March 2025
Intermediate to advanced
308 pages
7h 21m
French
Cet ouvrage a été traduit à l'aide de l'IA. Tes réactions et tes commentaires sont les bienvenus : translation-feedback@oreilly.com
Traditionnellement, les scientifiques des données utilisent Jupyter Notebook pour extraire des données de serveurs de bases de données ou d'ensembles de données externes (tels que des fichiers CSV, JSON, etc.) et les stocker dans des DataFrames pandas (voir figure 7-1).
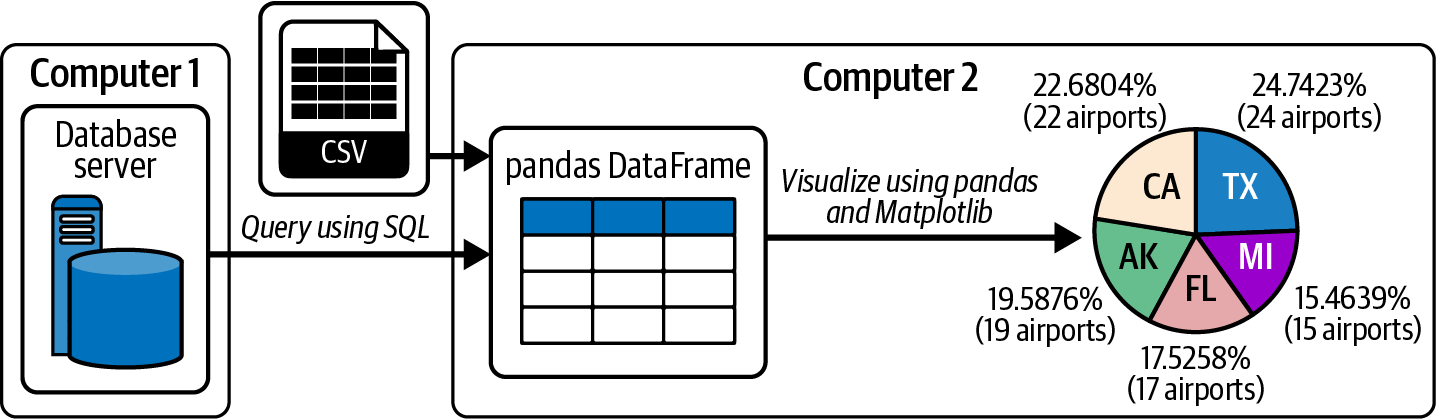
Ils utilisent ensuite les DataFrames à des fins de visualisation sur . Cette approche présente quelques inconvénients :
L'interrogation d'un serveur de base de données peut dégrader les performances du serveur de base de données, qui peut ne pas être optimisé pour les charges de travail analytiques.
Le chargement des données dans les DataFrames occupe des ressources précieuses, notamment la mémoire et le calcul. Par exemple, si l'intention est de visualiser certains aspects de l'ensemble de données, tu dois charger l'ensemble des données en mémoire avant de pouvoir effectuer une visualisation dessus.
Le traçage de visualisations à l'aide de Matplotlib utilise également une quantité importante de mémoire. Dans les coulisses, Matplotlib maintient en mémoire divers objets tels que des figures, ...
Read now
Unlock full access






