January 2026
Beginner to intermediate
318 pages
3h 38m
Chinese
本作品已使用人工智能进行翻译。欢迎您提供反馈和意见:translation-feedback@oreilly.com
在上一章中,您从工程和组织双重视角探索了LLMs的安全部署。您考察了各类基础设施考量、API设计模式及访问控制机制,这些措施有助于在生产环境中守护这些强大的模型。然而,若底层模型本身可被操控,即便是部署最严谨的系统仍将面临风险。
本章将聚焦于LLM领域中攻防双方展开的精彩博弈。您将扮演攻击者的角色,理解这些模型如何遭受攻击,继而转向探讨可保护模型的防御措施。与其他Deep Learning系统类似,LLMs同样易受对抗性攻击——即精心设计的输入数据,旨在以非预期且潜在有害的方式操纵模型行为。
这场博弈的 stakes 至关重大。随着LLMs日益融入金融服务、医疗健康、内容审核及安全系统等关键应用领域,其漏洞可能引发严重后果。攻击者若成功操控LLM,便能绕过内容过滤器生成有害内容,提取训练过程中使用的私密信息,甚至危及依赖模型输出的下游系统。
本章将深入探讨LLM安全的四大核心维度。首先全面解析针对LLMs的对抗性攻击,涵盖攻击分类、实施方法及影响评估。您将剖析从微妙词汇替换到复杂越狱策略、嵌入空间操纵等各类技术手段。
其次,您将研究增强LLM对抗性输入韧性的稳健微调技术。从对抗性训练、数据增强到TRADES优化、可验证稳健方法等高级手段,您将探索如何在训练过程中强化模型防御能力。
随后,您将深入实践针对LLMs的红队测试:在部署前系统性地探测模型漏洞。您将研究手动与自动化方法,设计能识别并缓解安全风险的有效程序。
最后,您将探索评估对抗鲁棒性的专业指标与方法论,突破标准性能指标的局限,全面评估LLM抵御蓄意攻击的能力。
本章贯穿实用案例与实施策略,在安全性和可用性间寻求平衡。完成学习后,您将深入理解LLMs领域的安全格局,掌握开发更稳健可靠模型的具体技术。
让我们踏上探索LLMs对抗性机器学习的旅程——在这里,巧妙prompt工程与安全漏洞利用的界限常被模糊,攻防博弈推动着持续创新。
在大规模语言模型(LLMs)领域,对抗性攻击可呈现多种形态,从微妙的词汇替换到精心设计的绕过对齐过滤器的prompt。这些攻击利用模型固有漏洞,常导致生成有害内容、泄露敏感信息或破坏模型与伦理准则的对齐性等非预期后果。
针对LLMs的对抗性攻击可从多维度进行分类。理解对抗性攻击的分类体系有助于防御者构建全面的安全策略,因为它揭示了攻击可能发起的不同角度。我们根据四个关键维度对攻击进行分类,这些维度涵盖了攻击方法论中最关键的变化。
图6-1展示了针对LLMs的对抗性攻击分层分类体系,呈现了不同维度(知识访问权限、攻击目标、攻击面、扰动类型)。该分类体系有助于我们理解攻击者操纵LLMs时可能采用的多元策略。
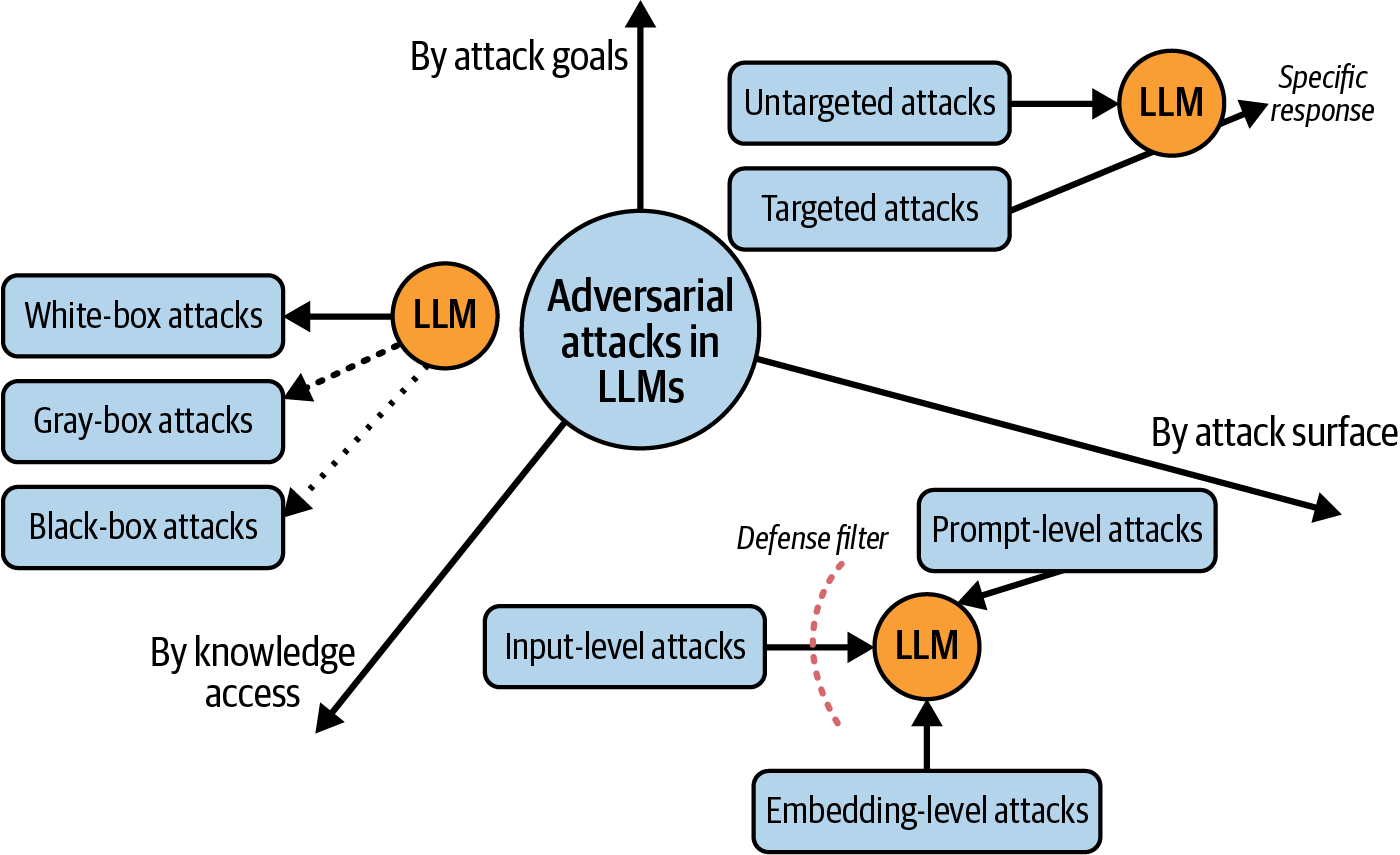
首先,攻击差异取决于攻击者获取模型知识的程度:能否窥见模型架构与权重(白盒攻击)、仅能通过API查询(黑盒攻击),或掌握部分信息(灰盒攻击)。1 该维度至关重要,因其决定了可行攻击技术及防御优先级。白盒攻击威力更强但需开源模型,而黑盒攻击对部署系统更具现实意义。
攻击者可完全访问模型架构、参数及梯度,通过优化技术实现精准操控。此类攻击威力最强,但实践中最为不切实际,仅适用于开源模型。 ...
Read now
Unlock full access






