PREVENTION
The vast majority of errors in estimation stem from a failure to measure what was wanted or what was intended. Misleading definitions, inaccurate measurements, errors in recording and transcription, and confounding variables plague results.
To prevent such errors, review your data collection protocols and procedure manuals before you begin, run several preliminary trials, record potential confounding variables, monitor data collection, and review the data as they are collected.
Before beginning to analyze data you have collected, establish the provenance of the data: Is it derived from a random sample? From a representative one?
Display the Data
Your first step should be to construct a summary of the data in both tabular and graphic form. Both should display the minimum, 25th percentile, median, mean, 75th percentile, and maximum of the data. This summary will usually suggest the estimators you will need.
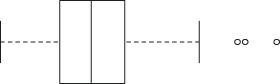
Use a box plot rather than a stem-and-leaf diagram. The latter is an artifact of a time when people would analyze data by hand. Though stem-and leaf diagrams are relatively easy to manually construct for a small or moderate size dataset, a computer can generate a box plot like that shown in Figure 5.1 in a fraction of the time.
FIGURE 5.1. Boxplot of Heights of Sixth-Graders.
Aggregate Statistics
Do not be misled by aggregate statistics. David C. Howell reported the ...
Get Common Errors in Statistics (and How to Avoid Them), 4th Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

