Chapter 4. Deployment Pipelines
Deployment pipelines are a key part of Continuous Delivery. A deployment pipeline is a series of steps that occur between CI and Production deployment, coordinated by a software tool. We use a deployment pipeline for several reasons:
-
To automate the different build, test, and deployment activities
-
To visualize the progress of software toward Production
-
To find and reduce bottlenecks or wait times in the deployment process
Done well, a deployment pipeline acts as a realization of part of a Value Stream Map, which makes the deployment pipeline a useful tool for sharing information with people in the organization who are familiar with Value Stream Mapping as a key part of modern business practices. Many people simply reuse their CI tool for managing their deployment pipeline, but this may omit the valuable orchestration and visualization that more specialized deployment pipeline tools provide.
Mapping Out a Deployment Pipeline
To start with, build a so-called “walking skeleton” deployment pipeline, with each stage between code commit and Production represented as a simple echo hello, world! activity.
As described by Alistair Cockburn on alistair.cockburn.us:
A Walking Skeleton is a tiny implementation of the system that performs a small end-to-end function. It need not use the final architecture, but it should link together the main architectural components. The architecture and the functionality can then evolve in parallel.
As you find time to automate more and more of the pipeline, you’ll reduce manual steps while still retaining the coordination of the tool.
Tools for Deployment Pipelines
The following sections provide an overview of a few tools that work well with Windows and .NET to orchestrate and visualize deployment pipelines.
GoCD
GoCD from ThoughtWorks is by far the most advanced tool for Continuous Delivery deployment pipelines. GoCD was designed specifically to support Continuous Delivery deployment pipelines and offers sophisticated features such as the Value Stream Map (seen in Figure 4-1), diamond dependencies, massively parallel builds (using remote build agents), NuGet packages as a build trigger, and an intuitive user interface that is friendly enough for developers, IT operations people, and commercial/product people alike.
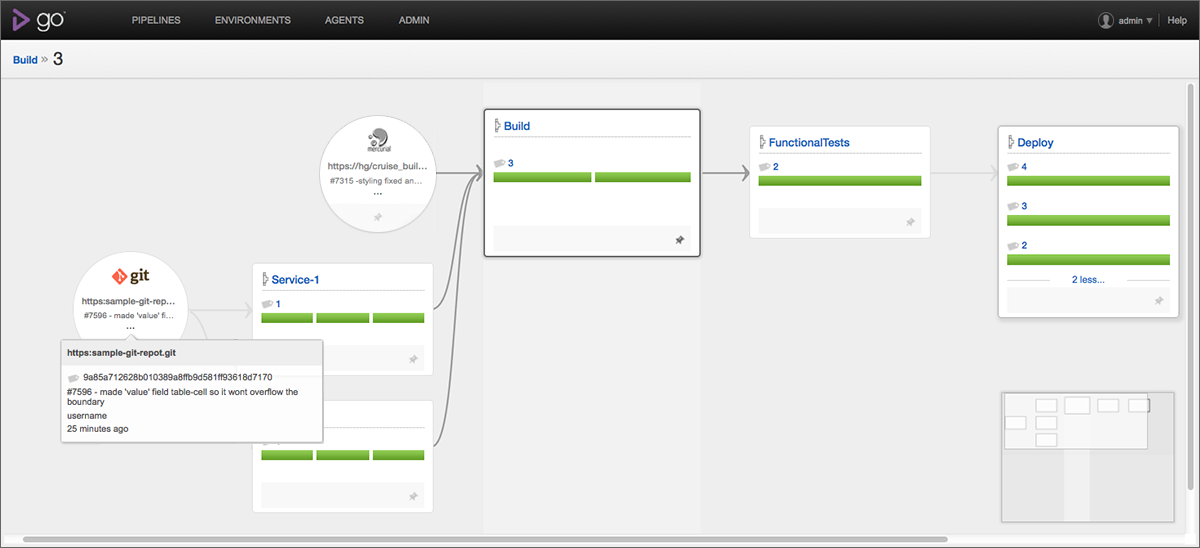
Figure 4-1. GoCD Value Stream Map view
A powerful feature for larger organizations is the rich role-based security model, which allows us to model permissions that reflect team security boundaries: for regulated sectors where developers cannot deploy to Production, for example, this is a major enabler. GoCD also provides traceability for the activity in each pipeline stage, showing what or who triggered a step. Rollbacks with GoCD are as simple as a single button click.
