Chapter 1. Elements of Database Applications
If Life is a Tree, it could have arisen from an inexorable, automatic rebuilding process in which designs would accumulate over time.
Once upon a time, database programming on the Java platform was an exercise in native programming; nothing existed within the Java platform to support database programming efforts. The first tool in the database programming arsenal arrived in March 1996 in the form of Java’s first proposed enterprise API, JDBC. JDBC enabled application developers to use a single API to access any database from any vendor.
JDBC, however, is the start—not the end—of database programming. JDBC simply enables you to access a database; it does not address all elements of database programming. It does not:
Ensure your database meets the need of your application
Automate the mapping of Java classes into relational entities
Provide a model for structuring your Java components
Manage application transactions
This book is about database programming; it is not about JDBC. However, because JDBC plays such a critical role in database programming, it will play a critical role in this book. If you need to brush up on your JDBC skills, take a look at the tutorial in Chapter 11 or my earlier book, Database Programming with JDBC and Java (O’Reilly). This book addresses all of the elements of database programming and their respective roles in supporting real world database applications.
Database Application Architectures
Database applications require an entire network of software in order to function. Even the most basic of database applications—the command-line SQL tool—is a complex system involving the database engine and a separate client utility. Architecture is the space in which all of the elements of an application operate. Before we look at each of those elements, we should first take a look at the space itself.
Architecture identifies the hardware and software necessary to support an application and specifies how those tools communicate within a network. When referring to architecture, different people tend to have different things in mind. In some cases, architecture refers to the way hardware is placed on a physical network. This kind of architecture is called network architecture. Other times, however, architecture refers to the system architecture—the way different logical and physical components work together to create a complex network application. The last kind of architecture is software architecture, when architecture refers to the design of one of the pieces of software that make up the system architecture.
The Network Architecture
The network architecture focuses on hardware issues and how they connect to one another. The quality of your network architecture affects security and bandwidth and limits the ability of your applications to talk with different parts of the system. Figure 1-1 is a simple network architecture diagram.

It shows how the network separates the Internet from the network in which the web server runs with a firewall. Similarly, this network diagram places the database server in a separate network segment, again separated by a firewall. In spite of the fact that very little about network architecture is specific to database applications, it can make a significant impact on the performance of those applications. It is therefore helpful to understand those aspects most relevant to database systems.
Network segmentation
Segmentation is the way in which the network is divided for performance and security. Routers, bridges, and firewalls are all tools of network segmentation.
The first rule of segmentation is to divide your network into regions of equal hostility and sensitivity. Hostility describes the attitude of people with access to a given network segment. The Internet, for example, is considered an extremely hostile network. Your home network—assuming you have no children—is conversely minimally hostile.
Sensitivity represents the risk profile of the data within a network segment. A high-risk profile means that public exposure or destruction of the data can cause significant harm. A sensitive network segment is therefore one that houses data that must be kept private at all costs. IRS database servers have a very high degree of sensitivity, whereas a Quake server ranks on the low end.
Note
BEST PRACTICE: Place your database servers on a high-sensitivity, low-hostility network segment. In other words, you should never place a database server directly on the Internet or a network segment that is even routable to the Internet.
If two software components have very different levels of sensitivity, they should be on different network segments separated by firewalls that limit the interaction between their networks. Because databases serve as primary data storage points, they tend to have higher sensitivity profiles than other software components. As a good general rule of thumb, database servers should be protected in a high-security network segment. In Figure 1-1, for example, a firewall separates the web server from the database server.
Bandwidth
Databases are the fountain from which data streams to all kinds of applications on the network. It is therefore critical—especially for high-volume database servers—to allocate the necessary bandwidth to database servers. It is not uncommon for database servers to be connected to the network through multiple fiber-based gigabit Ethernet ports.
Proper bandwidth also means paying attention to issues other than the raw size of your pipe. A good network architect also structures the topology of the network to minimize packet collisions and bring the database network as close as possible to the other networks that rely on the databases.
