When considering what an EHR could and should be, we must carefully admit that a custom paper-form-based record system is awfully hard to beat, from the perspective of the doctor that designed it. It can be as comprehensive as the user needs, and it can be modified and extended at any time by modifying the form template or by making diagrams on a specific patients form. With the judicious use of check boxes a form becomes blazingly fast, but the check boxes are not traps; each check box supports infinite extensibility. Paper degrades very slowly, and we have paper medical records that date back at least a century. Fast, durable, extensible, intuitive, convenient, forgiving, and cheap. We have not even mentioned post-it notes.
Consider the partial form in Figure 4-1.[4]
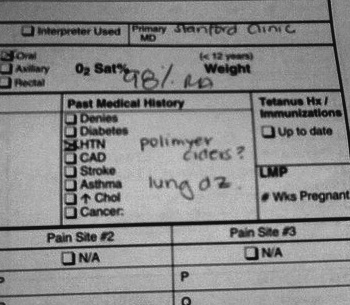
In the “history” section of the form, which is obviously very complex, the nurse had written “Polimyer Ciders” after the patient had told her that she had “polymyositis.” Sounds like a mistake, right? This is funny, which is why it was posted on the Internet. Being funny does not keep this example from showing just how smart the paper process is. The nurse had written the phrase with a question mark. She had known that she did not understand what the patient was talking about, but passed along what she had heard, along with her confusion about it. Notice that “HTN,” which stands for hypertension, is also checked. There is space here for a person to make notes, as the nurse did, but still clearly mark with a simple “x” the most common healthcare issues faced by typical patients. Diabetes, hypertension, heart disease, stroke, asthma, high cholesterol, and cancer are all options here. Note the expectant colon ':' in the cancer check box, calling for whoever is writing to record what type of cancer the patient had, if they chose to use the cancer check box. Paper is flexible enough to cover the strange stuff, yet fast on typical tasks.
Consider the blank sheet of plain white paper. A sheet of paper can become legal notes for a lawyer, the design of a machine or circuit for an engineer, the careful drawing of a building for an architect, and notes about a patient for a doctor. When you account for paper airplanes and origami, paper has a wonderfully large number of wonderful uses.
The powerful aspect of a paper chart is that there is never a limitation of the type or content of data that can be added. If it can be written or drawn, it can be added as needed.
The recently released Apple Retina display is 326 pixels per inch (PPI), and normal humans cannot see clearly past 300 PPI. In the HDMI video standard, monitors must support 30-bit color on the low end. An 8-1/2 x 11-inch sheet of paper comes out to 8,415,000 pixels at 300 DPI (more HD than the most uber-HD monitors now available). Assuming they support a 30-bit color depth, this means that they are supporting 252,450,000 bits per image, or about 31 MB per image. Of course, the human eye is capable of seeing many of these pages per second, but the real limitation of the paper system is a human’s ability to change sheets of paper quickly. Assuming the doctor was really moving, he might see 5 pages per second. That puts the bandwidth of paper at something like 1262.25 megabits per second (Mbps). In comparison, a good broadband Internet connection runs at about 5 Mbps, which is enough to stream movies. If you account for the fact that a doctor might be dynamically ignoring 995 pages of medical record to look at the right 5 pages, and then considered her rate of consumption at 1,000 pages per second, the bandwidth of paper is faster, by far, than any computer network in practical existence. All of these numbers are estimates, but it would be difficult for anyone not to concede that the actual bandwidth of paper-to-brain is pretty fast.
Moreover, it is easy to make paper better at any given information task. It is simple for any doctor to use a computer or photocopier to print lines and labels all over the blank sheet of paper, turning a simple sheet of paper into a form. Paper forms in healthcare are far more potent than in most industries.
When doctors look at a paper form, they feel no loyalty to the lines and check boxes. Doctors are not mere paper pushers or automatons who fill in everything in triplicate. Doctors feel comfortable drawing “outside the lines” and because they often create their own forms, and are frequently the only readers of their own completed forms, the paper-based patient data system melds easily with the mind of the designing physician. This is all just the benefits of a single paper form; when you add a folder to keep groups of forms together, it becomes even more powerful.