GoCD inherently supports nonlinear deployment pipelines, which enables teams to make informed decisions about what tests to run before deployment; this contrasts with some tools that encourage software to pass through many stages or environments every time. For large, complicated .NET software systems, GoCD is a major enabler for Continuous Delivery.
Octopus
Octopus is a deployment tool for .NET with a flexible plug-in system based on PowerShell. It uses NuGet packages as its artifact format and can connect to remote NuGet feeds to find and deploy NuGet packages. Octopus has special features for handling .NET applications, IIS, Windows Services, and Azure, so many deployment tasks are very straightforward. As seen in Figure 4-2, the concept of environments in Octopus means that deployment scripts can easily be targeted to all environments or just, for example, Production.
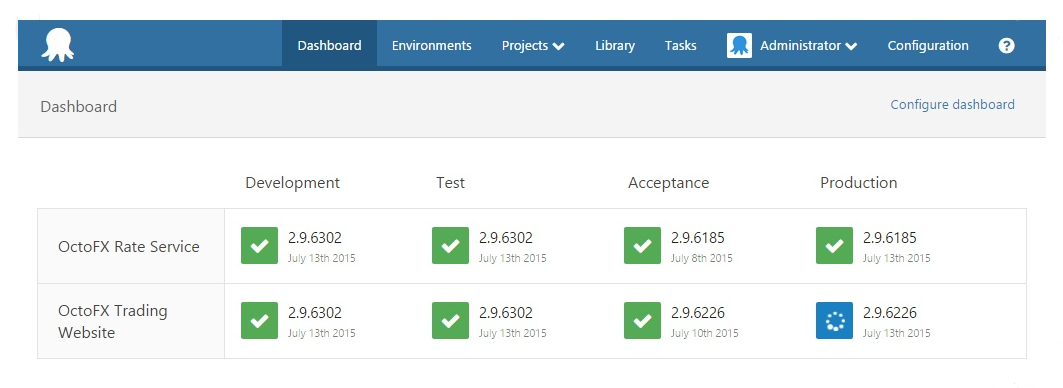
Figure 4-2. Octopus showing several environments
With its REST API, Octopus integrates well with other API-driven Continuous Delivery tools such as TeamCity and GoCD; in these cases, TeamCity or GoCD typically handles the CI and deployment pipeline coordination, calling into Octopus to carry out the Windows-specific or .NET-specific deployment tasks.
TeamCity
TeamCity is a CI server, but has many features that make it useful for deployment pipelines, including native NuGet support, powerful artifact filtering, and integration with a large number of other tools. Also, as seen in Figure 4-3, many tools integrate well with TeamCity, such as Octopus, making a cohesive ecosystem of tools for Continuous Delivery.
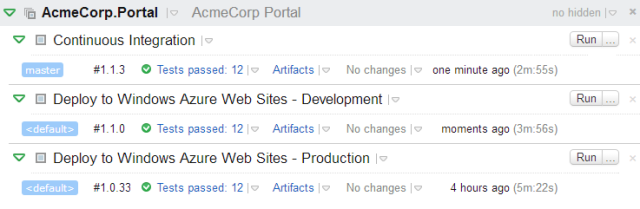
Figure 4-3. TeamCity Build Chains
TeamCity uses build chains to provide deployment pipelines, with downstream stages triggered by a successful upstream stage.
