Chapter 5. Cloudy with a Chance of Meatballs: When Clouds Meet Big Data
The Big Tease
As scientific and commercial supercomputing collide with public and private clouds, the ability to design and operate data centers full of computers is poorly understood by enterprises not used to handling 300 million anythings. The promise of a fully elastic and cost-effective computing plant is quite seductive, but Yahoo!, Google, and Facebook solved these problems on their own terms.
Traditional enterprises and agencies that are now facing pressure to compute on a global scale or even a more modest desire to improve the efficiency of their enterprise-scale physical plant will need to identify their own requirements for cloud computing and big data.
Conventional clouds are a form of platform engineering designed to address very specific financial, organizational and operational requirements. Private clouds are often designed by residents of silos who only value the requirements of their own silo. Clouds, like any platform, can be designed to meet a variety of requirements beyond the purely operational.
Everyone wants an elastic platform or cloud, but as discussed in Chapter 2, designing platforms at global scale always comes with trade-offs, and elasticity does not come for free. Big data analytics clouds must meet stringent performance and scalability expectations that require a very different form of cloud.
The idea of clouds “meeting” big data or big data “living in” clouds isn’t simply marketing hype. Because big data followed so closely on the trend of cloud computing, both customers and vendors still struggle to understand the differences from their enterprise-centric perspectives.
On the surface there are physical similarities in the two technologies—racks of conventional cloud servers and racks of Hadoop servers are constructed from the same physical components. But Hadoop transforms those servers into a single supercomputer, whereas conventional clouds host thousands of private mailboxes.
Conventional clouds consist of applications such as mailboxes and Windows desktops and web servers because single instances of those applications no longer saturate commodity servers. Cloud technology made it possible to stack enough mailboxes onto a commodity server so that it could achieve operational efficiency.
Since Hadoop easily saturates every piece of hardware it can get its hands on, Hadoop is a bad fit for being forced into a conventional cloud that is used to containing many idle applications. Although everyone who already has existing conventional clouds seems to think big data should just work in them effortlessly, it’s never that easy. Hadoop clouds must be designed to support supercomputers, not idle mailboxes.
A closer look reveals important differences between conventional clouds and big data; most significantly, they achieve scalability in very different ways, for very different reasons. Beyond the mechanisms of scalability that each exploits, the desire to put big data into clouds so it all operates as one fully elastic supercomputing platform overlooks the added complexity that results from this convergence. Complexity impedes scalability.
Scalability 101
Stated simply, the basic concept of scalability defines how well a platform handles a flood of new customers, more friends, or miles of new CCTV footage. Achieving scalability requires a deep understanding about what the platform is attempting to accomplish and how it does that. When a river of new data reaches flood stage, a platform scales if it can continue to handle the increased load quickly and cost-effectively.
Although the concept of scalability is easy to understand, the strategies and mechanisms used to achieve scalability for a given set of workloads is complex and controversial, often involving philosophical arguments about how to share things—data, resources, time, money—you know, the stuff that humans rarely share well.
How systems and processes scale isn’t merely a propeller-head computer science topic; scalability applies to barbershops, fast food restaurants, and vast swaths of the global economy. Any business that wants to grow understands why platforms need to scale; understanding how to make them scale is the nasty bit.
The most common notion of scalability comes from outside the data center, in economies of scale. Building cars, burgers, or googleplexes requires a means of production that can cost-effectively meet the growth in demand. In the 20th century, the US economy had an affluent population of consumers who comprised a market so large that if a company’s product developed a national following, it had to be produced at scale.
This tradition of scalable production traces back past Henry Ford, past the War of Independence, and into the ancestral home of the industrial revolution in Europe. During a minor tiff over a collection of colonies, the British Army felt the need to exercise some moral suasion. Their field rifles were serious pieces of engineering—nearly works of art. They were very high quality, both expensive to build and difficult to maintain in the field.
The US army didn’t have the engineering or financial resources to build rifles anywhere near that quality, but they knew how to build things simply, cheaply, and with sufficient quality—and these are the tenets of scalable manufacturing.
