This chapter will explore the use of XML as a means for providing the mediation between diverse data structures and formats as data is passed between applications. We will also examine how ESB-enabled data transformation and content-based routing services can support an XML data exchange architecture that insulates individual applications from wholesale changes in data structures.
XML, the eXtensible Markup Language, is accepted by the industry as the ideal vehicle for sharing structured data among applications and organizations. Putting aside for a moment the benefits of web services technologies such as SOAP and WSDL, there is much to be gained by simply adopting XML as the means for representing data that is shared between applications. XML has many benefits, including the following:
- XML is becoming universally understood.
XML has become a lingua franca for representing data and interfaces between applications. Many packaged-application vendors provide inputs and outputs in XML. Think about your own applications and how they could better integrate and share data if they accepted and emitted XML.
- XML provides a richer data model
The power of XML to represent data is one reason that it’s been adopted so broadly. XML lets you model hierarchies, lists, and complex types directly in the data structure. This is in contrast to an RDBMS, which requires table joins, special schema features, and mapping routines to achieve the same thing.
- XML makes data self-describing
XML embeds metadata that describes the hierarchy and data element names. This is the basis for XML parser technology that can use the tags and associated schema to identify elements of data by name and datatype.
- XML is dynamic
An XML document is loosely coupled with its schema, unlike data structures in relational tables, which are hard-wired to their schemas. This means that programs that extract data directly from the XML structure using standard XML expressions such as XPath are independent of the schema and loosely coupled with the structure itself.
- XML eliminates fixed formats
The order in which the data elements appear in a document doesn’t need to be fixed. Each element can be of a variable length and can include a variable number of other fields.
When combined, these principles allow XML to encode the entire contents of a database—all its tables, columns, rows, and constraints—in a single XML file.
Well, some would say that is up for debate, but it is certainly more human-readable than some of its predecessors, such as EDI. XML is generally readable by many tools. You can view XML documents in Microsoft Explorer, and most developer tools have viewers or editors for XML. XML is also writable. XML is well suited for integration tools that can visually create and manage sophisticated data mappings.
Any well-formed XML document is parseable by a variety of standard parsers. This contrasts starkly with most other data representations, such as EDI, which required specialized parsers based upon the type of data being represented.
Consider the following EDI fragment:
LOC+147+0090305::5' MEA+WT++KGM:22500' LOC+9+NLRTM' LOC+11+SGSIN' RFF+BM+933' EQD+CN+ABCU2334536+2210+++5' NAD+CA+ABC:172:20'
This is not very self-describing. It is also very fixed. In this case, we at least have an EDI standard that defines “LOC” and “NAD” as having special meaning, and the “+” operator has special syntactic meaning to something that is parsing and interpreting the data. However, many implementations of EDI emitters and consumers vary in interpretation, and are prone to interoperability issues.
When not using an EDI link, it is more common to have proprietary data formats that can be as simple as a comma-separated list of data:
0090305, 22500. NLRTM, SGSIN, 933, ABC
Inevitably, this data needs to be shared with other applications. It may be obtainable through some application-level interfaces, or it may be accessible only through an ETL type of dump and load. If you have some kind of schema to help recognize and parse the data, some custom data translation can be applied to get the data into an appropriate form for another application’s consumption.
