Application development can be a deceivingly complex undertaking.
Not only must our programs do their jobs, they must do them well. There’s a laundry list of characteristics that Good Software implies:
Secure
Sound/maintains integrity
Scalable
Interoperable
Robust/resilient
Correct/functions as specified
And while these are all prerequisites to a finished product, not a single one is specific to any business. Across the world, programmers slave over their terminals, spinning up custom solutions to the same fundamental issues facing everyone else.
Bluntly put, this is a waste.
For the sake of simplicity, we may categorize all code in a system into one of three flavors:
Core concerns
Cross-cutting concerns
Plumbing
The primary purpose of an application is to satisfy business logic, the set of rules that dictate its expected behavior. More simply, this is what a program does. For instance, an email client must be able to let its users read, compose, send, and organize email. All functions related to the fulfillment of business logic fall into the category of core concerns.
Object-oriented principles lend themselves well toward modeling business logic. Typically done via separation of concerns,[1] a related set of functionality may be compartmentalized in a module, with well-defined interfaces for how each component will interact outside of its internals (see Figure 1-1). In the case of our email client example, this might lead to separate modules for interacting with remote servers, rendering HTML, composing new mail, etc.
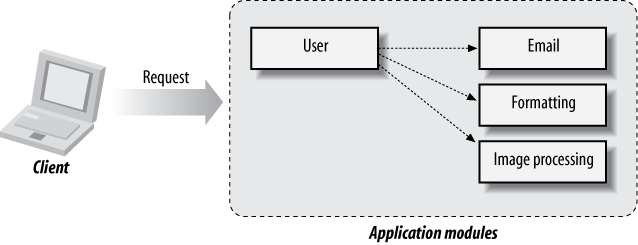
The core is typically going to contain rules unique to your application, and no one can build it aside from you and your team. Our job as software engineers is to realize ideas, so the more time we can dedicate to business logic, the more efficient we become. And the best way to limit our scope to core concerns is to reduce or eliminate the energy we spend everywhere else.
While the core of an application defines its primary function, there is a host of secondary operations necessary to keep things running correctly and efficiently. Security assertions, transactional boundaries, concurrency policies—all are helpful in ensuring the integrity of the system is in check. We define these as aspects.
The problem with aspects is that they’re intrinsically tangential to core concerns. In other words, cross-cutting concerns are intended to stretch across modules (Figure 1-2).
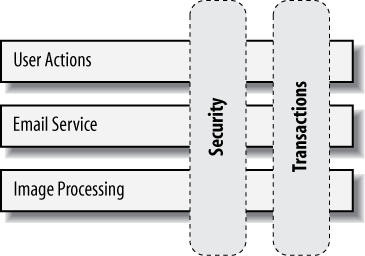
This layout paints a picture of perpendicular, or orthogonal, aims. For this reason, it takes great care to integrate aspects with the core in complementary fashion, as opposed to weighing it down.
While it may seem that aspects violate good practice to separate concerns, in fact they’re quite complementary in design. This is because they allow us to reuse shared code across modules, often transparently.
Banking software must allow users to withdraw money from their accounts, but it would make for an interesting solution if we could withdraw from any account we wanted; we need a security assertion at some point to ensure the requesting user has permission. If we hardcode this logic into the “withdraw” function, we’ve intermixed security with a core concern, and we’ll likely end up copying/pasting similar checks all over the place. A much better approach is to apply security as an common aspect to be shared by many modules and configure where it’s enforced separately.
This configuration ultimately regulates the direction of the invocation chain, but we don’t want to give it too much of our attention.
Once modules have been built to address the core, there’s still the matter of getting data and invocations from point A to point B. Plumbing provides this routing, and may take several forms:
Forwarding control from an HTTP request to some action handler
Obtaining a JDBC connection or JavaMail session
Mapping a nonnative request (JSON, ActionScript, RDBMS SQL) into a Java object
A sufficiently decoupled system defines interfaces for each module. This ensures that components may be developed in isolation, limits the need for explicit dependencies, and encourages parallel development. All good things.
And like all good things, there’s a cost: integration. Plumbing code is nothing more than an adapter between endpoints and provides few merits of its own (Figure 1-3).
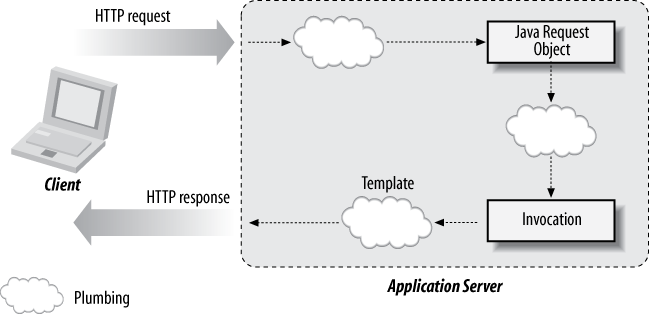
Perhaps the worst characteristic of the integration layer is that it is notoriously difficult to test. Although Unit Tests, pieces of code that perform assertions on isolated functions, are quite easy to write given a properly designed module, Integration Tests are much more expansive; they typically require a more involved setup of the test environment, and they may take orders of magnitude longer to invoke. This makes for both a process prone to developer laziness (tests may not be written!) and increased time in the build/test cycle.
Plumbing is a means to an end, and therefore of little value in and of itself. It will benefit us to take an approach that minimizes the time we spend getting data from one endpoint to another. As we’ll soon see, we may rely upon standards that remove this responsibility from our shoulders.
That’s a lot to consider before even a single line of code is written. Ironically, the solutions we concoct to address these issues are prone to becoming problems in themselves, and we’re at risk for introducing a tangled mess.