Hardware
Database engines are among the most resource-intensive applications commonly found in business environments. Solid performance for database applications demands the proper hardware for all parts of the application. If you were to choose only one thing to spend money on, you should spend it on RAM. Running a very close second to RAM in importance, however, is disk access speed.
Note
BEST PRACTICE: When selecting hardware for database servers, spend your money on RAM and high-speed disk access.
Ultimately, a database will run faster if it can cache a lot of data in RAM. Ideally, you have more memory for your database engine than you have data. In reality, however, that much memory is rarely possible. Good database performance therefore needs a solid array of disks. Though SCSI disks are the ideal, a RAID of IDE disks can support a web site’s database just fine. The disks should then be divided into at least three sets of responsibilities:
It is even better if your database engine enables you to split up tables and indexes on different disks. You want the database tables and indexes on the fastest drives you have available.
Various System Architectures
The role of the system architect is to look at the overall technology objectives of an organization and establish a system architecture that maximizes the reuse of critical components. A simple web application can work well in any number of different system architectures; it works best, however, when it fits nicely with the other applications in that architecture. For example, you can build an excellent web application using Perl and MySQL. If the organization you are building it for, however, has an established J2EE (Java 2 Enterprise Edition) infrastructure with an Oracle backend, you are introducing new components requiring maintenance that cannot be easily integrated into that organization’s existing environment.
The starting point for determining an appropriate system architecture is to understand the basic enterprise platform for the organization. Because I am covering database programming in a J2EE environment, I will assume your basic enterprise platform is J2EE. Alternatives include .NET and general web services. These platforms all come with basic approaches to different kinds of architectural requirements. In this section, I will briefly discuss the different system architectures that fit inside the J2EE platform.
Note
BEST PRACTICE: Develop architectural principles and use them as the basis for all technology decisions for your application.
The client/server architecture
The client/server architecture is one of the oldest distributed computing architectures in use on the J2EE platform. You will sometimes hear people refer to the client/server architecture as a two-tier architecture. The term two-tier describes the way in which application processing can be divided in a client/server application. A two-tier application ideally provides multiple workstations with a uniform presentation layer that communicates with a centralized database. The presentation layer is generally the client, and the database layer is the server.
Figure 1-2 shows how two-tier systems provide clients with access to centralized data. A client like a Java Swing application talks directly to a database and displays the data in the user interface.
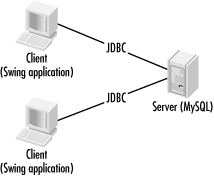
A client/server architecture is definitely appropriate for some applications. Specifically, any application that must deal directly with the database needs to be a client/server application. For example, the command-line tools that enable you to enter arbitrary SQL statements are client/server applications that fit this profile. In fact, just about any database administration tool is a good candidate for a client/server architecture.
A client/server architecture falls apart, however, when application logic needs to operate on the data from the database or when application logic needs to be shared among multiple clients. The client/server architecture suffers specifically from the following problems:
- The fat client
Perhaps you have seen a client/server application evolve over time to include more and more application logic operating on data from the database. Ideally, the client/server architecture is supposed to let each machine do only the processing relevant to its specialization—graphical presentation of data on the client and the storage and retrieval of data on the server. This breakdown, however, does not clearly provide a place for application logic—also known as business logic. As more and more business logic ends up in the client, you end up with a problem known as the fat client. Fat client systems are notorious for their inability to adapt to changing environments and scale with growing user and data volume.
- Object reuse
Object reuse[1] is a very vague, yet central concept to object-oriented software engineering. You can reuse code through cutting and pasting or through linking either statically or dynamically to an API, or you can reuse shared object instances. The ideal form of reuse is to reuse shared object instances among applications. Of course, that requires a single point of focus for applications. Only the database is shared under the two-tier model. In order to reuse object instances, you need to embed them in the server—and create a fat server—or move to a different architecture.
