10章さらに先へ
私たちはこれまで強化学習について多くのことを学んできました。本書の前半では強化学習の基礎を学び、後半ではディープラーニングを使った重要な手法を見てきました。ここでは現代の深層強化学習として、さらに進んだアルゴリズムを紹介します。まずは深層強化学習の全体図を示し、その後に方策勾配法系列のアルゴリズムを、続いてDQN系列のアルゴリズムを見ていきます。
また本章では、深層強化学習のケーススタディとして重要な研究例を紹介します。囲碁や将棋などのボードゲーム、ロボット制御、半導体の設計など、社会で大きな成果をあげた例を紹介します。最後に深層強化学習の可能性や課題について議論し、本書を締めくくります。
10.1 深層強化学習アルゴリズムの分類
ここでは深層強化学習のアルゴリズムをタイプに応じて分類します。この分類方法は文献[20]を参考にしています。それでは、図10-1を見てみましょう。
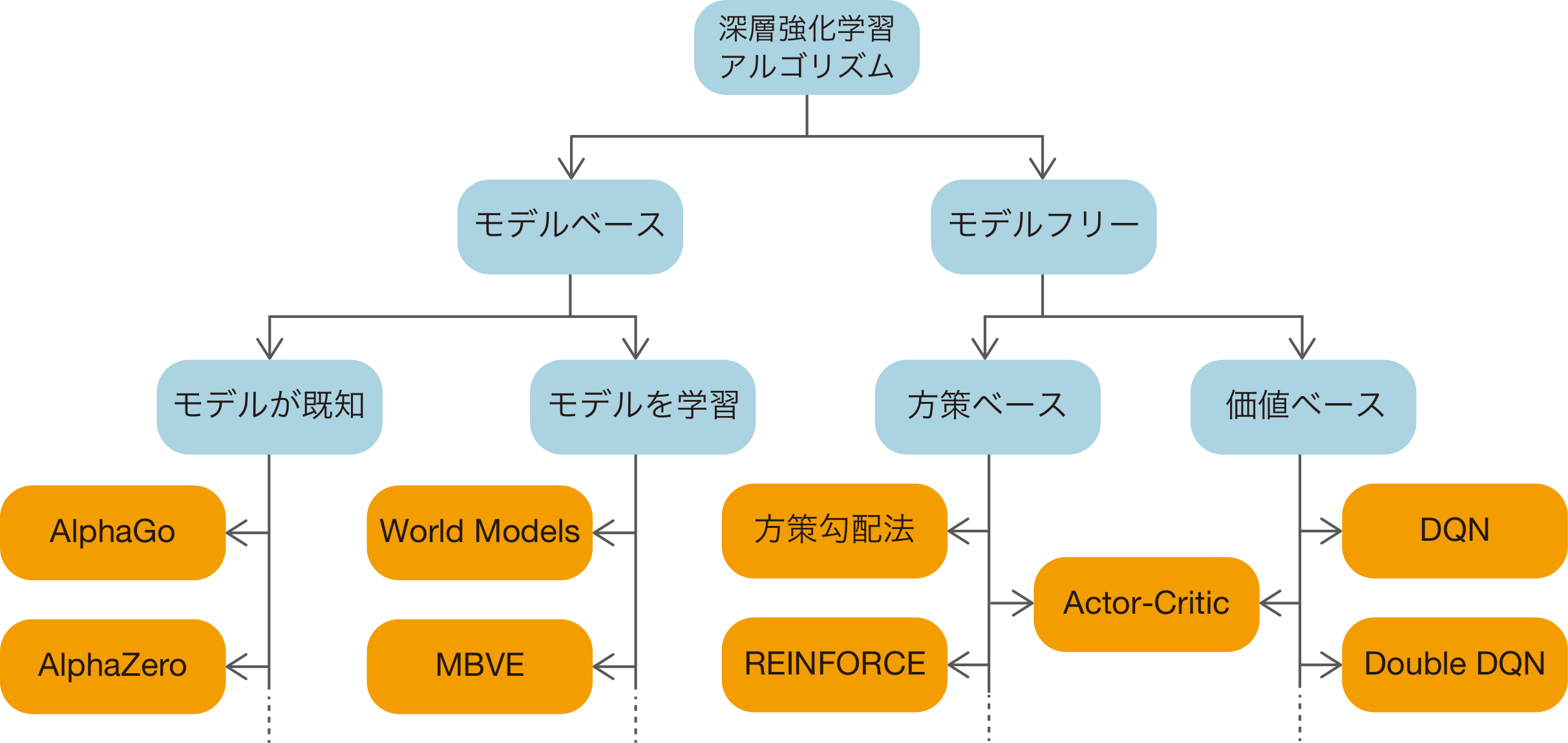
図10-1 深層強化学習アルゴリズムの分類図
これから図10-1をもとに、深層強化学習のアルゴリズムの分類方法を説明します。まず大きな分かれ道は、環境のモデル——状態遷移関数 と報酬関数——を使用するかどうかです。環境のモデルを使用しない場合をモデルフリー(Model-free)の手法、環境のモデルを使用する場合を ...
と報酬関数——を使用するかどうかです。環境のモデルを使用しない場合をモデルフリー(Model-free)の手法、環境のモデルを使用する場合を ...
Get ゼロから作るDeep Learning ❹ ―強化学習編 now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

