Chapter 1. Introduction
If you are looking for an introduction into the world of Istio, the service mesh platform, with detailed examples, this is the book for you. This book is for the hands-on application architect and development team lead focused on cloud-native applications based on the microservices architectural style. This book assumes that you have had hands-on experience with Docker, and while Istio will be available on multiple Linux container orchestration solutions, the focus of this book is specifically targeted at Istio on Kubernetes/OpenShift. Throughout this book, we will use the terms Kubernetes and OpenShift interchangeably. (OpenShift is Red Hat’s supported distribution of Kubernetes.)
If you need an introduction to Java microservices covering Spring Boot, WildFly Swarm, and Dropwizard, check out Microservices for Java Developers (O’Reilly).
Also, if you are interested in Reactive microservices, an excellent place to start is Building Reactive Microservices in Java (O’Reilly) because it is focused on Vert.x, a reactive toolkit for the Java Virtual Machine.
In addition, this book assumes that you have a comfort level with Kubernetes/OpenShift; if that is not the case, OpenShift for Developers (O’Reilly) is an excellent free ebook on that very topic. We will be deploying, interacting, and configuring Istio through the lens of OpenShift, however, the commands we use are portable to vanilla Kubernetes as well.
To begin, we discuss the challenges that Istio can help developers solve and describe Istio’s primary components.
The Challenge of Going Faster
As a software development community, in the era of digital transformation, you have embarked on a relentless pursuit of better serving customers and users. Today’s digital creators, the application programmer, have not only evolved into faster development cycles based on Agile principles, you are also in pursuit of vastly faster deployment times. Although the monolithic code base and resulting application might be deployable at the rapid clip of once a month or even once a week, it is possible to achieve even greater “to production” velocity by breaking up the application into smaller units with smaller team sizes, each with its independent workflow, governance model, and deployment pipeline. The industry has defined this approach as microservices architecture.
Much has been written about the various challenges associated with microservices as it introduces many teams, for the first time, to the fallacies of distributed computing. The number one fallacy is that the “network is reliable.” Microservices communicate significantly over the network—the connection between your microservices. This is a fundamental change to how most enterprise software has been crafted over the past few decades. When you add a network dependency to your application logic, you have invited in a whole host of potential hazards that grow proportionally if not exponentially with the number of connections you make.
Furthermore, the fact that you now have moved from a single deployment every few months to potentially dozens of software deployments happening every week, if not every day, brings with it many new challenges. One simple example is how do you manage to create a more frictionless deployment model that allows code being checked into a source code manager (e.g., Git) to more easily flow through the various stages of your workflow, from dev to code review, to QA, to security audit/review, to a staging environment and finally into production.
Some of the big web companies had to put frameworks and libraries into place to help alleviate some of the challenges of an unreliable network and many code deployments per day. For example, companies like Netflix created projects like Netflix OSS Ribbon, Hystrix, and Eureka to solve these types of problems. Others such as Twitter and Google ended up doing similar things. These frameworks that they created were very language and platform specific and, in some cases, made it very difficult to bring in new services written in programming languages that didn’t have support from these resilience frameworks they created. Whenever these resilience frameworks were updated, the applications also needed to be updated to stay in lock step. Finally, even if they created an implementation of these resiliency frameworks for every possible permutation of language or framework, they’d have massive overhead in trying to maintain this and apply the functionality consistently. Getting these resiliency frameworks right is tough when trying to implement in multiple frameworks and languages. Doing so means redundancy of effort, mistakes, and non-uniform set of behaviors. At least in the Netflix example, these libraries were created in a time when the virtual machine (VM) was the main deployable unit and they were able to standardize on a single cloud platform and a single programming language. Most companies cannot and will not do this.
The advent of the Linux container (e.g., Docker) and Kubernetes/OpenShift have been fundamental enablers for DevOps teams to achieve vastly higher velocities by focusing on the immutable image that flows quickly through each stage of a well-automated pipeline. How development teams manage their pipeline is now independent of language or framework that runs inside the container. OpenShift has enabled us to provide better elasticity and overall management of a complex set of distributed, polyglot workloads. OpenShift ensures that developers can easily deploy and manage hundreds, if not thousands, of individual services. Those services are packaged as containers running in Kubernetes pods complete with their respective language runtime (e.g., Java Virtual Machine, CPython, and V8) and all their necessary dependencies, typically in the form of language-specific frameworks (e.g., Spring and Express) and libraries (e.g., jars and npms). However, OpenShift does not get involved with how each of the application components, running in their individual pods, interacts with one another. This is the crossroads where architects and developers find ourselves. The tooling and infrastructure to quickly deploy and manage polyglot services is becoming mature, but we’re missing similar capabilities when we talk about how those services interact. This is where the capabilities of a service mesh such as Istio allow you, the application developer, to build better software and deliver it faster than ever before.