As I mentioned before, in spite of its shortcomings, a two-tier architecture does have a place in application development. In addition to applications tied directly to the database, simple applications with immediate deadlines and no maintenance or reuse requirements are prime candidates. The following checklist provides important questions to ask before committing yourself to a two-tier design. If you can answer “yes” to each of the questions in the checklist, then a two-tier architecture is likely your best solution. Otherwise, you should consider one of the other architectures supported by the J2EE platform.
Does your application emphasize time-to-market over architecture?
Does your application use a single database?
Is your database engine located on a single host?
Is your database likely to stay approximately the same size over time?
Is your user base likely to stay approximately the same size over time?
Is there no web interface to your application?
Are your requirements fixed with little or no possibility of change?
Do you expect minimal maintenance after you deliver the application?
The simple web site architecture
Perhaps the simplest—and most familiar—architecture to Internet developers is that of the simple web site. Figure 1-3 shows the simple web site architecture with a page generation technology like JSPs (JavaServer Pages) or servlets talking directly to a database engine. In short, this is the web equivalent to the client/server architecture. Its critical difference is that an intermediate tier is structuring the data for display and providing it to the client.

In general, all of the faults of the client/server architecture apply to this architecture. It does, however, provide some flexibility on the display side. You can use the web server as the location for your shared object access. Unfortunately, you cannot access the objects directly; you must access them through the display information provided by the web server. The advantage this architecture has over the pure client/server architecture is that you can now provide multiple views of the same object instances. Unfortunately, these views must be browser-based and have roughly the same content.
Peer-to-peer
Peer-to-peer (P2P) is a new name for an old architecture. Every other architecture presented in this book seeks to break processing down into specialized tiers that handle one kind of application processing. The peer-to-peer architecture still has physical divisions among different kinds of logic, but it hides those divisions behind an egalitarian logical façade. Under the P2P architecture, all logical players can perform all tasks.
Figure 1-4 shows how the P2P architecture divides the network into equal nodes. Each node is capable of making direct contact with any other node and requesting services from that node. Similarly, each node is capable of providing services to any other node.
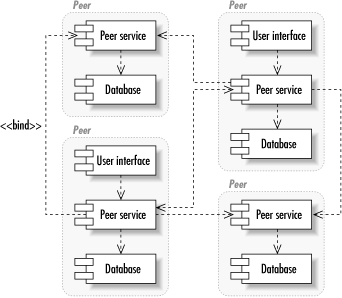
Within a P2P node, the system can be performing any number of tasks. One of the beauties of the P2P architecture is that the details of how a given node is providing its services are completely hidden from the other nodes. You could, for example, implement a P2P auction network in which one node consisted of a database server and a GUI and another node consisted of flat files and a command-line utility.
Another advantage of a P2P architecture is that there’s no single point of failure. Assuming the problem domain is appropriate to P2P, the failure of any one node—or even a large group of nodes—doesn’t affect the functionality of the system built on top of the architecture. The remaining nodes simply seek services from one another.
In reality, the development of a scalable P2P system is quite a challenge. No one has truly gotten this right yet. Pure P2P networks like Gnutella suffer from serious scalability issues and an inability of many nodes to actually request services from other nodes. Other P2P systems like the infamous Napster compromise on the P2P architecture and thus compromise on its advantages. Napster created a single point of failure for the network and thus ceased to exist in a meaningful sense when that point of failure was shut down.
You should consider a P2P architecture under the following conditions:
You need massive failover capabilities.
Replication of services to all nodes is practical.
The source of services is not important—i.e., no security or trust issues exist.
Distributed architectures
Logic in distributed architectures is divided among any number of specialized tiers for handling that data. The number of tiers runs well beyond the extra tier demanded by client/server for business logic. Distributed architectures include tiers for business logic, content services, and everything else you can imagine.
Like the P2P architecture, distributed architectures are logical in that they provide for a high-level division of labor among the following tiers:
- User interface layer
The user interface (UI) layer is responsible for all direct user interaction. A physical implementation of the UI layer could consist of a web browser or be a combination of browser, command-line, and Swing applications.
- Content generation layer
The content generation layer is responsible for structuring content for display to the UI layer and subsequently routing user input. It is generally a web server or cluster of web servers using static and dynamic content generation tools to pull content from a content management layer.