In contrast, data represented by XML is more readable and consumable. It is more easily read by humans, and easier to consume using parsing technology because it carries more context, or information about the nature of the content. Here is the XML equivalent of the previous EDI fragment:
<EDI_Message>
<Address>
<AddressType>Stowage location</AddressType>
<AddressLine>0090305</AddressLine>
<CodeList>ISO</CodeList>
</Address>
<Quantity>
<QuantityType>Weight</QuantityType>
<QuantityNumber>22500</QuantityNumber>
<QuantityUnits>KGM</QuantityUnits>
</Quantity>
<Address>
<AddressType>Loading port</AddressType>
<AddressLine>NLRTM</AddressLine>
<Codelist>UNLOCODE</Codelist>
</Address>
<Address>
<AddressType>Discharging port</AddressType>
<AddressLine>SGSIN</AddressLine>
<Codelist>UNLOCODE</Codelist>
</Address>
<Documentation>
<DocumentationType>Bill of Lading</DocumentationType>
<DocumentationNumber>933</DocumentationNumber>
</Documentation>
<Address>
<AddressType>Carrier</AddressType>
<AddressLine>ABC</AddressLine>
<CodeList>BIC</CodeList>
</Address>
</EDI_Message>As we will see in the next section, individual XML elements can be identified and consumed independently from the rest of the XML document.
An application and its external data representation can be extended without breaking the links between it and the other applications it shares data with. XML is extensible, in that portions of an existing XML document can be modified or enhanced without affecting other portions of the document. For example, additional data elements and attributes can be added to a portion of an XML document, and only the application that will be accessing that new element needs to be modified. Other applications that don’t require the extended data can continue to work without modification.
Let’s explore this point by examining a scenario. Say you need to increase the operational efficiency of a supply chain. In a supply chain that moves billions of dollars of goods per year, even a nominal increase in operational efficiency, such as reducing the time from order placement to delivery of goods to receipt of payment, can have an impact of millions of dollars in savings per year. Improving the time it takes to fulfill the actual order can be a significant factor in reducing the overall cycle time in the supply chain process. In this scenario, improving the order fulfillment time involves adding more details to the shipping address. With XML, we can extend data without adversely affecting all the producing and consuming applications that need to exchange that data.
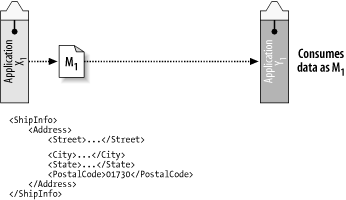
Consider the following XML fragment, which represents the body of message M1:
<ShipInfo >
<Address>
<Street>...</Street>
<City>...</City>
<State>...</State>
<PostalCode>...</PostalCode>
</Address>
</ShipInfo>XML is extensible in that a data element may have
attributes added to it, such as serviceLevel="overnight"
in the following listing:
<ShipInfo serviceLevel="overnight" >
<Address>
<Street>...</Street>
<City>...</City>
<State>...</State>
<PostalCode>...</PostalCode>
</Address>
</ShipInfo>This attribute is additional information, but for
applications that don’t know about serviceLevel, its
existence is unimportant. The structure didn’t
change, the values didn’t change, so it’s all
good.
Another simple thing we can do to decrease the overall time of the order fulfillment process is to upgrade the shipping address data to make use of nine-digit postal codes instead of just the five-digit prefix. (The U.S. postal code routing system requires that a minimum five-digit postal code be used. An optional four-digit predicate allows the postal delivery service to more efficiently route the package to its destination.)
A simple business requirement such as this can be the driver for why applications need to change to produce and consume the new data formats. In our postal code example, this requirement is driven by the consuming applications, such as the ones responsible for the logistical processing (e.g., printing the shipping labels).
To support the full nine-digit postal code, we
need to make changes to the data structures
themselves. The following listing shows message
M2 with an additional
Plus4 that
represents the optional additional four
digits:
<ShipInfoserviceLevel="overnight"> <Address> <Street>...</Street> <City>...</City> <State>...</State> <PostalCode>01730<Plus4>????</Plus4></PostalCode> </Address> </ShipInfo>
The process by which message
M1 becomes
M2 by adding the Plus4 element across all
applications can be done incrementally. This is
largely driven by the requirements of the
receiving applications that need to consume the
data with the enhanced format. In some cases, the
Plus4 element
may not be necessary. For example, the invoicing
application that generates the itemized invoice
containing the ShipTo address could do without the
Plus4
information. Eventually, it may be nice to have it
there for consistency’s sake, but the urgency to
upgrade that application is not as high as
extending the application that prints the physical
shipping label. XML thus reinforces the ESB
philosophy of “leave and layer,” allowing you to
selectively upgrade interfaces and data structures
as time permits.
