Chapter 1. Introducing I/O
Input and output, I/O for short, are fundamental to any computer operating system or programming language. Only theorists find it interesting to write programs that don’t require input or produce output. At the same time, I/O hardly qualifies as one of the more “thrilling” topics in computer science. It’s something in the background, something you use every day—but for most developers, it’s not a topic with much sex appeal.
But in fact, there are plenty of reasons Java programmers should find I/O interesting. Java includes a particularly rich set of I/O classes in the core API, mostly in the java.io
and java.nio
packages. These packages support several different styles of I/O. One distinction is between byte-oriented I/O, which is handled by input and output streams, and character-I/O, which is handled by readers and writers. Another distinction is between the old-style stream-based I/O and the new-style channel- and buffer-based I/O. These all have their place and are appropriate for different needs and use cases. None of them should be ignored.
Java’s I/O libraries are designed in an abstract way that enables you to read from external data sources and write to external targets, regardless of the kind of thing you’re writing to or reading from. You use the same methods to read from a file that you do to read from the console or from a network connection. You use the same methods to write to a file that you do to write to a byte array or a serial port device.
Reading and writing without caring where your data is coming from or where it’s going is a very powerful abstraction. Among other things, this enables you to define I/O streams that automatically compress, encrypt, and filter from one data format to another. Once you have these tools, programs can send encrypted data or write zip files with almost no knowledge of what they’re doing. Cryptography or compression can be isolated in a few lines of code that say, “Oh yes, make this a compressed, encrypted output stream.”
In this book, I’ll take a thorough look at all parts of Java’s I/O facilities. This includes all the different kinds of streams you can use and the channels and buffers that offer high-performance, high-throughput, nonblocking operations on servers. We’re also going to investigate Java’s support for Unicode. We’ll look at Java’s powerful facilities for formatting I/O. Finally, we’ll look at the various APIs Java provides for low-level I/O through various devices including serial ports, parallel ports, USB, Bluetooth, and other hardware you’ll find in devices that don’t necessarily look like a traditional desktop computer or server.
I won’t go so far as to say, “If you’ve always found I/O boring, this is the book for you!” I will say that if you do find I/O uninteresting, you probably don’t know as much about it as you should. I/O is the means for communication between software and the outside world. Java provides a powerful and flexible set of tools for doing this crucial part of the job. Having said that, let’s start with the basics.
What Is a Stream?
A stream is an ordered sequence of bytes of indeterminate length. Input streams move bytes of data into a Java program from some generally external source. Output streams move bytes of data from Java to some generally external target. (In special cases, streams can also move bytes from one part of a Java program to another.)
The word stream is derived from an analogy between a sequence and a stream of water. An input stream is like a siphon that sucks up water; an output stream is like a hose that sprays out water. Siphons can be connected to hoses to move water from one place to another. Sometimes a siphon may run out of water if it’s drawing from a finite source like a bucket. On the other hand, if the siphon is drawing water from a river, it may well operate indefinitely. So, too, an input stream may read from a finite source of bytes such as a file or an unlimited source of bytes such as System.in
. Similarly, an output stream may have a definite number of bytes to output or an indefinite number of bytes.
Input to a Java program can come from many sources. Output can go to many different kinds of destinations. The power of the stream metaphor is that the differences between these sources and destinations are abstracted away. All input and output operations are simply treated as streams using the same classes and the same methods. You don’t need to learn a new API for every different kind of device. The same API that reads files can read network sockets, serial ports, Bluetooth transmissions, and more.
Where Do Streams Come From?
The first source of input most programmers encounter is System.in. This is the same thing as stdin in C—generally some sort of console window, probably the one in which the Java program was launched. If input is redirected so the program reads from a file, then System.in is changed as well. For instance, on Unix, the following command redirects stdin so that when the MessageServer program reads from System.in, the actual data comes from the file data.txt instead of from the console:
% java MessageServer < data.txtThe console is also available for output through the static field out in the java.lang.System class, that is, System.out
. This is equivalent to stdout in C parlance and may be redirected in a similar fashion. Finally, stderr is available as System.err
. This is most commonly used for debugging and printing error messages from inside catch clauses. For example:
try {
//... do something that might throw an exception
}
catch (Exception ex) {
System.err.println(ex);
}Both System.out and System.err are print streams—that is, instances of java.io.PrintStream. These will be discussed in detail in Chapter 7.
