May 2018
Beginner
73 pages
1h 30m
English
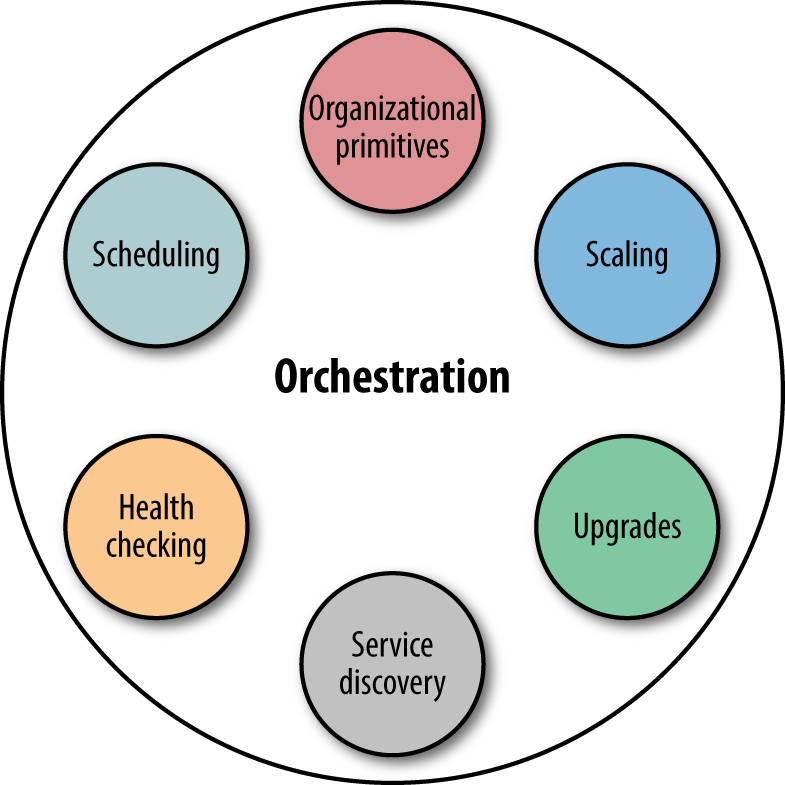
With the cattle approach to managing infrastructure, you don’t manually allocate certain machines for running an application. Instead, you leave it up to an orchestrator to manage the life cycle of your containers. In Figure 4-1, you can see that container orchestration includes a range of functions, including but not limited to:
Organizational primitives, such as labels in Kubernetes, to query and group containers
Scheduling of containers to run on a host
Automated health checks to determine if a container is alive and ready to serve traffic and to relaunch it if necessary
Autoscaling (that is, increasing or decreasing the number of containers based on utilization or higher-level metrics)
Upgrade strategies, from rolling updates to more sophisticated techniques such as A/B and canary deployments
Service discovery to determine which host a scheduled container ended upon, usually including DNS support
Sometimes considered part of orchestration but outside the scope of this book is the topic of base provisioning—that is, installing or upgrading the local operating system on a node or setting up the container runtime there.
Service discovery (covered in greater detail in Chapter 5) and scheduling are really two sides of the same coin. The scheduler decides where in a cluster a container is placed ...
Read now
Unlock full access






