Even if you are using the QueryParser to build all your queries, you’ll
gain a better understanding of how searching works in Ferret by building
each of the queries by hand. We’ll also include the Ferret Query Language
(FQL) syntax for each different type of query as we go. As you read,
you’ll find some queries that you can’t build even using the QueryParser, so it will be useful to learn about
them as well.
Before we get started, we should mention that each Query has a boost field. Because you will
usually be combining queries with a BooleanQuery, it
can be useful to give some of those queries a higher weighting than the
other clauses in the BooleanQuery. All Query objects also implement hash and eql?, so they can be used in a HashTable to cache query results.
TermQuery is the most basic of all queries and is actually the building
block for most of the other queries (even where you wouldn’t expect it,
like in WildcardQuery and
FuzzyQuery). It is very simple to use. All you need
to do is specify the field you want to search in and the term you want
to search for:
# FQL: "title:shawshank"query=TermQuery.new(:title,"shawshank")
BooleanQueries are used to combine other queries. Combined with TermQuery, they cover most of the queries
users use every day on the major search engines. We already saw an
example of a BooleanQuery earlier, but we didn’t
explain how it works. A BooleanQuery is implemented
as a list of BooleanClauses.
Each clause has a type: :should,
:must, or :must_not. :should clauses add value to the relevance
score when they are found, but the query won’t reject a document just
because the clause isn’t present. This is the type of clause you would
find in an “or” query. A :must
clause, on the other hand, must be present in a
document for that document to be returned as a hit. Finally, a :must_not clause causes the
BooleanQuery to reject all documents that contain
that clause. For example, say we want to find all documents that contain
the word “rails”, but we don’t want the documents about trains, and we’d
especially like the “rails” documents that all contain the term “ruby”.
We’d implement this query like this:
# FQL: "content:(+rails -train ruby)"query=BooleanQuery.new()query.add_query(TermQuery.new(:content,"rails"),:must)query.add_query(TermQuery.new(:content,"train"),:must_not)query.add_query(TermQuery.new(:content,"ruby"),:should)
One rule to remember when creating
BooleanQueries is that every BooleanQuery must include at least one
:must or :should parameter. A BooleanQuery with only :must_not clauses will not raise any
exceptions, but it also won’t return any results. If you want to find
all documents without a certain attribute, you should add a
MatchAllQuery to your
BooleanQuery. Let’s say you want to find all
documents without the word “spam”:
# FQL: "* -content:spam"query=BooleanQuery.new()query.add_query(MatchAllQuery.new,:should)query.add_query(TermQuery.new(:content,"spam"),:must_not)
Once you add PhraseQuery to your bag of tricks, you can build pretty much any query that
most users would apply in their daily search engine usage. You build
queries by adding one term at a time with a position increment. For
example, let’s say that we want to search for the phrase “quick brown
fox”. We’d build the query like this:
# FQL: 'content:"quick brown fox"'query=PhraseQuery.new(:content)query.add_term("quick",1)query.add_term("brown",1)query.add_term("fox",1)
Ferret’s PhraseQueries offer a little more than
usual phrase queries. You can actually skip positions in the phrase. For
example, let’s say we don’t care what color the fox is; we just want a
“quick <> fox”. We can implement this query like this:
# FQL: 'content:"quick <> fox"'query=PhraseQuery.new(:content)query.add_term("quick",1)query.add_term("fox",2)
What if we want a “red”, “brown”, or “pink” fox that is either “fast” or “quick”? We can actually add multiple terms to a position at a time:
# FQL: 'content:"quick|fast red|brown|pink fox"'query=PhraseQuery.new(:content)query.add_term(["quick","fast"],1)query.add_term(["red","brown","pink"],1)query.add_term("fox",1)
So far, we’ve been strict with the order and positions of the terms. But Ferret also allows sloppy phrases. That means the phrase doesn’t need to be exact; it just needs to be close enough. Let’s say you want to find all documents mentioning “red-faced politicians”. You’d also want all documents containing the phrase “red-faced Canadian politician” or even “the politician was red-faced”. This is where sloppy queries come in handy:
# FQL: 'content:"red-faced politician"~4'query=PhraseQuery.new(:content,4)# set the slop to 4query.add_term("red-faced",1)query.add_term("politician",1)# you can also change the slop like thisquery.slop=1
The key to understanding sloppy phrase queries is knowing how the slop is calculated. You can think of a phrase’s “slop” as its “edit distance”. It is the minimum number of steps that you need to move the terms from the original search phrase to get the phrase occurring in the document (see Figure 4-1).