Instructions, diagrams, complaints, compliments, questions, answers, tables, pictures, reports, receipts, faxes, and, of course, post-it notes can all be added to a paper chart, normally just a folder, with ease. Doctors’ handwriting is famously illegible, but they rarely need to actually read the entire contents of a chart. They need to be able to use the written record of what they wrote to jog their memory: what is special or different about this patient, what are the next steps in the treatment? During typical operations the chart need only indicate what the next step is to the doctor who made it. But it is still powerful enough to hold the entire history (assuming the handwriting problem is addressed), for the rare occasions when it is important to look at everything.
The nurse who filled out the example form in Figure 4-1 also wrote “Lung DZ” in the history section. That phrase means “Lung Disease,” and is a wonderful example of medical abbreviations, an important part of the paper chart that will make the jump to electronic charts. Medical abbreviations are now largely standardized, after a substantial number of medical errors occurred because of nonstandard abbreviations. The standardization of abbreviations bounds written data, even on paper forms. Once medical abbreviations became standardized, they provided a clear enough shorthand for common medical terms that they could safely be recommended for use. But this is only possible when the mapping between abbreviations and longer terms is perfectly understood and mostly identical everywhere. That mapping, between abbreviations and longer terms, is in fact a healthcare ontology, one that performs well on paper. We will discuss medical abbreviations further in Chapter 10.
Individual paper forms are typically tokens in a complex clinical workflow. The nurse fills out a form when the patient arrives and gives the patient a copy. The patient then takes it to the X-ray department. The X-ray department performs an X-ray and gives the results (on paper and film) to the patient to take upstairs to a particular doctor. The nurse in the waiting room takes the papers and film, and deposits them in a wall-mounted box outside an exam room, and escorts the patient into the room. Each of the steps can have a check box on the form itself, so that the patient knows just where to go next, and if she gets lost (and who doesn’t in a hospital?) anyone can look at the form and show the patient where to go next. There are thousands of variations on this basic theme to accommodate the various needs of different clinical organizations.
This is an important insight that merits highlighting: even the paper chart (i.e., the whole bundle, not just a single form) is not just a paper record of a patient’s healthcare history and current status. It is also a token in a clinical workflow. Considering the record without considering the workflow is a simple mistake that is easy for technologists to repeatedly make. To prevent this mental error, try to adjust your mental imagery of a paper chart into something dynamic and moveable in nature. One of the authors tries to imagine the record as a manila folder with little wheels attached to it. That is a pretty silly mnemonic, but it works.
Some clinics use colored folders to enable different workflows. They place the chart in a green folder and send the patient to the green waiting room. A red folder might mean that a patient is waiting in the red waiting room, and in another clinic it might mean that a patient needs to have blood drawn. As we say elsewhere, there is no such thing as a typical healthcare workflow. At a minimum the paper chart is the home base to the various paper forms that enable different clinical workflows, and the whole contents must be copied to other organizations or departments when the patient moves. So the paper chart is always a workflow token, exercised to different degrees, in different organizations.
Often, a paper form will have been designed and cemented in the workflow so long ago that no current employee can remember why the form was designed in a particular way. Be very careful of this, because as you seek to replace the form in the workflow with software, you might discover that what you considered an incidental aspect of the form’s design was actually solving some important problem in another portion of the workflow that you did not fully understand.
Paper is an excellent record of clinical care, to the degree that the data does not need to move. It is a perfect healthcare record to the degree that healthcare is provided by a single clinician, looking at a patient chart and the patient all at the same time. Modern healthcare is no longer a one-doctor, one-record, one-patient game. The coordination of care for a patient requires that critical information be moved from where it is to where it needs to be, on time. Sometimes the paper chart moves fast enough. Most of the time it does not. God forbid a paper chart should be lost.
The first thing that people assume when you say “coordination of care” is that you mean between-organization coordination. But the primary benefit of EHR systems is that they coordinate care within a healthcare organization. This is why EHR adoption has been so strongly correlated with the size of a clinical organization. The more an organization needs to communicate with itself about a given patient, the greater the benefit of an EHR system. Conversely, single-clinician practices get the least benefit from computerization.