The only catch to simple, quick, and cheap is quality—not enough quality and the rifles aren’t reliable (will it fire after being dropped in a ditch?), and too much quality means higher costs, resulting in fewer weapons. The British had museum-quality rifles, but if that did not translate into more dead Americans, the quality was wasted and therefore not properly optimized. This is the first lesson of doing things at scale: too much quality impedes scale and too little results in a lousy body count.
Scalability isn’t just about doing things faster; it’s about enabling the growth of a business and being able to juggle the chainsaws of margins, quality, and cost. Pursuit of scalability comes with its own perverse form of disruptive possibilities.
Companies that create a great product or service can only build a franchise if things scale, but as their business grows, they often switch to designing for margins instead of market share. This is a great way to drive profit growth until the franchise is threatened.
Choosing margins over markets is a reasonable strategy in tertiary sectors that are mature and not subject to continuous disruption. However, computing technology will remain immature, innovative, and disruptive for some time. It is hard to imagine IT becoming as mature as bridge building, but the Golden Gate bridge was built by the lunatics of their time.
Companies that move too far down the margins path can rarely switch back to a market-driven path and eventually collapse under their own organizational weight. The collapse of a company is never fun for those involved, but like the collapse of old stars, the resultant supernova ejects talent out into the market to make possible the next wave of innovative businesses.
Motherboards and Apple Pie
Big data clusters achieve scalability based on pipelining and parallelism, the same assembly line principles found in fast food kitchens. The McDonald brothers applied the assembly line to burgers to both speed up production and reduce the cost of a single burger. Their assembly line consists of several burgers in various states of parallel assembly. In the computer world, this is called pipelining.
Pipelining also helps with efficiency by breaking the task of making burgers into a series of simpler steps. Simple steps require less skill; incremental staff could be paid less than British rifle makers (who would, of course, construct a perfect burger). More burgers plus faster plus less cost per burger equals scalability.
In CPU design, breaking down the circuitry pipeline that executes instructions allows that pipeline to run at higher speeds. Whether in a kitchen or a CPU, simple steps make it possible to either reduce the effort required (price) or increase the production (performance) of burgers or instructions.
Scalable systems require price and performance to be optimized (not just price and not just performance), all while trying to not let the bacteria seep into the meat left on the counter. Well, that’s the theory.
Once a kitchen is set up to efficiently make a series of burgers, then adding another burger assembly line with another grill and more staff to operate it will double the output of the kitchen. It is important to get the first assembly line as efficient as possible when it’s the example for thousands of new restaurants.
Back inside the CPU, it made economic sense for designers to build multiple floating-point functional units because most of the scientific code that was being run by their customers was saturating the CPU with these instructions. Adding another floating point “grill” made the program run twice as fast and customers gladly paid for it.
Scientific and commercial supercomputing clusters are mostly about parallelism with a little bit of pipelining on the side. These clusters consist of hundreds of “grills” all cooking the data in parallel, and this produces extraordinary scalability. Each cluster node performs exactly the same task (which is more complicated than applying mustard and ketchup), but the cluster contains hundreds of identically configured computers all running exactly the same job on their private slices of data.
Being and Nothingness
Big data cluster software like Hadoop breaks up the analysis of a single, massive dataset into hundreds of identical steps (pipelining) and then runs hundreds of copies at once (parallelism). Unlike what happens in a conventional cloud, Hadoop is not trying to cook hundreds of burgers; it’s trying to cook one massive burger. The ability to mince the problem and then charbroil it all together is where the genius lies in commodity supercomputing.
System designers use the term “shared-nothing” to indicate the process of hundreds of nodes working away on the problem while trying not to bother other nodes. Shared-nothing nodes try hard not to share anything. In practice, they do a little sharing, but only enough to propagate the illusion of a single, monolithic supercomputer.
On the other hand, shared-everything data architectures emphasize the value gained by having all nodes see a common set of data. Software and hardware mechanisms are required to ensure the single view remains correct or coherent but these mechanisms reduce isolation. The need to ensure a single, shared view is traded for scalability.
There is a class of workloads that does benefit from a single shared view, but in the world of big data, massive scalability is the last thing to be traded away, so shared nothing it is.
When doubled in size, a shared-nothing cluster that scales perfectly operates twice as fast or the job completes in half the time. A shared-nothing cluster never scales perfectly, but getting a cluster to 80% faster when doubled is still considered good scaling.