Files are another common source of input and destination for output. File input streams provide a stream of data that starts with the first byte in a file and finishes with the last byte in that file. File output streams write data into a file, either by erasing the file’s contents and starting from the beginning or by appending data to the file. These will be introduced in Chapter 4.
Network connections provide streams too. When you connect to a web server, FTP server, or some other kind of server, you read the data it sends from an input stream connected from that server and write data onto an output stream connected to that server. These streams will be introduced in Chapter 5.
Java programs themselves produce streams. Byte array input streams, byte array output streams, piped input streams, and piped output streams all move data from one part of a Java program to another. Most of these are introduced in Chapter 9.
Perhaps a little surprisingly, GUI components like TextArea and JTextArea do not produce streams. The issue here is ordering. A group of bytes provided as data for a stream must have a fixed order. However, users can change the contents of a text area or a text field at any point, not just at the end. Furthermore, they can delete text from the middle of a stream while a different thread is reading that data. Hence, streams aren’t a good metaphor for reading data from GUI components. You can, however, use the strings they do produce to create a byte array input stream or a string reader.
The Stream Classes
Most of the classes that work directly with streams are part of the java.io package. The two main classes are java.io.InputStream
and java.io.OutputStream
. These are abstract base classes for many different subclasses with more specialized abilities.
The subclasses include:
BufferedInputStream
|
BufferedOutputStream
|
ByteArrayInputStream
|
ByteArrayOutputStream
|
DataInputStream
|
DataOutputStream
|
FileInputStream
|
FileOutputStream
|
FilterInputStream
|
FilterOutputStream
|
ObjectInputStream
|
ObjectOutputStream
|
PipedInputStream
|
PipedOutputStream
|
PrintStream
|
PushbackInputStream
|
SequenceInputStream
|
The java.util.zip
package contains four input stream classes
that read data in compressed format and return it in uncompressed format and four output stream classes that read data in uncompressed format and write in compressed format. These will be discussed in Chapter 10.
CheckedInputStream
|
CheckedOutputStream
|
DeflaterOutputStream
|
GZIPInputStream
|
GZIPOutputStream
|
InflaterInputStream
|
ZipInputStream
|
ZipOutputStream
|
The java.util.jar
package includes two stream classes for reading files from JAR archives. These will be discussed in Chapter 11.
JarInputStream
|
JarOutputStream
|
The java.security
package includes a couple of stream classes used for calculating message digests:
DigestInputStream
|
DigestOutputStream
|
The Java Cryptography Extension (JCE) adds two classes for encryption and decryption:
CipherInputStream
|
CipherOutputStream
|
These four streams will be discussed in Chapter 12.
Finally, a few random stream classes are hiding inside the sun packages—for example, sun.net.TelnetInputStream and sun.net.TelnetOutputStream. However, these are deliberately hidden from you and are generally presented as instances of java.io.InputStream or java.io.OutputStream only.
Numeric Data
Input streams read bytes and output streams write bytes. Readers read characters and writers write characters. Therefore, to understand input and output, you first need a solid understanding of how Java deals with bytes, integers, characters, and other primitive data types, and when and why one is converted into another. In many cases Java’s behavior is not obvious.
Integer Data
The fundamental integer data type in Java is the int, a 4-byte, big-endian, two’s complement integer. An int can take on all values between -2,147,483,648 and 2,147,483,647. When you type a literal integer such as 7, -8345, or 3000000000 in Java source code, the compiler treats that literal as an int. In the case of 3000000000 or similar numbers too large to fit in an int, the compiler emits an error message citing “Numeric overflow.”
long
s are 8-byte, big-endian, two’s complement integers that range all the way from -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807. long literals are indicated by suffixing the number with a lower- or uppercase L. An uppercase L is preferred because the lowercase l is too easily confused with the numeral 1 in most fonts. For example, 7L, -8345L, and 3000000000L are all 64-bit long literals.
Two more integer data types are available in Java, the short
and the byte. shorts are 2-byte, big-endian, two’s complement integers with ranges from -32,768 to 32,767. They’re rarely used in Java and are included mainly for compatibility with C.
bytes, however, are very much used in Java. In particular, they’re used in I/O. A byte is an 8-bit, two’s complement integer that ranges from −128 to 127. Note that like all numeric data types in Java, a byte is signed. The maximum byte value is 127. 128, 129, and so on through 255 are not legal values for bytes.