There are classes of medical errors that are clearly related to the information not moving fast enough, like a patient’s allergies or current medication list not being with the nurse when a new drug is given to a patient. Many preventable medical errors go away entirely when you measure them, which means they mostly disappear whenever manual observation occurs. The spread of infections due to clinicians forgetting to wash their hands is a good example of this. The only real solution is to measure these types of behaviors all the time electronically, preferably preventing rather than merely chronicling the errors in question. Real-time workflow interruption can only occur when data values can spawn real-world stimuli (like flashing lights or beeps), and that means software.
Lastly, paper charts are difficult to study en masse. Doctors can easily look at a single paper chart and see how a patient with diabetes is doing, but they cannot get the same information about all of their patients with diabetes without doing costly and slow chart reviews. Paper chart reviews simply cannot serve to inform a profession that changes as fast as healthcare does.
Paper data is trapped, inactive, and difficult to study. If paper could shout, there would be no need for EHR systems.
The first thing that computer technologists must free themselves from is the notion that computers are the “solution” to information flow in a clinical environment. If computer specialists do not understand everything that a paper process is doing, or fail to respect the ways in which a paper-based information system handles something well, then they will appear arrogant to the clinical staff, who understand perfectly how effective the paper forms can be. When you introduce a computer system that makes a process that used to take 30 seconds take 10 minutes, then your solution will instantly be met with derision by clinical staff who are already overworked.
If you want a concrete example of how good paper is, consider the surgical checklist movement that has been growing in popularity. Studies have shown that this simple information intervention, which uses either a paper form or a whiteboard, has improved patient safety on the operating table more than any surgical technique advancement in the equivalent time frame. The next time you are feeling smug about your awesome health IT plans, keep in mind that this simple information intervention, which required no software at all, might be the most effective information-based intervention of the decade.
Clinical staff, especially nurses, are well-practiced in silent rebellion against unreasonable directions by a multitude of “pointy-haired” bosses, especially when those directions interfere with their care of patients. In their hearts, the clinical staff will plot against the new software, waiting patiently until the computer trainer has left, and then use any excuse to revert to a paper workflow. Months later, a review of the software deployment will reveal that the system had been abandoned for months, despite the project being regarded as a success by management. Countless deployments of health IT software have failed because of this type of rebellion. This problem is so prevalent that you should assume healthcare staff have always reverted back to a paper process, until random spot checks have proved otherwise for months. If possible the real-time usage data (but never the contents) of an EHR system should be an item that an organization monitors within its network operations center (or equivalent). At a minimum, usage data should be logged in a way that can be studied later. Do not assume that you understand how your health IT system is being used: know.
The first step in combating user abandonment is to be realistic and humble about the benefits of any health IT system in comparison to a paper system. This cannot happen without fully respecting how really brilliant paper forms can be in healthcare workflow. Being arrogant is the first rookie mistake in deploying health IT software.
The second rookie mistake in deploying health IT systems is to attempt to replicate the patient chart in software. Ironically, this mistake comes from giving too much respect to the paper form. This is a frequent mistake made by computer programmers and purchasers who come to recognize the complexities of an effective paper-based workflow. They make the reasonable assumption that if they perfectly replicate a paper form in the health IT software, then they cannot fail to successfully replicate the nuances of that workflow.
Sadly, although that is a reasonable assumption, it is utterly incorrect. Almost all early attempts to computerize clinical workflows began life as an attempts to clone a patient chart in software. Many mature computer software systems still maintain some paper chart analogies, while abandoning any real parallels to paper-like designs. In fact you can reasonably assume that to the degree an EHR system actually works identically to a paper chart, it is an immature design.
Software and paper are both amazingly capable information systems. They just happen to be very good at different types of information tasks. A computer program that directly imitates a paper-based clinical workflow is doomed to be worse than both the original paper process and an effective health IT software deployment. It is usually simple to determine when this is happening. Paper-based workflows are advanced, but they are not perfect. Computers can make most things that required lengthy workflows instantaneous. When you accelerate a paper-based workflow 1,000 times, small flaws in the fundamental paper workflow become 1,000 times worse. This is why health IT advocates must understand the “why” of paper forms as much as the static health data in question. If you are adding data fields to an EHR system from a preexisting paper form without understanding the role of those data fields in the paper workflow, you will regret it.