Several platform and workload engineering optimization strategies could be used to further increase the efficiency of a cluster from 80% to 90%. A cluster that scales better remains smaller, which also improves its operational efficiency as well.
Hadoop has already been demonstrated to scale to very high node counts (thousands of nodes). But since a 500-node cluster generates more throughput than a 450-node cluster, whether it is 8% faster instead of 11% isn’t as important as Hadoop’s ability to scale beyond thousands of nodes. Very few data processing platforms can achieve that, let alone do it affordably.
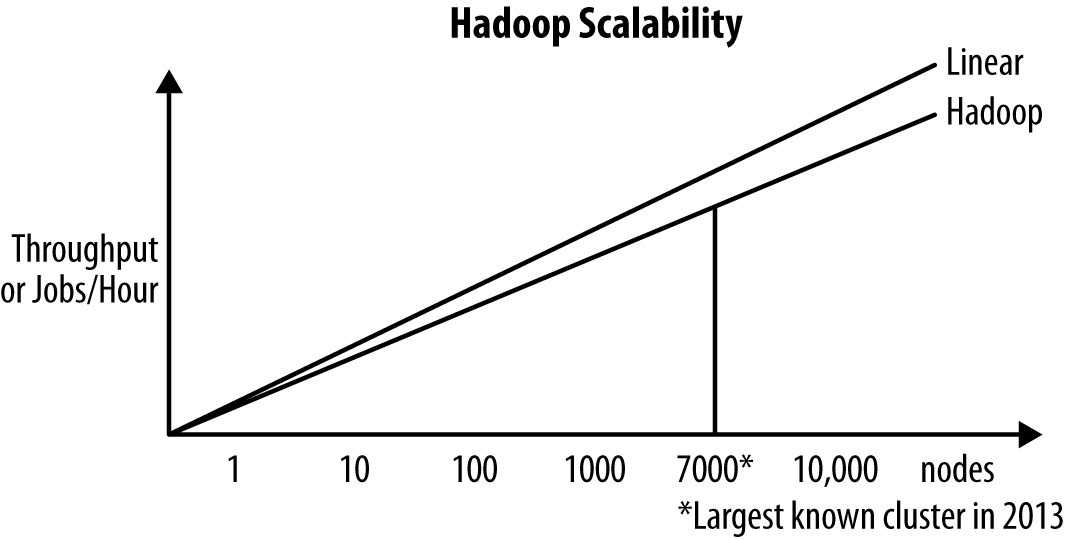
Parity Is for Farmers
Hadoop has done for commercial supercomputing what had already been accomplished in scientific supercomputing in the 1990s. Monolithic HPC supercomputers have been around since the 1960s when Seymour Cray designed the Control Data 6600, which is considered one of the first successful supercomputers. He must have worked as a short-order cook in a previous lifetime since his design innovations resemble those from a fast food kitchen.
What made the 6600 fast was the pipelining of tasks within the CPU. The steps were broken down to make them easier and cheaper to design and build. After Cray had finished pipelining the CPU circuits, he turned to parallelism by adding extra burger grills designed specifically to increase the number of mathematical or floating-point results that could be calculated in a second.
After Cray left CDC, he took his design one step further in the Cray-1 by noticing that solving hundreds of equations generated thousands of identical instructions (add two floating numbers, divide by a third). The only difference between all these instructions was the values (or operands) used for each instruction. He decided to build a vector-functional unit that would perform 64 sets of calculations at once—burger’s up!
Pipelining and parallelism have been hallmarks of HPC systems like the Cray, but very few corporations could afford a Cray or an IBM mainframe. Decades later, microprocessors became both affordable and capable enough that if you could figure out how to lash a hundred of them together, you might have a shot at creating a poor man’s Cray. In the late 1980s, software technology was developed to break up large monolithic jobs designed to run on a Cray into a hundred smaller jobs.
It wasn’t long before some scheduling software skulking around a university campus in the dead of night was infesting a network of idle workstations. If a single workstation was about 1/50th the speed of a Cray, then you only needed 50 workstations to break even. Two hundred workstations were four times faster than the Cray and the price/performance was seriously good, especially since another department probably paid for those workstations.