- Content management layer
The content management layer stores content from structuring and transmission to a UI. It includes content management systems and digital asset management systems.
- Web services layer
Whereas the content generation layer serves content to human users, the web services layer serves it to other applications. It is the integration point for modern applications across a LAN (Local Area Network). It exchanges messages with web services clients using open standards like XML (Extensible Markup Language).
- Business logic layer
Business objects in the business logic layer execute business logic on behalf of web services and users. It serves as a shared point for all business logic within an organization.
- Integration services layer
The integration services layer ties modern applications to their legacy counterparts through tools like enterprise messaging services and proprietary APIs.
- Data storage
This layer is where the database sits. In a real enterprise, the data storage layer consists of many different databases serving up various kinds of data.
Figure 1-5 shows an architecture for distributed applications.
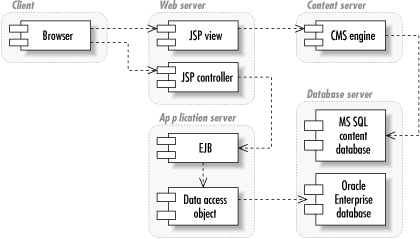
When you are writing EJB (Enterprise JavaBeans) applications, you’re using a distributed architecture. How many of the layers you use depends on the needs of your application. Regardless of how many layers you use, this architecture is definitely the most complex architecture covered in this book. Unlike the P2P architecture, no level of generality hides the physical services behind each layer. The business logic layer seeking data storage services knows what kind of data storage services it seeks.
Though a distributed architecture provides many advantages over other architectures, it is not without its drawbacks. I have already mentioned the complexity it adds to a system. It is also hard to find system architects proficient in all layers of a distributed application architecture. Though the J2EE platform attempts to mitigate these issues, it does not mitigate them completely.
Software Architecture
Software architecture describes the internal design of a software component. It identifies the classes that make up the piece of software and what processes those classes support. Standard software development methodologies provide for two common views of a software architecture: a static view and a behavioral view. Figure 1-6 is a UML (Unified Modeling Language)[2] class diagram that serves as the static view, and Figure 1-7 is a UML sequence diagram providing the behavioral view.
In designing an application, you need to pick out design patterns that will provide a level of reliability to its underlying logic. The first step to identifying the design patterns is identifying problems in generic terms. In database programming, you need design patterns to support persistence and encapsulation of business logic.
Over the course of this book, we will encounter many different design patterns. In this section, my goal is simply to provide an overview of these patterns. If you do not fully understand them after this section, you should not be concerned. I will be talking in more detail about each of them later.
User interface patterns
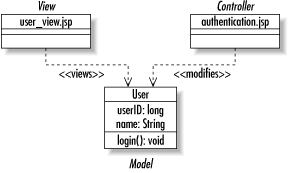
The UI provides a view of the system specific to the role of the user in question. Good UI patterns help keep the user interface decoupled from the server. Though to some degree UI patterns depend on the UI technology, there are also some generic patterns like the model-view-controller pattern that serve any form of UI.
The model-view-controller pattern.
Java Swing is based entirely on a very important UI pattern called the model-view-controller pattern (MVC). In fact, this key design pattern is what makes Java so perfect for distributed enterprise development. The MVC pattern separates a GUI component’s visual display (the view) from the thing it is a view of (the model) and the way in which the user interacts with the component (the controller).
In a client/server application that displays the rows from a database table in a Swing display, for example, the database serves as the model. In this application, the columns and rows of the Swing table match the columns and rows of the database table. The Swing table is the view. The controller is a less obvious object that handles user mouse clicks and key presses and determines what the model or view should do in response to those user actions.
Swing actually uses a variant of this pattern called the model-delegate pattern. The model-delegate pattern combines the view and the controller into a single object that delegates to its model.
Note
BEST PRACTICE: Use the MVC paradigm or a variation on the MVC paradigm in all applications with user interface needs.
