Chapter 1. Introduction
Welcome to this “Impatient Beginner’s Guide” to OpenShift. You have signed up for an account and now you are ready to create an application. Let’s move right to covering the minimum background information you will need so you can get to building things.
What Is the Difference Between IaaS, PaaS, and SaaS?
Let’s start by clearing up some “cloud computing” acronyms that people like to throw around.
Infrastructure as a Service (IaaS) is when a provider spins up computers for you on demand with certain predefined virtual hardware configurations. It is mainly targeted at system administrators and DevOps staff who used to rack and stack hardware. Probably the most famous of these services is Amazon EC2, but there is also Rackspace, Microsoft Azure, and Google Compute Engine, among others. The idea is that you specify the amount of RAM, CPU, and disk space you want in your “machine” and the provider spins it up for you in a matter of minutes.
This service is great since you no longer have to go through a long procurement process or fixed investment to obtain machines for your work. The drawback to this solution is that you are still responsible for installing and maintaining the operating system and server packages, configuring the network, and doing all the basic system administration. If you are reading this book, then system administration is probably not your area of expertise and you would likely rather spend your time writing code.
Software as a Service (SaaS) requires the least amount of maintenance and administration on your part. With SaaS you just sign up for the service and start using it. You may be able to make some customizations, but you’re limited to what the service provider allows you to do. Common examples of SaaS are Gmail, Salesforce, and QuickBooks Online. While these services are useful because you can start working right away with little to configure or deploy, they are of limited use to programmers. They offer the least amount of customization of the three cloud services mentioned here. As Steve’s kids’ physical education teacher says: “You get what you get and you don’t get upset.”
Platform as a Service (PaaS) is the middle ground between IaaS and SaaS. It is primarily targeted at application developers and programmers. With PaaS, you issue a few commands (which could be in a web console) and the platform spins up the development environment along with all the “server” pieces you need to run your application. For example, in this book we are going to make a Python web application with a PostgreSQL database. To get all this spun up, you issue one command and OpenShift does all the networking and server installs, and creates a Git repository for you. The OpenShift administrators will keep the operating system up-to-date, manage the network, and do all the sys admin work—leaving the developer to focus on writing code.
The Three Versions of OpenShift
OpenShift is Red Hat’s PaaS, and there are three different versions: OpenShift Origin, OpenShift Online, and OpenShift Enterprise (see Figure 1-1). OpenShift Origin, the free and open source version of OpenShift, is the upstream project for the other two versions. It is on GitHub and released under an Apache 2 license. All changes to the code base go through the public repository, for both Red Hat and external developers. If you want to use this version you will have to install it on your own infrastructure. We are not going to cover the installation of the OpenShift PaaS in this book.
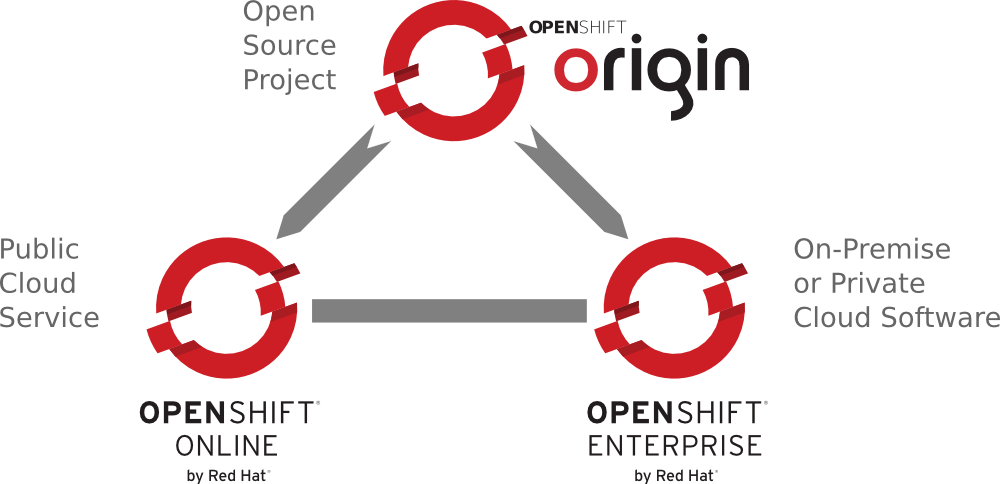
Approximately once every three weeks (the length of a sprint), Origin is packaged up and released as a new version of OpenShift Online. We are going to be using this version of OpenShift in the book. With Online, Red Hat takes care of hosting the PaaS on Amazon Web Services (AWS) and you just create an account for it. All the server work, such as updating the OS and managing networks, is covered by the OpenShift operations team. You are free to focus on your application and its code.