To illustrate this point, let’s consider a simple example of two applications, X1 and Y1, which exchange message M1 (Figure 4-1).
Now let’s say that a new application, Y2, needs to consume the new data as represented by message M2, as illustrated in Figure 4-2.
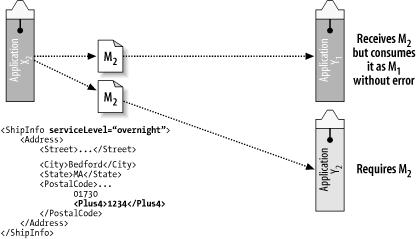
Assume that a new business requirement is
introduced where the receivers need to process the
extended data, message M2,
which includes the Plus4 element. The new application,
Y2, needs to process the
extended address data as represented by message
M2. The producing
application, X2, has been
upgraded to send the new datatype, but one of the
consuming applications can’t be upgraded until
there’s room in the budget. This is OK, provided
that the receiving application was written using
XPath, DOM, or SAX parsers to extract the
data.
If the application or the routing logic is using
XPath to examine the contents, it doesn’t matter
whether the message is structured as
M1 or
M2. The XPath expression to
access PostalCode is the same:
normalize-space(/ShipInfo/Address/PostalCode/text( )) 01730
But applications that know the extended structure of M2 can access the additional element:
normalize-space(/ShipInfo/Address/PostalCode/Plus4/text( ))
To access the full element as 01730-1234, the
following XPath expression can be used:
concat(normalize-space(/ShipInfo/Address/PostalCode/text( )),'-',
normalize-space(/ShipInfo/Address/PostalCode/Plus4/text( )))"The intrinsic extensibility of XML combined with best practices for extending an XML schema and for accessing the data in XML provides the ESB with a loosely coupled data model. This loosely coupled data model is a key aspect of the ESB, with significant benefits for development, deployment, and maintenance of the integration infrastructure.
Because of the extensibility of XML, producers and consumers of XML messages can be upgraded independently of one another to deal with the extended data structure. X1 can begin to send message M2 without any changes to either of the consumers; consumers Y1 and Y2 can be upgraded to process M2 independently of each other and of the producers. This scenario will work even if all the producers are not updated in tandem with the consumers.
Because XML parsing technology is largely
event-driven and data-driven, a receiving
application can be written such that the
additional information (in this case, Plus4) will be processed
only if the data in the XML message contains it.
This means that if an element is not present,
there is no error! Now, you might say that
building a system in which missing data is not an
error is bad design, and there is some truth to
that. But the ESB will help you handle these
business rules too.
There are cases in which incomplete data is
acceptable, and should not generate a fatal error.
The “business rules” surrounding the use of a
postal code is a good example. The use of the
Plus4 element
of a postal code means that efficiency and
expediency of delivery of the physical goods can
be improved. However, if the application that
receives message M can use only the five-digit
postal code, it’s not fatal to the application.
The package will still get to
its destination, just not as efficiently as it
would using the nine-digit postal code.
So far, we have been focusing on the generic benefits of using XML as the means for exchanging data between applications. The generic benefits of data-driven parsing technology and XPath expressions for pattern matching can provide a certain degree of loose coupling between applications, and allow for some improvements in data structures over time without forcing a simultaneous upgrade of all the applications concerned.
XML can provide a great deal of resilience to
changes in applications, as long as you’re just
adding data or enhancing structure, and not
actually changing the
structure. However, this can get you only so far.
What’s important to understand about the previous
example is that the PostalCode field still has its original
raw data, but now it also has additional element
field names that help to structure PostalCode data for use
separately. The structure changed—it got
richer—but the ability to access the PostalCode field remains
basically the same in both versions of the
message.