Meet Istio
Istio is an implementation of a service mesh. A service mesh is the connective tissue between your services that adds additional capabilities like traffic control, service discovery, load balancing, resilience, observability, security, and so on. A service mesh allows applications to offload these capabilities from application-level libraries and allow developers to focus on differentiating business logic. Istio has been designed from the ground up to work across deployment platforms, but it has first-class integration and support for Kubernetes.
Like many complimentary open source projects within the Kubernetes ecosystem, “Istio” is a Greek nautical term that means sail—much like “Kubernetes” itself is the Greek term for helmsman or a ship’s pilot. With Istio, there has been an explosion of interest in the concept of the service mesh, where Kubernetes/OpenShift has left off is where Istio begins. Istio provides developers and architects with vastly richer and declarative service discovery and routing capabilities. Where Kubernetes/OpenShift itself gives you default round-robin load balancing behind its service construct, Istio allows you to introduce unique and finely grained routing rules among all services within the mesh. Istio also provides us with greater observability, that ability to drill-down deeper into the network topology of various distributed microservices, understanding the flows (tracing) between them and being able to see key metrics immediately.
If the network is in fact not always reliable, that critical link between and among our microservices needs to be subjected to not only greater scrutiny but also applied with greater rigor. Istio provides us with network-level resiliency capabilities such as retry, timeout, and implementing various circuit-breaker capabilities.
Istio also gives developers and architects the foundation to delve into a basic explanation of chaos engineering. In Chapter 5, we describe Istio’s ability to drive chaos injection so that you can see how resilient and robust your overall application and its potentially dozens of interdependent microservices actually is.
Before we begin that discussion, we want to ensure that you have a basic understanding of Istio. The following section will provide you with an overview of Istio’s essential components.