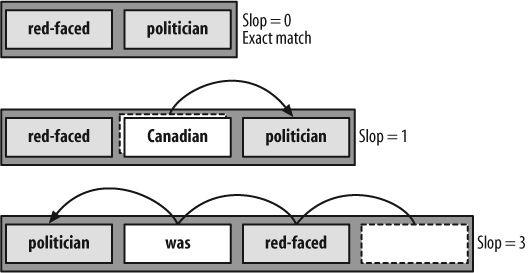
The first phrase is an exact match, so the slop is 0. In the next phrase you need to move “politician” right once, so the slop is 1. The third phrase shows that the terms don’t need to be in order. Just move “politician” left three times and you have a match. Hence, the slop is 3.
Now we are getting into some of the more specialized queries
available in Ferret. RangeQuery
does exactly what you would expect it to do: it searches for ranges of
values. Most of the time, RangeQueries are used on
date or number fields. Make sure you have these set up correctly as
described in the Date Fields” section in Chapter 2. For example, if you want to search for all blog
entries between June 1, 2005 and
March 15, 2006, you could build the query like this:
# FQL: 'date:[20050501 20060315]'query=RangeQuery.new(:date,:lower=>"20050501",:upper=>"20060315")
We don’t need to include both ends of the range. We could search for all entries before Christmas 2005:
# FQL: 'date:<20051225]'query=RangeQuery.new(:date,:upper=>"20051225")
Or all entries after Christmas 2005:
# FQL: 'date:[20051225>'query=RangeQuery.new(:date,:lower=>"20051225")
So, what happens to the blog entries from Christmas day in these
two examples? Both queries return blog entries from Christmas day
because these bounds are inclusive. That is, they include all terms
where :lower <= term <= :upper. We can easily make RangeQuery bounds exclusive. If we want
to make the first example exclusive, we write it like this:
# FQL: 'date:{20050501 20060315}'query=RangeQuery.new(:date,:lower_exclusive=>"20050501",:upper_exclusive=>"20060315")
This feature is useful for paging through documents by field value. Say we want to page through all the products in our database by price, starting with all products under $10, then all products between $10 and $20, etc., up to $100. We could do it like this:
10.timesdo|i|lower_price="%06.2f"%(i*10)upper_price="%06.2f"%((i+1)*10)query=RangeQuery.new(:price,:lower=>lower_price,:upper_exclusive=>upper_price)puts"products from $#{lower_price.to_f}to $#{upper_price.to_f}"index.search_each(query)do|doc_id,score|puts"#{index[doc_id][:title]}"endend
RangeQuery will work just as well on string
fields. Just keep in mind that the terms are always sorted as if they
were binary strings, so you may get some unexpected results if you are
sorting multibyte character encodings.
This is kind of like an optimized Boolean OR query. The optimization comes from the fact that it searches only a single field, making lookup a lot faster because all clauses use the same section of the index. As usual, it is very simple to use. Let’s say you want to find all documents with the term “fast” or a synonym for it:
# FQL: 'content:"fast|quick|rapid|speedy|swift"'query=MultiTermQuery.new(:content)query.add_term("quick")query.add_term("fast")query.add_term("speedy")query.add_term("swift")query.add_term("rapid")
But there’s more. What if you would prefer documents with the term “quick” and you don’t really like the term “speedy”? You can program it like this:
# FQL: 'content:"speedy^0.5|fast|rapid|swift|quick^10.0"'query=MultiTermQuery.new(:content)query.add_term("quick",10.0)query.add_term("fast")query.add_term("speedy",0.5)query.add_term("swift")query.add_term("rapid")
You may be wondering what use this is, since we can perform this
query (including the term weighting) with a
BooleanQuery. The reason it is included is that it is
used internally by a few of the more advanced queries that we’ll be
looking at in a moment: PrefixQuery,
WildcardQuery, and FuzzyQuery. In
Apache Lucene, these queries are rewritten as
BooleanQueries and they tend to be very
resource-expensive queries. But a BooleanQuery for
this task is overkill, and there are a few optimizations we can make
because we know all terms are in the same field and all clauses are
:should clauses. For this reason,
MultiTermQuery was created, making
WildcardQuery and FuzzyQuery much
more viable in Ferret.