The final version is OpenShift Enterprise, which is currently released about once a quarter. This version of OpenShift allows you to take the PaaS and run it anywhere you want, from bare metal in your data center to Rackspace or AWS. It is a complete package with Red Hat Enterprise Linux and all the OpenShift bits on top of it. It is also fully supported by Red Hat and is intended for customers who want stability and a production-ready install out of the box. Since stability is paramount, some of the features found in Origin or Online may not be in Enterprise for a release or two. The great part about having Enterprise in-house is that it allows sys admins and DevOps staff to have control over “standard architecture” while still allowing developers to self-provision. Developers get all the speed and agility they want, without the usual wait for “machine” provisioning. It actually helps the sys admins and developers get along.
You can move applications between any of these versions of OpenShift, as long as the cartridges used are available on the versions between which you are migrating. This gives developers and companies a very nice hybrid cloud option. Developers and small teams can work on Online, perhaps using Online for some of the applications that allow for data in the public cloud. However, if they start developing an application that has more stringent data requirements, they can bring it back behind the company firewall, keeping the same development pattern they used for the Online platform. The Online version can also be used to try out a new technology, for example Node.js at a Java shop, with minimal risk and learning investment for the sys admins. Then, if the development team likes the new technology, they can demo the application to the decision makers and sys admins to show the value in bringing the technology in-house. The sys admins can use Red Hat’s expertise in configuring the new technology on OpenShift to provide it internally. Since they have it in-house and it is standard Node.js, they can then tweak and tune it in a way that allows for rapid deployment to all internal projects using the new technology.
Choosing the Right Solution for You
As always with these questions, the optimal solution depends on the specifics of your use case. Maybe the decision has already been made for you—for example, if you work at a corporation that has already chosen OpenShift Enterprise and that is what you will be using. If you want the fewest management concerns, then you should look to OpenShift Online. Everything will be managed by the OpenShift Operations team. The trade-off is that you have less control over how the system is set up, what cartridges are available, and how the network is configured.
If you want to be on the cutting edge of PaaS, you feel comfortable supporting yourself on Linux-based machines, and you want to provide your own “hardware,” then running OpenShift Origin with Fedora or CentOS could be an option. On the other hand, if you want a more stable and supported version of OpenShift running Red Hat Enterprise Linux, then you are going to be interested in OpenShift Enterprise.
Given the state of developers, corporations, and the cloud, some good use cases for Online are hackathons, prototype projects, consulting houses, startups, smaller divisions in larger corporations, and students. OpenShift Origin might be good for a corporation trialing the notion of running its own PaaS, a hosting provider, or a university that wants to set up student experimentation. Please be aware that, given the trajectory of PaaS, there will probably be large corporations using public PaaS instances for production workloads within a year of the publication of this book. Steve is willing to bet a beer or a lemonade on it.
With that brief introduction, we are done talking about broad concepts and will now move into the discussion of concepts particular to OpenShift and how to get started.
Things to Understand
We know you are impatient and want to get started, but it is important for us to get some definitions cleared up first. It is also important to introduce some technology that you’ll use throughout your development workflow. If you are comfortable with the technology feel free to skip right over that next section, but please make sure you understand the definitions.
Words You Need to Understand
There is some basic terminology that is specific to OpenShift or used specifically on the platform. It is important to clarify these terms since they will be used throughout the text:
- Application
- This is your typical web application that will run on OpenShift. At this time, OpenShift is focused on hosting web applications. With this in mind, and to try to provide some security for your applications, the only ports exposed to incoming traffic are HTTP (80), HTTPS (443), and SSH (22). OpenShift also provides beta WebSocket support on HTTP (8000) and HTTPS (8443).
- Gear
- A gear is a server container with a set of resources that allows users to run their applications. Your gears run on OpenShift in the cloud. There are currently three gear types on OpenShift Online: small, medium, and large. Each size provides 1 GB of disk space by default. The large gear has 2 GB of RAM, the medium gear has 1 GB of RAM, and the small gear has 512 MB of RAM.
- Cartridge
To get a gear to do anything, you need to add a cartridge. Cartridges are the plug-ins that house the framework or components that can be used to create and run an application. One or more cartridges run on each gear, and the same cartridge can run on many gears for clustering or scaling. There are two kinds of cartridges:
- Standalone
- These are the languages or application servers that are set up to serve your web content, such as JBoss, Tomcat, Python, or Node.js. Having one of these cartridges is sufficient to run an application.