Starting with early Beowulf clusters in the 1990s, HPC clusters were being constructed from piles of identically configured commodity servers (i.e., pipeline simplicity). Today in 2013, a 1000-node HPC cluster constructed from nodes that have 64 CPU cores and zillions of memory controllers can take on problems that could only be dreamed about in the 1990s.
Google in Reverse
Hadoop software applies the HPC cluster trick to a class of global-scale computing problems that are considered non-scientific. Hadoop is an evolution of HPC clusters for a class of non-scientific workloads that were plaguing companies with global-scale but non-scientific datasets.
Financial services and healthcare companies also had problems as large as the HPC crowd, but until Hadoop came along the only way to analyze their big data was with relational databases.
Hadoop evolved directly from commodity scientific supercomputing clusters developed in the 1990s. Hadoop consists of a parallel execution framework called Map/Reduce and Hadoop Distributed File System (HDFS). The file system and scheduling capabilities in Hadoop were primarily designed to operate on, and be tolerant of, unreliable commodity components.
A Hadoop cluster could be built on ten laptops pulled from a dumpster and it would work—not exactly at enterprise grade, but it would work.
Yahoo! couldn’t initially afford to build 1000-node clusters with anything other than the cheapest sub-components, which is the first rule of assembly lines anyway; always optimize the cost and effort of the steps in the pipeline. Hadoop was designed to operate on terabytes of data spread over thousands of flaky nodes with thousands of flaky drives.
Hadoop makes it possible to build large commercial supercomputing platforms that scale to thousands of nodes and, for the first time, scale affordably. A Hadoop cluster is a couple of orders of magnitude (hundreds of times) cheaper than platforms built on relational technology and, in most cases, the price/performance is several orders of magnitude (thousands of times) better.
What happened to the big-iron, expensive HPC business in the early 1990s will now happen to the existing analytics and data warehouse business. The scale and price/performance of Hadoop is significantly disrupting both the economics and nature of how business analytics is conducted.
Isolated Thunderstorms
Everybody understands the value gained from a high-resolution view of consumers’ shopping habits or the possibility of predicting where crimes are likely to take place. This value is realized by analyzing massive piles of data. Hadoop must find a needle, customer, or criminal in a large haystack and do it quickly.
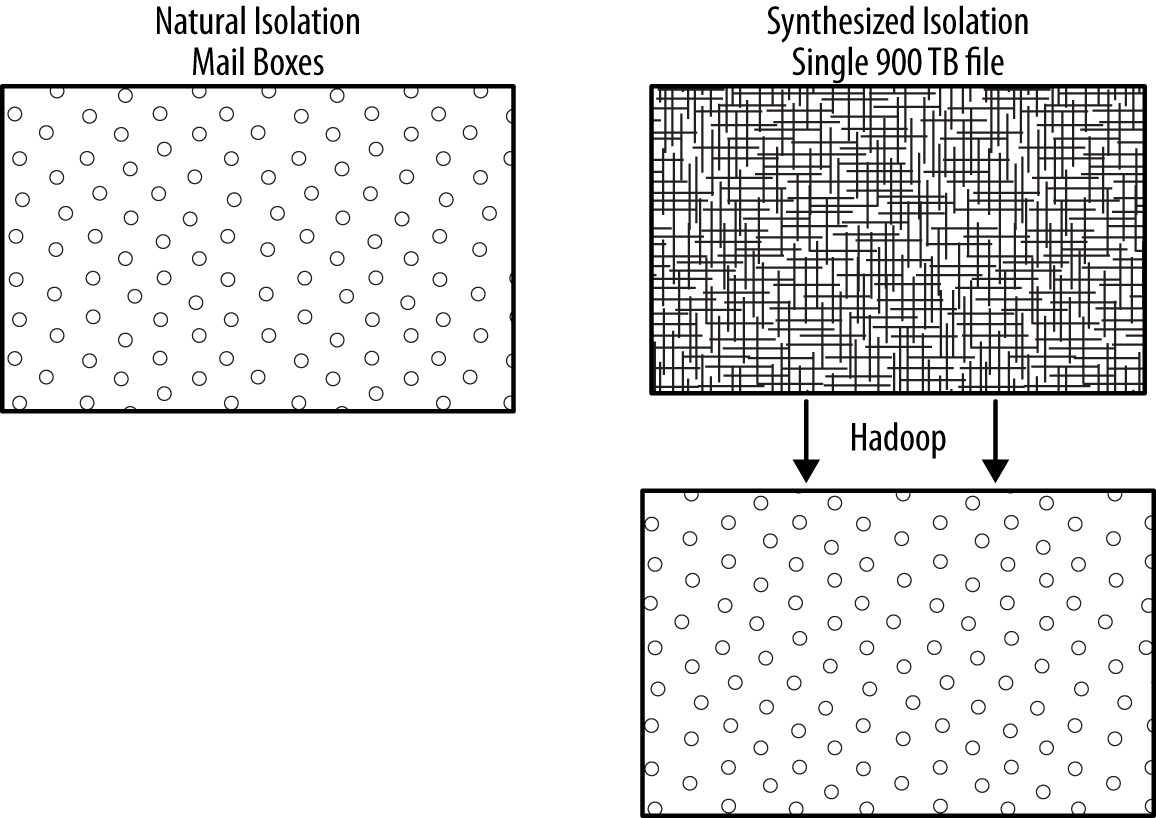
Hadoop breaks up one huge haystack into hundreds of small piles of hay. The act of isolating the haystacks into smaller piles creates a scalable, shared-nothing environment so that all the hundreds of piles are searched simultaneously.