We can improve upon this by applying some basic ESB concepts: a business process definition, content-based routing, and data transformation. All of these concepts are inherently part of the ESB.
A business process definition represents a series of steps in a flow between applications. For example, a purchase order document might follow these basic, logical steps: credit check, inventory check, order fulfillment, and invoice (Figure 4-3).
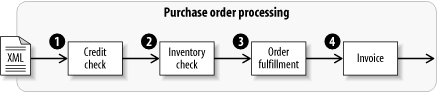
In the ESB, these steps may be mapped into service endpoints that represent physical applications. Using a business process definition, it is possible to administratively insert additional steps into that path of control flow, without modifying the applications directly.
What kinds of things might you insert into a
business process? In the PostalCode example, the components
would be specialized services that can alter the
path or otherwise affect the content of the
message. The path of execution, or the message
flow, between the producers and the consumers can
be augmented by adding a transformation service
into the business process.
Let’s assume that we have shut down Y1, and Y2 is the only version running (Figure 4-4). However, X1 (the original application) must remain online for another year, waiting for the allocation of money and time to upgrade it. There needs to be a strategy for keeping X1 working, and still satisfying the extended information needs of Y2. This can be accomplished by inserting a transformation step into the message flow between X1 and Y2.
Transformation is performed using a stylesheet language called XSLT (eXtensible Stylesheet Language Transformation). XSLT can restructure XML documents from one format to another, as well as transforming or enhancing the content. By applying an XSLT transformation, application X1 can still send document M1, as long as the transformation from M1 to M2 is done before the data arrives at Y2 (Figure 4-4).
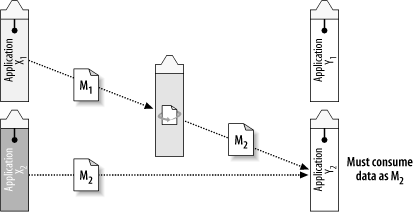
In the future, when X1 is upgraded to behave like X2, this transformation won’t be necessary.
For this XML transformation to work, it needs to
make an external call to a database lookup using
the street and city to obtain the extended
Plus4 element.
Advanced lookup capabilities using XQuery will be
explored in later chapters.
What we’ve seen so far is that by combining the extensibility of XML and the transformation power of XSLT processing services that are inherently built into the fabric of the ESB, we can provide resilience to change in more complex situations. While this approach has its merits, it doesn’t necessarily work well as the problem starts to scale up. The downside of this approach is that it requires direct knowledge of each point-to-point interaction between the various flavors of X and Y applications, and of when and where message M1 must be upgraded to M2. What happens when message type M3 is introduced?
This process can be further automated and generalized by introducing another ESB concept, Content-Based Routing (CBR). A CBR service can be plugged into the message flow between the producer X1 and the consumer Y1. This CBR service can be a lightweight process with the sole purpose of applying an XPath expression, such as the one used in our example, to determine whether the message conforms to the format of M1 or M2. If the message is of type M1, it can be routed automatically to another special service that fills in the missing pieces of data (Figure 4-5).
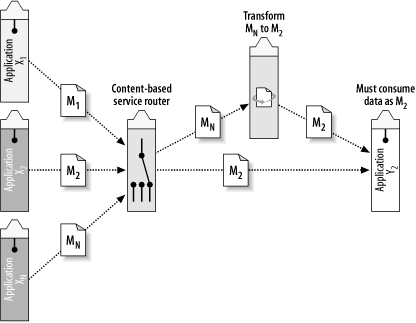
This transformation service can apply some simple rules to convert the five-digit postal code to a nine-digit format. The method by which this is done depends on the implementation of the service. It can be done simply by writing code to do a table lookup based on some values stored in a database, or implemented as an XSLT transformation that applies a stylesheet to produce the desired result. It can even make a call to an external web service using an outbound SOAP request. Structured integration patterns for performing Validate, Enrich, Transform, (Route,) and Operate (VETO, VETRO) will be explained in Chapter 11.
