Chapter 1. Returning to Our Senses
If a Tree Falls in the Forest…
BRAZIL BEGAN USING SATELLITE imaging to monitor deforestation during the 1980s. This was the first large-scale, coordinated response to loggers and ranchers who had been illegally clearing the rainforests, and it worked, for a time. To avoid being spotted, loggers and ranchers began working more discreetly in smaller areas that were harder to detect (see Figure 1-1).1 This required a new approach to monitoring the forests.

Figure 1-1. A view powered by Google Earth Engine showing global deforestation
Google Earth Engine and the Brazilian NGO, Imazon, worked together to create more powerful environmental monitoring capabilities. Their collaboration identified and mapped a much wider range of deforestation in much greater detail. With new analysis techniques for satellite imagery, they were able to classify forest topologies within the rainforest. This improved the accuracy of regional assessments, both for their contribution to the surrounding ecosystem and their vulnerability to human damage. They monitored the emergence of unofficial roads that marked new human activity. They modeled the environmental risks posed by agriculture, logging, and ranching to protected areas of the Amazon. They were also able to project future scenarios to help plan a more effective management strategy that balanced human land use with forest preservation.
The NGO, Rainforest Connection, takes a more on-the-ground approach to rainforest conservation in the Amazon, as well as in Indonesia and Africa. Networks of “upcycled,” or refurbished, mobile phones are placed into solar-charged cradles, suspended high within the forest canopy (see Figure 1-2). The phones are reprogrammed to detect sounds associated with invasive activities, like motorcycles, logging trucks, or chainsaws. This cyberpunk-looking retrofitted beacon approach notifies residents and rangers who can respond immediately.

Figure 1-2. One of Rainforest Connection’s modified phones, placed to monitor sounds associated with illegal loggers (Source: Rainforest Connection)
Topher White, the founder of Rainforest Connection, described his first effort in Indonesia:
We’re talking hundreds of kilometers from the nearest road, there’s certainly no electricity, but they had very good cell phone service, these people in the towns were on Facebook all the time…this sort of got me thinking that in fact it would be possible to use the sounds of the forest, pick up the sounds of chainsaws programmatically, because people can’t hear them, and send an alert. But you have to have a device to go up in the trees. So if we can use some device to listen to the sounds of the forest, connect to the cell phone network that’s there, and send an alert to people on the ground, perhaps we could have a solution to this issue…if you can show up in real time and stop people, it’s enough of a deterrent they won’t come back.
These digital sentinels in the sky and in the trees listen and watch over natural resources. They are powerful new tools that blend easily accessible sensor technologies with new data analysis capabilities to enable immediate response to illegal deforestation.
The same types of tools are also making city streets less mean.
The Sound of Violence
A bullet leaves the muzzle of a gun at between 3,500 and 5,000 feet per second. The speed of sound is 1,125 feet per second, making a gunshot a miniature sonic boom, audible for miles. For those unfamiliar with the sound, it might be confused for a tire blowout. For those who are familiar, it is a bleak reminder of how close and how commonplace lethal violence can be.
The effects of persistent gun violence on a community can be devastating. Trust erodes between law enforcement and citizens. Residents suffer from chronic fear-induced stress, more anxious all the time, and yet increasingly desensitized to violence. They often become resigned when violence does occur. The trauma to children is especially severe, with behavioral and learning difficulties that can impact the rest of their lives.
In 2016, the city of Cape Town, South Africa, adopted a new strategy to combat gun violence. An alert system, called ShotSpotters, was deployed in two areas of the city with high levels of gang activity. Using an array of microphones spread over 7 square kilometers, the system recognizes the sound of a gunshot, analyzes the sound to position its source, and then determines GPS coordinates. In under 60 seconds, the GPS coordinates are reported back to the Cape Town police, who can then send officers to within 2 meters of where the shot was fired (see Figure 1-3).

Figure 1-3. ShotSpotters places sensors to monitor for gunshots and alert police (Source: ShotSpotters)
In one case, a gunshot was picked up and located by the microphone system. Per typical police response, a K9 unit—a trained dog and a police handler—was sent to investigate. On the spot, police noticed that two people saw them and immediately ran away, so they followed them to a nearby house. In the house they found and confiscated an illegal automatic 9mm gun, along with 64 rounds of ammunition and a magazine.2 This immediate response became the norm.
Blending emerging smart city technology and trained Cape Town officers, the use of ShotSpotters was hugely successful. Within one month, the number of illegal gunshots dropped from 211 to 128. Within two months it had dropped to 31, eliminating 85% of the gunshots fired. In total, 54 guns have been removed from the streets in 7 months—a figure that was previously only achieved over a 6-year period.3
Catching the shooters required large amounts of physical information to be collected, analyzed, and applied to action in real time: correctly identifying the sound and time of a gunshot, positioning its source in geographic space, knowing the location of the nearest K9 unit. Once on the scene, trained police dogs sought the scent of gunpowder. The police officers visually identified the suspects.
These stories are not just about policing or monitoring. They are also about the intersection of some of our oldest and newest sensory abilities and how we use them to understand and interact with our world. Vision originated under water as a patch of protein-based photoreceptors on a single-celled organism, during the Cambrian explosion hundreds of millions of years ago. Tracking dogs have been used since Roman times, and police dogs have existed for over a hundred years. A human has about 5 million scent glands, whereas dogs have 125 million to 300 million. Their sense of smell is up to 100,000 times better than ours.4 Sound triangulation cross-referenced with GPS coordinates distributed via cloud-based analysis is relatively new, developed within the past decade. Technology can extend our natural sensory abilities, allowing us to see subatomic particles, to hear across a city, to keep watch over a continent, and to observe the farthest reaches of our universe. It lets us use our senses in ways we never have before, but it also relies on how we naturally use them in the first place. Understanding how our senses evolved, and how we use them now will help us as we design for new ways to use them in the future.
Experience Is Physical
Our senses gather the physical information that surrounds us. This information can’t be Googled, but we use it all the time. We can tell it’s morning by the light seeping through our curtains. We can tell what’s for dinner by aromas coming from the kitchen. We grab our umbrellas when we hear the sound of rain. We laugh when we get a joke, and hopefully, we can tell when someone doesn’t get the one we’ve just told. Aided by technology, we can tell that someone has just arrived at our front door, that our email was just sent, or that the truck in front of us is about to reverse (see Figure 1-4).