A good rule of thumb is that a technologist should be given a five-minute lecture on any given clinical data point and its role in the clinical workflow, until the technologist is comfortable actually giving such a brief lecture themselves. This is not a paragraph to just skip over. This is the heart of the technologist plus clinician collaboration that has made the most successful clinical software deployments work. If this is not happening constantly, as a natural part of your deployment or development process, then it needs to be formalized into a ongoing process. If you have trouble formalizing this process, read up on pair programming or agile software development and consider using some of those methods with clinician-technologist pairs. Unless a technologist has a reliable, if superficial, understanding of the clinical processes in a given clinical environment, the technology deployment will be misdirected. This level of familiarity takes time and is expensive. Be suspicious of any technologist who underestimates this expense, especially if he or she is not very familiar with health IT.
Do not think this advice does not apply to you if you are not actually conducting software development on the core of an EHR. When you deploy an EHR system, you are developing software. Your chosen EHR is simply your programming substrate. If you are thinking of your deployment of an EHR as a minor software development effort you will be better prepared for the level of engineering you will need to do in order to replace a paper-based data and workflow system.
Paper handles ambiguity extremely well. Remember the nurse who filled in the check box with a question mark? She was dynamically repurposing the paper form to communicate a complex ambiguity. With a software check box widget, which must be either checked or unchecked, there is no option for “repurposed.” Imagine the conundrum that this creates for the EHR software developer/deployer. To fully account for the case where a midlevel clinical professional, like a nurse, is unsure about a detail of the patient’s history, the software developer must force the nurse to make a choice that she in unsure of (she does not really know whether she should “check” or not), to somehow record the fact that she was uncomfortable somehow, and then find a way for the higher-level provider to override that clinical decision in an elegant way. That is a lot of software intelligence to replace something that the paper form does intrinsically.
If you want to replace a paper chart or even migrate from a previous software-based system, you must fully understand what the old and new systems are capable of. Elegant and advanced health IT software has different ways of dealing with healthcare workflows. The most useful tool in your effort to “develop” your EHR system is to understand the two basic approaches to recording health data: liberally formatted input and usefully bounded input.
Just because you are storing data does not mean that you are storing it well. Certain data storing software (relational databases) have a concept called normalization. For now, we can skip an exact definition of what relational databases are and what, precisely, normalization means in that context. Those of you who are already familiar with normalization (as it applies to databases, not statistics) will quickly be comfortable with our use of this term. For our purposes, we will use the term normalization to mean data that is:
If the patient data in an EHR is well bounded and well linked, it is easy to leverage for higher level processes like reporting, clinical decision support, data exchange, and other useful clinical automations. The simplest useful function that an EHR can perform with normalized data is accurate and comprehensive reporting. The basic function that underlies data reporting is data grouping, which in healthcare means grouping patients based on some data about them. The meaningful use standards require smoking status reporting, for instance, and that is only possible with normalized smoking data.
Normalized data allows you to ask questions of your patients as a population. In some ways, the term electronic in electronic health record is ironic. Merely storing patient data on computers does not, by itself, allow a patient population to be studied more effectively. There are at least two examples of health IT approaches that certainly count as electronic, but do not qualify as an EHR as per meaningful use. The first is simply a collection of word processing documents. Many physician power users created methods of very effectively creating piles and piles of text documents about their patients. Although these power users benefited greatly from their automations, this did not create data in a way that would allow grouping. Similarly, many in the health IT industry have historically maintained that the purpose of computer systems should be to merely archive and organize scans of paper charts. The meaningful use standards made it clear that these approaches were unacceptable. Of course, both of these approaches could be part of a system that qualified as an EHR under meaningful use, but they do not qualify without software that meets requirements that are impossible without structured data.
Information exchange between clinical sites is impossible to automate without normalized data. For information exchange to take place, data must not only be normalized (i.e., well-structured), but it must be structured in a specific way. One of the tasks that is relatively simple for computers to execute is the conversion of one form of structured data to another. Different forms of structured data have different benefits. Specific data structure formats allow the transfer of clinical data from one party to another and we will discuss those in detail in Chapter 11. For now it is important to emphasize that without well-structured clinical data as a starting point, it is impossible to generate data in a structure that can facilitate the exchange of clinical information. This means there is no point in moving to an EHR system without normalized data because without adequate structure, there is no way for computerized patient data to coordinate care better than paper records.
