Storm is a distributed, reliable, fault-tolerant system for processing streams of data. The work is delegated to different types of components that are each responsible for a simple specific processing task. The input stream of a Storm cluster is handled by a component called a spout. The spout passes the data to a component called a bolt, which transforms it in some way. A bolt either persists the data in some sort of storage, or passes it to some other bolt. You can imagine a Storm cluster as a chain of bolt components that each make some kind of transformation on the data exposed by the spout.
To illustrate this concept, here’s a simple example. Last night I was watching the news when the announcers started talking about politicians and their positions on various topics. They kept repeating different names, and I wondered if each name was mentioned an equal number of times, or if there was a bias in the number of mentions.
Imagine the subtitles of what the announcers were saying as your input stream of data. You could have a spout that reads this input from a file (or a socket, via HTTP, or some other method). As lines of text arrive, the spout hands them to a bolt that separates lines of text into words. This stream of words is passed to another bolt that compares each word to a predefined list of politician’s names. With each match, the second bolt increases a counter for that name in a database. Whenever you want to see the results, you just query that database, which is updated in real time as data arrives. The arrangement of all the components (spouts and bolts) and their connections is called a topology (see Figure 1-1).
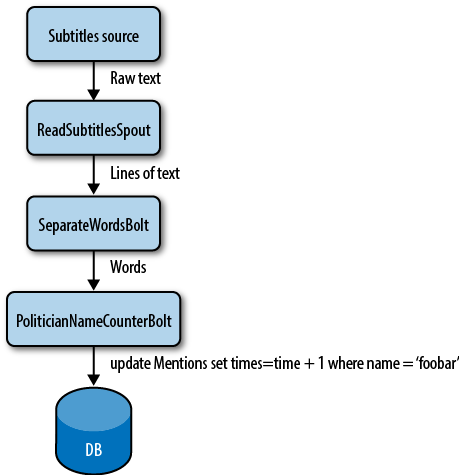
Now imagine easily defining the level of parallelism for each bolt and spout across the whole cluster so you can scale your topology indefinitely. Amazing, right? Although this is a simple example, you can see how powerful Storm can be.
What are some typical use cases for Storm?
- Processing streams
As demonstrated in the preceding example, unlike other stream processing systems, with Storm there’s no need for intermediate queues.
- Continuous computation
Send data to clients continuously so they can update and show results in real time, such as site metrics.
- Distributed remote procedure call
Easily parallelize CPU-intensive operations.
In a Storm cluster, nodes are organized into a master node that runs continuously.
There are two kind of nodes in a Storm cluster: master node and worker nodes. Master node run a daemon called Nimbus, which is responsible for distributing code around the cluster, assigning tasks to each worker node, and monitoring for failures. Worker nodes run a daemon called Supervisor, which executes a portion of a topology. A topology in Storm runs across many worker nodes on different machines.
Since Storm keeps all cluster states either in Zookeeper or on local disk, the daemons are stateless and can fail or restart without affecting the health of the system (see Figure 1-2).

Underneath, Storm makes use of zeromq (0mq, zeromq), an advanced, embeddable networking library that provides wonderful features that make Storm possible. Let’s list some characteristics of zeromq:
Socket library that acts as a concurrency framework
Faster than TCP, for clustered products and supercomputing
Carries messages across inproc, IPC, TCP, and multicast
Asynch I/O for scalable multicore message-passing apps
Connect N-to-N via fanout, pubsub, pipeline, request-reply
Tip
Storm uses only push/pull sockets.
Within all these design concepts and decisions, there are some really nice properties that make Storm unique.
- Simple to program
If you’ve ever tried doing real-time processing from scratch, you’ll understand how painful it can become. With Storm, complexity is dramatically reduced.
- Support for multiple programming languages
It’s easier to develop in a JVM-based language, but Storm supports any language as long as you use or implement a small intermediary library.
- Fault-tolerant
The Storm cluster takes care of workers going down, reassigning tasks when necessary.
- Scalable
All you need to do in order to scale is add more machines to the cluster. Storm will reassign tasks to new machines as they become available.
- Reliable
All messages are guaranteed to be processed at least once. If there are errors, messages might be processed more than once, but you’ll never lose any message.
- Fast
Speed was one of the key factors driving Storm’s design.
- Transactional
You can get exactly once messaging semantics for pretty much any computation.
Get Getting Started with Storm now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