Figure 1-4. Think about the way your senses work throughout the day. Sunlight can wake you. The smell of cooking can remind you how hungry you are. The sound of rain can delight or disappoint, depending on your plans.
David Eagleman is a cognitive neuroscientist who studies how human experience and the mind shape each other. He writes:
Sealed within the dark, silent chamber of your skull, your brain has never directly experienced the external world, and it never will. Instead, there’s only one way that information from out there gets into the brain. Your sensory organs—your eyes, ears, nose, mouth, and skin—act as interpreters. They detect a motley crew of information sources (including photons, air compression waves, molecular concentrations, pressure, texture, temperature) and translate them into the common currency of the brain: electrochemical signals.5
Everything we know, do, and say happens through our senses—both the information we accumulate and how we act upon it throughout our day.
Unlike Tank in The Matrix, most of us can’t do much with falling lines of machine code. The gazillions of bits of information on the internet must be translated to and from 1s and 0s into interfaces that we can physically experience. We can read text and view images, videos, and virtual worlds. We can hear sound alerts or speak requests to the latest speech assistants. We can feel the buzz of our phone in our back pocket, or the victorious rumble of the game controller in our hands as we blow up the last boss on the last level. We experience everything, whether physical or digital, natural or designed, through our senses.
Our senses are always on, sending a continuous stream of information through our nervous system to our brains. But a good deal of the time, we aren’t aware of our senses at all. Think about what shoes feel like on your feet. You probably really haven’t noticed them except when you put them on, unless they are uncomfortable. You probably didn’t even notice what having feet felt like today until you read this just now (see Figure 1-5). Though essential to experience, we only notice a tiny fraction of the sensory information we gather.

Figure 1-5. Take a moment to feel your feet. When they are in shoes, we barely notice them. When we take off those shoes to walk barefoot through the grass, the wonderful sensation can completely take over.
At certain times, a single sensory experience, like a delicious taste or a beautiful piece of music, can consume us. At other times, we can tune out the monotonous conversation in front of us, or laser focus on the cutie giving us the eye from across a booming party. We can switch focus between different sensory experiences lightning fast: when we hear a sudden loud noise we turn to look. We shudder when a slimy fish touches our feet underwater. Sometimes we consciously choose where our attention is, and sometimes our reflexes take over.
[NOTE]
For the sake of clarity, the word modality will be used to describe human capabilities and the word mode will be used to describe device capabilities. They are often used interchangeably, but that would make this a very difficult book to read, let alone write. To add to the confusion, multimodal is used for describing both people and devices that have either multiple modalities or modes. We hope that this will be clear in context.
People Have Modalities
It isn’t enough to simply sense the world around us. We need to extract meaning from this information and use it to make decisions and take action. Once light has been gathered on the back of our eyes by the retina, we interpret color, brightness, shapes, and movement. Because we have stereoscopic vision, we can also perceive distance. If we recognize a familiar face, we might smile and wave. If we recognize a snarling animal, we might back away.
It turns out that there are specific ways to interpret sensory information and apply it to our decisions and actions. We can recognize shapes visually and through direct contact, when we touch them. We don’t generally taste or smell shapes to tell them apart (see Figure 1-6). Along the same lines, vibrations might not be the best way to provide IKEA furniture assembly instructions.

Figure 1-6. Which of these chocolates is tarragon grapefruit, and which are cardamom nougat, or lavender vanilla? Our sense of vision works better for figuring out some things than others. Sadly, this book is not lickable, so you may never know.
The kinds of information we sense, the way we interpret that information, and the kinds of decisions and actions that can be based on that information are linked. Over the course of our lives, we develop patterns in how we use different sensory channels. These are called modalities. They are also known as sensorimotor schema. These modalities are usually described by their focal sense, like visual, auditory, or haptic. Vision relies on our eyes, audition relies on our ears, and haptics rely on our sense of touch and movement. Using these senses together is known as multimodality. Modalities shape the way we use sensory information to inform our behaviors (see Figure 1-7).

Figure 1-7. A behavioral pattern using a set of perceptual, cognitive, and motor functions together
We are multimodal most of the time; very few human behaviors are unimodal. For example, walking down the street combines our sense of balance, vision, touch, and movement. Having a conversation combines the sense of hearing and vision, our ability to create speech, and perhaps also movements and touch if you tend to talk with your hands.
These combinations make our daily interactions possible. At a traffic light, we learn to step on our gas pedal when we see a green light. A yellow light makes us consider whether to step on the brake or not. We hear a kettle whistle and turn off the burner. We see a branch across our path, and we decide whether to jump over it or walk around it. We hear marimbas, and we pull out our phones to see who is calling. Our senses enable a wide range of behaviors, making us adaptive and responsive to the world, to each other, and to our devices. The more we use each multimodal combination, the stronger they become, forming the core behaviors, habits, and skills we use throughout our lives (see Figure 1-8).

