March 2017
Beginner to intermediate
163 pages
3h 45m
English
I’ve been with LinkedIn for only 18 months. Yet, what I’ve seen in data operations has amazed me. Like all consumer web companies, there’s always been an enormous amount of data that’s flowed through LinkedIn. But LinkedIn was relatively early to realize the importance of this data.
At LinkedIn, it wasn’t just about getting the analytics right. The company realized early on that infrastructure had to go hand in hand with analytics to support the data ecosystem. Many open source projects, most famously Apache Kafka, were born at LinkedIn to support this ecosystem. Today at LinkedIn, we rely heavily on the scalability and reliability of Kafka, Hadoop, and a surrounding ecosystem of open source and internally developed tools to serve our analytic needs.
Early on, the company found that different teams—such as the Email Team, and the Homepage Team—were using disparate tools when building data pipelines, as illustrated in Figure 9-1.
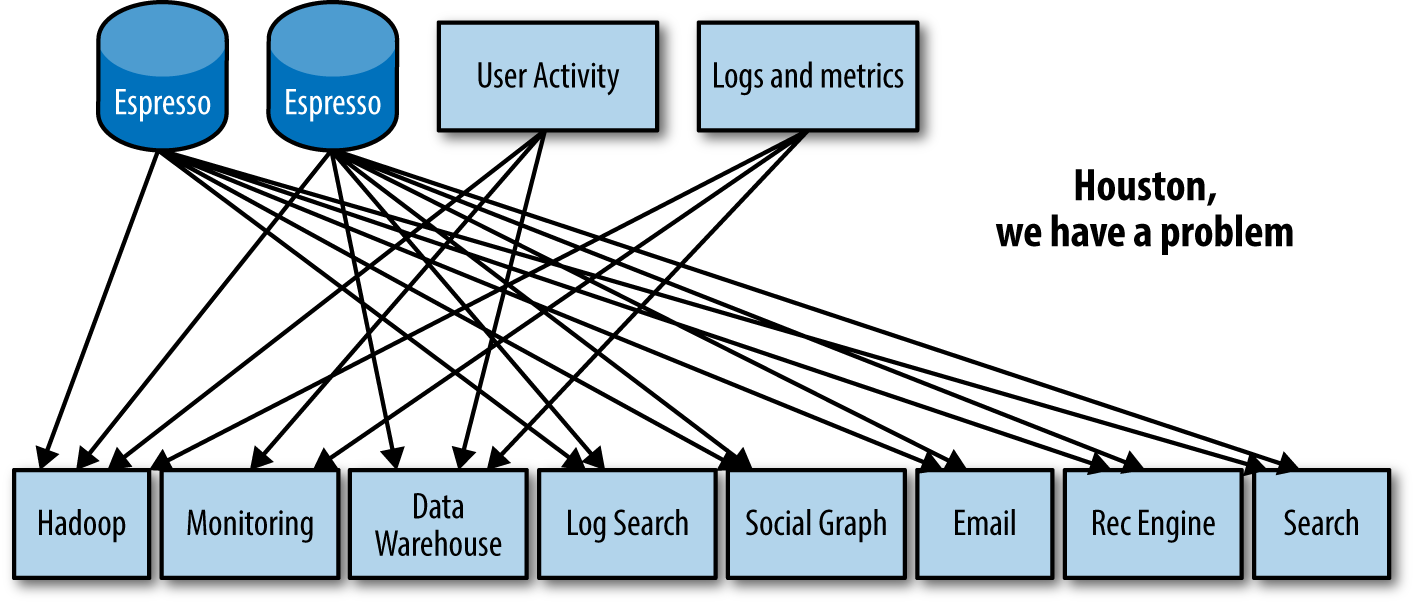
LinkedIn knew, of course, that it shouldn’t have multiple pipelines for moving and ingesting data, or for computing metrics. It’s inefficient and difficult to manage, and, most important, it leads to inconsistent and unpredictable ...
Read now
Unlock full access






