March 2017
Intermediate to advanced
616 pages
19h 39m
English
Clearly, we must break away from the sequential and not limit the computers. We must state definitions and provide for priorities and descriptions of data. We must state relationships, not procedures.
Grace Murray Hopper, Management and the Computer of the Future (1962)
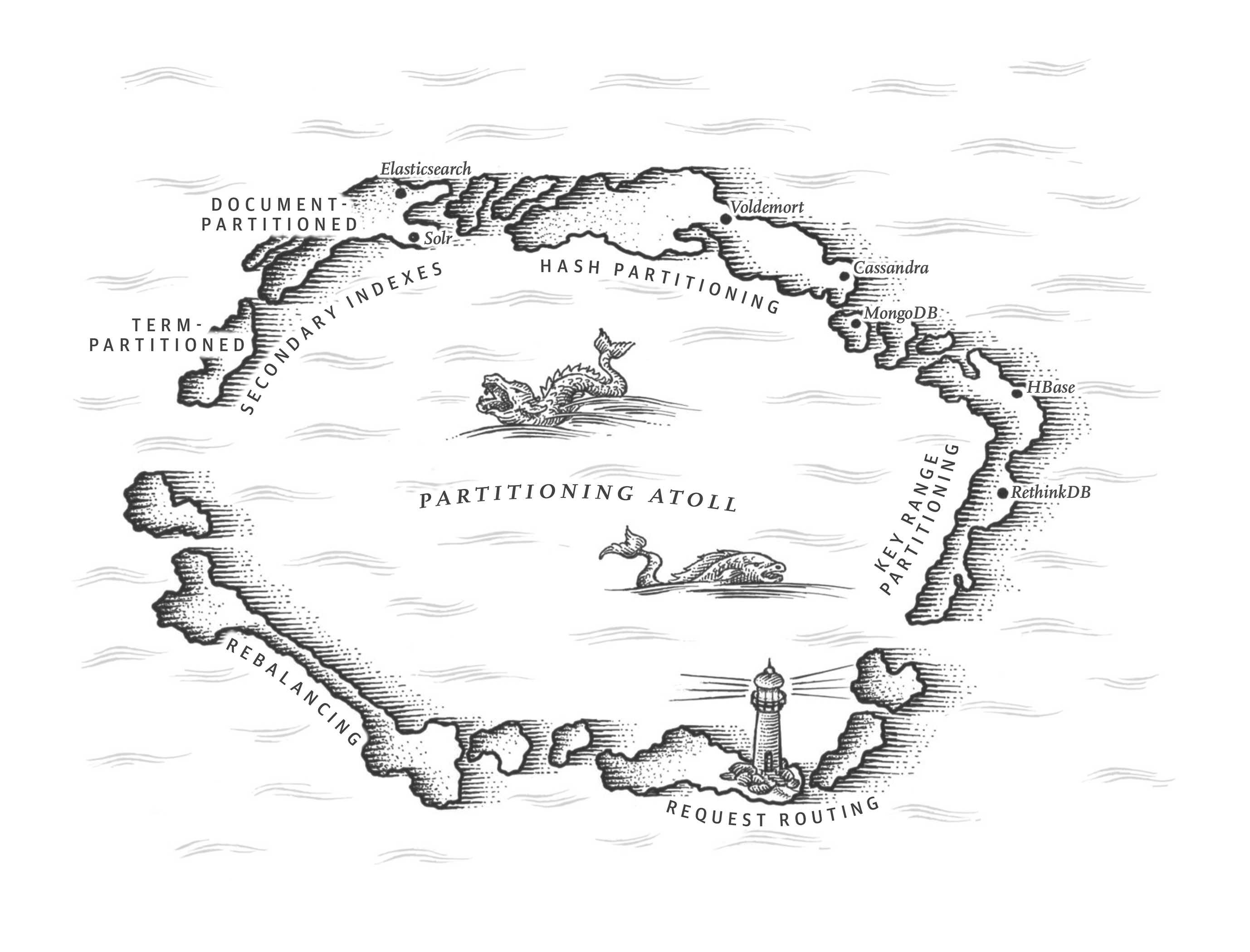
In Chapter 5 we discussed replication—that is, having multiple copies of the same data on different nodes. For very large datasets, or very high query throughput, that is not sufficient: we need to break the data up into partitions, also known as sharding.i
What we call a partition here is called a shard in MongoDB, Elasticsearch, and SolrCloud; it’s known as a region in HBase, a tablet in Bigtable, a vnode in Cassandra and Riak, and a vBucket in Couchbase. However, partitioning is the most established term, so we’ll stick with that.
Normally, partitions are defined in such a way that each piece of data (each record, row, or document) belongs to exactly one partition. There are various ways of achieving this, which we discuss in depth in this chapter. In effect, each partition is a small database of its own, although the database may support operations that touch multiple partitions at the same time.
The main reason for wanting to partition data is scalability. Different partitions can be placed on different nodes in a shared-nothing cluster (see the introduction ...
Read now
Unlock full access