Figure 1-8. Learning the alphabet through reading, writing, and singing (Modalities have been applied to education, where it is believed that some children have stronger visual, auditory, or tactile, kinesthetic learning styles. Teaching materials may include a mix of media to accommodate this.)
Devices Have Modes
Devices are now also becoming more adaptive and responsive. For a long time, the evolution of personal computing seemed somewhat steady: from the keyboard and mouse, to the feature phone, to the smartphone. Then it seemed to pick up the pace: tablets, Siri, the Nintendo Wii, XBox Kinect, Google Glass, the Nest thermostat, wearables, driverless cars, the Oculus Rift, Amazon Echo, and Google Home. It’s reached an astonishing velocity (see Figure 1-9).

Figure 1-9. The number of interface modes has kept pace with technical innovation, and has likely contributed to it as well
These different channels of interaction are called modes (see Figure 1-10). Similar to human modalities, they are developed around specific types of physical information. While multimodal interfaces have always been a part of user experience design, there have never been as many different kinds. Speech, touch, haptic, and gestural interfaces are now ubiquitous across laptops, smartphones, tablets, game consoles, and wearables. Virtual reality (VR) is growing across the gaming industry, and new types of products are entering our homes, cars, offices, and the streets of our cities. Devices can now use many different kinds of human behavior as input and provide feedback across a wide array of outputs.

Figure 1-10. The building blocks of device modes mirror those of human modalities
An example of this is force touch on Apple devices. When a user hard presses on an item, say an email header in their inbox, the taptic engine creates a “popping” haptic feedback, accompanied with a blurring visual effect. The touchscreen employs a number of force resistance capacitors to detect the amount of pressure that is being applied, the position, as well as the duration. Once the touch gesture is recognized, it provides various email features on the screen.
There can be many different modes for the same interaction, or multiple modes within a single interaction. In fact, the moment computing became multimodal (via the mouse, keyboard, and GUI) was when it really began to become accessible to everyone.
Think of using your screen or Siri to make a phone call. To call someone, you can tap out the phone number on the touchscreen. You can also ask Siri to make the call for you. You may have long-pressed the Home button to initiate Siri in the first place or have simply said “Hey, Siri” (see Figure 1-11).
Figure 1-11. You can use buttons to make a call yourself (left) or ask Siri to dial for you (right)
Human Modalities + Device Modes = Interfaces
Technology can now be embedded into any object or environment, seamlessly integrating into a wider range of our experiences. It can literally be incorporated directly into our bodies. Screens, locks, cars, glasses, and many other objects can now be considered devices, as they become connected and digital. The kinds of interactions we can have with these devices has expanded well beyond the clicks, swipes, and taps that we are accustomed to with screens. Approaching a door fitted with an August smartlock can unlock it, while walking away can lock it again (see Figure 1-12). Many fitness devices can tell the difference between walking, running, and biking, which trigger them to start tracking the activity. (Unfortunately, we still have to do our own exercising.)

Figure 1-12. An August lock can open when it detects its owner
Our interactions with technology are being blended into the ways we already interact with the physical world, and product design teams are responsible for figuring out how. These types of interfaces, like hands-free or eyes-free, complement the physical activity they accompany. Many have existed for some time with simpler mechanical technologies. Turn signal in cars are augmented by clicking. We may not have the chance to glance at the blinking arrow on our dashboard, but we can hear that our signal is engaged by the sound.
In addition, these physical interactions may have many layers of information within a single sensory channel; VUIs are an example of this. Prosody is the intonation, tone, stress, and rhythm we use in spoken language. It expresses meaning and emotions beyond words. Changes in intonation and stress can indicate sarcasm. They can also change a statement to a question. For interaction design, prosody is important to designing voice interfaces, but it has equally powerful implications for all sound design. Game designers use prosody to great effect (see Figure 1-13). Background music speeds up to let players know that they are running out of time. Triumphant music often rises in pitch, while setbacks are marked with falling tones.

Figure 1-13. The video game Vilmonic, like most others, uses tonal sound effects and short melodies to reinforce a sense of drama and narrative
It’s also very common for people to use one sense to compensate for another. This behavior, known as substitution, allows us to use an alternative sensory modality when our usual modality is blocked or engaged. When it is dark, we put our hands out in front of us and shuffle our feet. We can no longer see obstacles in our path, so we feel them out. When it’s loud, we may look at the movements of a person’s lips more closely and may use more gestures to communicate. Many crosswalks use sounds to indicate changes in signal. Closed-captioning originated as way for people with hearing impairments to watch films and television; it is now a staple of sports bars where no one can hear a television at all. Substitution is a very common design strategy for accessibility: Braille, screen readers, and sign language remap information from one sensory modality to another. But it’s common for all people to rely on other senses when they cannot use their typical modality for a task.
Our senses of vision and hearing are very closely tied together and we develop many multimodal behaviors between them. In multisensory integration, an effect known as synchrony emerges, where we try to align visual movement and auditory rhythms together. Our visual and auditory abilities reinforce each other, and increase our ability to predict each other better. Those 8-bit game sound effects aren’t just retro cool. They help players learn to play and develop their skills more effectively. They reinforce the difference between a positive and negative event using some of the same cues used in spoken language. The audiovisual combination is particularly effective for timing or rhythm-based user activities. The combination of visual, haptic, and proprioceptive abilities—our senses of sight, touch, and movement—reinforce each other in creating spatial mappings of objects and environments. Much of screen-based design relies on this sensory integration in creating core interactions like navigation and browsing.
Much of interaction design relies on how each sense works individually and on abilities that emerge from how we integrate them together. Mapping sensory modalities to interface modes correctly can mean the difference between a cohesive experience and a disjointed one (see Figure 1-14). This integration can also help people learn new experiences more quickly and feel excited and delighted by them.