When some of these queries are rewritten to
MultiTermQueries, there is a risk that they will add
too many terms to the query. Say someone comes along and submits the
WildcardQuery “?*”
(i.e., search for all terms). If you have a million terms in your index,
you could run into some memory overflow problems. To prevent this,
MultiTermQuery has a :max_terms limit that is set to 512 by default. You can set this to whatever value
you like. If you try to add too many terms, by default the lowest scored
terms will be dropped without any warnings. You can increase the
:max_terms like this:
query=MultiTermQuery.new(:content,:max_terms=>1024)
You also have the option of setting a minimum score. This is
another way to limit the number of terms added to the query. It is used
by FuzzyQuery, in which case the range of scores is
0..1.0. You shouldn’t use this
parameter in either PrefixQuery or
WildcardQuery. The only other time you would probably use this is when building a
custom query of your own:
query=MultiTermQuery.new(:content,:max_terms=>1024,:min_score=>0.5)
The PrefixQuery is useful if you want to store a hierarchy of categories in
the index as you might do for blog entries. You could store them using a
Unix filename-like string:
index<<{:category=>"/sport/"}index<<{:category=>"/sport/judo/"}index<<{:category=>"/sport/swimming/"}index<<{:category=>"/coding/"}index<<{:category=>"/coding/c/"}index<<{:category=>"/coding/c/ferret"}index<<{:category=>"/coding/lisp/"}index<<{:category=>"/coding/ruby/"}index<<{:category=>"/coding/ruby/ferret/"}index<<{:category=>"/coding/ruby/hpricot/"}index<<{:category=>"/coding/ruby/mongrel/"}
Note that the :category field
in this case should be untokenized. Now you can find all
entries relating to Ruby using a PrefixQuery:
# FQL: 'category:/coding/ruby/*'query=PrefixQuery.new(:category,"/coding/ruby/")
PrefixQuery is the first of the queries covered
here that use the MultiTermQuery. As we mentioned in the
previous section, MultiTermQuery has a maximum number
of terms that can be inserted. Let’s say you have 2,000 categories and
someone submits the prefix query with / as the prefix, the root category. Ferret
will try to load all 2,000 categories into the
MultiTermQuery, but MultiTermQuery
will only allow the first 512 and no more—all others will be ignored.
You can change this behavior when you create the PrefixQuery using the
:max_terms property:
# FQL: 'category:/*'query=PrefixQuery.new(:category,"/",:max_terms=>1024)
WildcardQuery allows you to run searches with two simple wildcards: * matches any number of characters (0..infinite), and ? matches a single character. If you look at
PrefixQuery’s FQL, you’ll notice that it looks like a
WildcardQuery. Actually, if you build a
WildcardQuery with only a single * at the end of the term and no ?, it will be rewritten internally, during
search, to a PrefixQuery. Add to
that, if you create a WildcardQuery with no
wildcards, it will be rewritten internally to a
TermQuery. The Wildcard API is pretty similar to
PrefixQuery:
# FQL: 'content:dav?d*'query=WildcardQuery.new(:content,"dav?d*")
Just like PrefixQuery,
WildcardQuery uses MultiTermQuery
internally, so you can also set the :max_terms property:
# FQL: 'content:f*'query=WildcardQuery.new(:content,"f*",:max_terms=>1024)
You should be very careful with
WildcardQueries. Any query that begins with
a wildcard character (*
or ?) will cause the searcher to
enumerate and scan the entire field’s term index. This can be quite a
performance hit for a very large index. You might want to reject any
WildcardQueries that don’t have a non-wildcard prefix.
There is one gotcha we should mention here. Say you want to select
all the documents that have a :price
field. You might first try:
# FQL: 'price:*'query=WildcardQuery.new(:price,"*")
This looks like it should work, right? The problem is, * matches even empty fields and actually gets
optimized into a MatchAllQuery. On the bright side,
the performance problems that plague WildcardQueries
that start with a wildcard character don’t actually apply to plain old * searches. So, back to the problem at hand,
we can find all documents with a :price field like this:
# FQL: 'price:?*'query=WildcardQuery.new(:price,"?*")
However, don’t forget about the performance implications of doing
this. Think about building a custom Filter to perform
this operation instead.
FuzzyQuery is to TermQuery what a sloppy
PhraseQuery is to an exact PhraseQuery.
FuzzyQueries match terms that are close to each other
but not exact. For example, “color” is very close to “colour”.
FuzzyQuery can be used to match both of these terms.
Not only that, but they are great for matching misspellings like
“collor” or “colro”. We can build the query like this:
# FQL: 'content:color~'query=FuzzyQuery.new(:content,"color")
Again, just like PrefixQuery,
FuzzyQuery uses MultiTermQuery
internally so you can also set the :max_terms
property:
# FQL: 'content:color~'query=FuzzyQuery.new(:content,"color",:max_terms=>1024)
FuzzyQuery is implemented using the Levenshtein
distance algorithm (http://en.wikipedia.org/wiki/Levenshtein_distance).
