1>", $current_date, "</H1>", "\n";
print "<P>", qq|<A HREF="$script_name">Click here to run again!</A>|, "\n";
print "</BODY></HTML>", "\n";
exit (0);
This program displays the current time, as well as a hypertext link to itself. If you click on the link to run the program again, the date and time that is displayed should change, but it does not, because the browser is retrieving the cached document. You need to explicitly tell the browser to reload the document if you want to run the CGI program again.
Fortunately, there is a solution to this problem. If you don't want a virtual document to be cached, you can use the Expires and/or Pragma headers to instruct the client not to cache the document.
#!/usr/local/bin/perl print "Content-type: text/html", "\n"; print "Pragma: no-cache", "\n\n"; . . .
or
#!/usr/local/bin/perl print "Content-type: text/html", "\n"; print "Expires: Wednesday, 27-Dec-95 05:29:10 GMT", "\n\n"; . . .
However, some browsers don't handle these headers correctly, so don't rely on them.
3.7 Status Codes
Status codes are used by the HTTP protocol to communicate the status of a request. For example, if a document does not exist, the server returns a “404” status code to the browser. If a document has been moved, a “301” status code is returned.
CGI programs can send status information as part of a virtual document. Here's an arbitrary example that returns success if the remote host name is bu.edu, and failure otherwise:
#!/usr/local/bin/perl
$remote_host = $ENV{'REMOTE_HOST'};
print "Content-type: text/plain", "\n";
if ($remote_host eq "bu.edu") {
print "Status: 200 OK", "\n\n";
print "Great! You are from Boston University!", "\n";
} else {
print "Status: 400 Bad Request", "\n\n";
print "Sorry! You need to access this from Boston University!", "\n";
}
exit (0);
The Status header consists of a three-digit numerical status code, followed by a string representing the code. A status value of 200 indicates success, while a value of 400 constitutes a bad request. In addition to these two, there are numerous other status codes you can use for a variety of situations, ranging from an unauthorized or forbidden request to internal system errors. Table 3.3 shows a list of some of commonly used status codes.
| Status Code | Message |
| 200 | Success |
| 204 | No Response |
| 301 | Document Moved |
| 401 | Unauthorized |
| 403 | Forbidden |
| 404 | Not Found |
| 500 | Internal Server Error |
| 501 | Not Implemented |
For a complete listing of status codes, see: http://www.w3.org/hypertext/WWW/Protocols/HTTP/HTRESP.html
Unfortunately, most browsers do not support all of them.
The “No Response” Code
One status code that deserves special attention is status code 204, which produces a “no response.” In other words, the browser will not load a new page if your CGI program returns a status code of 204:
#!/usr/local/bin/perl print "Content-type: text/plain", "\n"; print "Status: 204 No Response", "\n\n"; print "You should not see this message. If you do, your browser does", "\n"; print "not implement status codes correctly.", "\n"; exit (0);
The “no response” status code can be used when dealing with forms or imagemaps. For example, if the user enters an invalid value in one of the fields in a form or clicks in an unassigned section of an imagemap, you can return this status code to instruct the client to not load a new page.
3.8 Complete (Non-Parsed) Headers
Thus far, we've only seen examples with partial HTTP headers. That is, when all you include is a Content-type header, the server intercepts the output and completes the header information with header information of its own. The header information generated by the server might include a “200 OK” status code (if you haven't overridden it with a Status header), the date and time, the version of the server, and any other information that it thinks a browser might find useful.
But as we mentioned in Chapter 1 CGI programs can override the header information generated by the server by generating a complete HTTP header on its own.
Why go to all the trouble of generating your own header? When your program returns a complete HTTP header, there is no extra overhead incurred by the server. Instead, the output of the CGI program goes directly to the client, as shown in Figure 3.2. This may mean faster response time for the user. However, it also means you need to be especially careful when generating your own headers, since the server won't be able to circumvent any errors.
Figure 3.2: Partial and complete headers
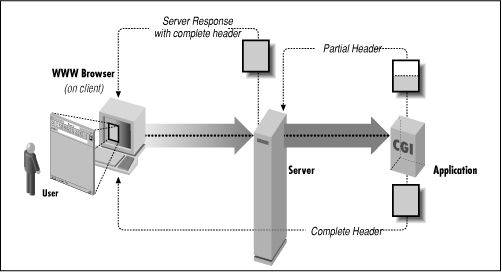
How does the server know if the CGI program has output a partial or a complete HTTP header without “looking” at it? It depends on which server you use. On the NCSA and CERN servers, programs that output complete headers must start with the “nph-” prefix (e.g., nph-test.pl), which stands for Non-Parsed Header.
The following example illustrates the usefulness of creating an NPH script:
#!/usr/local/bin/perl
$server_protocol = $ENV{'SERVER_PROTOCOL'};
$server_software = $ENV{'SERVER_SOFTWARE'};
print "$server_protocol 200 OK", "\n";
print "Server: $server_software", "\n";
print "Content-type: text/plain", "\n\n";
print "OK, Here I go. I am going to count from 1 to 50!", "\n";
$| = 1;
for ($loop=1; $loop <= 50; $loop++) {
print $loop, "\n";
sleep (2);
}
print "All Done!", "\n";
exit (0);
When you output a complete header, you should at least return header lines consisting of the HTTP protocol revision and the status of the program, the server name/version (e.g., NCSA/1.4.2), and the MIME content type of the data.
You can run this program by opening the URL to:
http://your.machine/cgi-bin/nph-count.pl
When you run this CGI script, you should see the output in “real time”: the client will display the number, wait two seconds, display the next number, etc.
Now remove the complete header information (except for Content-type), change the name to count.pl (instead of nph-count.pl), and run it again. What's the difference? You will no longer see the output in “real time”; the client will display the entire document at once.
Get CGI Programming on the World Wide Web now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