VSO
Microsoft’s Visual Studio Online suite offers a release management workflow based on deployment pipelines, as seen in Figure 4-4.1
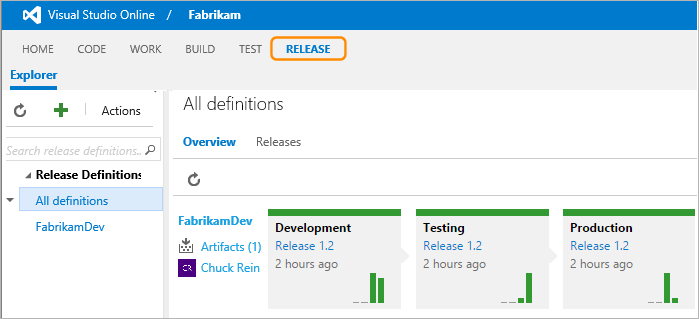
Figure 4-4. Visual Studio Online release management workflow
VSO offers clean, browser-based tools that provide useful metrics, custom deployment workflows, support for on-premise deployments, and deep integration with Azure.
Other Tools
Inedo BuildMaster has support for .NET-based deployment pipelines using chained builds, as well as built-in features for dealing with change control rules.
Jenkins has a Delivery Pipeline Plugin that provides a visual map of a deployment pipeline.
IBM UrbanCode Deploy is a tool for automating application deployments designed to facilitate rapid feedback and Continuous Delivery in agile development.
XebiaLabs XL Deploy offers point-and-click configuration of deployment pipelines combined with advanced reporting for regulatory compliance.
Deployment Techniques
There is more to deployments in Continuous Delivery than simply copying a package to a server. Our aim is seamless deployments without downtime and to achieve this we need to make use of various techniques, which we cover in this section.
Use Blue-Green Deployment for Seamless Deploys
With blue-green deployment, a Production environment is split into two equal and parallel groups of servers. Each “slice” is referred to as blue or green and initially only one half receives live traffic (Figure 4-5). The flow of traffic can be controlled by a programmed routing service, a load balancer, or a low-TTL DNS weighting between nodes.
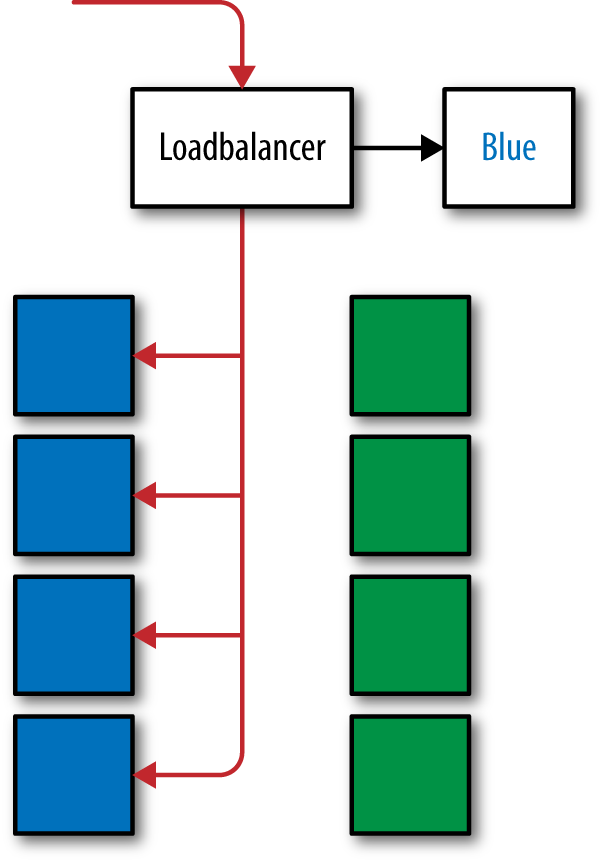
Figure 4-5. Traffic being routed to the blue slice via configuration
The slice not receiving live traffic can be used for preproduction testing of the next version of the code. Because both halves of Production are identical, this is a safe way to test a code release. The process of going live is to switch the flow of traffic from one slice to the other.