Understanding Istio Components
The Istio service mesh is primarily composed of two major areas: the data plane and the control plane, which is depicted in Figure 1-1.
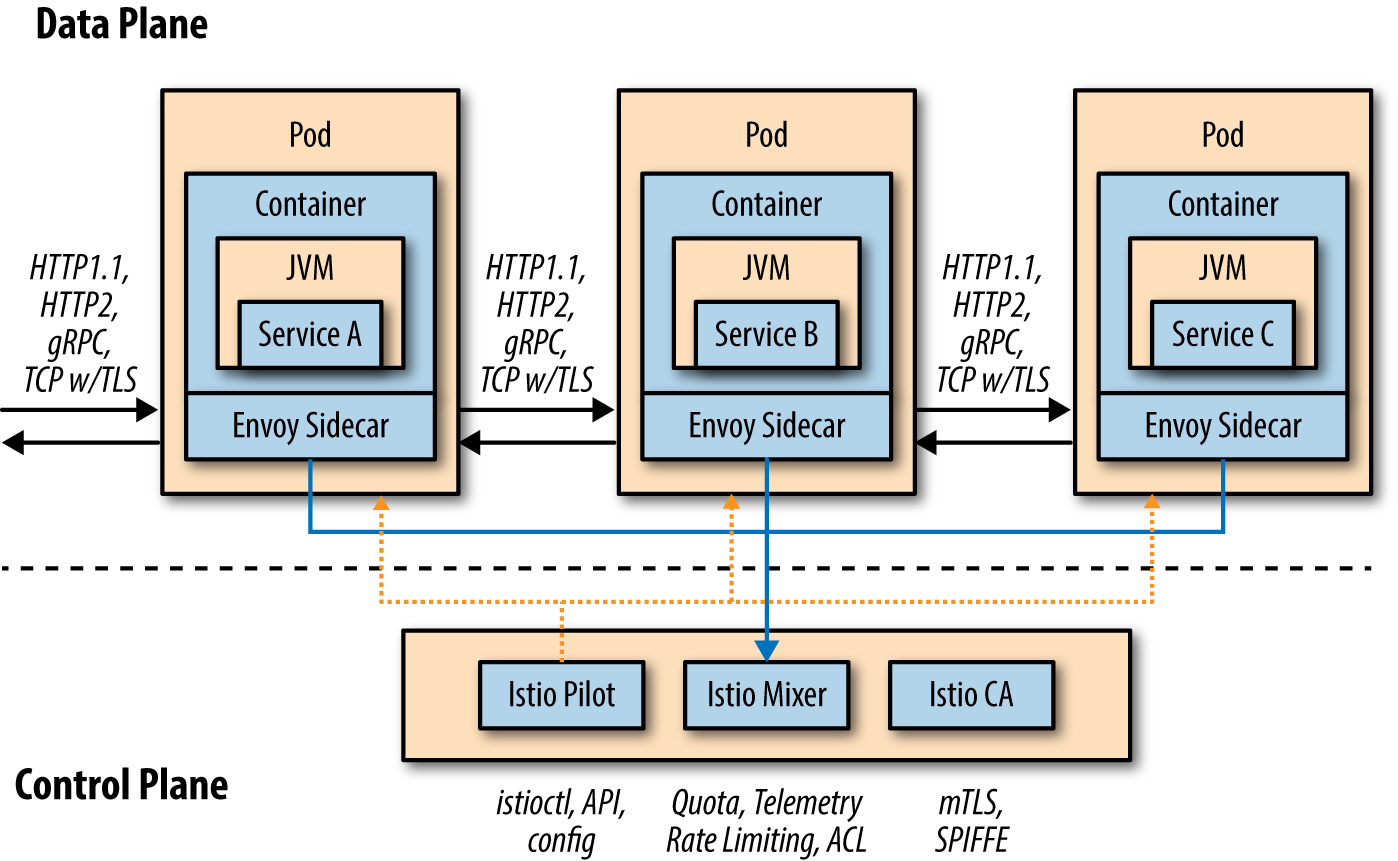
Figure 1-1. Data plane versus control plane
Data Plane
The data plane is implemented in such a way that it intercepts all inbound (ingress) and outbound (egress) network traffic. Your business logic, your app, your microservice is blissfully unaware of this fact. Your microservice can use simple framework capabilities to invoke a remote HTTP endpoint (e.g., Spring’s RestTemplate and JAX-RS client) across the network and mostly remain ignorant of the fact that a lot of interesting cross-cutting concerns are now being applied automatically. Figure 1-2 describes your typical microservice before the advent of Istio.
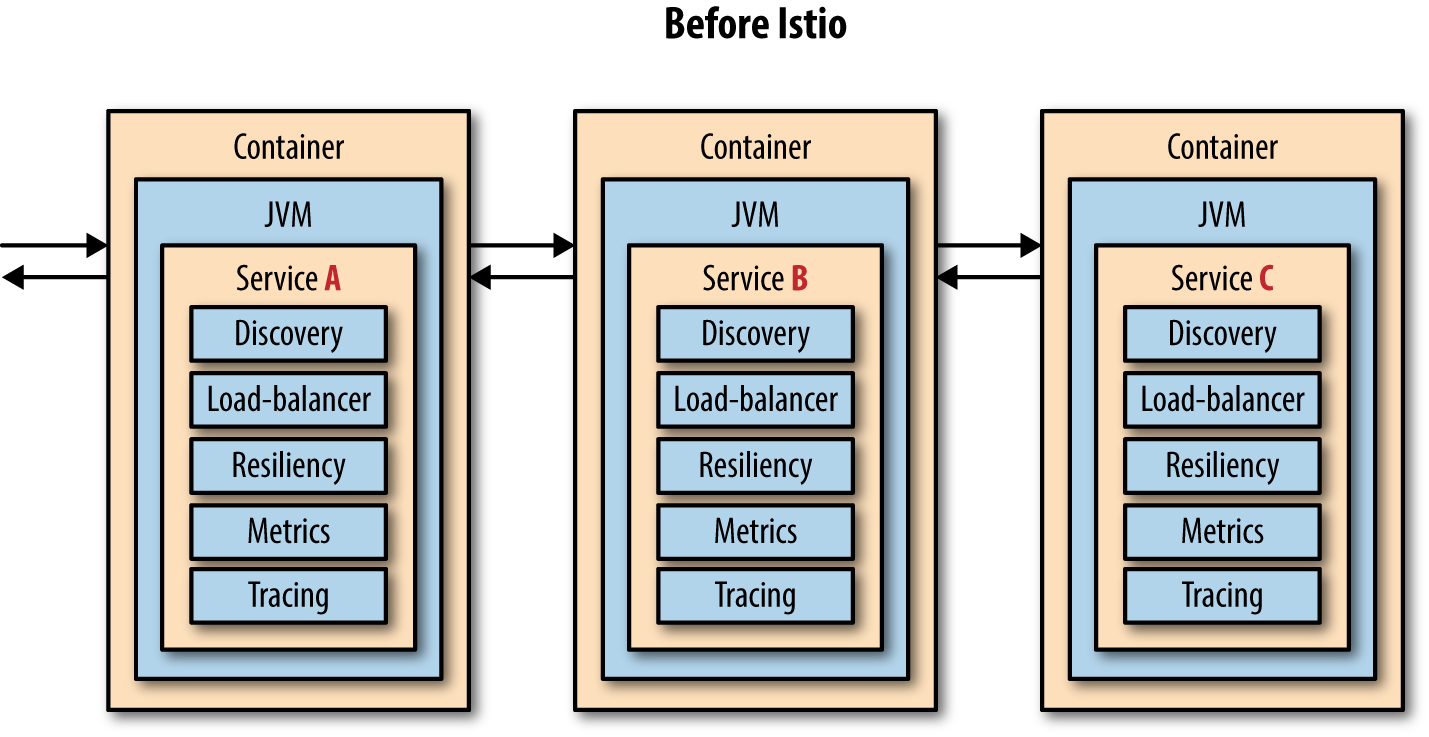
Figure 1-2. Before Istio
The data plane for Istio service mesh is made up of two simple concepts: service proxy and sidecar container, as shown in Figure 1-3.
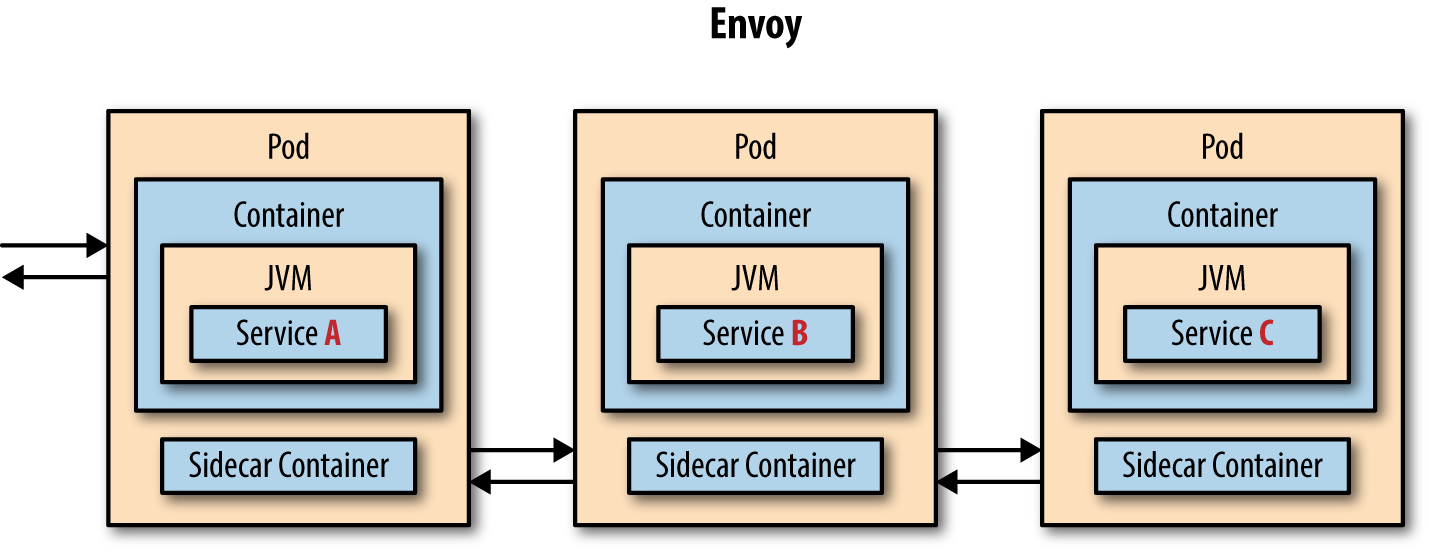
Figure 1-3. With Envoy sidecar (istio-proxy)
Let’s explore each concept.