Figure 1-14. Human modalities and device modes work together to create feedback loops, essential for effective interactions.
Physical Information: The New Data
We use physical information to guide all our experiences. We monitor air temperature with our skin to decide if we need a sweater. We use proximity to gauge when to reach for a doorknob as we are walking towards it. We hear the sound of an oncoming train and start shuffling toward the edge of the platform. Researchers estimate that the eye alone can capture 10 million bits of information per second.6 We use a phenomenal amount of physical information to get through our day.
These kinds of physical information are making their way into interaction design through the expanding variety of sensors in devices. Ruggedized, miniaturized, and power-optimized for their use in smartphones, these components and technologies now easily cross over to new environmental and usage contexts. The research company CBI says that from 2004 to 2014, the cost of sensors fell to an average of $0.60 per unit: “Declining sensor cost is one of the main drivers of Internet of Things technology, and the proliferation of internet-connected devices in the built environment. Those sensors are allowing us to gather new data that was previously inaccessible.”7 In Teslas, they are used to help cars park themselves. Our ovens might use them to tell us that they have reached the correct temperature for lasagna. Smoke detectors monitor carbon monoxide—a gas that we cannot easily detect on our own.
The use of physical information expands the types of interactions we can have with our devices, and the kinds of functionalities that can be automated. Using sensor-based data to shape interactions is a substantial shift from forms, clicks, and other measurements of screen-based user behavior. Interactions can be more immediate, more contextual, and more dynamic. Physically rooted interactions can feel more intimate and private to the user, and impart a stronger sense of embodiment and identity. They also introduce considerations about how information is gathered and used.
Sensor data is often a continuous stream of information, as opposed to a set of individual data points. That can require much more processing and analysis in order to extract meaning, and the meaning that’s extracted can be more than a user bargained for. Biometric analysis can extract a person’s identity from certain kinds of data, exposing them to cybercrime and immoral or illegal forms of bias. Compliance laws are particularly strict around health and identifiable information, with requirements about the type of data, how it is used, as well as where it is stored, and for how long. The way this information is managed will determine whether people trust the next generation of devices and the companies that make them.
The same types of privacy issues led to public concern about the ShotSpotters system.
“The microphones are only listening for gunshots. But, there have been a few cases where someone’s voice was picked up by ShotSpotter’s mics,” says Oakland police officer Omega Crumb, who’s responsible for much of the department’s technology. He believes an incident in which an officer from the neighboring city of Fremont came to Oakland to serve a warrant was a case study in how valuable that recording can be.
“They get out to make the arrest and the suspect shoots the Fremont officer,” Crumb recounts. “The suspect said when he went to court that he didn’t know it was the police, they never said it. ShotSpotter was able to come in and pulled that sensor and you can hear them clearly saying, ”Freeze! Police,’ And then you hear the suspect shoot. So that was a key one. That was a big one for us,” says Crumb.
In another case in 2007, a shooting victim shouted out the street name of the person who just shot him—and that recording was used in court to convict the killer of second-degree murder.
This technology allows the police to record our conversations without our knowledge. The privacy concerns are obvious. “Are they maybe this terribly evil thing right now? No. Probably not,” said Brian Hofer, now chair of the Oakland Privacy Advisory Commission, who worked with the city government to create a privacy policy for ShotSpotter. “Could they be? Sure, just re-program your software.”8
In response to this, the CEO of ShotSpotters commented:
It’s a healthy conversation to have. We need to discuss the costs and benefits of these new technologies, and examine the trade-offs, not only in how the data is used, but if there is data leakage. We don’t yet fully understand the trade-offs in the benefits or costs of using this kind of information on behalf of users. The security threats are just surfacing. We’re going to find out what they are very rapidly.
The decisions that users and companies make together on these issues will not only shape our experiences, but our rights as well. Making these decisions explicit and transparent is vital.
Sensing, Understanding, Deciding, and Acting: The New Human Factors
The foundational tenets of user-centered design originated from research and design principles in the fields of marketing and industrial design: understanding user groups, designing for how something is used as well as how it looks, designing for real people across a variety of sizes, shapes, and abilities. These tenets had existed for almost a century. And then the computer came along and flipped the script. Very rapidly, designers needed to shift from how people used objects to how they interacted with information. Those interactions focused primarily on a single type of hardware: the screen. Much of what we know about usability is based on it. This shift was profound for designers, but its impact to our collective behavior was even more so. We now spend most of our waking hours with screens. For the last 30 years, the screen has risen in use until it completely dominated all of our interactions of any kind. We spend more time with screens than we do with other people, the outdoors, pets, or other kinds of tools. The only other thing in your life that comes close to that much of your face time is your pillow. User-centered design helped create a screen-centered life for many people.
The rise of new interface technologies is poised to reverse that tide and redefine the role of technology in our lives. We know a great deal about how people consume information. The rise of sensor-based technologies is illuminating how we live with it. Information and interactions can be distributed across many kinds of device capabilities and in any physical object, environment, activity, or event. An input trigger could be the moment a person comes within a set physical location, such as with GPS or beacon devices, not just a direct interaction with a device interface. An output might be a text notification, or a fully automated behavior, like having your living room mopped. To create these kinds of interactions requires a new understanding of user behaviors.
A simple way to organize these new factors is by what we are doing with physical information during an interaction: how we sense, understand, decide, and act. These are the core building blocks to all multimodal experiences. We may not use all the blocks in every single experience and there is overlap and interplay between them. In other cases, they may form a response loop.
This particular model helps to break apart the kinds of design considerations that occur across the multiple modes of interactions. It also provides flexibility around how human modalities blend together and how different interface modes can be mapped to them.
Sensing
Perception is not just how we sense physical information, but how we become aware of, organize and interpret it. An example of perception is hearing: it is specially attenuated within the range of the human voice, which comes as no surprise. The physiognomy of our ears—the tympanic membrane, the malleus, incus, and stapes of our middle ear—is physically optimized to transmit those acoustic frequencies.
In the same way that standards for text legibility are well defined, the sensibility of other kinds of physical information will begin to become more firmly established. The use of speech technology introduces new metrics, like the number of utterances in a voice interaction, and confidence—the likelihood that a word was recognized correctly. Haptic interactions can be measured by pressure or force, vibration speed, and intensity. Traditional usability metrics are being applied to new types of experiences as well. Differentiation and recall, tests that can be used to measure the usability of icons, are also being used for haptic vibrations, sometimes called hapticons; these gauge how well a person can remember a vibration pattern or tell two different patterns apart.
Product development teams will need to be familiar with the anthropometrics that describe our sensory capabilities, like our field of vision, the range of human hearing, and the amount of force detectable by our sense of touch. We will also need to better understand how we process that information and apply it during physical activities.
Understanding and Deciding
Cognition describes the processes we have in place to help acquire understanding and knowledge. An example of this is how the speed and accuracy of our reading ability play decisive roles in the design of road signage. At highway speeds, our ability to read a sign degrades rapidly because of how quickly we pass them, so the number of words must be limited. Our ability to recognize our exit and to make a turn off is also affected. To accommodate this, exit signs may need to be placed a full half mile before an exit to give us the time we need to process the information, make a decision, and execute it. These response times aren’t just good design practice. They are federal regulation.
Executive cognition is part of this, which is how we use understanding to control our behavior. There are many different models of decision making in psychology, and probably no single right one. In a lighter example, there are many kinds of decisions when it comes to dessert. You can decide to have chocolate pudding instead of lemon cake, which is preference. You can decide that you really shouldn’t have cake at all, which is inhibition. You can decide that you need cake right away, and begin to bake one, which requires procedural abilities. There are also different levels of decisions like buying a cake versus starting a bakery, and they require their own information, analysis, and sequence along the way.
Acting
Action is to apply information (or sometimes not apply it) in the physical world. Our primary forms of action are physical movement and speech. Physical movement is spans basic skills like gripping objects and moving your eyes while scanning images, to more complex activities like paragliding, chopping vegetables, or playing electric guitar. Action encompasses not just the activities themselves, but how we acquire these physical skills. Repeating a physical activity over time can improve our ability to execute it. Repetition can also make it a more permanent and automatic part of our behavior: an ingrained habit like biting your nails or an expert skill like your tennis swing. This is especially relevant to augmented, assistive, and automated technologies, and understanding the ins and outs are critical to human safety. One example is the way we automatically move our eyes to focus them, a reflex called focal accommodation. Because we have no control over this reflex, it can interfere with the use of VR and AR headgear, causing dizziness and nausea.
Awareness during physical activities is idiosyncratic. There are some activities, like flossing our teeth, where we mentally check out and it’s OK. It’s easy for us to multitask and maybe watch a TV show at the same time. There are other activities where we want to check out, but shouldn’t, like repeating a forklift maneuver for the 78th time today. The key is balancing engagement against cognitive limits.
Focus: The New Engagement
For the first time in 50 years, the number of fatalities from traffic accidents in the United States rose in 2015. This rise was widely attributed to distracted driving—using smartphones while at the wheel.9 While adding turn-by-turn navigation to driving has fundamentally changed the experience, access to other features has also made it more dangerous. These dangers must be prioritized and carefully considered; a person’s focal abilities must come first. Adding a new activity or modifying the current one can cause user errors or complete distraction. Engagement is not always what it’s cracked up to be.
Conversely, focus is gaining prominence in interaction design. It’s the ability to prioritize, organize, and delegate attention in a controlled but comfortable way. Reducing distraction is one part of this, but supporting the way our attention naturally works is another. Designing for focus also accounts for the duration of activity, fatigue, and other factors.
Flow is a state of mind first described by psychologist Mihaly Csikszentmihalyi. The writer Dana Chisnell describes it as being “”in the zone,’ relaxed and energized at the same time. The outside world ceases to exist and time fades away. Awareness heightens and senses are charged, increasing productivity and creativity.”10 In physical activity—which is pretty much all activity—flow is the ideal state of performance. Perception, cognition, and action fuse into a seamless, effortless multimodal experience.
These flow states emerge as we develop “ways to order consciousness so as to be in control of feelings and thoughts.”11 And flow is necessary to accomplish many different kinds of daily activities. Just imagine throwing a ball to a dog. You do it pretty effortlessly. Now try to imagine calculating the distance, force, and trajectory mathematically, accounting for both the weight of the ball and your own arm. All of that complex calculation is already in the throwing action. You figured it out, you just didn’t do it consciously. We need to be in a flow state to successfully complete many kinds of activities. Flow creates control from non-aware perception, cognition, and behavior. Counterintuitively, we can do certain things better when we aren’t fully aware that we are doing them. This is the opposite of what most would consider engagement in interaction design, which is a high level of awareness.
Enabling focus in multimodal experiences is creating the right combination at the right time: filtering distraction, prioritizing and organizing aware engagement, allowing for flow—non-aware engagement, and even allowing for disengagement. Different kinds of multimodal experiences have different impacts to focus or require certain levels of focus to be effective. For example, reading can be difficult in noisy environments, especially if there is a great deal of spoken language in the background. When both our eyes and ears are trying to use the language-processing part of our brain, it can cause crossed signals. On the other hand, some people tap their feet to music, accentuating rhythm—which is a special pattern recognition of its own. They might not even realize they are doing it, but it enhances the experience for them. Some modalities complement each other. Some conflict. It depends on a number of factors, like the person, the context, and the modalities.
Multimodality Makes a Wider Range of Human and Product Behaviors Possible
We have various systemic and cross-modal abilities to process the sensory information we gather. For example, our ability to detect rhythm spans audio and haptic patterns. Some of our sensory behaviors are reflexive or tied to involuntary or instinctive behaviors. A loud sound or bright light can trigger a startle response, where we might literally jump to attention to respond to what is happening. Mercedes-Benz takes advantage of this in one of its new safety features, called PRE-SAFE Sound. According to Wired:
When a collision is detected, the car emits a static sound at about 85 decibels. This is loud enough to trigger the acoustic reflex that contracts the stapedius muscle in the middle ear to block out the sound, protecting the sensitive eardrums and other bits of the inner ear. This sound is not loud enough to cause hearing loss, but it protects the ear from the airbag deployment, which can emit a pressure wave in the 150–170 decibel range, which can damage hearing.12
People are able to combine their sensory abilities, analytical and decision-making processes, and physical skills in limitless ways. Product teams have only just begun to scratch the surface of how to combine modes in our technologies. The types of multimodal abilities and interfaces is as limitless as the kinds of experiences we can dream up.
How Multimodality Affects Design
Creating Usability
All interactions rely on some aspect of human multimodality, though sometimes in unexpected, and even counterintuitive ways. We get used to the mostly silent, mostly rectangular presence of our phone in our pocket, except perhaps when we sit down on it funny (see Figure 1-15). We don’t really notice the weight or size of it at all. Sometimes, if we are looking for our phone, we have to tap or rummage through all our pockets to find it, even though we could technically feel it in our pocket with the nerve endings in our skin. In a short amount of time, we forget the feeling of the seat we are sitting on and focus on the meal in front of us. Our eyes adjust to darkness, our sense of taste to a soup that’s just a little too salty, or our skin to the temperature of a cold swimming pool. Over longer periods of time and repetition, we can fall asleep easily in a noisy city apartment, or drive less stressfully on a winding road in the dark. This phenomenon, known as neural adaptation, allows us to filter out repeated sensory stimulus. This frees our focus for new information that we can quickly compare to our existing expectations of an experience.

