So far, we have been looking at the concepts of implementing routing policies. In this section, we’ll start implementing real routing policies using access lists, focusing on routing policies that implement routing modularity.
Let’s revisit the scenario we saw in the first chapter, where a typographical error caused a route to be incorrectly advertised, making two sites unreachable on an organization’s intranet. Figure 4.9 shows a network topology for that scenario.
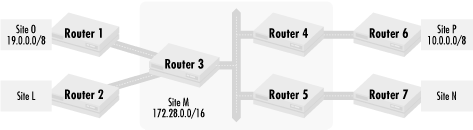
In Figure 4.9, we see a network where four sites, L, N, O, and P, connect to each other through a central hub Site M. Network 19.0.0.0/8 belongs to Site O, and network site 10.0.0.0/8 belongs to Site P. Network 172.28.0.0/16 belongs to Site M. In our failure scenario, a typographical error causes Site O to advertise a route to network 10.0.0.0/8 from Router 1 instead of network 19.0.0.0/8. (This is an easy typo to make since the number 9 is close to the number on the computer keyboard.) The typo causes Sites L, M, and N to see two routes to network 10.0.0.0/8 and no routes to network 19.0.0.0/8. Just to make things interesting, let’s also say that the serial link between Routers 1 and 3 has much greater bandwidth than the serial link between Routers 4 and 6. That makes the route from Router 3 to Site O the preferred route to network 10.0.0.0/8 for Sites L, M, and O because of the more favorable network.
This scenario is a problem because network 19.0.0.0/8 is no longer advertised in the intranet, and no one in Sites L, M, N, or P can reach Site O. Conversely, no one in Site O can use the services of any other network since the return packets for a connection (or for server responses) have no route back to Site O. In addition, since the preferred route to Site P’s network 10.0.0.0/8 goes to Site O, no packets ever reach Site P either.
How can we minimize the impact of this kind of typographical error? We know which routes should be sent from each site and which should be received. If we enforce a policy that says that only the well known and previously agreed upon routes should be sent and received from each site, then a route mistakenly advertised from a site will not get propagated. Let’s spell out the policy so we can translate it into access lists:
Only network 19.0.0.0/8 should be accepted from Site O
To implement this policy with access lists, we build a policy set with network 19.0.0.0/8 in it, and then accept only the routes in that policy set from Site D. Here is the access list:
access-list 1 permit 19.0.0.0
For this example, let’s say that Router 3 is connected to Site O via serial interface 1, and the routing protocol used is EIGRP. We then apply access list 1 on Router 3 with the following:
router eigrp 1000 distribute-list 1 in Serial 1
This first line says that we will modify the EIGRP routing protocol for Autonomous System 1000. The second line says that only the routes defined in access list 1 will be permitted in from serial 1.
How does this access list deal with our typographical error scenario? When Site O broadcasts a route to network 10.0.0.0/8 instead of a route to network 19.0.0.0/8, the route will be rejected by Router 3 and not propagated to the rest of the network. While the route to network 19.0.0.0/8 has disappeared, the route going to Site P’s network 10.0.0.0/8 is unaffected. In this way, routing problems in Site O affect only Site O. We have gained routing modularity because bad route advertisements by Site O will not propagate across the intranet.
Since Site M cannot control what routes Site O broadcasts to it, Site M needs to limit the routes it hears from Site O. Although we have just implemented a policy that permits only routes in from Site O that belong to O, we cannot depend on that policy because Site M may be administered by a different organization than Site O, or because of any of the other reasons discussed before. To make sure that bad routes do not propagate, Site O should filter outgoing route updates to ensure that inappropriate routes, whether caused by typographical errors or other reasons, do not propagate. On Router 1, we build a policy set of Site O’s routes:
access-list 2 permit 19.0.0.0
If we say that Router 1’s connection to Site M is through serial interface 0, we apply the access list on Router 1 as follows:
router eigrp 1000 distribute-list 2 out Serial0
The distribute-list
out command allows only the routes defined in
access list 2 to be sent out of the serial interface going to Site M.
Site P and Site M have a relationship similar to the relationship between Site O and Site M. We can make routing robust between the sites in the same way. Let’s say that Routers 4 and 6 both use serial interface 2 to talk to each other. Since Site E uses network 10.0.0.0/8, we would set up the following on Router 4:
access-list 4 permit 10.0.0.0 ! routing process section router eigrp 1000 distribute-list 4 in Serial 2
This configuration fragment permits only the route to 10.0.0.0 in through serial interface 2 of Router 4, thus permitting only network 10.0.0.0/8 to come in from Site O. Router 6 should have the following:
access-list 5 permit 10.0.0.0 ! routing process section router eigrp 1000 distribute-list 5 out Serial 2
This fragment of router configuration prevents Site P from advertising any route other than network 10.0.0.0/8. Put together, these two applications of access lists make it much more unlikely that a bad route will escape from Site P.