Inserting the routing and transformation into the process between the producers and consumers of the postal code gives us an advantage that we didn’t have with XML alone. Through a sequence of inspection, routing, and transformation combined with the use of XML documents, we can handle a wide array of complex integration tasks and add a great deal of resilience to changing data in the underlying applications. We can also think about these formats, routes, and transformations separately from the underlying applications.
The integration architect can use the ESB’s process management and XML processing facilities to improve the message data without ever modifying the sending applications. Using this model, only the consuming applications need to be modified to support the improvement in data. And as we have seen, not all the consumers need to be upgraded either. For the ones that do, the upgrade can happen independently of the data translation upgrades, allowing greater flexibility in the coordination of development timelines of the applications that are driving the requirement.
The simple example in the previous section is a one-directional map: it flows from left to right. If we want a general-purpose architecture for the exchange of information, data will need to flow in multiple directions. Figure 4-6 expands on our routing and transformation concept by replicating the process on both sides of the communication, allowing the multiple forms of data to flow in all directions.
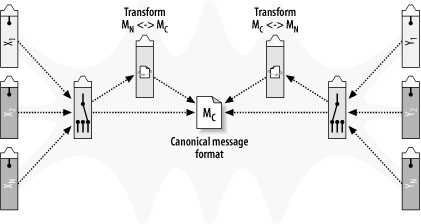
In the middle of this generic data exchange architecture is a canonical, application-independent version of the data. A best-practice strategy in integration is to decide on a set of canonical XML formats as the means for expressing data in messages as it flows through an enterprise across the ESB. Companies often use their already-established enterprise data models, or, alternatively, adopt industry-standard message formats as the basis for their own canonical representations. By doing so, companies standardize the definitions for common business entities such as addresses, purchase orders, and invoices.
The integration architect then works with the owner of each individual application to transform any application content into and out of this canonical format. By having an independent representation of the data, all application teams can work in parallel and without requiring advanced agreement between them. When extensions to the canonical format are required, they can simply be added as extra XML attributes and elements, relying on the inherent flexibility of XML.
As the applications change, the impact is limited to the transformation into and out of the canonical format. In addition to XML’s inherent flexibility, application owners have a great deal of freedom to enhance their applications and take advantage of new information within the canonical format.
There have been several attempts within the industry to provide a standardized representation of business data, and the results of these attempts have achieved various degrees of adoption. For example, in the heyday of electronic marketplaces, CommerceOne made popular the xCBL format, Ariba has promoted cbXML, and RosettaNet uses something called Partner Interface Processes (PiP). Some businesses have gone ahead and created their own proprietary XML formats. The level of “format” is at the business-object level; e.g., the definition of a purchase order or shipping address.
What this means to you, the integration architect, is that there are a number of XML dialects and overlapping conventions out there for representing business data in XML. Your business partners may have already standardized on one of these dialects, but you can probably safely assume that at least a few of your business partners haven’t standardized on XML at all just yet. Most of your business partners are probably limited to some kind of fixed format for exchanging data. For example, in financial services you have come to rely on FIX and SWIFT; in healthcare, you probably rely on HIPPA and HL7. Furthermore, the partners that have standardized on XML probably haven’t decided on the same dialect.
One scalable strategy that can be built upon is to use the routing and transformation technique that was explored previously and create a set of common XML formats for use in your ESB. These XML grammars become your company’s internal standard and comprise “MyCompanyML,” a markup language for data interchange within your company. Many organizations choose to build upon an existing standard, such as xCBL, rather than starting from scratch and inventing their own.
All applications that communicate through the bus can share data using these formats. Does this mean that all applications need to be modified to speak this new dialect immediately? No. The ESB can convert data flowing onto the bus or off the bus, depending on the formats supported by the specific applications that need to be integrated. The recommended approach that is being used today in many ESB integrations is to create transformation services that convert the data to and from the common XML format and the target data format of the application being plugged in, as illustrated in Figure 4-7.