Figure 1-15. Nothing gets between me and my notifications...or does it? Do you feel your phone in your back pocket every second of the day that it’s there? Or just sometimes, like when it vibrates?
Neural adaptation is precisely why interactions like notifications and alerts work. Once we are accustomed to a certain noise level or the visual state of our laptop screen, we set a baseline sensory expectation called a threshold, and concentrate our attention within it. A sudden vibration or sound deviates from that baseline, and we automatically refocus our attention. We notice that sound and figure out how to respond. Our static screen has a flash of a different color and animation on it; we read the alert.
While we might think of engagement as one of the most important parts of user experience, it is partly our sensory ability to disengage that makes notifications effective. What allows us to refocus our attention is the contrast in sensory expectations to the new sensory stimulus. This can be triggered by activating an unused sensory channel, like a sound when it’s quiet. It can be within the same sense that we are focused on, but by changing it: an animation or a shot of a vivid color when the visual field is static or monochrome. It can be by a different sensory channel, like a tap on the shoulder when we are concentrating on a book. What can be most effective is to use some combination of all of these.
The reverse can also work. Reducing or eliminating an expected stimulus can also redirect our attention. It can be unnerving when all conversation stops suddenly as we enter a room. We definitely notice. Eliminating the responsiveness of one button can redirect a person to seek one that does work. A dimming screen lets us know that our laptop is about to go to sleep. People automatically seek out and notice these changes, called threshold events. They anchor our experiences and form the boundaries and transitions between them (see Figure 1-16).

