April 2021
Intermediate to advanced
521 pages
13h 33m
English
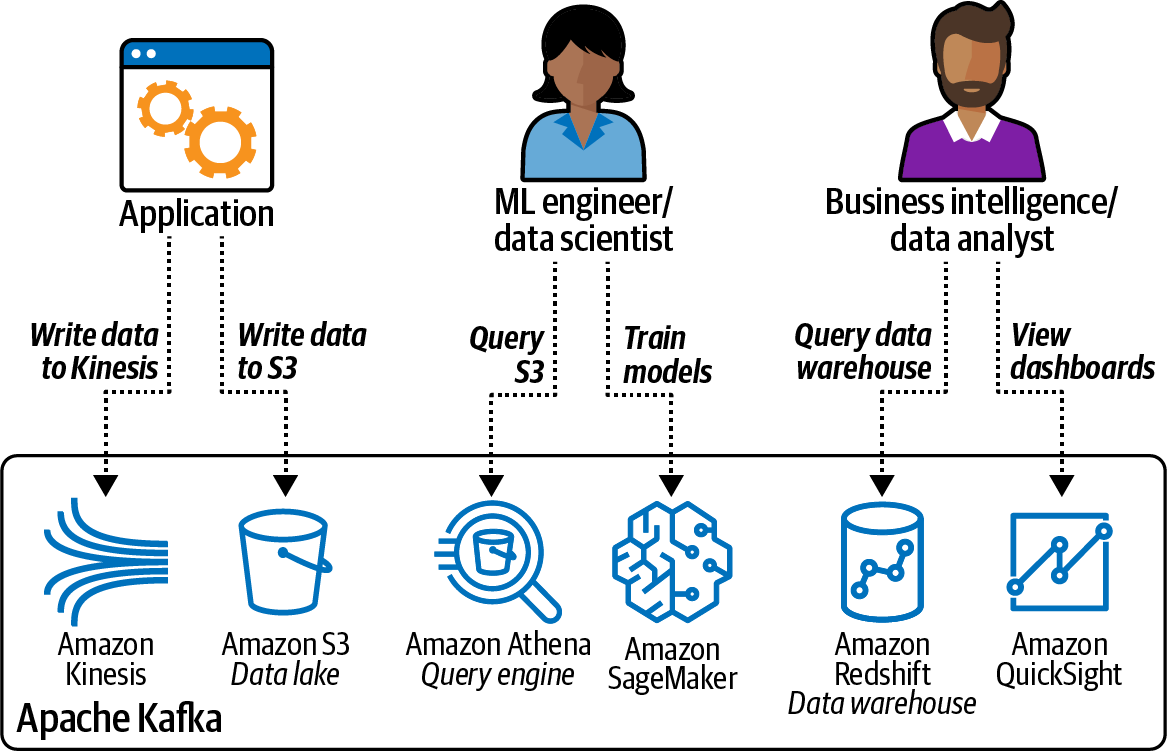
In this chapter, we will show how to ingest data into the cloud. For that purpose, we will look at a typical scenario in which an application writes files into an Amazon S3 data lake, which in turn needs to be accessed by the ML engineering/data science team as well as the business intelligence/data analyst team, as shown in Figure 4-1.
Amazon Simple Storage Service (Amazon S3) is fully managed object storage that offers extreme durability, high availability, and infinite data scalability at a very low cost. Hence, it is the perfect foundation for data lakes, training datasets, and models. We will learn more about the advantages of building data lakes on Amazon S3 in the next section.
Let’s assume our application continually captures data (i.e., customer interactions on our website, product review messages) and writes the data to S3 in the tab-separated values (TSV) file format.
As a data scientist or machine learning engineer, we want to quickly explore raw datasets. We will introduce Amazon Athena and show how to leverage Athena as an interactive query service to analyze data in S3 using standard SQL, without moving the data. In the first step, we will register the TSV data in our S3 bucket with ...
Read now
Unlock full access