Intranets typically have what are called stub networks. These are networks or administrative domains that send all traffic not destined for a host on that network out through a single router or small set of routers. There is no transit traffic through these networks; any traffic that is on the network is either to or from the network. External traffic typically goes to some central network that has connectivity to all other networks on that intranet.
The host segments shown in Figure 4.10 are stub networks, and the router connecting them to the backbone segment is a stub router. The stub router has several Ethernet segments with hosts connected to it and one connection to a fast Ethernet backbone segment. The function of the router is to connect the hosts to the backbone segment. The host segments do not need to hear routing updates because no other routers are on the segments. Hosts can easily be configured to default all traffic not bound for their segment to the router. At the same time, no routing updates should be accepted from the host segments. Any routing updates heard on the segment must be from misconfigured hosts or another router that has been mistakenly connected to one of the host segments.
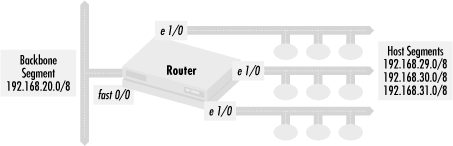
To reduce unnecessary traffic on the segments and to prevent any spurious routing updates from injecting bad routing information, we need to enforce the policy:
Do not send routing updates to the host segments
Do not accept routing updates from the host segments
Advertise on the backbone segment only the routes for the networks connected to the router
To implement the policy, we need an access list with no routes in it:
access-list 1 deny all
This access list permits nothing into a policy set and can be used to deny all routes. We will use this kind of access list for the first and second policy statements. To implement the third policy statement, we will build an access list of the networks connected to the router:
access-list 2 permit 192.168.29.0 access-list 2 permit 192.168.30.0 0.0.1.0
The access lists are then used to define the routes sent out of specific interfaces. Let’s say we are using the routing protocol EIGRP in this network:
router eigrp 10 network 192.168.20.0 network 192.168.29.0 network 192.168.30.0 network 192.168.31.0 ! no routes to the host segments distribute-list 1 out Ethernet 1/0 distribute-list 1 out Ethernet 1/1 distribute-list 1 out Ethernet 1/2 ! no routes from the host segments distribute-list 1 in Ethernet 1/0 distribute-list 1 in Ethernet 1/1 distribute-list 1 in Ethernet 1/2 ! advertise only connected routes distribute-list 2 out fast 0/0
The policy implementation takes place
in the distribute-list
commands. The first three
distribute-list
out statements
stop any routes from being advertised to the host segments. The next
three statements stop the router from believing any route updates
form the host segments. The last distribute list prevents the router
from distributing anything but the three networks directly connected
to it.
Another key border where routing policies often need to be enforced is the interface where routing information is redistributed from one routing protocol or routing protocol administrative system to another. Each routing protocol has its own unique properties that network administrators want to either take advantage of or avoid. Let’s look at an example where we send routing information in a certain routing protocol but refuse to listen to it.
In Figure 4.11, three routers are connected via their Ethernet 1 interface to an Ethernet segment containing a number of hosts. The routers also have a serial line (serial interface 0) connecting them to other networks. The routers broadcast RIP updates to the hosts, so they know which router to use for the best path to whatever networks the routers know about. Note that although most host systems come configured to understand only RIP, RIP has many limitations as a routing protocol, so the routers actually talk to each other using IGRP. So in this case, we want to make sure that we send out RIP routing updates (from the routers to the hosts) but have the routers ignore all RIP information received.
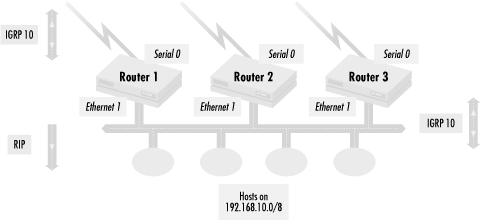
To implement this, we use the deny all access list defined in the previous example:
access-list 1 deny all
We use this access list to get an empty policy set, which is the set of all the routes we accept in via RIP. Next, let’s define the RIP routing process:
router rip network 192.168.10.0 redistribute igrp 10 distribute-list 1 in
The network statement here says that we
broadcast RIP on all interfaces connected to network 192.168.10.0/8.
The next statement says that we will redistribute all routes learned
from IGRP process 10 into RIP. The final
distribute-list statement restricts what routes
are accepted in by RIP. Since no interface is specified, all RIP
routing updates accepted by the router must be in the policy set
defined by access list 1. Since access list 1 denies all routes, all
routes advertised via RIP are ignored, regardless of what interface
they come in on.