Figure 1-16. The iPhone and MacBook use several different ways to interrupt our threshold, or baseline sensory experiences, to deliver notifications
Paradoxically, neural adaptation can eventually cause interactions to fail. Over time, we get used to certain types of stimuli, and start to tune them out—especially when they are overused or aren’t immediately relevant. Since 1993, browser-based advertisements were usually in a banner near the top of a screen or down the righthand column. As a result, people developed banner-blindness; they stopped seeing banner ads on pages all together. They visually recognized the shape and position of the banners and filtered them out without reading them.13 Because of this, internet advertising formats are an endless arms race between our brain’s ability to filter out noise, and advertisers’ efforts to regain our attention.
Neural adaptation is one of the many attributes of multimodality that can play a powerful role in creating effective user experiences. Most significantly, multimodality shapes how we learn from new experiences, how we focus and engage within experiences, and how that focus and engagement adapt over repeated experiences. It is a crucial component of multitasking, “expert” behaviors, and calm technology. It also underpins most design strategies for accessibility.
Creating Delight, Trust, and Love
More than this, the senses and modalities are inextricably tied to perceiving quality and experiencing delight. When we shut a door made out of solid hardwood, there is something really satisfying about the weight, the slow swing, and the precise click of the bolt catching. We can tell that it’s sturdier than a hollow particle board door by how it moves and the sound it makes (see Figure 1-17). Much of the delight of experiences is sensorial, whether an intoxicating perfume, a soulful song, a breathtaking view, or the lulling sway of a sailboat on a calm sea. It’s poetic to describe delightful experiences across senses: a velvety bite of cake, a deliciously satisfied grin, a gentle caress as soft as a daydreamer’s sigh. To take a less lyrical tack, there is a scientific basis to this. Delightful experiences are very often multisensory and multimodal, whether directly within the experience or by association with memories. We enjoy foods that have a pleasant texture in our mouth, scents that remind us of a spring hike through the woods, or a warm, fuzzy, squirmy, and ridiculously adorable puppy. We are more likely to feel an emotional response or connection to a multisensory experience. We also remember them for longer, recall them more clearly and easily, and are more likely to both desire and repeat the experience later.

