At this point, I want to diverge from the beaten path. So far, I’ve detailed everything that’s in a “standard” SAX application, from the reader to the callbacks to the handlers. However, there are a lot of additional features in SAX that can really turn you into a power developer, and take you beyond the confines of “standard” SAX. In this section, I’ll introduce you to two of these: SAX filters and writers. Using classes both in the standard SAX distribution and available separately from the SAX web site (http://www.megginson.com/SAX), you can add some fairly advanced behavior to your SAX applications. This will also get you in the mindset of using SAX as a pipeline of events, rather than a single layer of processing. I’ll explain this concept in more detail, but suffice it to say that it really is the key to writing efficient and modular SAX code.
First
on the list is a class that comes in the basic SAX download from
David Megginson’s site, and should be included with any parser
distribution supporting SAX 2.0. The class in question here is
org.xml.sax.XMLFilter. This class extends the
XMLReader interface, and adds two new
methods to that
class:
public void setParent(XMLReader parent); public XMLReader getParent( );
It might not seem like there is much to say here; what’s the
big deal, right? Well, by allowing a hierarchy of
XMLReader
s through this filtering
mechanism, you can build up a processing chain, or
pipeline
,
of events. To understand what I mean by a pipeline, here’s the
normal flow of a SAX
parse:
Events in an XML document are passed to the SAX reader.
The SAX reader and registered handlers pass events and data to an application.
What developers started realizing, though, is that it is simple to insert one or more additional links into this chain:
Events in an XML document are passed to the SAX reader.
The SAX reader performs some processing and passes information to another SAX reader.
Repeat until all SAX processing is done.
Finally, the SAX reader and registered handlers pass events and data to an application.
It’s the middle steps that introduce a pipeline, where one
reader that performed specific processing passes its information on
to another reader, repeatedly, instead of having to lump all code
into one reader. When this pipeline is set up with multiple readers,
modular and efficient programming results. And that’s what the
XMLFilter class allows for: chaining of
XMLReader implementations through filtering.
Enhancing this even further is the class
org.xml.sax.helpers.XMLFilterImpl
,
which provides a helpful implementation of
XMLFilter. It is the convergence of an
XMLFilter and the
DefaultHandler class I showed you in the last
section; the XMLFilterImpl class implements
XMLFilter, ContentHandler,
ErrorHandler, EntityResolver,
and DTDHandler, providing pass-through versions of
each method of each handler. In other words, it sets up a pipeline
for all SAX events, allowing your code to override any methods that
need to insert processing into the pipeline.
Let’s use one of these filters. Example 4-5 is a working, ready-to-use filter. You’re past the basics, so we will move through this rapidly.
Example 4-5. NamespaceFilter class
package javaxml2;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.XMLFilterImpl;
public class NamespaceFilter extends XMLFilterImpl {
/** The old URI, to replace */
private String oldURI;
/** The new URI, to replace the old URI with */
private String newURI;
public NamespaceFilter(XMLReader reader,
String oldURI, String newURI) {
super(reader);
this.oldURI = oldURI;
this.newURI = newURI;
}
public void startPrefixMapping(String prefix, String uri)
throws SAXException {
// Change URI, if needed
if (uri.equals(oldURI)) {
super.startPrefixMapping(prefix, newURI);
} else {
super.startPrefixMapping(prefix, uri);
}
}
public void startElement(String uri, String localName,
String qName, Attributes attributes)
throws SAXException {
// Change URI, if needed
if (uri.equals(oldURI)) {
super.startElement(newURI, localName, qName, attributes);
} else {
super.startElement(uri, localName, qName, attributes);
}
}
public void endElement(String uri, String localName, String qName)
throws SAXException {
// Change URI, if needed
if (uri.equals(oldURI)) {
super.endElement(newURI, localName, qName);
} else {
super.endElement(uri, localName, qName);
}
}
}I start out by extending XMLFilterImpl, so I
don’t have to worry about any events that I don’t
explicitly need to change; the XMLFilterImpl class
takes care of them by passing on all events unchanged unless a method
is overridden. I can get down to the business of what I want the
filter to do; in this case, that’s changing a namespace URI
from one to another. If this task seems trivial, don’t
underestimate its usefulness. Many times in the last several years,
the URI of a namespace for a specification (such as XML Schema or
XSLT) has changed. Rather than having to hand-edit all of my XML
documents or write code for XML that I receive, this
NamespaceFilter takes care of the problem for me.
