Excluding Robots
The robot community understood the problems that robotic web site access could cause. In 1994, a simple, voluntary technique was proposed to keep robots out of where they don’t belong and provide webmasters with a mechanism to better control their behavior. The standard was named the “Robots Exclusion Standard” but is often just called robots.txt, after the file where the access-control information is stored.
The idea of robots.txt is simple. Any web server can provide an optional file named robots.txt in the document root of the server. This file contains information about what robots can access what parts of the server. If a robot follows this voluntary standard, it will request the robots.txt file from the web site before accessing any other resource from that site. For example, the robot in Figure 9-6 wants to download http://www.joes-hardware.com/specials/acetylene-torches.html from Joe’s Hardware. Before the robot can request the page, however, it needs to check the robots.txt file to see if it has permission to fetch this page. In this example, the robots.txt file does not block the robot, so the robot fetches the page.
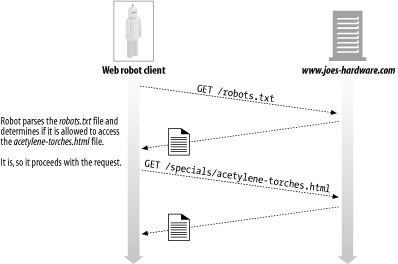
Figure 9-6. Fetching robots.txt and verifying accessibility before crawling the target file
The Robots Exclusion Standard
The Robots Exclusion Standard is an ad hoc standard. At the time of this writing, no official standards body owns this standard, ...
Get HTTP: The Definitive Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