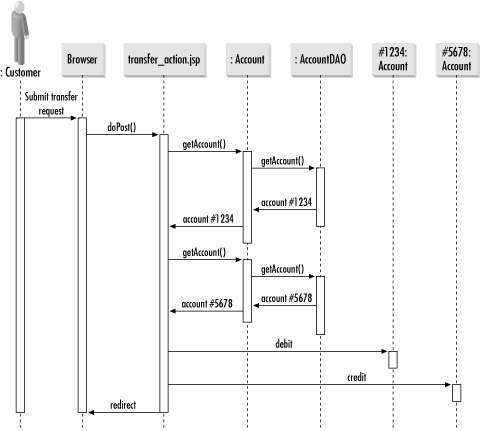
The MVC pattern is not limited to Swing applications. It is also the preferred way of building the HTML (Hypertext Markup Language) pages for web applications. Figure 1-8 illustrates the MVC pattern in a JSP-based web application. In this case, the JSP page is the view, the servlet the controller, and the EJB or JavaBean the model.
The listener pattern.
For the Swing example of MVC, it would be nice if the view could be told about any changes to the model. The listener pattern provides a mechanism by which interested parties are notified of events in other objects. You have probably seen this pattern in Swing development as well.
The listener pattern enables one object to listen to specific events
that occur to another object. A common listener in the JavaBeans
component model is something called a
PropertyChangeListener. One object can declare
itself a PropertyChangeListener by implementing
the java.beans.PropertyChangeListener interface.
It then tells other objects that it is interested in property changes
by calling the addPropertyChangeListener( ) method
in any JavaBean it cares about. The important part of this pattern is
that the object being listened to needs to know nothing about its
listeners except that those objects want to know when a property has
changed. Consequently, you can design objects that live well beyond
the uses originally intended for them.
Business patterns
As a general rule, the midtier business logic is likely to use just about every design pattern in common use. The two most common general patterns I have encountered are the composite and factory patterns. More important to the business logic, however, is the component model.
The component model defines the standards you rely on for encapsulating your application logic. Java has two major component models: JavaBeans and Enterprise JavaBeans. JavaBeans defines a contract between applications and their components that tells applications how to find out what attributes are supported by a component and how to trigger that component’s behavior. Enterprise JavaBeans takes the basic contract of JavaBeans into the realm of distributed computing. EJB provides for communication among components across a network, the ability to search for components, and the ability to include components in transactions.
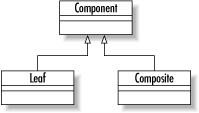
The composite pattern.
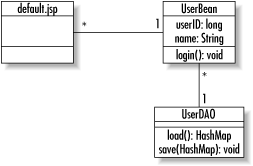
The composite pattern appears everywhere in the real world. It represents a hierarchy in which some type of object may both be contained by similar objects and contain similar objects. Figure 1-9 shows a UML diagram describing the composite pattern.
Note
BEST PRACTICE: Look carefully for the composite pattern in the problems you are modeling. It appears everywhere in problem domains.
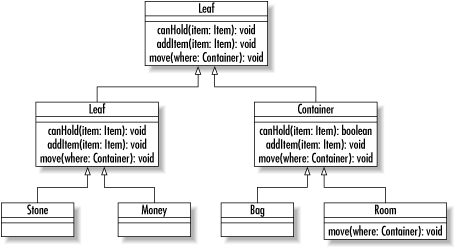
To put a more concrete face on the composite pattern, think of a
virtual reality game that attempts to model your movements through a
maze. In your game, you might have a Room class
that can contain Item objects. Some of those
Item objects (like a bag) can contain other
Item objects. Your room is a container, and bags
are containers. On the other hand, things like money and stones
cannot contain anything. To complicate matters further, the room
cannot be contained by anything greater than it. The result is the
class diagram in Figure 1-10.
The factory pattern.