Passing an XMLReader instance to the constructor
sets that reader as its parent, so the parent reader receives any
events passed on from the filter (which is all events, by virtue of
the XMLFilterImpl class, unless the
NamespaceFilter class overrides that behavior). By
supplying two URIs, the original and the URI to replace it with, you
set this filter up. The three overridden methods handle any needed
interchanging of that URI. Once you have a filter like this in place,
you supply a reader to it, and then operate upon the
filter, not the reader.
Going back to contents.xml and
SAXTreeViewer, suppose that O’Reilly has
informed me that my book’s online URL is no longer http://www.oreilly.com/javaxml2, but
http://www.oreilly.com/catalog/javaxml2.
Rather than editing all my XML samples and uploading them, I can just
use the NamespaceFilter class:
public void buildTree(DefaultTreeModel treeModel,
DefaultMutableTreeNode base, String xmlURI)
throws IOException, SAXException {
// Create instances needed for parsing
XMLReader reader =
XMLReaderFactory.createXMLReader(vendorParserClass);
NamespaceFilter filter =
new NamespaceFilter(reader,
"http://www.oreilly.com/javaxml2",
"http://www.oreilly.com/catalog/javaxml2");
ContentHandler jTreeContentHandler =
new JTreeContentHandler(treeModel, base, reader);
ErrorHandler jTreeErrorHandler = new JTreeErrorHandler( );
// Register content handler
filter.setContentHandler(jTreeContentHandler);
// Register error handler
filter.setErrorHandler(jTreeErrorHandler);
// Register entity resolver
filter.setEntityResolver(new SimpleEntityResolver( ));
// Parse
InputSource inputSource =
new InputSource(xmlURI);
filter.parse(inputSource);
}Notice, as I said, that all operation occurs upon the filter, not the
reader instance. With this filtering in place, you can compile both
source files (NamespaceFilter.java and
SAXTreeViewer.java), and run the viewer on the
contents.xml file. You’ll see that the
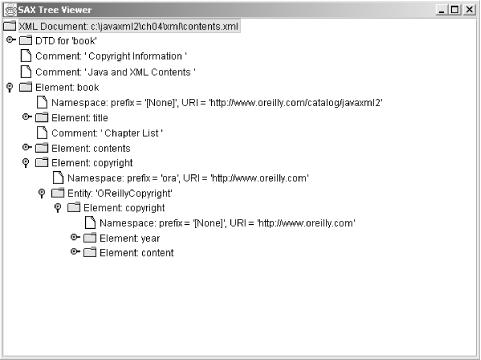
O’Reilly namespace URI for my book is changed in every
occurrence, shown in Figure 4-2.
Of course, you can chain these filters together as well, and use them as standard libraries. When I’m dealing with older XML documents, I often create several of these with old XSL and XML Schema URIs and put them in place so I don’t have to worry about incorrect URIs:
XMLReader reader =
XMLReaderFactory.createXMLReader(vendorParserClass);
NamespaceFilter xslFilter =
new NamespaceFilter(reader,
"http://www.w3.org/TR/XSL",
"http://www.w3.org/1999/XSL/Transform");
NamespaceFilter xsdFilter =
new NamespaceFilter(xslFilter,
"http://www.w3.org/TR/XMLSchema",
"http://www.w3.org/2001/XMLSchema");Here, I’m building a longer pipeline to ensure that no old namespace URIs sneak by and cause my applications any trouble. Be careful not to build too long a pipeline; each new link in the chain adds some processing time. All the same, this is a great way to build reusable components for SAX.
Now that you understand how filters work in SAX, I want to introduce
you to a specific filter,
XMLWriter
.