The Levenshtein distance is similar to slop. It is the number of edits needed to
convert one term to another. So “color” and “colour” have a Levenshtein
distance score of 1.0 because a single letter has been added. “Colour”
and “coller” have a Levenshtein distance score of 2.0 because two
letters have been replaced. A match is determined by calculating the
score for a match. This is calculated with the following formula, where
target is the term we want to match and
term is the term we are matching in the
index.
Levenshtein distance score:
1 − distance / min(target.size, term.size)This means that an exact match will have a score of 1.0, whereas
terms with no corresponding letters will have a score of 0.0. Since
FuzzyQuery has a limit to the number of matching
terms it can use, the lowest scoring matches get discarded if the
FuzzyQuery becomes full.
Because of the way FuzzyQuery is implemented,
it needs to scan every single term in its field’s index to find all
valid similar terms in the dictionary. This can take a long time if you
have a large index. One way to prevent any performance problems is to
set a minimum prefix length. Do this by setting the :min_prefix_len parameter
when creating the FuzzyQuery. This parameter is set
to 0 by default; hence, the fact that it would need to scan every term
in index.
To minimize the expense of finding matching terms, we could set the minimum prefix length of the example query to 3. This would greatly reduce the number of terms that need to be enumerated, and “color” would still match “colour”, although “cloor” would no longer match:
# FQL: 'content:color~' => no way to set :min_prefix_length in FQLquery=FuzzyQuery.new(:content,"color",:max_terms=>1024,:min_prefix_length=>3)
You can also set a cut-off score for matching terms by setting
the :min_similarity parameter. This will not affect how many
terms are enumerated, but it will affect how many terms are added to the
internal MultiTermQuery, which
can also help improve performance:
# FQL: 'content:color~0.8' => no way to set :min_prefix_length in FQLquery=FuzzyQuery.new(:content,"color",:max_terms=>1024,:min_similarity=>0.8,:min_prefix_length=>3)
In some cases, you may want to change the default values for
:min_prefix_len
and :min_similarity, particularly for
use in the Ferret QueryParser. Simply set the class
variables in FuzzyQuery:
FuzzyQuery.default_min_similarity=0.8FuzzyQuery.default_prefix_length=3
This query matches all documents in the index. The only time
you’d really want to use this is in combination with a negative clause
in a BooleanQuery or in combination with a filter,
although ConstantScoreQuery makes more sense for the
latter:
# FQL: '* -content:spam'query=BooleanQuery.new()query.add_query(MatchAllQuery.new,:should)query.add_query(TermQuery.new(:content,"spam"),:must_not)
This query is kind of like MatchAllQuery
except that it is combined with a Filter. This is useful when you
need to apply more than one filter to a query. It is also used
internally by RangeQuery. “Constant Score” means that
all hits returned by this query have the same score, which makes sense
for queries like RangeQueries where either a document
is in the range or it isn’t:
# FQL: 'date:[20050501 20060315]'filter=RangeFilter.new(:date,:lower=>"20050501",:upper=>"20060315")query=ConstantScoreQuery.new(filter)
So, what is the difference between this query and the previous one? Not a lot, really. The following two queries are equivalent:
# FQL: 'date:[20050501 20060315] && content:ruby'query1=FilteredQuery.new(TermQuery.new(:content,"ruby"),RangeFilter.new(:date,:lower=>"20050501",:upper=>"20060315"))# FQL: 'date:[20050501 20060315] && content:ruby'filter=RangeFilter.new(:date,:lower=>"20050501",:upper=>"20060315")query2=BooleanQuery.new()query2.add_query(TermQuery.new(:content,"ruby"),:must)query2.add_query(ConstantScoreQuery.new(filter),:must)
It’s really just a matter of taste. There is a slight performance
advantage to using a FilteredQuery, although the
QueryParser will create a
BooleanQuery.
Span queries are a little different from the queries we’ve
covered so far in that they take into account the range of the terms
matched. In the PhraseQuery” section earlier in this
chapter, we talked about using PhraseQuery to
implement a simple Boolean AND query that ensured
that the terms were close together. Span queries are designed to do that
and more.
A couple of things to note here. First, span queries can contain
only other span queries, although they can be combined with other
queries using a BooleanQuery.
Second, any one span query can contain only a single field. Even when
you are using SpanOrQuery, you must ensure that all
span queries added are on the same field; otherwise, an ArgumentError will be raised.