In Figure 4.9, all the sites except for Site M are stub networks. Since Site M uses network 172.28.0.0/16, any traffic going between sites needs to go through that network first, making the network an ideal default network. A default network is a destination where a router sends all packets that have no explicitly defined routes in its routing table. For example, if a router has only network 10.0.0.0/8 and default network 172.28.0.0/16 in its routing table, and it was asked to forward a packet to network 198.168.30.0/8, the router forwards the packet to the same path as to 172.28.0.0/16, the default network. Note that a default network is different from a default route. A default route is where a router sends a packet if it does not have explicit routing information for the packet’s destination. It is a route as opposed to a network, although the route to the default network becomes the default route.
Default networks are very useful in reducing the load and complexity of routing and route filtering. They reduce the router resource impact by reducing the number of routes that routers need to know about. In some cases, such as the interface between the Internet and an intranet, using a default network can spare routers from having to process tens of thousands of routes.
Let’s look in detail at Figure 4.9, the interface between Site O and Site M. This is shown in Figure 4.12.
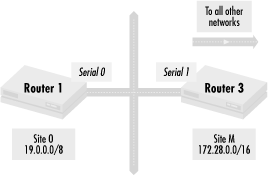
Router 1 only accepts traffic for network 19.0.0.0/8 since Site O is a stub network and does not transit traffic through it. We can reduce the number of networks that Site O has to see and propagate within itself by using the following configuration in Router 1:
default-network 172.28.0.0 access-list 1 permit 172.28.0.0 router rip distribute-list 1 in Serial 0
The first statement declares that network 172.28.0.0/16 is the default network. Access list 1 defines a policy set consisting only of the default network. The next two statements define the properties of the RIP routing process, saying that only the default network 172.28.0.0 is allowed into Router 1 (and thus Site O) because only the routes in the policy set defined by access list 1 are accepted in through serial interface 0.
How does this reduce the processing of routing updates in Site O’s network? Since we accept only one route, to network 172.28.0.0/16 as the default network to other networks, Router 1 doesn’t have to accept route 10.0.0.0/8 from Site O or any other route from other sites within the intranet. Because only one route is accepted, Site O has fewer routes to broadcast within its internal routing updates, which reduces the size of routing updates sent and the amount of network bandwidth used by those routing updates within Site O. Recall that Site O can have its own internal network structure with routing updates; as a stub network it doesn’t transit traffic from other sites. Fewer routes also means that routers within Site O have fewer routes to examine when using routing access lists and building routing tables, thus reducing the CPU load.
Using default networks can also reduce the bandwidth used for routing updates on the serial line between Site M and Site O. If the administrator of Site M knows that all other sites use 172.28.0.0/16 as a default network, Routers 3, 4, and 5 can send only the default network to other sites during routing updates (see Figure 4.9). For example, Router 3 would use a configuration like this:
access-list 2 permit 172.28.0.0 router rip distribute-list 2 out Serial 1
to limit the routing updates sent to Site O. In this way, more bandwidth is reserved for user data.
Default networks do have some tradeoffs that must be acknowledged. Traffic to networks not defined anywhere within an intranet will travel to a default network before getting dropped by a router on the default network. That means the bad traffic ends up taking more resources because more time goes by before they are rejected. In considering this tradeoff, you have to consider how much traffic will be sent to unreachable networks and how much of that you want to tolerate.
So far, I have only shown how to filter routes sent out of interfaces, but Cisco routers have another option for filtering routes that allow network administrators to reduce the impact of route filtering. In the previous example, we filtered routes going out of Router 3 and all of the routes learned by the RIP routing protocol were compared to an access list every time a routing update was sent from Router 3’s serial interface, creating a potentially dangerous CPU load.
Even if we used the IGRP routing protocol with AS 5 instead of RIP, where the configuration on Router 3 would look something like this:
access-list 2 permit 172.28.0.0 ! igrp definition router igrp 5 network 172.28.0.0 ! rip definitions router rip redistribute igrp 5 distribute-list 2 out Serial 1
the CPU load problem would remain because the chief difference in the
RIP routing definition is the redistribute
igrp
5 line, which serves only
to send all of the routes in IGRP 5 into RIP.
An option of the
distribute-list statement that lets us reduce the
impact of filtering routes when they are distributed from one routing
process to another. If we specify a routing process instead of an
interface, routes are received only when they are updated by that
routing process. We can rewrite the example as follows:
access-list 2 permit 172.28.0.0 router igrp 5 network 172.28.0.0 ! rip definition router rip distribute-list 2 out igrp 5 redistribute igrp 5
Routes are filtered and sent to the RIP process every time the IGRP routing protocol sends updates. This happens every 90 seconds (the IGRP default). Since the RIP process receives the default route only when IGRP is updated, it does not need to filter routes when it sends routing updates, and the router needs to filter the route only every 90 seconds, as opposed to every 30 seconds with RIP. If there were many interfaces the router needed to send RIP updates out from, the CPU savings would be substantial. Generally, when filtering routes directly from one route process into another, it is best to send routes from the least frequently updated process into the more frequently updated routing process. This saves the most CPU by conserving processing time.
Get Cisco IOS Access Lists now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