Other resources, including the meaningful use standards, refer to normalized data as “structured data” but that ignores the possibility that the structure is wrong. Normalized, for our purposes, means well-structured and working. Not all structure is created equal. Substantial portions of this book will be spent discussing what well-structured data looks like.
If EHR software is not providing well-bounded and well-linked data, it is really no better, and often much worse, than paper charts. The important thing for clinicians to understand is that the data must be linked and bounded correctly. That might seem obvious to a technologist. What the technologist needs to understand is that linking and bounding clinical data is a complex clinical decision. Clinicians often defer this complicated medical issue by designing paper forms, with boundaries that are easy to repurpose on a case-by-case basis.
The paper form check box and the software check box only seem similar. The paper version can be marked with a question mark, in the case of a confused clinical staff member. It can be the source of an arrow drawn to a note written elsewhere in on the form. In short it can, and often does, all kinds of information tasks. Obviously a paper form check box can also be checked or not checked.
The check box element of standard graphical user interfaces (GUIs; the part of software that you actually see on the screen), can only do one of those tasks. It can be on. It can be off. In fact, the check box can represent any two arbitrary states: hungry or not hungry, etc.
The advantage of the software check box is that it is strongly bounded. By limiting the choices to only two possibilities it forces the clinical user to place the patient into one of two categories. Once a patient has been categorized in this way, it is possible for the software to leverage this in countless automated tasks. Most of the meaningful use standards are focused on the contents of the reports that a mature EHR system can generate, and without well-bounded data these reports are impossible. Let’s look at two examples of how a check box can be used or abused in clinical software.
The first simple example is the test for HIV status. The HIV lab test can actually have more than just positive and negative results, but results are typically retested until a person can be considered clearly either HIV positive or negative. Using a simple check box, a user can mark a patient as HIV positive. That allows the software to include other information about the patient’s health in reports for all the patients that are HIV positive. Forcing a distinction between HIV positive and negative and excluding the ambiguities involved in the test is a useful thing to do. It allows the software to provide warnings to clinical users to protect themselves from HIV infection using double latex gloves when appropriate. There are countless other clinical workflows that change based on HIV status. Using a software check box to force a clinician into making a yes or no decision makes the software more capable of clinically useful tasks.
Many technologists are used to similarly exclusive options (usually using exclusive radio buttons, which is another type of software GUI element) for male or female. In fact, this is the perfect example of the type of two-value choices that are appropriate in typical software design (like accounting software or web-based store fronts), but totally inappropriate for clinical software. For any clinician there are at least three genders: male, female, and other (as in “You better pay attention to this clinical issue”). For any clinician who treats gender-related conditions there are many, many more. It is clinically dangerous to ignore gender-related clinical issues by forcing clinicians to choose either male or female.
HIV status can be usefully bounded as a yes or no question, but gender cannot be bounded as just XX or XY. On a paper form, “male” and “female” are safe options because you can clearly mark any third choice in countless ways. Gender designation is a controversial and subtle health information issue, and a good example for the difficult requirements for health software. Health software has to get a thousand subtle data bounding issues right just to be on par with paper. Checking to see how many options are available for gender is a great way to determine how mature an EHR system is. If there are only two choices, the software should be considered dangerously immature.
Bounding also has another general principle: have only one copy of a given data in the database. Once you consider the difficulties of having two or more copies, the reason for this quickly becomes apparent. Let’s suppose we have HIV status recorded in two places in the database: place A and place B. Normally this happens when two different subsystems in an EHR need to leverage the same piece of data. We can imagine that place A is in the surgical planning portion of the EHR and place B is the HIV status on the main patient chart.
Obviously, knowing whether a patient has HIV before a surgery is critically important. It makes sense to make an extra HIV question part of the presurgery workflow. The workflow is implicitly asking the patient: “Hey, last week when we scheduled this surgery, we asked you if you were HIV positive and you said no...but I am giving you one more chance to answer that question differently...” and then explicitly: “Are you HIV positive?” usually on a presurgery form. The workflow pretty much has to be this way. Sometimes people are reluctant to share important health information, and the workflow has to give people multiple opportunities to share this information.