Superficially, Hadoop seems to be related to conventional cloud computing because the first cloud implementations came from the same companies attempting global-scale computing. The isolation benefits that make any shared-nothing platform achieve scalability also make clouds scale. However, conventional clouds and Hadoop achieve isolation through very different mechanisms.
The Hadoop isolation mechanism breaks up a single pile of hay into hundreds of piles so each one of those nodes works on its own private pile. Hadoop creates synthesized isolation. But a cloud running a mail application that supports hundreds of millions of users already started out with hundreds of millions of mailboxes or little piles of hay.
Conventional clouds have natural isolation. The isolation mechanism results from the initial requirement that each email user is isolated from the others for privacy. Although Hadoop infrastructure looks very similar to the servers running all those mailboxes, Hadoop clusters remain one single, monolithic supercomputer disguised as a collection of cheap, commodity servers.
Private Cloud Myths
Many large enterprises in the 1990s had hundreds or thousands of PCs that needed care and feeding, which mostly meant installing, patching, and making backups. As the workforce became more mobile and laptops replaced desktops, employees’ computers and employers’ sensitive data became more difficult to protect. Early private clouds were set up to move everyone’s “My Documents” folder back into their data center so it could be better secured, backed up, and restored.
When personal computers began to have more computing power than the servers running the back-office accounting systems, most of the spare power went unused by those users who spent their days using MS Office. A single modern workstation in the early 2000s could support 8 or 10 users. This “bare-iron” workstation could be carved up into 10 virtual PCs using a hypervisor like VMware’s ESX or Red Hat’s KVM. Each user got about the same experience as having their own laptop gave them, but the company reduced costs.
Conventional clouds consist of thousands of virtual servers, and as long as nothing else is on your server beating the daylights out of it, you’re good to go. The problem with running Hadoop on clouds of virtualized servers is that it beats the crap out of bare-iron servers for a living. Hadoop achieves impressive scalability with shared-nothing isolation techniques, so Hadoop clusters hate to share hardware with anything else. Share no data and share no hardware—Hadoop is shared-nothing.
While saving money is a worthwhile pursuit, conventional cloud architecture is still a complicated exercise in scalable platform engineering. Most conventional clouds are not able to support Hadoop because they rely on each individual application to provide its own isolation.
Hadoop in a cloud means large, pseudo-monolithic supercomputer clusters lumbering around. Hadoop is not elastic like millions of mailboxes can be. It is a 1000-node supercomputer cluster that thinks (or maybe wishes) it is still a Cray. Conventional clouds designed for mailboxes can be elastic but will not elastically accommodate supercomputing clusters that, as a single unit of service, span 25 racks.