Another common pattern found in the core Java libraries is the
factory pattern. The pattern encapsulates the creation of objects
behind a single interface. Java
internationalization support is peppered with implementations of the
factory design pattern. The
java.util.ResourceBundle class, for example,
contains logic that enables you to find a bundle of resources for a
specific locale without having to know which subclass of
ResourceBundle is the right one to instantiate. A
ResourceBundle is an object that might contain
translations of error messages, menu item labels, and text labels for
your application. By using a ResourceBundle, you
can create an application that will appear in French to French users,
in German to German users, and in English to English and American
users.
Because of the factory pattern, using a
ResourceBundle is quite easy. To create a Save
button, for example, you might have the following code:
ResourceBundle bundle =
ResourceBundle.getBundle("labels", Locale.getDefault( ));
Button button = new Button(bundle.getString("SAVE"));This code actually shows two factory methods:
Locale.getDefault( ) and
ResourceBundle.getBundle( ).
Locale.getDefault( ) constructs a
Locale instance representing the locale in which
the application is running.
The goal of this pattern is to capture the creation logic of certain
objects in a single method. The benefit of providing a single
location for that logic is that the logic can vary without impacting
applications that rely on those classes. Sun Microsystems, for
example, could change the getBundle( ) method to
look for XML-based property bundles as well as traditional Java
property bundles without any impact to the masses of legacy Java
systems.
Persistence patterns
One key to smooth development in a distributed architecture is providing a clear division between data storage code and business logic code. At some point, a business object needs to save itself to a data store. You will chose a persistence model that supports the persistence of your business components. The goal is to make sure that the business object knows nothing about how it is stored in the database—in fact, it should not even know that its persistence form is a database.
The form of your persistence model will determine the underlying pattern you use. Later in the book, we will get into a custom persistence model based on the data access object pattern.
The data access object pattern.
The data access object pattern—also referred to as the persistence delegate pattern—relies on a delegate to make a component persistent. Each business component sees generic methods in its delegate for persistence operations like loading, creating, saving, and deleting the component. Behind those methods are implementations for a specific data storage technology and schema. In our case, the data storage technology is a relational database.
Note
BEST PRACTICE: Use the data access object pattern in your database applications. It is a key aspect of most of the chapters in this book. I describe it in greater detail in Chapter 4.
The memento pattern.
In the persistence delegate pattern, how does the persistence delegate know about the state of the object it is persisting? You could pass the object to the persistence methods, but that action requires your delegate to know a lot more about the objects it supports that you probably want. Another design pattern—the memento pattern—comes to the rescue here.
A memento is a tool for capturing an object’s state and safely passing it around. The advantage of the memento pattern is that it enables you to modify the components and the delegates independently. A change to the component has no effect on the delegate and a change to the delegate has no effect on the component. The persistence handler knows only how to get the data it needs to support the underlying data storage schema from the memento. I provide a concrete implementation of the memento pattern later in the book.
Component Models
We have already touched a bit on component models. A component model defines the various aspects of encapsulating business logic in software. The Java platform provides two major component models:
The JavaBeans component model
The Enterprise JavaBeans component model
Enterprise JavaBeans work well only in distributed architectures and the P2P architecture. JavaBeans, on the other hand, work in any architecture. If you use JavaBeans in a distributed architecture, however, you will have to write your own logic to support interprocess communication, security, transaction management, and other functionality that comes free with EJBs.
JavaBeans
The JavaBeans specification defines the way in which you should write your components so they can be used by other components and application elements. When you write JavaBeans, applications that know nothing about those beans can still use them. One example of JavaBeans in action is the development of JSP tag libraries. Your tag handlers are JavaBeans components. A JSP container can access the properties in your tag library because the way in which you write those properties uses standard getter and setter methods defined by the JavaBeans specification.
The beauty of the JavaBeans specification is its simplicity. To
conform to it, you need only write your
getters and setters using standard
getXXX( ) and setXXX( ) method
calls. You can optionally implement listener support to enable
applications to listen for changes in properties. There is really
nothing much more to the component model.
Just as simplicity is JavaBeans advantage, it is also its disadvantage. The JavaBeans specification does not provide for many of the following pieces necessary in distributed architectures:
- Transaction support
Transaction support enables your components to put in database transactions without requiring a programmer to worry about when to start and end the transaction. If you want transaction support with JavaBeans, you need to write your own transaction logic.
