May 2025
Beginner to intermediate
260 pages
2h 58m
Chinese
本作品已使用人工智能进行翻译。欢迎您提供反馈和意见:translation-feedback@oreilly.com
取得 ML 进展的最佳方法是反复遵循图 7-1 所示的迭代循环,我们在第三部分的导言中已经看到了这一点。从建立建模假设开始,迭代建模流水线,并进行详细的错误分析,为下一个假设提供依据。
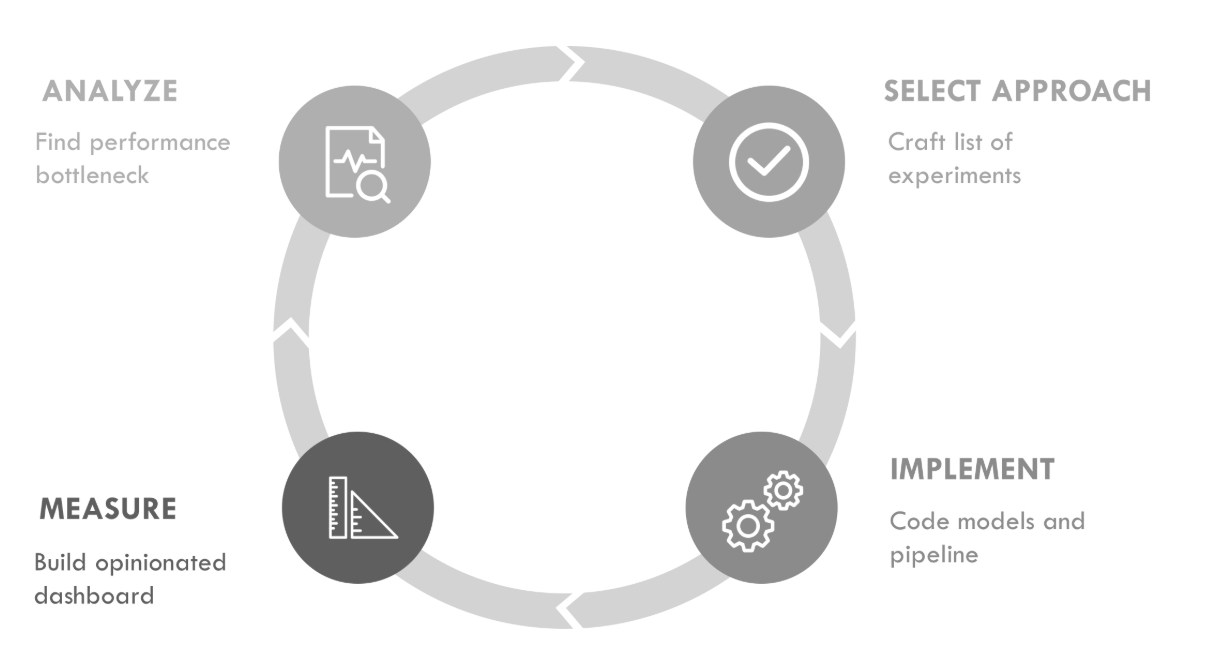
前几章介绍了这一循环的多个步骤。在第 5 章中,我们介绍了如何对模型进行训练和评分。 在第 6 章中,我们分享了如何更快地构建模型和排除与 ML 相关的错误的建议。本章首先展示了使用训练有素的分类器为用户提供建议的方法,然后为 ML 编辑器选择了一个模型,最后将两者结合起来构建了一个可用的 ML 编辑器,从而结束了循环的迭代。
在"ML 编辑器规划 "中,我们概述了我们的 ML 编辑器计划,其中包括训练一个模型,将问题分为高分和低分两类,并使用这个训练好的模型指导用户写出更好的问题。让我们看看如何使用这样的模型为用户提供写作建议。
ML 编辑器的目标是提供写作建议。将问题分为好坏是朝着这个方向迈出的第一步,因为它可以向用户显示问题的当前质量。我们希望在此基础上更进一步,通过向用户提供可操作的建议来帮助他们改进问题的表述。
本节将介绍提供此类建议的方法。我们将从简单的方法开始,这些方法依赖于综合特征度量,在推理时不需要使用模型。然后,我们将了解如何利用模型的得分及其对扰动的敏感性来生成更加个性化的推荐。你可以在本书 GitHub 站点上的生成推荐笔记本中找到本章展示的每种方法应用于 ML 编辑器的示例。
通过 ML 循环的多次迭代,可以训练出性能良好的模型。每次迭代都有助于通过研究现有技术、迭代潜在数据集和检查模型结果来创建一组更好的特征。为了向用户提供建议,您可以利用这种特征迭代工作。这种方法并不一定要求对用户提交的每个问题都运行一个模型,而是侧重于提供一般性建议。
您可以直接使用这些特征,也可以使用训练有素的模型来帮助选择相关特征。
预测特征一旦确定,就可以直接传达给用户,而无需使用模型。如果某个特征的平均值在每个类别中都有显著差异,就可以直接分享这一信息,帮助用户将他们的示例推向目标类别的方向。
我们很早就发现了 ML 编辑器的一个特点,那就是存在问号。对数据的检查表明,得分高的问题往往问号较少。为了利用这一信息生成推荐,我们可以编写一条规则,如果用户问题中的问号比例远远大于高分问题中的问号比例,就会向用户发出警告。
使用 pandas 只需几行代码就能实现每个标签平均特征值的可视化。
class_feature_values=feats_labels.groupby("label").mean()class_feature_values=class_feature_values.round(3)class_feature_values.transpose()
运行前面的代码会产生表 7-1 所示的结果。在这些结果中,我们可以看到,我们生成的许多特征值在高分和低分问题(此处标注为 "真 "和 "假")上有明显不同。
| 标签 | 假的 | 正确 |
|---|