- Embedded
- An embedded cartridge provides functionality to enhance your application, such as a database or Cron, but cannot be used on its own to create an application.
- Scalable application
- Application scaling enables your application to react to changes in traffic and automatically allocate the necessary resources to handle your increased demand. The OpenShift infrastructure monitors incoming web traffic and automatically brings up new gears with the appropriate web cartridge online to handle more requests. When traffic decreases, the platform retires the extra resources. There is a web page dedicated to explaining how scaling works on OpenShift.
- Client tools, Web Console, or Eclipse plug-ins
- You can interact with the OpenShift platform via RHC client command-line tools you install on your local machine, the OpenShift Web Console, or a plug-in you install in Eclipse to interact with your application in the OpenShift cloud. The only time you must use these tools is when you are managing the infrastructure or components of your application. For example, you would use these tools when creating an application or embedding a new cartridge. The rest of your work with your application will happen through Git and SSH, which we describe in the following section.
Technology You Need to Understand
There is also some basic technology you need to be able to use to effectively work with OpenShift as a developer. The rest of this book will assume you understand this technology at a basic level.
SSH
SSH is a tool you install on your local machine that allows you to log in to your OpenShift gears and have command-line access. With SSH, all interactions with the server are encrypted. OpenShift also uses SSH keys to authenticate your login for both command-line access and Git interactions. With the use of keys, you never have to type in a password to connect to the server.
Once you SSH into your gear, you have all the access you need as an application developer; you can look at logs, change configuration for your app servers, and move files around. However, you are not an administrator on the gear; you cannot install new binaries using yum, you cannot change DNS settings, and you cannot get root access. One other benefit of SSH is that you can also use it to port forward, which “tricks” your local machine into thinking things running on your gear can be accessed locally. There is a whole section dealing with remote access over SSH on OpenShift.com, and we discuss it further in Chapter 5. There is also an OpenShift blog post discussing SSH port forwarding. There are instructions on how to use port forwarding in Chapter 7.
Git
Git is a program that provides distributed version control. You may have used Subversion, CVS, or Visual SourceSafe; these are centralized version control systems. With centralized systems there is a master server and everyone else has a copy of the code that they need to synchronize with the master. With Git, every repository, from the one on your laptop to the one on the server, is considered a legitimate master. Everything is kept in sync through patches sent between repositories. You can use Git like a pseudo-centralized version control system by having everyone on the team agree on “The Master.” Wikipedia has a good discussion about some of the differences between centralized and distributed version control systems.
The important thing to keep in mind with Git is that the Git repository on your machine is considered a repository, and you need to commit your changes there first. You have to add any new files and commit any changes on your local machine before you can push your changes to any other Git repository.
On OpenShift, when you spin up the primary application gear you create a Git repository on that gear that hosts all the code for your application. If you use the command-line tools or the Eclipse tools, at the end of application creation you clone the Git repository from the gear onto your local machine. We use SSH to secure all our Git transactions, so if you don’t get your SSH keys set up properly you can’t actually do any development work on your application. After the cloning, you now have two Git repositories:
- A remote repository on the OpenShift gear
- A local repository on your laptop or desktop
There are three basic commands you need to use to work with OpenShift:
-
git add - Add a file to your local Git repository. Even if a file is in the directory representing your Git repo, it is not considered part of the repository until you add it.
-
git commit - Commit any changes you have made to your local repository.
-
git push - Push the changes from your local repository back up to the gear from which it was cloned.
If you are interested in learning more, there are several different decent documents to get you going. If you are coming from Subversion land, there is even a Git introduction for you. The fine people at GitHub have also put together a nice collection of resources about Git.
A quick note about the difference between Git and GitHub. Git is the tool; GitHub is a site that allows for public and private hosting of Git repositories. GitHub also adds a lot of social features, making it very easy for developers to find and collaborate on code. We host many QuickStarts—Git repositories that are a shortcut to getting started with a framework or an application—on GitHub. That said, there is no requirement to use GitHub with OpenShift, and your application repositories are private and only accessible to people with SSH access to your gear.
This chapter covered the minimal amount of background you need to get started creating applications. We didn’t cover much information about how OpenShift is architected, its various pieces, or other tools you can use when working on the platform. Once you build a few applications, you can go on and read more about those topics if you need to. With all those preliminaries out of the way, let’s move on to why you really got this book—time to create a web application!
Get Getting Started with OpenShift now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