Java has no short or byte literals. When you write the literal 42 or 24000, the compiler always reads it as an int, never as a byte or a short, even when used in the right-hand side of an assignment statement to a byte or short, like this:
byte b = 42; short s = 24000;
However, in these lines, a special assignment conversion is performed by the compiler, effectively casting the int literals to the narrower types. Because the int literals are constants known at compile time, this is permitted. However, assignments from
int variables to shorts and bytes are not—at least not without an explicit cast. For example, consider these lines:
int i = 42; byte b = i;
Compiling these lines produces the following errors:
Error: Incompatible type for declaration. Explicit cast needed to convert int to short. ByteTest.java line 6
This occurs even though the compiler is theoretically capable of determining that the assignment does not lose information. To correct this, you must use explicit casts, like this:
int i = 42; byte b = (byte) i;
Even the addition of two byte variables produces an integer result and thus cannot be assigned to a byte variable without a cast. The following code produces the same error:
byte b1 = 22; byte b2 = 23; byte b3 = b1 + b2;
For these reasons, working directly with byte variables is inconvenient at best. Many of the methods in the stream classes are documented as reading or writing bytes. However, what they really return or accept as arguments are ints in the range of an unsigned byte (0–255). This does not match any Java primitive data type. These ints are then converted into bytes internally.
For instance, according to the Java class library documentation, the read( ) method of java.io.InputStream returns “the next byte of data, or −1 if the end of the stream is reached.” Upon reflection, this sounds suspicious. How is a −1 that appears as part of the stream data to be distinguished from a −1 indicating end of stream? In point of fact, the read( ) method does not return a byte; its signature shows that it returns an int:
public abstract int read( ) throws IOException
This int is not a Java byte with a value between −128 and 127 but a more general unsigned byte with a value between 0 and 255. Hence, −1 can easily be distinguished from valid data values read from the stream.
The write( )
method in the java.io.OutputStream class is similarly problematic. It returns void but takes an int as an argument:
public abstract void write(int b) throws IOException
This int is intended to be an unsigned byte value between 0 and 255. However, there’s nothing to stop a careless programmer from passing in an int value outside that range. In this case, the 8 low-order bits are written and the top 24 high-order bits are ignored:
b = b & 0x000000FF;
Tip
Although this is the behavior described in the Java Language Specification, since the write( ) method is abstract, actual implementation of this scheme is left to the subclasses, and a careless programmer could do something different.
On the other hand, real Java bytes are used in methods that read or write arrays of bytes. For example, consider these two read( ) methods from java.io.InputStream:
public int read(byte[] data) throws IOException public int read(byte[] data, int offset, int length) throws IOException
While the difference between an 8-bit byte and a 32-bit int is insignificant for a single number, it can be very significant when several thousand to several million numbers are read. In fact, a single byte still takes up four bytes of space inside the Java virtual machine, but a byte array occupies only the amount of space it actually needs. The virtual machine includes special instructions for operating on byte arrays but does not include any instructions for operating on single bytes. They’re just promoted to ints.
Although data is stored in the array as signed Java bytes with values between −128 and 127, there’s a simple one-to-one correspondence between these signed values and the unsigned bytes normally used in I/O. This correspondence is given by the following formula:
int unsignedByte = signedByte >= 0 ? signedByte : 256 + signedByte;
Conversions and Casts
Since bytes have such a small range, they’re often converted to ints in calculations and method invocations. Often, they need to be converted back, generally through a cast. Therefore, it’s useful to have a good grasp of exactly how the conversion occurs.
Casting from an int to a byte—for that matter, casting from any wider integer type to a narrower type—takes place through truncation of the high-order bytes. This means that as long as the value of the wider type can be expressed in the narrower type, the value is not changed. The int 127 cast to a byte still retains the value 127.