To state the obvious, the more that can be done for us, the less we have to do ourselves.
While it’s a likely requirement that business logic be unique to your application, the machinery that moves things along is not held to the same supposition. On the contrary, if aspects and plumbing are provided in a generic fashion, the developer is freed to limit both scope and focus to more tangible requirements.
Let’s say we want to register a new user with the system. Building everything in-house using traditional object-oriented methodology, we’d:
Check that we have permission to register someone new (Security)
Start a boundary so everything is ensured to complete together, without affecting anything else (Transactions)
Get a business worker delegate from some pool or cache, so we have control over concurrency (Performance and Transactional Isolation)
Make a hook into the database (Resource Management)
Store the user (Business Logic)
Get a hook to an SMTP (mail) server (Resource Management)
Email a confirmation (Business Logic)
Return our worker so another call may use it (Performance and Transactional Isolation)
Close our boundary (Transactions)
Even a simplified example shows that we’re “speaking like a computer.” All this talk about pools and boundaries and databases is undermining the utility of a programming language to help us express our ideas like humans. I’d much rather write:
pseudofunction registerUser(user)
{
database.storeUser(user);
mailService.emailUser(user);
}If we could make the computational elements transparent, we’d be in position to pay greater attention to the business logic.
Now that we’ve identified candidates to be culled from our source tree, we may introduce an abstraction that provides the necessary features in a decoupled fashion. A commonly employed technique is to take advantage of a construct called a Container. Loosely defined:
A Container is a host that provides services to guest applications.
The intent here is to provide generic services upon which applications may rely. The service support desired is usually defined by some combination of user code and metadata that together follow a contract for interaction between the application and container. In the case of Enterprise JavaBeans (EJB) 3.1, this contract is provided by a document jointly developed by experts under the authority of the Java Community Process (http://jcp.org). Its job is to do all the work you shouldn’t be doing.
Just as interfaces in code abstract the “what” from the “how,” the EJB Specification dictates the capabilities required of a compliant EJB Container. This 626-page document is the result of lessons learned in the field, requests by the community, and subsequent debate by the JSR-318 Expert Group (http://jcp.org/en/jsr/detail?id=318).
It is the purpose of this book to introduce concepts provided by the spec in a concise manner, alongside examples where appropriate.
Let’s dig in. The Specification defines itself (EJB 3.1 Specification, page 29):
The Enterprise JavaBeans architecture is a [sic] architecture for the development and deployment of component-based business applications. Applications written using the Enterprise JavaBeans architecture are scalable, transactional, and multi-user secure. These applications may be written once, and then deployed on any server platform that supports the Enterprise JavaBeans specification.
More simply rewritten:
Enterprise JavaBeans is a standard server-side component model for distributed business applications.
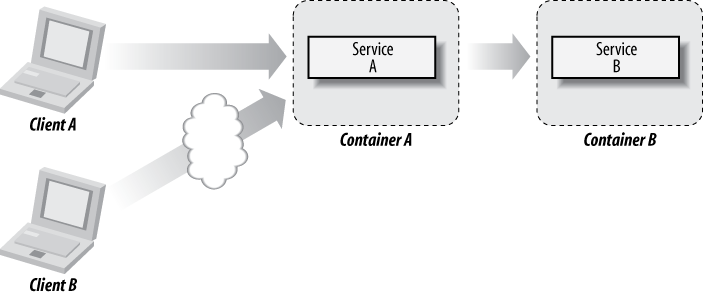
This means that EJB defines a model for piecing together a full system by integrating modules. Each component may represent a collection of business processes, and these will run centralized on the server (Figure 1-4).
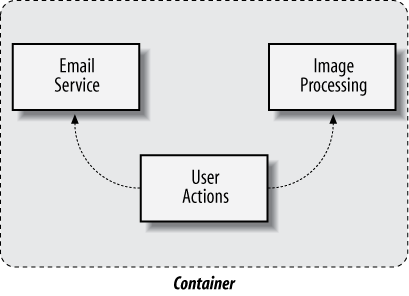
Additionally, the “distributed” nature will provide a mechanism to spread modules across different processes, physical machines, or even entire networks (Figure 1-5).
As we’ll soon discover, EJB is also an aggregate technology; it wires up other facets of the Java Enterprise Edition (http://java.sun.com/javaee/), such as messaging, transactions, resource management, persistence, and web services. It’s this integration that will reduce the evil plumbing we’d identified earlier.
Embracing the standard of EJB has other, nontechnical benefits. Applications that take advantage of EJB architecture are portable across any compliant Container implementation. In practice, there may be some retrofitting required in order to resolve vendor-specific features, but applications written to spec alone should stay true to the Sun Microsystems “write once, run anywhere” philosophy of the Java language.
Finally, the familiarity of EJB means that developers already oriented to the technology may spend less time learning the control flow of a particular application, making hiring and training a much more simplified exercise.
We’ve seen requirements common to many applications and how these can be met without recoding the same stuff the company across the street did last week. We’ve discussed the importance of keeping business logic uncluttered with cross-cutting concerns. And we’ve cringed at the unnecessary plumbing employed by the roll-your-own approach.
Most importantly, we’ve revealed the EJB Specification as a viable solution to:
Address common/generic issues within application development
Code less
Standardize
Integrate with other technologies under the umbrella of the Java Enterprise Edition
The specification offers a few different bean types, and the most sensible choice will depend upon the intended purpose.
[1] Edsger Dijkstra, “On the role of scientific thought” (1982). http://www.cs.utexas.edu/users/EWD/transcriptions/EWD04xx/EWD447.html
Get Enterprise JavaBeans 3.1, 6th Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