With blue-green, application rollbacks are simple and seamless; merely switch the flow of traffic back to the previously live slice.
Canary Deployments
A Canary, or Pilot, deployment is when prerelease/beta changes are deployed to a very small subset of the Production instances, possibly only a single instance, to serve live traffic. This allows for a sanity check of the prerelease before promoting it to the rest of the Production servers. Canary releases catch issues with a release package such as misconfigurations and unrealized breaking changes. They also allow for a final verification of how a new feature will behave under live traffic while maintaining minimal impact on the rest of the platform. These instances are heavily monitored with specific thresholds—such as not having an increased error rate—defined in advance that must be achieved to allow promotion of the prerelease.
With load balancing of requests, you can tweak how much traffic the canary server receives—a low weighting would send a fraction of the traffic handled by the other servers. There should only be one Canary version being tested at a time so as to avoid managing multiple versions in Production, and it should be quick and easy to remove or roll back the instance in the event of a bad release.
A Dark Deployment is similar, except that it is not included in the load balancer and does not receive live traffic. Instead, it allows for smoke tests to be run using Production configuration before promoting the prerelease. This has less risk of affecting consumers, but does not verify performance with live traffic.
Postdeployment Checks
It is important that the deployment pipeline includes methods to rapidly verify that a deployment has been successful. Deployment verification tests (DVTs) should be kicked off immediately after a deployment package has been released to the server. These checks are very lightweight and are centered around ensuring that the mechanics of a deployment were successful, while smoke tests, as described later, are to ensure the application itself is behaving as expected.
Tests should include verifying the files are in the expected location, application pools exist with the correct settings, services have been started, and that a health check URL can be successfully hit. If these checks fail, then the deployment was not a success and should be investigated further. These checks should highlight if the issue was caused by a bug in the deployment process itself, in which case a rollback may not fix the issue. The tests should help locate the failure in the process. As such, DVTs should also be run when deploying to preproduction environments as tests for your deployment process.
Smoke Tests
Smoke tests are a very small subset of your automated end-to-end tests that are run against the environment after a deployment, for example, signing up a user and performing a checkout, or processing a single batch request. These verify that the main path of the application is successful. They differ from the DVTs in that they exercise the system as an end user would.
It is important to resist the temptation to run your full suite of end-to-end tests as smoke tests. The value of these tests is in a fast confirmation that the system is operating as expected after deployment rather than fully testing the application itself.
Decouple File Delivery from Code Availability
In Continuous Delivery, it is useful to split the deployment of new software into two separate parts:
-
Delivery of files onto a server
-
Making the new software active
On Windows, we have several options for this. If our software runs in IIS, we can deliver the new code to a new folder on disk, and then simply repoint the IIS Virtual Directory to the new folder in order to make the new code live. For non-IIS code, we can use NTFS volume mount points to control the location where software is presented to the operating system, taking advantage of the Add-PartitionAccessPath and Remove-PartitionAccessPath PowerShell cmdlets to automate the reconfiguration of the mount points.
Script a Rollback Procedure Too
An excellent way to ensure confidence in your Continuous Delivery process is to have a simple and scripted process for returning to a known good state—a quick rollback procedure.
The most effective rollback is simply to redeploy the previous software version using the deployment pipeline. By redeploying the previous artifacts you are releasing proven code and not that which may contain an untested hotfix hastily added under pressure. After a rollback has been deployed, the DVTs and smoke tests should be run to ensure the rollback was successful. In order for rollbacks to work, each release needs to be incremental, avoiding breaking changes and supporting backward compatibility.