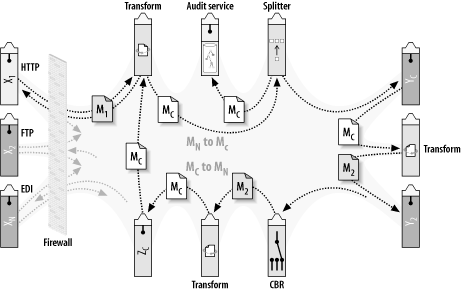
Figure 4-7. Transformation and routing can facilitate a generic data exchange with a canonical XML format as the native data type of the ESB
Figure 4-7 shows the series of steps that occur when a document flows through an enterprise using a canonical XML data exchange. The space in the middle between the applications and services is intentionally depicted as nebulous so that we can focus on the exchange concepts rather than the physical details of the underlying ESB. The details of what’s in that center—the core architecture of the ESB—will be addressed in the next three chapters.
The following are the processing steps illustrated in Figure 4-7, beginning from the top left in a clockwise direction. Each step is treated as an event-driven service that receives a message asynchronously using reliable messaging, and forwards the resulting message on to the next step after processing.
An external partner sends an XML or SOAP message over the HTTP protocol. Once inside the firewall, the message is assigned to a business process that controls the steps through the ESB.
The message (M1) is run through a transformation service. The transformation service converts the XML content from the data format used by the partner to the data format used as the canonical XML format. The resulting message (MC) is then forwarded onto a “splitter” service.
The splitter service has the sole purpose of making a copy of the message and routing it to an audit service. The audit service may add additional information to the message, such as contextual information about the business process and a timestamp of when the message arrived. The audit service itself could be implemented as a native XML persistence engine that allows the direct storage and retrieval of XML documents. This subject will be covered in Chapter 7.
The original message is forwarded on to application YC, which operates on the message; that is, it consumes the message and processes it. Conveniently, this particular application already knows how to consume messages in the canonical data format.
As part of the business process, the message now needs to be forwarded to application Y2, which understands only its own proprietary format. Therefore, before moving on Y2, the MC message is routed to a transformation service that converts it to M2, which is the target data format required by application Y2.
The transformation service sends the message M2 to the application Y2.
After being consumed and operated on by application Y2, the message now needs to get routed to another business process. This other business process can be invoked in a variety of ways from a number of different places within the bus. The process can’t ensure that the message is already in the canonical format. Therefore, it has a CBR service that examines its content and determines whether the message needs to be transformed.
In this case, the CBR service has identified the message as being in M2 format, and routes the message to a transformation service to get converted to MC format before getting delivered to application ZC.
Application ZC is responsible for generating an invoice and sending it asynchronously back to the partner.
Before doing this, however, the invoice needs to be converted into the format that the partner understands. Therefore, it is routed to another transformation service that converts it from message MC to message M1. In addition, this service constructs the SOAP envelope around the message (if required by that partner).
The invoice message is delivered to the partner asynchronously using the protocol that is appropriate for dealing with that partner.
The individual steps in the previous section could have been implemented in a number of different ways. Steps 2 and 3 could be combined; the transformation service in Step 2 could have done the splitting up of the message without a separate splitter service. An XSLT stylesheet can be written so that a “splitter” or “fan-out” operation can be performed while the data transformation is occurring. For example, a single XSLT stylesheet can perform a transformation that converts a purchase order from cXML to xCBL, and also splits off the line-item details into separate messages for the supply chain applications that need to process them.
The dual transformation from MC to M2 for processing by application Y2, and then back again into MC, could have been done another way under different circumstances. The format of M2 could have preserved the original message content in its MC format, and appended the translated content to the end. That way, when the message moved on to the next step, it would still have its original MC message content intact and would avoid the need for an additional translate step. However, this method doesn’t work in this particular case. Here, the Y2 application also needs to enrich the message with content that is required by the next application in the process.
