June 2025
Beginner to intermediate
446 pages
10h 46m
English
Not so long ago, in 2012, data scientist was branded “the sexiest job of the 21st century” by the Harvard Business Review. Obviously, we can argue about the validity of this label more than a decade after it was proclaimed. However, the fact is that individuals “who can coax treasure out of messy, unstructured data” are still in high demand, and Microsoft Fabric doesn’t disappoint anyone who considers themselves a data scientist.
Before we dig deep into examining particular data science workloads in Microsoft Fabric, let’s first look at Figure 7-1 for an overview of the most common data science process stages from a high-level perspective. Please keep in mind that this process is not exclusively related to Microsoft Fabric—it’s more of a generic, tool-agnostic approach.
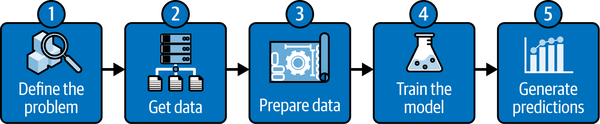
In this chapter, we’ll discuss four options that Microsoft Fabric provides to support data science workloads: MLflow, SynapseML, AutoML, and Semantic Link. These options include various ready-made solutions that can be seamlessly integrated with other Fabric experiences, as well as some unique features, such as Semantic Link, to support specific Fabric-related use cases.
Let’s start by introducing the process of creating machine learning experiments (which allow data scientists to log parameters, code versions, and output ...
Read now
Unlock full access






