Chapter 4. Structuring Deployments as Pipelines
In this chapter you’ll learn about the benefits of structuring your deployments out of customizable pieces, the parts of a Spinnaker pipeline, and how codifying and iterating on your pipeline can help reduce the cognitive load of developers. At the end of this chapter, you should be able to look at a deployment process and break down different integration points into specific pipeline parts.
Benefits of Flexible User-Defined Pipelines
Most deployments consist of similar steps. In many cases, the code must be built and packaged, deployed to a test environment, tested, and then deployed to production. Each team, however, may choose to do this a little differently. Some teams conduct functional testing by hand whereas others might start with automated tests. Some environments are highly controlled and need to be gated with an approval by a person (manual judgment), whereas others can be updated automatically whenever there is a new change.
At Netflix, we’ve found that allowing each team to build and maintain their own deployment pipeline from the building blocks we provide lets engineers experiment freely according to their needs. Each team doesn’t have to develop and maintain their own way to do common actions (e.g., triggering a CI build, figuring out which image is deployed in a test environment, or deploying a new server group) because we provide well-tested building blocks to do this. Additionally, these building blocks work for every infrastructure account and cloud provider we have. Teams can focus on iterating on their deployment strategy and building their product instead of struggling with the cloud.
Spinnaker Deployment Workflows: Pipelines
In Spinnaker, pipelines are the key workflow construct used for deployments. Each pipeline has a configuration, defining things like triggers, notifications, and a sequence of stages. When a new execution of a pipeline is started, each stage is run and actions are taken.
Pipeline executions are represented as JSON that contains all the information about the pipeline execution. Variables like time started, parameters, stage status, and server group names all appear in this JSON, which is used to render the UI.
Pipeline Stages
The work done by a pipeline can be divided into smaller, customizable blocks called stages. Stages are chained together to define the overall work done as part of the continuous delivery process. Each type of stage performs a specific operation or series of operations. Pipeline stages can fall into four broad categories.
Infrastructure Stages
Infrastructure stages operate on the underlying cloud infrastructure by creating, updating, or deleting resources.
These stages are implemented for every cloud provider where applicable. This means that if your organization leverages multiple clouds, you can deploy to each of them in a consistent way, reducing cognitive load for your engineers.
Examples of stages of this category include:
-
Bake (create an AMI or Docker image)
-
Tag Image
-
Find Image/Container from a Cluster/Tag
-
Deploy
-
Disable/Enable/Resize/Shrink/Clone/Rollback a Cluster/Server Group
-
Run Job (run a container in Kubernetes)
Bake stages take an artifact and turn it into an immutable infrastructure primitive like an Amazon Machine Image (AMI) or a Docker image. This action is called “baking.” You do not need a bake step to create the images you will use—it is perfectly fine to ingest them into Spinnaker in another way.
Tag Image stages apply a tag to the previously baked images for categorization. Find Image stages locate a previously deployed version of your immutable infrastructure so that you can refer to that same version in later stages.
The rest of the infrastructure stages operate on your clusters/server groups in some way. These stages do the bulk of the work in your deployment pipelines.
External Systems Integrations
Spinnaker provides integrations with custom systems to allow you to chain together logic performed on systems other than Spinnaker.
Examples of this type of stage are:
-
Continuous Integration: Jenkins/TravisCI
-
Run Job
-
Webhook
Spinnaker can interact with Continuous Integration (CI) systems such as Jenkins. Jenkins is used for running custom scripts and tests. The Jenkins stage allows existing functionality that is already built into Jenkins to be reused when migrating from Jenkins to Spinnaker.
The custom Webhook stage allows you to send an HTTP request into any other system that supports webhooks, and read the data that gets returned.
Testing
Netflix has several testing stages that teams can utilize. The stages are:
-
Chaos Automation Platform (ChAP) (internal only)
-
Citrus Squeeze Testing (internal only)
Canary (open source)
The ChAP stage allows us to check that fallbacks behave as expected and to uncover systemic weaknesses that occur when latency increases.