Figure 1-17. A hardwood door feels solid and satisfying
The senses are also how we create bonds of trust and intimacy with other people, with brands, and with the products we use. There are millions of search results that offer advice about how to pass the touch barrier on a date, underscoring how important it is to building human relationships (see Figure 1-18).
Figure 1-18. Establishing physical contact has a dramatic impact to the intimacy within a relationship, and it might just get you to date #2
Both physical proximity and contact are a sign of trust; more frequent proximity and contact increase that trust. Results of a study on this topic revealed how even just a little bit went a long way in creating emotional bonds. Waitresses were instructed to lightly touch their patrons. “Surprisingly, the researchers found that the tipping rate of both male and female customers was significantly higher in both of the touching conditions than in the baseline no-touch condition (a phenomenon that has been labeled the “Midas touch” effect).”14
This crosses over into products as well. People are more likely to purchase items in a store if they can touch them and to feel a stronger affinity for brands with which they have had a physical interaction. For many, seeing and touching something “makes it real.” We may have rational ideas and powerful emotions, but we validate them with physical evidence. It’s only through our senses that people, places, and things become a part of our world and our lives. Touch, especially, is a two-way street. When we touch, we feel our own fingers as much as we feel the object we are touching. We can feel how cold our own hands are in the warm grasp of our friend. Touch is vital—not only because it affirms the emotional connection to others, but also of others to us. In his famous experiments with baby rhesus monkeys, Harry Harlow demonstrated that baby monkeys preferred a cloth-covered surrogate mother without food to a wire and wood surrogate with food (see Figure 1-19). Without a comfortingly touchable surrogate, the baby monkeys suffered adverse health conditions. It became crystal clear that touch is vital to our well-being and, in various stages of our life, our very survival.15
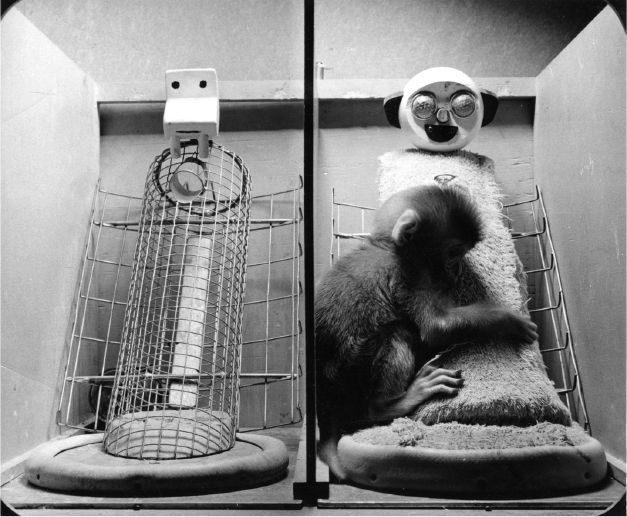
Figure 1-19. Baby monkeys preferred soft, cloth covered surrogate mothers to those with only wire and wood, even when the soft mothers offered no food
On the flip side, people feel a strange sense of discomfort and exposure when they cannot physically affirm presence. A study conducted in 2014 in the UK explored the deep emotional attachment and bond between people and their mobile devices. Participants showed extreme levels of distress and anxiety when a phone was nonfunctional, damaged, or lost. They felt protective over their devices. “Phones were considered an extension of self,” with an elevated desire to ensure the presence of the phone by touch or visual “checking.” The researchers found that the physical proximity and constant physical and visual contact with the phone increased both the emotional bond that their owners felt for it and their own sense of security and control for themselves.16 Though participants rationally valued the technology (the communication, information, and other conveniences that their smartphone provided), it was the physical affirmation of the device that made them feel secure—that the device was there and ready when needed.
According to Ralph Schiller, the CEO of ShotSpotters, the company’s technology had a strong effect on trust and the sense of personal security within the community:
Instead of a 10 or 20 percent response [based on citizen reporting], there is a 100 percent response to gunshots. The community feels that change. People begin to volunteer information; they become a part of their own safety. Their awareness changes the dynamics completely. They expect a response, and in turn it makes their police force more accountable to them. With both the community and the police force working together, it deters further gun violence, because bad actors expect a response. It denormalizes the violence. It sends the message that this isn’t supposed to happen here. This isn’t supposed to happen anywhere.
Press about the efforts also notes that greater trust between the communities and police “is leading to officers getting more on-the-ground information that supports the accumulation of the forensic data needed for prosecutions.” 17
The ability of devices to not only earn trust for themselves but enable other people to increase their trust of one another despite violent circumstances is a powerful testament to the kinds of outcomes that are possible.
Multimodal Design Is Cross-Disciplinary
While multimodal design seems to be unfolding in the new kinds of interfaces possible with technologies like natural language or emerging sensor-based interactions, it has always been a part of all design and tool use. The first cave painting required our creative ancestors to see the color applied to the cave wall, and to guide its application by touch. Product design accounts for both the visual and tactile experience of objects. In fashion design, the hand of the fabric is the way that a fabric feels overall—texture, weight, the way it drapes and folds, its rigidity—how stiff a tightly woven wool coat can feel compared to the airiness of silk gauze (see Figure 1-20). Designers have always had to intuit these underlying principles of multimodality in the objects that they create. With the advances in both cognitive neuroscience and behavioral psychology, we can see more clearly why it works.

Figure 1-20. The “hand” of a fabric is how it feels, and because our fingers and skin are so sensitive, clothing designers know that subtle details will not go unnoticed
As interaction blurs into existing design disciplines and spawns new hybrids—fashion technology, wearables, driverless cars, the connected home, and smart cities—blending multimodal experiences across interaction and existing physical design disciplines becomes increasingly important. We already have tactile relationships with the designed objects in our lives. Physical interactions that already exist can be incorporated into new delightful experiences. In the classic self-winding Rolex Oyster Perpetual watch, people shake their wrist to give the watch a few extra winds throughout the day to keep it running. In the Pebble watch, this gesture activated the backlight feature, bringing new meaning to an old habit.
Multimodal interactions can also improve the kinds of experiences that are already being delivered. We have automatic cognitive processes in our minds to read facial expressions and body language, and we notice how people stand, how they move when they speak. We read emotional cues in nonverbal communication. Being able to read each other’s emotional cues is an important survival skill for the social creatures that we are, so we are constantly seeking them out when we look at other people. We also read those human emotions into inanimate objects, in a phenomenon called anthropomorphism. In automotive design, the overall look of the car is called its stance: how people can infer aggressive, playful, or relaxed faces and body positions in the geometry of its shapes (see Figure 1-21). People find emotional cues in the “posture” of their car.