Automated Testing of Database Changes
The speed and volume of changes to modern software systems means that making database changes manually is risky and error-prone. We need to store database scripts, reference data, and configuration files in version control and use techniques such as TDD, CI, and automated acceptance testing to gain confidence that our database changes will both work correctly and not cause the loss of valuable data when deployed to Production.
Note
Consider that different approaches to database change automation may be useful at different stages of a system’s lifecycle: large-scale refactorings are better-suited to database comparison tools, whereas steady, ongoing development work may work well with a migrations approach. Each approach has merits in different circumstances.
Database Unit Testing
Many teams working with SQL Server use stored procedures to implement business logic in the data tier. It can be difficult to practice Continuous Delivery with significant business logic in the database; however, we can make stored procedures easier to test by using tools such as tSQLt, MSTest, SQL Test, and DBTestDriven. By running unit tests against stored procedures, these tools help us to practice TDD for database code, reducing errors and helping us to refactor more easily.
We can also make use of LocalDB, a lightweight, developer-friendly version of SQL Server designed for testing, which can remove the need for a full SQL Server installation.
EF Code-First Migrations
Microsoft’s Entity Framework (EF) provides C#-driven migrations (called EF Code-first Migrations). Migrations are written in C# and can be exported as SQL for review by a DBA. If you’re using EF6, then EF Code-first Migrations could work well.
FluentMigrator
FluentMigrator is an open source .NET database migrations framework with excellent support for many different databases, including SQL Server, Postgres, MySql, Oracle, Jet, and Sqlite. Installation is via a NuGet package, and migrations are written in C#. Each migration is explicitly annotated with an integer indicating the order in which the migrations are to be run.
If database changes are driven largely by developers, or if you need to target several different database technologies (say SQL Server, Postgres, and Oracle), then FluentMigrator is a good choice.
Flyway
Flyway is an advanced open source database migration tool. It strongly favors simplicity and convention over configuration. Flyway has APIs for both Java and Android and several command-line clients (for Windows, Mac OSX, and Linux).
Flyway uses plain SQL files for migrations, and also has an API for hooking in Java-based and custom migrations.
Notably, Flyway has support for a wide range of databases, including SQL Server, SQL Azure, MySQL, MariaDB, PostgreSQL, Oracle, DB2, Redshift, H2, Hsql, Derby, SQLite, and others.
Redgate Tools
Redgate provides a variety of tools for SQL Server aimed at database change and deployment automation, including SQL Source Control, ReadyRoll (for SQL migrations), SQL CI (for automated testing), SQL Release (for release control via Octopus), and DLM Dashboard (for tracking database changes through environments).
The Redgate tool suite arguably provides the greatest flexibility for database Continuous Delivery. DBA-driven changes via SSMS are supported with SQL Source Control, while developer-driven changes can use a declarative SSDT approach or ReadyRoll migrations. For organizations working with .NET and SQL Server that need flexibility and choice about how database changes are made and deployed, especially those that need input from DBAs, Redgate tools work extremely well.
SSDT
SQL Server Data Tools (SSDT) is Microsoft’s declarative approach to database change automation. SSDT is aimed at developers using Visual Studio and has tight integration with other Microsoft tooling, particularly tools for Business Intelligence (BI). Some teams successfully use SSDT in combination with other tools (Redgate, tSQLt, etc.) to compensate for some of the features SSDT lacks (such as reference data management).
Other
DBMaestro provides tools for SQL Server and Oracle, with a strong focus on policy enforcement. If you’re working in a regulated industry, the DBMaestro tools could work well.
Summary
We have looked at a collection of tools that work well for visualizing and orchestrating a Continuous Delivery deployment pipeline. A well-implemented deployment pipeline really helps to elevate the understanding of the progress of changes toward Production across the organization. We have also outlined some techniques for ensuring that our deployments are seamless and reliable.
1 The deployment pipeline feature is due to be available in an update to TFS 2015.
Get Continuous Delivery with Windows and .NET now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