But just because the workflow has to ask the question twice does not mean that the information system should have two places in the database where the information can exist. Let’s continue to imagine that the presurgery HIV status has its own place in the database. Obviously, the whole reason that the second HIV question exists in the workflow is because, occasionally, a patient will answer “Yes” to the question only immediately before the surgery. Sometimes, the value of the first HIV status will be “No” and the presurgery HIV status will be “Yes.” It is also possible to have the main HIV status be “Yes” and the presurgery HIV status be “No,” but usually this is a data entry error.
So what do “Yes/No” or “No/Yes” items mean? Obviously, these data items have no reliable meaning. They must be reconciled. The need for reconciliation is common when you have two separate software systems, and we will talk more about how to deal with these type of issues in Chapter 11. But it should never happen within the same information system. Normalization requires that a single piece of data occur only one time in a given information system. If you find that there are two places to record an identical piece of data in a particular system, that is evidence of a flawed design.
That brings us to this rule: Have only one copy of any given piece of data. Instead of copying data into two places on the system, instead link data from one part of the information system to the other.
Data linking is a far more subtle and difficult issue. Data linking is all about the way data in one part of a patient’s record relates to data in another part of the record. When data linking fails, the data in an EHR for a patient is at war with itself. The simplest way to ensure that data is well-linked is to try and ensure that data is always linked correctly, rather than duplicated.
Returning to gender as an example, when a new patient, Jane Doe arrives at the office, the front desk personnel was distracted and marked Jane as a “male.” Later, Jane becomes pregnant. In different parts of the EHR system, the fact of Jane’s pregnancy and details about her pregnancy are stored. We might wish that an EHR could warn us of such a typo, but to do this, pregnancy status must somehow be linked with gender in a way that allows the software to know that something is amiss. If a patient marked as a male has pregnancy data, the patient’s record is probably at war with itself. Either linking has not occurred, or the software is not properly leveraging the links. We know that normalization requires that a single fact appear in only one place in the database. That rule is being violated here. In the pregnancy data section, the fact that the patient is female is either assumed or explicitly recorded, but it is contradicted elsewhere in the record.
It should be clear that the first two principles of normalization are really two parts of the same principle. Instead of duplicating data with the same meaning in an EHR, only one copy should be kept. Linking allows that single copy to do the work of two copies.
As with many things in health IT, the exception proves the rule. Although a single copy of any given data point is always preferable, this is impossible in any EHR system that has even rudimentary interoperation with other information systems (e.g., the insurance companies’ IT infrastructure). Often several copies and variations must be maintained about a data element in order to account for the differences between systems. The simplest example is when a given patient has one name that he or she prefers to use at the clinic, and another name that must be used to bill insurance.
Rather than a violation of our core concept, that data should not be replicated, we should more carefully define what a “piece” of data means. Every “First Name” field in an information system is usually not equivalent at all; rather, each copy is really a different piece of data. For instance you might have the following legitimate examples of secondary “First Name” fields.
| First Name for billing |
| First Name in the name history |
| First Name as recently imported from the Lab Information System (LIS) |
These are all cases where you must seemingly violate the single copy rule, but by defining the fields more carefully you can see that they are not actually the identical data at all; instead, they are merely strongly related data fields.
Essentially, this allows us to again extend the “have only one copy” rule:
Have only one copy of any given piece of data, unless you have a good reason not to. Instead, use linking to make a single data element work in different parts of a system. When this is possible, it is usually because two copies of the data have different meanings. When you have two copies, make sure to clearly differentiate why the second copy must exist. Never, under any circumstances, continually maintain two copies of the same data with identical clinical purposes.
It is acceptable for you to import a health record from another provider that has an HIV status that is opposite the one that you have for a particular patient. It is acceptable for you to maintain a different name for a patient, so that you can get billing to work. It is not acceptable, not even a little bit, for you to have two different copies for HIV status that you must rely on in different clinical situations. If your EHR system continually places you in a position where clinicians are wondering which value is correct, that is a design flaw. Mature EHR systems will not do this to clinical users.
There are cases where healthcare data is necessarily at war with itself. You must do everything you can not to add to that problem.
First names, last names, eye color, and gender are all things that normal IT regards as stationary and static aspects of a person. But in fact, all of these things change in some people some of the time. Normal IT systems might allow users to update and change these “static” personal information data points, but EHR systems must allow these changes to occur and also track them over time. This is a another good indicator of mature EHR systems. If there is no mechanism for accessing the history of name changes for an individual, then you should regard the EHR as dangerously immature.