This class, as well as a subclass of it,
DataWriter
,
can be downloaded from David Megginson’s SAX site at
http://www.megginson.com/SAX.
XMLWriter extends
XMLFilterImpl, and DataWriter
extends XMLWriter. Both of these filter classes
are used to output XML, which may seem a bit at odds with what
you’ve learned so far about SAX. However, just as you could
insert statements that output to Java Writers in
SAX callbacks, so can this class. I’m not going to spend a lot
of time on this class, because it’s not really the way you want
to be outputting XML in the general sense; it’s much better to
use DOM, JDOM, or another XML API if you want mutability. However,
the XMLWriter class offers a valuable way to
inspect what’s going on in a SAX pipeline. By inserting it
between other filters and readers in your pipeline, it can be used to
output a snapshot of your data at whatever point it resides in your
processing chain. For example, in the case where I’m changing
namespace URIs, it might be that you want to actually store the XML
document with the new namespace URI (be it a modified O’Reilly
URI, a updated XSL one, or the XML Schema one) for later use. This
becomes a piece of cake by using the XMLWriter
class. Since you’ve already got
SAXTreeViewer using the
NamespaceFilter, I’ll use that as an
example. First, add import statements for
java.io.Writer (for output), and the
com.megginson.sax.XMLWriter class. Once
that’s in place, you’ll need to insert an instance of
XMLWriter between the
NamespaceFilter and the
XMLReader instances; this means output will occur
after namespaces have been changed but before the visual events
occur. Change your code as shown here:
public void buildTree(DefaultTreeModel treeModel,
DefaultMutableTreeNode base, String xmlURI)
throws IOException, SAXException {
// Create instances needed for parsing
XMLReader reader =
XMLReaderFactory.createXMLReader(vendorParserClass);
XMLWriter writer =
new XMLWriter(reader, new FileWriter("snapshot.xml"));
NamespaceFilter filter =
new NamespaceFilter(writer,
"http://www.oreilly.com/javaxml2",
"http://www.oreilly.com/catalog/javaxml2");
ContentHandler jTreeContentHandler =
new JTreeContentHandler(treeModel, base, reader);
ErrorHandler jTreeErrorHandler = new JTreeErrorHandler( );
// Register content handler
filter.setContentHandler(jTreeContentHandler);
// Register error handler
filter.setErrorHandler(jTreeErrorHandler);
// Register entity resolver
filter.setEntityResolver(new SimpleEntityResolver( ));
// Parse
InputSource inputSource =
new InputSource(xmlURI);
filter.parse(inputSource);
}Be sure you set the parent of the NamespaceFilter
instance to be the XMLWriter, not the
XMLReader. Otherwise, no output will actually
occur. Once you’ve got these changes compiled in, run the
example. You should get a snapshot.xml file created in the directory
you’re running the example from; an excerpt from that document
is shown here:
<?xml version="1.0" standalone="yes"?>
<book xmlns="http://www.oreilly.com/catalog/javaxml2">
<title ora:series="Java"
xmlns:ora="http://www.oreilly.com">Java and XML</title>
<contents>
<chapter title="Introduction" label="1">
<topic name="XML Matters"></topic>
<topic name="What's Important"></topic>
<topic name="The Essentials"></topic>
<topic name="What's Next?"></topic>
</chapter>
<chapter title="Nuts and Bolts" label="2">
<topic name="The Basics"></topic>
<topic name="Constraints"></topic>
<topic name="Transformations"></topic>
<topic name="And More..."></topic>
<topic name="What's Next?"></topic>
</chapter>
<!-- Other content... -->
</contents>
</book>Notice that the namespace, as changed by
NamespaceFilter, is modified here. Snapshots like
this, created by XMLWriter instances, can be great
tools for debugging and logging of SAX events.
Both XMLWriter and DataWriter
offer a lot more in terms of methods to output XML, both in full and
in part, and you should check out the Javadoc included with the
downloaded package. I do not encourage you to use these classes for
general output. In my experience, they are most useful in the case
demonstrated here.
Get Java and XML, Second Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

