July 2014
Beginner to intermediate
336 pages
9h 30m
English
In this chapter we continue our examination of classification methods for data mining. One attractive classification method involves the construction of a decision tree, a collection of decision nodes, connected by branches, extending downward from the root node until terminating in leaf nodes. Beginning at the root node, which by convention is placed at the top of the decision tree diagram, attributes are tested at the decision nodes, with each possible outcome resulting in a branch. Each branch then leads either to another decision node or to a terminating leaf node. Figure 8.1 provides an example of a simple decision tree.
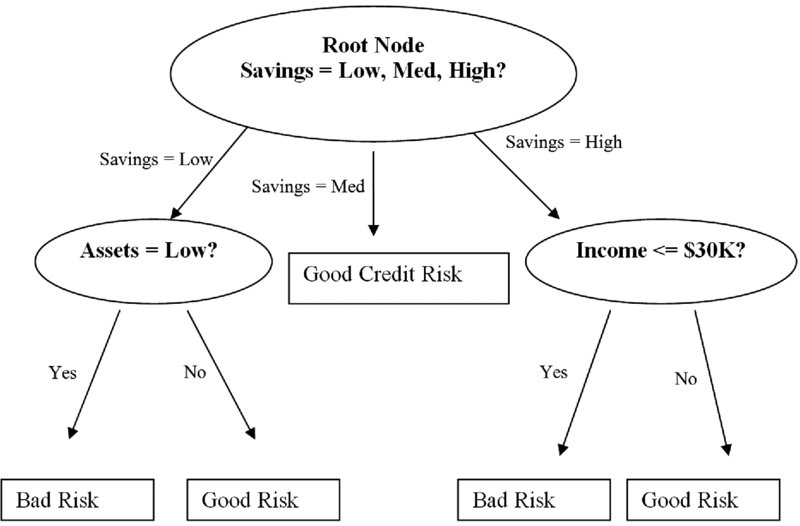
Figure 8.1 Simple decision tree.
The target variable for the decision tree in Figure 8.1 is credit risk, with potential customers being classified as either good or bad credit risks. The predictor variables are savings (low, medium, and high), assets (low or not low), and income (≤$50,000 or >$50,000). Here, the root node represents a decision node, testing whether each record has a low, medium, or high savings level (as defined by ...
Read now
Unlock full access