The problem with trying to normalize healthcare data is that there are too many exceptions. Most patients will always have something about them that is outside the bounds of what an EHR might normally expect. The solution is simple: free text, which usually lives in a part of the record called patient notes.
Free text has many of the same benefits of paper. With enough text, almost any subtlety can be made clear. Free text has no bounds. Like paper, it can contain whatever it needs to. Like paper, free text data has substantial limitations when compared to normalized data. When we say free text, we really just mean text, with an emphasis on the fact that one can always write anything in text GUI fields. Although it is possible for software to analyze free text information, it is unwise to rely on the results of those analysis for clinical decisions.
Imagine that the free text portion of a clinical record contains the following text:
Now consider this second record:
In both phrases, an identical string of words appear, but in context, one person is HIV positive, and the other is not. Software can easily search all of the patient records for the phrase “has had HIV” or “has HIV” and assume that all of the patients with this text written somewhere in their EHR record are HIV positive. Of course, for some small portion of the patients, the ones with tricky text as in this example, that conclusion would be wrong. For software to be able to process free text information, it would need to be able to read, with context, as well as a human. The software would need to understand sarcasm and irony. This is a difficult task indeed, as not every human can easily parse sarcasm or irony.
Computers are very good at processing discrete data. Computers can process free text as discrete data, and come to valuable conclusions. Those conclusions cannot be relied on for life or death decisions, though. Any information that must be relied on for critical health decisions must be recorded as normalized data.
You cannot get normalized data from free text. Happily it is relatively simple to have normalized data generate free text. Many modern EHR systems allow users to first create normalized patient data, and then automatically generate free text from that data. Automatic text generation saves time and contributes greatly to the readability of the patient chart. The mechanism is simple: a doctor or nurse uses a GUI to record health information, like a check box to record HIV status, and then the software imports that data automatically into the note using automatically generated prose. In the HIV example, the software might add the sentence “The patient is HIV positive” to the note, when the check box is checked. A doctor can extend this text in meaningful ways, adding richness while saving time. He or she might write, “The patient is HIV positive, but is not yet experiencing symptoms.” The small time savings gained from not needing to type the first half of this longer sentence adds up in the constantly time-constrained healthcare industry.
There are two obvious important dangers with auto-generated free text data. Both of them have to do with protecting the integrity of the normalized data.
Some systems, which have claimed falsely to be EHR systems, do not record normalized data from their GUI elements, instead electing to use the free text note as the only place the data is stored. A good example is any system that uses word processor macros to generate text documents quickly. This type of software has GUIs that could be used to save normalized data, but instead of saving the values into a database that can be normalized, it saves it only as a text document. This is a software design flaw, and cannot meet the meaningful use requirements. By definition, a system like this is not an EHR.
Some EHR users will modify the free text data to contradict the normalized data, without also modifying the normalized data. This is a user process flaw that cannot easily be corrected in software. Because free text is flexible enough to support any content there is no simple way to ensure that it does not contradict normalized data.
Now we have the background to look at a simple statement taken directly from the meaningful use standards:
The Stage 1 meaningful use criteria, consistent with other provisions of Medicare and Medicaid law, focuses on electronically capturing health information in a structured format; using that information to track key clinical conditions and communicating that information for care coordination purposes (whether that information is structured or unstructured, but in structured format whenever feasible);
The meaningful use standards use the term structured, whereas we say normalized only to emphasize that structure is not a simple issue and must be handled carefully. Still this language demonstrates that the Department of Health and Human Services (HHS) recognizes that the distinction and capabilities inherent in free text versus structured (hopefully normalized) data are important issues. Now you should understand why.
The lesson of this chapter is simple. For the clinician it is to recognize the value of normalized or structured data. For the technologist it is to recognize that structuring of EHR data is a clinical issue. Healthcare ontologies represent the practice of bounding healthcare data. Sometimes health ontology is a science, and at other times it is a power struggle or political maneuvering. For now it is enough to say that how to bound healthcare data is best left to specialists. If you find yourself trying to imagine all of the alternatives to “male” and “female” or answering some other fundamentally clinical data bounding question, you are probably in trouble. This chapter is all about why data needs to be normalized, and Chapter 5 details how that should occur.
Get Hacking Healthcare now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