Service proxy
A service proxy is a proxy on which an application service relies for additional capabilities. The service calls through the service proxy any time it needs to communicate with the outside world (i.e., over the network). The proxy acts as an intermediary or interceptor that can add capabilities like automatic retries, timeouts, circuit breaker, service discovery, security, and more. The default service proxy for Istio is based on Envoy Proxy.
Envoy Proxy is a Layer 7 proxy (see the OSI model on Wikipedia) developed by Lyft, the ridesharing company, which currently uses it in production to handle millions of requests per second (among many others). Written in C++, it is a battle tested, highly performant, and lightweight. It provides features like load balancing for HTTP1.1, HTTP2, gRPC, the ability to collect request-level metrics, tracing spans, active and passive health checking, service discovery, and many more. You might notice that some of the capabilities of Istio overlap with Envoy. This fact is simply explained as Istio uses Envoy for its implementation of these capabilities.
But how does Istio deploy Envoy as a service proxy? A service proxy could be deployed like other popular proxies in which many services’ requests get serviced by a single proxy. Istio brings the service-proxy capabilities as close as possible to the application code through a deployment technique known as the sidecar.
Sidecar
When Kubernetes/OpenShift were born, they did not refer to a Linux container as the runnable/deployable unit as you might expect. Instead, the name pod was born and it is the primary thing you manage in a Kubernetes/OpenShift world. Why pod? Some think it was some reference to the 1956 film Invasion of the Body Snatchers, but it is actually based on the concept of a family or group of whales. The whale being the early image associated with the Docker open source project—the most popular Linux container solution of its era. So, a pod can be a group of Linux containers. The sidecar is yet another Linux container that lives directly alongside your business logic application or microservice container. Unlike the real-world sidecar that bolts on to the side of a motorcycle and is essentially a simple add-on feature, this sidecar can take over the handlebars and throttle.
With Istio, a second Linux container called “istio-proxy” (aka the Envoy service proxy), is manually or automatically injected alongside your primary business logic container. This sidecar is responsible for intercepting all inbound (ingress) and outbound (egress) network traffic from your business logic container, which means new policies can be applied that reroute the traffic (in or out), apply policies such as access control lists (ACLs) or rate limits, also snatch monitoring and tracing data (Mixer) and even introduce a little chaos such as network delays or HTTP error responses.
Control Plane
The control plane is responsible for being the authoritative source for configuration and policy and making the data plane usable in a cluster potentially consisting of hundreds of pods scattered across a number of nodes. Istio’s control plane comprises three primary Istio services: Pilot, Mixer, and Auth.
Pilot
The Pilot is responsible for managing the overall fleet and all of your microservices running across your Kubernetes/OpenShift cluster. The Istio Pilot is responsible for ensuring that each of the independent and distributed microservices, wrapped as Linux containers and inside their pods, has the current view of the overall topology and an up-to-date “routing table.” Pilot provides capabilities like service discovery as well as support for RouteRule and DestinationPolicy. The RouteRule is what gives you that finely grained request distribution. We cover this in more detail in Chapter 3. The DestinationPolicy helps you to address resiliency with timeouts, retries, circuit breaker, and so on. We discuss DestinationPolicy in Chapter 4.
Mixer
As the name implies, Mixer is the Istio service that brings things together. Each of the distributed istio-proxies delivers its telemetry back to Mixer. Furthermore, Mixer maintains the canonical model of the usage and access policies for the overall suite of microservices or pods. With Mixer, you can create ACLs (whitelist and blacklist), you can apply rate-limiting rules, and even capture custom metrics. Mixer has a pluggable backend architecture that is rapidly evolving with new plug-ins and partners that will be extending Mixer’s default capabilities in many new and interesting ways. Many of the capabilities of Mixer fall beyond the scope of this book, but we do address observability in Chapter 6, and security in Chapter 7.
If you would like to explore Mixer further, refer to the upstream project documentation as well as the Istio Tutorial for Java Microservices maintained by the Red Hat team.
Auth
The Istio Auth component, also known as Istio CA, is responsible for certificate signing, certificate issuance and revocation/rotation. Istio issues x509 certificates to all your microservices, allowing for mutual Transport Layer Security (mTLS) between those services, encrypting all their traffic transparently. It uses identity built into the underlying deployment platform and builds that into the certificates. This identity allows you to enforce policy.
Get Introducing Istio Service Mesh for Microservices now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