On the other hand, if the int value is too large for a byte, strange things happen. The int 128 cast to a byte is not 127, the nearest byte value. Instead, it is −128. This occurs through the wonders of two’s complement arithmetic. Written in hexadecimal, 128 is 0x00000080. When that int is cast to a byte, the leading zeros are truncated, leaving 0x80. In binary, this can be written as 10000000. If this were an unsigned number, 10000000 would be 128 and all would be fine, but this isn’t an unsigned number. Instead, the leading bit is a sign bit, and that 1 does not indicate 27 but a minus sign. The absolute value of a negative number is found by taking the complement (changing all the 1 bits to 0 bits and vice versa) and adding 1. The complement of 10000000 is 01111111. Adding 1, you have 01111111 + 1 = 10000000 = 128 (decimal). Therefore, the byte 0x80 actually represents −128. Similar calculations show that the int 129 is cast to the byte −127, the int 130 is cast to the byte −126, the int 131 is cast to the byte −125, and so on. This continues through the int 255, which is cast to the byte −1.
When 256 is reached, the low-order bytes of the int are filled with zeros. In other words, 256 is 0x00000100. Thus, casting it to a byte produces 0, and the cycle starts over. This behavior can be reproduced algorithmically with this formula, though a cast is obviously simpler:
int byteValue;
int temp = intValue % 256;
if ( intValue < 0) {
byteValue = temp < −128 ? 256 + temp : temp;
}
else {
byteValue = temp > 127 ? temp - 256 : temp;
}Character Data
Numbers are only part of the data a typical Java program needs in order to read and write. Many programs also handle text, which is composed of characters. Since computers only really understand numbers, characters are encoded by assigning each character in a given script a number. For example, in the common ASCII encoding, the character A is mapped to the number 65; the character B is mapped to the number 66; the character C is mapped to the number 67; and so on. Different encodings may encode different scripts or may encode the same or similar scripts in different ways.
Java understands several dozen different character sets for a variety of languages, ranging from ASCII to the Shift Japanese Input System (SJIS) to Unicode. Internally, Java uses the Unicode character set. Unicode is a superset of the 1-byte Latin-1 character set, which in turn is an 8-bit superset of the 7-bit ASCII character set.
ASCII
ASCII, the American Standard Code for Information Interchange, is a 7-bit character set. Thus it defines 27, or 128, different characters whose numeric values range from 0 to 127. These characters are sufficient for handling most of American English. It’s an often-used lowest common denominator format for different computers. If you were to read a byte value between 0 and 127 from a stream, then cast it to a char, the result would be the corresponding ASCII character.
ASCII characters 0–31 and character 127 are nonprinting control characters. Characters 32–47 are various punctuation and space characters. Characters 48–57 are the digits 0–9. Characters 58–64 are another group of punctuation characters. Characters 65–90 are the capital letters A–Z. Characters 91–96 are a few more punctuation marks. Characters 97–122 are the lowercase letters a–z. Finally, characters 123–126 are a few remaining punctuation symbols. The complete ASCII character set is shown in Table A-1 in the Appendix.
Latin-1
ISO 8859-1, Latin-1, is an 8-bit character set that’s a strict superset of ASCII. It defines 28, or 256, different characters whose numeric values range from 0 to 255. The first 128 characters—that is, those numbers with the high-order bit equal to 0—correspond exactly to the ASCII character set. Thus 65 is ASCII A and Latin-1 A; 66 is ASCII B and Latin-1 B; and so on. Where Latin-1 and ASCII diverge is in the characters between 128 and 255 (characters with the high-order bit equal to 1). ASCII does not define these characters. Latin-1 uses them for various accented letters such as ü needed for non-English languages written in a Roman script, additional punctuation marks and symbols such as ©, and additional control characters. The upper, non-ASCII half of the Latin-1 character set is shown in Table A-2 in the Appendix. If you were to read an unsigned byte value from a stream, then cast it to a char, the result would be the corresponding Latin-1 character.
Unicode
Latin-1 suffices for most Western European languages (with the notable exception of Greek), but it doesn’t have anywhere near the number of characters required to represent Cyrillic, Greek, Arabic, Hebrew, or Devanagari, not to mention pictographic languages like Chinese and Japanese. Chinese alone has over 80,000 different characters. To handle these scripts and many others, the Unicode character set was invented. Unicode has space for over one million different possible characters. Only about 100,000 are used in practice, the rest being reserved for future expansion. Unicode can handle most of the world’s living languages and a number of dead ones as well.
The first 256 characters of Unicode are identical to the characters of the Latin-1 character set. Thus 65 is ASCII A and Unicode A; 66 is ASCII B and Unicode B, and so on.