The Citrus stage performs squeeze testing, directing increasingly more traffic toward an evaluation cluster in order to find its load limit.
The Canary stage allows you to send a small amount of production traffic to a new build and measure key metrics to determine if the new build introduces any performance degradation. This stage is also available in OSS. These stages have been contributed by other Netflix engineers to integrate with their existing tools.
Additionally, functional tests can also be run via Jenkins.
Controlling Flow
This group of stages allows you to control the flow of your pipeline, whether that is authorization, timing, or branching logic. The stages are:
-
Check Preconditions
-
Manual Judgment
-
Wait
-
Run a Pipeline
The Check Preconditions stage allows you to perform conditional logic. The Manual Judgment stage pauses your pipeline until a human gives it an OK and propagates their credentials. The Wait stage allows you to wait for a custom amount of time. The Pipeline stage allows you to run another pipeline from within your current pipeline. With these options, you can customize your pipelines extensively.
Triggers
The final core piece of building a pipeline is how the pipeline is started. This is controlled via triggers. Configuring a pipeline trigger allows you to react to events and chain steps together. We find that most Spinnaker pipelines are set up to be triggered off of events. There are several trigger types we have found important.
Time-based triggers:
Manual
Cron
Event-based triggers:
Git
Continuous Integration
Docker
Pipeline
Pub/Sub
Manual triggers are an option for every pipeline and allow the pipeline to be run ad hoc. Cron triggers allow you to run pipelines on a schedule.
Most of the time you want to run a pipeline after an event happens. Git triggers allow you to run a pipeline after a git event, like a commit. Continuous Integration triggers (Jenkins, for example) allow you to run a pipeline after a CI job completes successfully. Docker triggers allow you to run a pipeline after a new Docker image is uploaded or a new Docker image tag is published. Pipeline triggers allow you to run another pipeline after a pipeline completes successfully. Pub/Sub triggers allow you to run a pipeline after a specific message is received from a Pub/Sub system (for example Google Pub/Sub, or Amazon SNS).
With this combination of triggers, it’s possible to create a highly customized workflow bouncing between custom scripted logic (run in a container, or through Jenkins) and the built-in Spinnaker stages.
Notifications
Workflows that are automatically run need notifications to broadcast the status of events. Spinnaker pipelines allow you to configure notifications for pipeline start, success, and failure. Those same notification options are also available for each stage. Notifications can be sent via email, Slack, Hipchat, SMS, and Pub/Sub systems.
Expressions
Sometimes the base options aren’t enough. Expressions allow you to customize your pipelines, pulling data out of the raw pipeline JSON. This is commonly used for making decisions based on parameters passed into the pipeline or data that comes from a trigger.
For example, you may want to deploy to a test environment from your Jenkins triggered pipeline when your artifact name contains “unstable,” and to prod otherwise. You can use expressions to pull the artifact name that your Jenkins job produced and use the Check Preconditions stage to choose the branch of your pipeline based on the artifact name. Extensive expression documentation is available on the Spinnaker website.1
Exposing this flexibility to users allows them to leverage pipelines to do exactly what they want without needing to build custom stages or extend existing ones for unusual use cases, and gives engineers the power to iterate on their workflows.
Version Control and Auditing
All pipelines are stored in version control, backed by persistent storage. We have found it’s important to have your deployments backed by version control because it allows you to easily fix things by reverting. It also gives you the confidence to make changes because you know you’ll be able to revert if you cause a regression in your pipeline.
We have also found that auditing of events is important. We maintain a history of each pipeline execution and each task that is run. Spinnaker events, such as a new pipeline execution starting, can be sent to a customizable endpoint for aggregation and long-term storage. Our teams that deal with sensitive information use this feature to be compliant.