The Network Is the Backplane
Cloud computing evolved from grid computing, which evolved from client-server computing, and so on, back to the IBM Selectric, yet operating private clouds remains undiscovered country for most enterprises. Grids at this scale are not just plumbing; they are serious adventures in modern engineering. Enterprises mostly use clouds to consolidate their sprawling IT infrastructure and to reduce costs.
When groups attempt to implement any type of cloud—conventional or Hadoop, private or public—more likely than not, they use legacy practices that are not affordable at scale. Private clouds are often implemented with expensive tier 1 legacy infrastructure and practices.
It’s not that Hadoop can’t run in conventional clouds—it will run in a cloud built from a dumpster full of laptops, but it will not be very efficient. When Hadoop clouds are deployed with legacy practices and hardware, performance and scalability will be severely compromised by underpowered nodes connected to underpowered external arrays or any other users running guests on the physical servers that contain Hadoop data nodes. A single Hadoop node can easily consume physical servers, even those endowed with high disk I/O throughput.
Most conventional clouds share I/O and network resources based on assumptions that guests will never be as demanding as Hadoop data nodes are. Running Hadoop in a conventional cloud will melt down the array that is shared due to the way that most SANs are configured and connected to clouds in enterprises.
Conventional clouds that were designed, built, and optimized for web servers, email, app servers, and Windows desktops simply will not be able to withstand the resource intensity of Hadoop clusters.
Cloud computing and enterprise network topologies are designed for manageability and attachment. Hadoop uses the network topologies to interconnect all its data processing nodes in a way that throughput and efficiency are prioritized over attachment and manageability, so this often creates topological conflicts if Hadoop is running in conventional clouds.
If Hadoop must be imposed on a conventional cloud, it needs to be a cloud designed to run supercomputers, not a conventional cloud that has been remodeled, repurposed, and reshaped. Big data clouds must be designed for big data.
The Orientation of Clouds
Everyone assumes that Hadoop can work in conventional clouds as easily as it works on bare iron, but that’s only true if they’re willing to ignore the high cost and complexity to manage and triage Hadoop and its inability to scale when imposed in conventional clouds.
Conventional cloud infrastructure is neither architecturally nor economically optimal for running supercomputers like Hadoop. And Hadoop is already a proven, self-contained, highly resilient cloud in its own right.
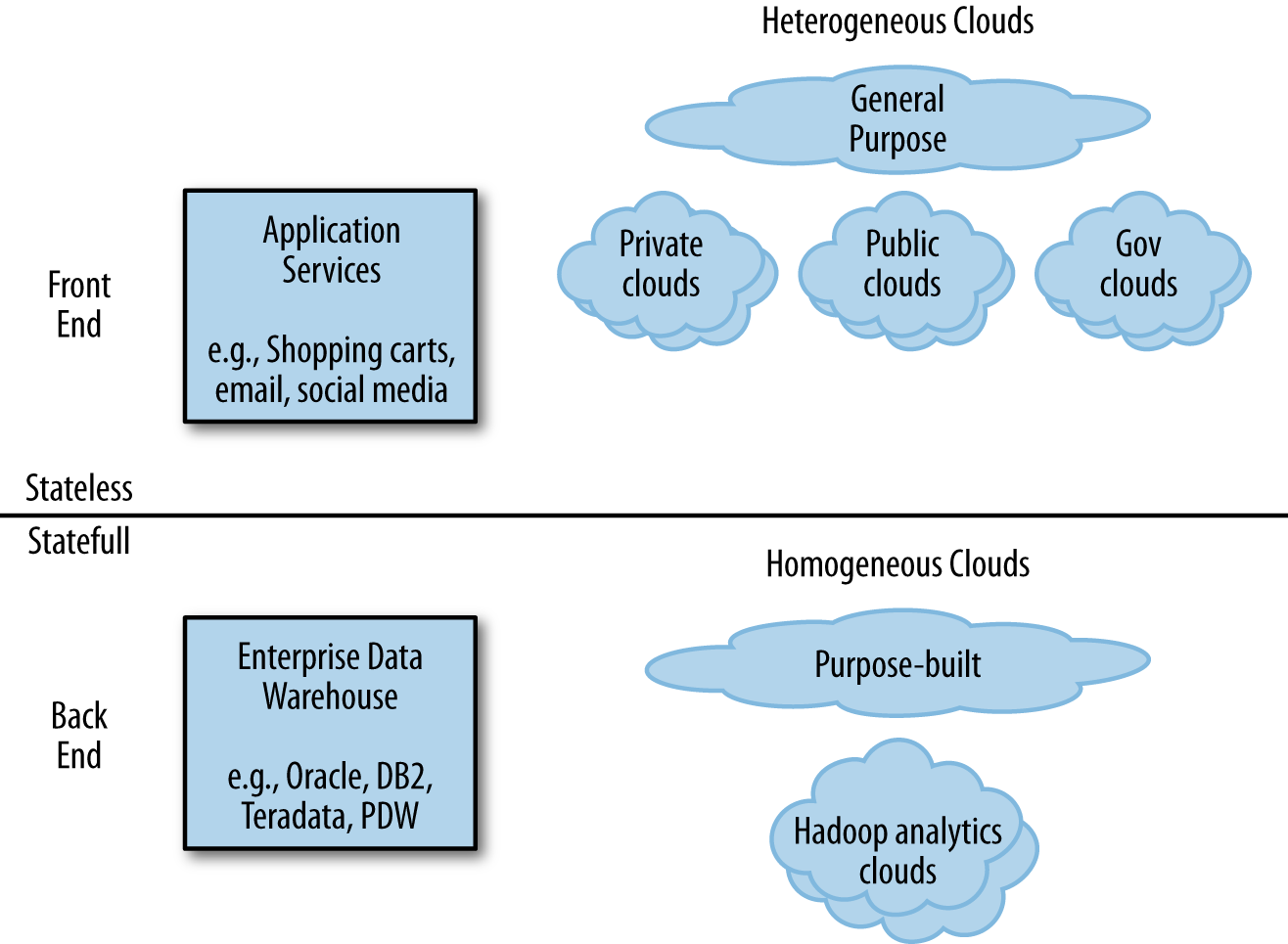