Unicode is only a character set. It is not a character encoding. That is, although Unicode specifies that the letter A has character code 65, it doesn’t say whether the number 65 is written using one byte, two bytes, or four bytes, or whether the bytes used are written in big- or little-endian order. However, there are certain standard encodings of Unicode into bytes, the most common of which are UTF-8, UTF-16, and UTF-32.
UTF-32 is the most naïve encoding. It simply represents each character as a single 4-byte (32-bit) int.
UTF-16 represents most characters as a 2-byte, unsigned short. However, certain less common Chinese characters, musical and mathematical symbols, and characters from dead languages such as Linear B are represented in four bytes each. The Java virtual machine uses UTF-16 internally. In fact, a Java char is not really a Unicode character. Rather it is a UTF-16 code point, and sometimes two Java chars are required to make up one Unicode character.
Finally, UTF-8 is a relatively efficient encoding (especially when most of your text is ASCII) that uses one byte for each of the ASCII characters, two bytes for each character in many other alphabets, and three-to-four bytes for characters from Asian languages. Java’s .class files use UTF-8 internally to store string literals.
Other Encodings
ASCII, Latin-1, and Unicode are hardly the only character sets in common use, though they are the ones handled most directly by Java. There are many other character sets, both that encode different scripts and that encode the same scripts in different ways. For example, IBM mainframes have long used a non-ASCII character set called EBCDIC. EBCDIC has most of the same characters as ASCII but assigns them to different numbers. Macintoshes commonly use an 8-bit encoding called MacRoman that matches ASCII in the lower 128 places and has most of the same characters as Latin-1 in the upper 128 characters, though in different positions. DOS (including the DOS shell in Windows) uses character sets such as Cp850 that include box drawing characters such as ╚ and ╬. Big-5 and SJIS are encodings of Chinese and Japanese, respectively, that include most of the numerous characters used in those scripts.
The exact details of each encoding are fairly involved and should really be handled by experts. Fortunately, the Java class library includes a set of reader and writer classes written by such experts. Readers and writers convert to and from bytes in particular encodings to Java chars without any extra effort. For similar reasons, you should use a writer rather than an output stream to write text, as discussed in Chapter 20.
The char Data Type
Text in Java is primarily composed of the char primitive data type, char arrays, and Strings, which are stored as arrays of chars internally. Just as you need to understand bytes to really grasp how input and output streams work, so too do you need to understand chars to understand how readers and writers work.
In Java, a char is a 2-byte, unsigned integer—the only unsigned type in Java. Thus, possible char values range from 0 to 65,535. Each char represents a particular character in the Unicode character set. chars may be assigned to by using int literals in this range; for example:
char copyright = 169;
chars may also be assigned to by using char literals—that is, the character itself enclosed in single quotes:
char copyright = '©';
Sun’s javac compiler can translate many different encodings to Unicode by using the -encoding command-line flag to specify the encoding in which the file is written. For example, if you know a file is written in ISO 8859-1, you might compile it as follows:
% javac -encoding 8859_1 CharTest.javaThe list of available encodings is given in Table A-4.
With the exception of Unicode itself, most character sets understood by Java do not have equivalents for all the Unicode characters. To encode characters that do not exist in the character set you’re programming with, you can use Unicode escapes. A Unicode escape sequence is an unescaped backslash, followed by any number of u characters, followed by four hexadecimal digits specifying the character to be used. For example:
char copyright = '\u00A9';
Unicode escapes may be used not just in char literals, but also in strings, identifiers, comments, and even in keywords, separators, operators, and numeric literals. The compiler translates Unicode escapes to actual Unicode characters before it does anything else with a source code file.
Tip
Unicode escapes are a relic of times when most text editors could not handle Unicode. Fortunately, this hasn’t been the case for years. Today, Java source code should be written in Unicode (preferably UTF-8) and any non-ASCII characters typed directly. In 2006, Unicode escapes serve only to obfuscate code.
Readers and Writers
Streams are primarily intended for data that can be read as pure bytes—basically, byte data and numeric data encoded as binary numbers of one sort or another. Streams are specifically not intended for reading and writing text, including both ASCII text, such as “Hello World,” and numbers formatted as text, such as “3.1415929”. For these purposes, you should use readers and writers.