- Distributed access
Distributed access provides direct access to your component through some distributed component model—RMI, CORBA, EJB, DCOM, etc. Because JavaBeans is not a distributed component model, you have to manually combine your JavaBeans with another component model—generally, RMI—for exporting components.
- Security
If you make your components available over a network, you need a mechanism for securing them against unauthorized access. If you are using JavaBeans, you will have to write your own code to authenticate clients and authorize their component access.
- Persistence management
Persistence management automatically maps your components to a data store. In other words, with a component model that provides persistence management, you never have to write any JDBC code. JavaBeans, however, requires you to become quite familiar with JDBC in order to save the state of the beans to a relational database.
- Searching
Searching enables applications to search for the components they need. Again, if you are using JavaBeans, you will have to write your own search methods and leverage JDBC queries to support component searching.
Enterprise JavaBeans
The Enterprise JavaBeans component model is basically a component model for distributed architectures. It provides many of the features lacking in JavaBeans at the cost of JavaBeans simplicity. Because the EJB component model handles all of these aspects of distributed component management, you can literally pick and choose the best-designed business components from different vendors and make them work and play well with one another in the same environment. EJB is now the standard component model for capturing distributed components on the Java platform. It hides from you the details you would have had to worry about with JavaBeans.
One of the benefits of the EJB approach is that it separates different application development roles into distinct parts so that the outputs of one role are usable in different environments by the players of the other roles. You can use your EJB container, for example, to house components written by third-party vendors or custom written by your team. Similarly, a JDBC service provider can deploy their JDBC drivers in any EJB container without impacting transaction management.
Figure 1-11 illustrates what it takes to code a single component under the EJB component model. You have the actual bean, the home interface, and a remote interface. When you deploy a bean in a container, the container creates implementations of your home and remote interfaces. Contrast all of this work with the simplicity of the JavaBeans component model. Not only do you write just one class, but what you see is what you get—nothing fancy happens out of your view.

Persistence Models
A persistence model dictates how your components persist themselves to a data store. The EJB component model, for example, comes with a built-in persistence model in the form of container-managed persistence. When you use the container-managed persistence model with Enterprise JavaBeans, you do not have to write a line of database access code. Instead, you specify a database mapping when you deploy the application through deployment configuration files. The EJB container manages the rest.
Other persistence models may perform all or part of the work necessary to implement component persistence. Over the course of this book, we will examine the most popular persistence models for both the JavaBeans and EJB component models.
EJB Persistence
Until recently, container-managed persistence in EJB has proven to be insufficient for most application development. Most EJB developers write their own persistence logic for their beans—a practice called bean-managed persistence. Bean-managed EJB programmers use some other persistence model when constructing their components. The full gamut of EJB-specific persistence models include:
- EJB 1.x CMP
This model is container-managed persistence (CMP) under the EJB 1.x specification. As I noted earlier, few people actually use this persistence model. It has difficulties with such basic persistence operations as searching and primary key management. It also does not provide a solid mapping of many-to-many relationships.
- BMP
Bean-managed persistence (BMP) is not itself a persistence model. It instead means that you are using some non-EJB persistence model for storage of your EJB components.
- EJB 2.x CMP
Because of the massive shortcomings of EJB 1.x CMP, EJB 2.0 introduced a new container-managed persistence model. Though it is not yet widely supported, it does promise to address the shortcomings of EJB 1.x CMP. To meet this challenge, however, it introduces a new query language. Because many alternative persistence models have evolved, it is unclear if EJB 2.x CMP will be accepted.
Other Persistence Models
Many persistence models have evolved both to address shortcomings in EJB persistence models and to support the persistence of non-EJB systems. If you have read my book Database Programming with JDBC and Java, then you have seen one such alternative persistence model. Among today’s most popular alternatives is Java Data Objects (JDO). We will examine JDO and my custom persistence model as well as several others over the course of this book.
Get Java Database Best Practices now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