Example Pipeline
To tie all these concepts together we will walk through an example pipeline, pictured in Figure 4-1.
This pipeline interacts with two accounts, called TEST and PROD. It consists of a manual start, several infrastructure stages, and some stages that control the flow of the pipeline. This pipeline represents the typical story of taking an image that has already been deployed to TEST (and tested in that account), using a canary to test a small amount of production traffic, then deploying that image into PROD. This pipeline takes advantage of branching logic to do two things simultaneously.
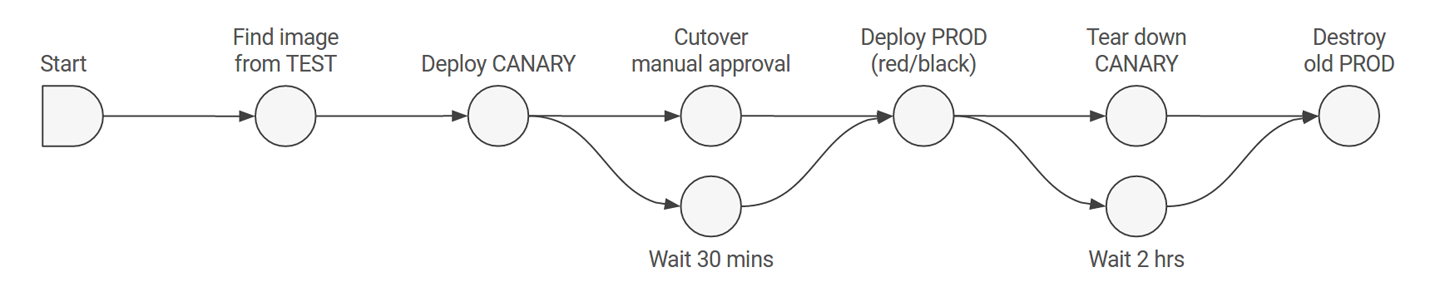
Figure 4-1. A sample Spinnaker deployment pipeline.
This pipeline finds an image that is running in the TEST account and then deploys a canary of that image to the PROD account. The pipeline then waits for the canary to gather metrics, and also waits for manual approval. Once both of these actions complete (including a user approving that the pipeline should continue) a production deployment proceeds using the “red/black” strategy discussed in Chapter 3 (old instances are disabled as soon as new instances come up). The pipeline stops the canary after the new production server group is deployed, and waits two hours before destroying the old production infrastructure.
This is one example of constructing a pipeline from multiple stages. Structuring your deployment from stages that handle the infrastructure details for you lowers the cognitive load of the users managing the deployments and allows them to focus on other things.
Jenkins Pipelines Versus Spinnaker Pipelines
We often receive questions about the difference between Jenkins pipelines and Spinnaker pipelines. The primary difference is what happens in each stage. Spinnaker stages, as you’ve just seen, have specifically defined functionality and encapsulate most cloud operations. They are opinionated and abstract away cloud specifics (like credentials and health check details). Jenkins stages have no native support for these cloud abstractions so you have to rely on plug-ins to provide it. We have seen teams use Spinnaker via its REST API to provide this functionality.
Summary
In this chapter, we have seen the value of structuring deployment pipelines out of customizable and reusable pieces. You learned the building blocks that we find valuable and how they can be composed to follow best practices for production changes at scale.
Pipelines are defined in a pipeline configuration. A pipeline execution will happen when that particular configuration is invoked either manually or via a trigger. As a pipeline runs, the pipeline will transition across the stages and do the work specified by each stage. As stages run, notifications or auditing events will be invoked depending on stages starting, finishing, or failing. When this pipeline execution finishes, it can trigger further pipelines to continue the deployment flow.
As more functionality is added into Spinnaker, new stages, triggers, or notification types can be added to support the new features. Teams can easily change and improve their deployment processes to use these new features while continuing to use best practices.
Get Continuous Delivery with Spinnaker now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