Because conventional clouds are designed for a class of applications that are not throughput-intensive, they consume few resources. These do-little clouds exploit the resource profile of many front-end applications such as ecommerce and web mail. As generations of hardware servers evolved to be more powerful, it became possible to stack several server instances of web mail onto a single physical chassis.
Commodity hardware has outstripped the combination of bottlenecks and lethargic think times that exist for most front-end applications. Since most applications deployed on refreshed hardware cannot benefit from improved hardware technology, stacking multiple versions of instances on a single hardware chassis better utilizes the refreshed hardware. The success of VMware is living proof that these applications exist in large numbers.
Conventional clouds deploy and manage applications at an OS-image level since clouds are designed to consolidate instances of applications running on very idle servers. These clouds support several variants of Windows and Linux and can restart the OS image (and sometimes the application itself) in the event of a failure. Typically, there might be 16 to 64 copies of Windows running on a single hardware chassis. If these images remain lethargic, then the world is good.
But if some of these applications start to consume resources such as memory, network or disk bandwidth, then the other 63 server instances will start to suffer. Conventional cloud provisioning systems can relocate these resource-intensive application images in order to minimize the disruption.
When a Hadoop cluster is imposed into a conventional cloud, many platform assertions quickly fail. The most important assertion is that Hadoop processing nodes are designed to completely saturate all the hardware resources at their disposal. Because Hadoop is designed to be a high-throughput supercomputer, processing nodes have very few bottlenecks.
If a Hadoop node is one of 64 OS images running on a chassis (even a chassis built for high performance with plenty of spindles and memory channels), then the other 63 images will be severely impacted. If a Hadoop cluster is deployed in a conventional cloud, then what appears to be a 100-node cluster might only be provisioned on 20 physical machines, and so it has the actual throughput of a 20-node cluster. A 100-node Hadoop cluster is not a collection of 100 standalone instances that can be relocated and restarted; it is one unified 100-node data processing instance.
The other assertion that wreaks havoc with running Hadoop in conventional clouds is that data is not elastic. When a Windows image fails, the private data that needs to be relocated is relatively small so it can be moved quickly. But a Hadoop data processing node typically reads hundreds of terabytes of private data during the course of a day. Provisioning or relocating a Hadoop data processing node involves terabytes of inelastic data.