The SpanTermQuery is the basic building block for span queries. It’s almost
identical to the basic TermQuery. The difference is
that it enumerates the positions of its matches. These positions are used by the
rest of the span queries:
includeFerret::Search::Spans# FQL: There is no Ferret Query Language for SpanQueries yetquery=SpanTermQuery.new(:content,"ferret")
Because of the position enumeration,
SpanTermQuery will be slower than a plain
TermQuery, so it should be used only in combination
with other span queries.
This is where span queries start to get interesting.
SpanFirstQuery matches terms within a limited
distance from the start of the field, the distance being a parameter
to the constructor. This type of query can be useful because often the
terms occurring at the start of a document are the most important
terms in a document. To find all documents with “ferret” within the
first 100 terms of the :content
field, we do this:
includeFerret::Search::Spans# FQL: There is no Ferret Query Language for SpanQueries yetquery=SpanTermQuery.new(:content,"ferret")
This query is pretty easy to understand. It is just like a
BooleanQuery that does only :should clauses. With this query we can find
all documents with the term “rails” in the first 100 terms of the
:content field and the term
“ferret” anywhere:
# FQL: There is no Ferret Query Language for SpanQueries yetspan_term_query=SpanTermQuery.new(:content,"rails")span_first_query=SpanFirstQuery.new(span_term_query,100)span_term_query=SpanTermQuery.new(:content,"ferret")query=SpanOrQuery.new()query.add(span_term_query)query.add(span_first_query)
Let’s reiterate here that all span queries you add to
SpanOrQuery must be on the same field.
This query can be used to exclude span queries. This gives us
the ability to exclude documents based on span queries, as you would
do with a :must_not clause in a
BooleanQuery. Let’s exclude all documents matched
by the previous query that contain the terms “otter” or
“train”:
# FQL: There is no Ferret Query Language for SpanQueries yetspan_term_query=SpanTermQuery.new(:content,"rails")span_first_query=SpanFirstQuery.new(span_term_query,100)inclusive_query=SpanOrQuery.new()inclusive_query.add(span_first_query)inclusive_query.add(SpanTermQuery.new(:content,"ferret"))exclusive_query=SpanOrQuery.new()exclusive_query.add(SpanTermQuery.new(:content,"otter"))exclusive_query.add(SpanTermQuery.new(:content,"train"))query=SpanNotQuery.new(inclusive_query,exclusive_query)
This is the one you’ve been waiting for, the king of all span queries. This allows you to specify a range for all the queries it contains. For example, if we set the range to equal 100, all span queries within this query must have matches within 100 terms of each other or the document won’t be a match. Let’s simply search for all documents with the terms “ferret”, “ruby”, and “rails” within a 50 term range:
# FQL: There is no Ferret Query Language for SpanQueries yetquery=SpanNearQuery.new(:slop=>50)query.add(SpanTermQuery.new(:content,"ferret"))query.add(SpanTermQuery.new(:content,"ruby"))query.add(SpanTermQuery.new(:content,"rails"))
Actually, we could have just done that with a sloppy PhraseQuery. But by combining
other span queries, we can do a lot of things that a sloppy PhraseQuery can’t handle. One other
thing that a sloppy PhraseQuery can’t do is force the terms
to be in correct order. With the SpanNearQuery, we
can force the terms to be in correct order:
# FQL: There is no Ferret Query Language for SpanQueries yetquery=SpanNearQuery.new(:slop=>50,:in_order=>true)#set in_order to truequery.add(SpanTermQuery.new(:content,"ferret"))query.add(SpanTermQuery.new(:content,"ruby"))query.add(SpanTermQuery.new(:content,"rails"))
This will match only documents that have the terms “ferret”, “ruby”, and “rails” within 50 terms of each other and in that particular order.
We mentioned at the start of this chapter that you can boost queries. This can be very handy when you want to make one term more important than your other search terms. For example, let’s say you want to search for all documents with the term “ferret” and the terms “ruby” or “rails”, but you’d much rather have documents with “rails” than just “ruby”. You’d implement the query like this:
# FQL: 'content:(+ferret rails^10.0 ruby^0.1))'query=BooleanQuery.new()term_query=TermQuery.new(:content,"ferret")query.add_query(term_query,:must)term_query=TermQuery.new(:content,"rails")term_query.boost=10.0query.add_query(term_query,:should)term_query=TermQuery.new(:content,"ruby")term_query.boost=0.1query.add_query(term_query,:should)
Unlike boosts used in Documents
and Fields, these boosts aren’t
translated to and from bytes so they don’t lose any of their precision.
As for deciding which values to use, it will still require a lot of
experimentation. Use the Search::Searcher#explain and Index::Index#explain methods to see how
different boost values affect
scoring.
Get Ferret now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