Figure 1-21. A car’s stance adds personality and fosters attachment
It is also why the brightening and dimming of the sleep light on a MacBook could be so evocative. It matched the rise and fall rhythm of a sleeper’s breath. It makes the state of sleep mode immediately recognizable. The computer isn’t turned off at all, and will “wake up” when opened. It’s why the shaking motion of a rejected password is endearing even though something went wrong. It looks a bit like a baby refusing a bite of food it doesn’t like. These product behaviors appeal to our rational understanding of what is happening, but tap into subtle body language cues that we already know. In cognitive neuroscience, mirror neurons are understood to fire both when we act or feel an emotion, and when we observe someone else performing the same act or feeling the same emotion. We may even have tense the same muscles. It’s possible that these emotive behaviors in products cause the same mirroring, eliciting empathy for our products. You get an unconscious sense that a computer needs sleep, recharge, and to let its processors cool down. This is actually good for the device, and more than just rationally understanding it, you feel it. You get a sense that bad passwords taste yucky for your computer, so you try to enter your password more carefully the next time. You feel responsibility for the well-being of the device, and treat it more carefully. And it is true—our devices need us to care for them, as much as we need them to function for us. Displaying it as if it were an emotional need—not just a pragmatic set of instructions in the user manual—changes the feeling and urgency dramatically.
These interactions don’t just show love for people, they ask for it in very charming ways. Along with everything else, our senses allow us to express and feel love. And people do love giving love as much as they love receiving it. We’re funny that way.
Summary
The senses are the (only) ways that we have of experiencing the world. Understanding how they work is key to designing new interfaces. They can also be extended by technology, with sensors that can go places, stay alert, and perceive things that we can’t. These design methodologies expand upon existing practices and introduce some new ones. Both the human capacity and device capability for multimodal combinations and activities is near limitless.
1 Gustavo Faleiros, “Looking Down on Deforestation: Brazil Sharpens Its Eyes in the Sky to Snag Illegal Rainforest Loggers,” Scientific American, April 12, 2011, https://www.scientificamerican.com/article/brazil-satellites-catch-illegal-rainforest-loggers/.
2 “Cape Town metro cops arrest 73 in crackdown,” Independent Online, August 15, 2016, http://www.iol.co.za/news/crime-courts/cape-town-metro-cops-arrest-73-in-crackdown-2057190.
3 “Cape Town fights crime with drones, acoustic technology, and smartphones,” My Broadband, January 25, 2017, https://mybroadband.co.za/news/security/195448-cape-town-fights-crime-with-drones-acoustic-technology-and-smartphones.html.
4 Peter Tyson, “Dogs’ Dazzling Sense of Smell,” Nova, October 4, 2012, http://www.pbs.org/wgbh/nova/nature/dogs-sense-of-smell.html.
5 David Eagleman, The Brain: The Story of You (New York: Pantheon Books, 2015, 41).
6 Kristin Koch, et al., “How Much the Eye Tells the Brain,” Current Biology 16, no. 14 (July 2006).
7 “80+ Startups Making Cities Smarter Across Traffic, Waste, Energy, Water Usage, and More,” CB Insights, January 24, 2017, https://www.cbinsights.com/research/iot-smart-cities-market-map-company-list.
8 Andrew Stelzer, “Is this crime-fighting technique invading your privacy?”, Newsworks, November 22, 2016, http://www.newsworks.org/index.php/local/the-pulse/98667-is-this-crime-fighting-technique-invading-your-privacy.
9 Barb Darrow, “Distracted Driving Is Now an Epidemic in the U.S.,” Fortune, September 14, 2016, http://fortune.com/2016/09/14/distracted-driving-epidemic/.
10 Dana Chisnell, “Beyond Task Completion: Flow in Design,” UX Magazine, October 7, 2011, https://uxmag.com/articles/beyond-task-completion-flow-in-design.
11 Mihaly Csikszentmihalyi. Flow: The Psychology of Optimal Experience (New York: Harper Perennial Modern Classics, 1990), 24.
12 Jordan Golson, “Mercedes Is Using Loud Static to Protect Fancy Ears in Crashes,” Wired, July 13, 2015, https://www.wired.com/2015/07/mercedes-using-loud-static-protect-fancy-ears-crashes/.
13 Jan Panero Benway. “Banner blindness: The irony of attention grabbing on the World Wide Web,” Proceedings of the Human Factors and Ergonomics Society 42nd Annual Meeting (October 1998): 463-467.
14 Alberto Gallace and Charles Spence, “In touch with the future: The sense of touch from cognitive neuroscience to virtual reality,” (Oxford: Oxford University Press, 2014), 165–166.
15 Harry F. Harlow, “The Nature of Love,” American Psychologist (1958): 673–685.
16 Gisli Thorsteinsson and Tom Page, “User attachment to smartphones and design guidelines,” International Journal of Mobile Learning and Organization 8 (2014): 201–205.
17 Bill Corcoran, “Sensors help police curb gang violence in Cape Town,” Irish Times, November 10, 2016, https://www.irishtimes.com/business/sensors-help-police-curb-gang-violence-in-cape-town-1.2854954.
Get Designing Across Senses now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