Whatever cloud you pick, data is always inelastic and those terabytes always move at the speed of infrastructure bottlenecks. Even Hadoop can’t break the laws of physics, although HDFS does a better job of provisioning and relocating data across its own cloud because it is optimized for a different set of platform assertions.
Conventional clouds rely heavily on shared storage (such as the S3 file system on AWS or traditional NFS pods) which is not required to be high-performance; it’s more important that shared storage accommodates provisioning and relocation than throughput and scalability. I/O is not required for do-little clouds.
However, if Hadoop data processing nodes each expect to draw their private data throughput from shared storage, then many more shared storage pods for each Hadoop processing node will be required to meet the demand and then Hadoop strains the economics of the conventional cloud infrastructure. Hadoop is far less seamless and more resource invasive if it’s forced into a conventional cloud infrastructure.
Conventional clouds are just one way to provision and schedule computing resources for a specific, mostly low-throughput category of applications, but even conventional clouds are deployed on bare iron. This type of cloud converts thousands of servers into a flexible pool of computing resources that allow a broad, mostly heterogeneous collection of Windows and Linux servers to operate more efficiently. By this definition, conventional clouds are heterogeneous, general-purpose clouds.
Hadoop, however, when deployed across the same bare-iron servers, is a homogeneous, purpose-built, supercomputing analytics cloud. When viewed as an alternative deployment model of a cloud, Hadoop is a superior topology for an expanding family of Apache analytics applications.
A Hadoop analytics cloud differs in how it commissions and de-commissions individual data processing nodes. It cannot provision a copy of Windows or Linux, however, it can provision or relocate HBASE, HIVE, Accumulo, Stinger, MapReduce, Storm, Impala, Spark, Shark and an expanding ecosystem of Apache analytics.
The art to running any cloud on any hardware infrastructure is to make sure platform and workload assertions hold, or if they don’t, understand the implications of the trade-offs. Groups who are compelled to run Hadoop in conventional clouds must understand how the assertions differ between heterogeneous conventional clouds and homogeneous Hadoop analytics clouds and discover what types of analytics applications can work well within the constraints of a conventional cloud.
My Other Data Center Is an RV Park
Companies attempting to build conventional clouds or Hadoop analytics clouds that operate at global scale are discovering they also need to rethink everything they thought they knew about how to design, build, and run data centers.
The pioneering companies that initially purchased servers from vendors like IBM, HP, and Dell quickly realized that the value—and pricing—of those servers was driven by features they didn’t need (like graphics chips and RAID cards). The same features that might be useful for regular customers became completely irrelevant to companies that were going to sling 85,000 servers without ever running a stitch of Windows.
Hardware vendors were building general-purpose servers so that their products would appeal to the greatest number of customers. That’s a reasonable convention in product design, but like scientific computing users, commercial computing users do not require general-purpose servers to construct purpose-built supercomputing platforms.
After learning how to buy or build stripped-down servers, those companies quickly moved on to optimizing the entire notion of a data center, which is just as critical to the platform as the servers and software are. It was inevitable that the physical plant also had to be deconstructed and optimized.
Since absolutely everything must be optimized at global scale—including everything in the computing plant—data centers are being redesigned, resized, and relocated. Sometimes entire data centers can be deleted and replaced with a container full of servers that only needs power, water for cooling and a network drop. Today’s data centers can be found in a stack of intermodal containers like those on ocean freighters or located on empty lots or abandoned RV parks.
Converge Conventionally
Cloud computing evolved from the need to handle millions of free email users cheaply. Big data evolved from a need to solve an emerging set of supercomputing problems. Grids or clouds or whatever they will be called in the future are simply platforms of high efficiency and scale.
Although clouds are primarily about the operational aspects of a computing plant, learning how to operate a supercomputer is not like operating any traditional IT platform. Managing platforms at global scale is extremely disruptive to the enterprise’s notion of what it means to operate computers. And over time, the care and feeding of thousands of supercomputers will eventually lead us to change the way computers must operate.
Get Disruptive Possibilities: How Big Data Changes Everything now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