The application ZC, which generates the invoice, could have simply generated it in the target M1 format that the partner expected. However, many partners have their own formats and protocols that they prefer to communicate with. ZC is a generic invoicing application that needs to know only the canonical XML format. Specialized transformation services that know how to convert the canonical invoice message MC to the specific targeted formats, such as EDI, PiP, or proprietary flat file format, can take on that responsibility separately. Even the management of the multiple partners and their protocols and formats can be separated into its own service.
At first glance, it may seem a bit exorbitant to require a transformation engine for each and every application that plugs into the ESB. However, in contrast with the point-to-point transformation solution, this method can reduce complexity over time, as the number of applications on the bus increases and as changes are introduced. When using specific point-to-point transformations between each application, the number of transformation instances increases exponentially with the number of applications. This is commonly referred to as the N-squared problem. With the canonical XML data exchange approach, the number of transformations increases much more linearly as new applications are brought into the integration.
Applying the canonical XML data exchange technique on a larger scale yields the following benefits:
Each application needs to focus on only one type of transformation to and from a common format. This illustrates an important philosophy of the bus that will be reinforced throughout the book. If you are the owner of an individual application, your only concern is that you plug into the bus, you post data to the bus, and you receive data from the bus. The bus is responsible for getting the data where it needs to go, in the target data formats that it needs to be in, and using the protocols, adapters, and transformations necessary to get there.
New applications being written to plug into the bus can use the canonical XML format directly. And multiple applications not anticipated today can tap into the flow of messages on the bus to create heretofore unimagined uses.
ESB services such as the CBR and the splitter can be written to use the canonical XML format. As we will see in Chapter 7, a service type can be written once and then customized on a per-instance basis by supplying different XSLT stylesheets, endpoint definitions, and routing rules. Having an agreed-upon format for common things such as address tags and purchase order numbers can be a tremendous advantage here.
Standard stylesheet templates and libraries can be created and reused throughout the organization.
Does it matter which XML dialect you choose for the native format of the ESB? That would depend on what the majority of the applications already speak. If much of your in-flight data is destined for a particular target format, and that target format is sufficient for generically representing all possible forms of your business data, go ahead and standardize on that XML format as the native datatype for the ESB. An example of such a format is xCBL. xCBL is a standard for describing things such as addresses, purchase orders, and so on, and was jointly developed by SAP and CommerceOne during the early days of dotcom and public exchanges. Like many other standards efforts, xCBL has not gone on to dominate the XML industry. However, because it was codeveloped by SAP, the message schema has a high degree of affinity to SAP’s IDOC elements and terminology.
The only basic recommendation here is that the format be XML. As you now know, many advantages can be realized when XML is the native datatype for in-flight documents within the ESB. And there are many more advantages of using XML as the native datatype, as will be discussed throughout this book.
In this chapter we saw that there are tremendous advantages to using XML as the means of representing data that is shared between applications. We have also learned the following:
XML allows applications to evolve more easily. It provides the flexibility to enhance data structures to handle the changes that businesses need to make. In doing so, XML allows you to upgrade your systems incrementally and continuously.
XML provides a richer data model than relational databases and includes standards-based transformation grammars such as XSLT and XQuery.
XML also supports best practices that enable resilient data access in evolving XML schema. This is accomplished through the proper use of XPath and XML data access APIs. It is expected that tools and methodologies will be developed that automate and validate these best practices.
XML alone won’t accommodate all the data exchange requirements of an enterprise that is dealing with legacy systems and partner interactions. With the help of intelligent content-based routing and targeted transformation services, ESB lays the groundwork for a generic data exchange architecture and the basis for more sophisticated business process management.
Get Enterprise Service Bus now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