Input and output streams are fundamentally byte-based. Readers and writers are based on characters, which can have varying widths depending on the character set. For example, ASCII and Latin-1 use 1-byte characters. UTF-32 uses 4-byte characters. UTF-8 uses characters of varying width (between one and four bytes). Since characters are ultimately composed of bytes, readers take their input from streams. However, they convert those bytes into chars according to a specified encoding format before passing them along. Similarly, writers convert chars to bytes according to a specified encoding before writing them onto some underlying stream.
The java.io.Reader and java.io.Writer classes are abstract superclasses for classes that read and write character-based data. The subclasses are notable for handling the conversion between different character sets. The core Java API includes nine reader and eight writer classes, all in the java.io package:
BufferedReader
|
BufferedWriter
|
CharArrayReader
|
CharArrayWriter
|
FileReader
|
FileWriter
|
FilterReader
|
FilterWriter
|
InputStreamReader
|
LineNumberReader
|
OutputStreamWriter
|
PipedReader
|
PipedWriter
|
PrintWriter
|
PushbackReader
|
StringReader
|
StringWriter
|
For the most part, these classes have methods that are extremely similar to the equivalent stream classes. Often the only difference is that a byte in the signature of a stream method becomes a char in the signature of the matching reader or writer method. For example, the java.io.OutputStream class declares these three write( ) methods:
public abstract void write(int i) throws IOException public void write(byte[] data) throws IOException public void write(byte[] data, int offset, int length) throws IOException
The java.io.Writer class, therefore, declares these three write( ) methods:
public void write(int i) throws IOException public void write(char[] data) throws IOException public abstract void write(char[] data, int offset, int length) throws IOException
As you can see, the signatures match except that in the latter two methods the byte array data has changed to a char array. There’s also a less obvious difference not reflected in the signature. While the int passed to the OutputStream write( ) method is reduced modulo 256 before being output, the int passed to the Writer write( ) method is reduced modulo 65,536. This reflects the different ranges of chars and bytes.
java.io.Writer also has two more write( ) methods that take their data from a string:
public void write(String s) throws IOException public void write(String s, int offset, int length) throws IOException
Because streams don’t know how to deal with character-based data, there are no corresponding methods in the java.io.OutputStream class.
Buffers and Channels
Streams are reasonably fast as long as an application has to read from or write to only one at a time. In fact, the bottleneck is more likely to be the disk or network you’re reading from or writing to than the Java program itself. The situation is a little dicier when a program needs to read from or write to many different streams simultaneously. This is a common situation in web servers, for example, where a single process may be communicating with hundreds or even thousands of different clients simultaneously.
At any given time, a stream may block. That is, it may simply stop accepting further requests temporarily while it waits for the actual hardware it’s writing to or reading from to catch up. This can happen on disks, and it’s a major issue on network connections. Clearly, you don’t want to stop sending data to 999 clients just because one of them is experiencing network congestion. The traditional solution to this problem prior to Java 1.4 was to put each connection in a separate thread. Five hundred clients requires 500 threads. Each thread can run independently of the others so that one slow connection doesn’t slow down everyone.
However, threads are not without overhead of their own. Creating and managing threads takes a lot of work, and few virtual machines can handle more than a thousand or so threads without serious performance degradation. Spawning several thousand threads can crash even the toughest virtual machine. Nonetheless, big servers need to be able to communicate with thousands of clients simultaneously.
The solution invented in Java 1.4 was nonblocking I/O. In nonblocking I/O, streams are relegated mostly to a supporting role while the real work is done by channels and buffers. Input buffers are filled with data from the channel and then drained of data by the application. Output buffers work in reverse: the application fills them with data that is subsequently drained out by the target. The design is such that the writer and reader don’t always have to operate in lockstep with each other. Most importantly, the client application can queue reads and writes to each channel. It does not have to stop processing simply because the other end of the channel isn’t quite ready. This enables one thread to service many different channels simultaneously, dramatically reducing the load on the virtual machine.
Channels and buffers are also used to enable memory-mapped I/O. In memory-mapped I/O, files are treated as large blocks
of memory, essentially as big byte arrays. Particular parts of a mapped file can be read with statements such as int x = file.getInt(1067) and written with statements such as file.putInt(x, 1067). The data is stored directly to disk at the right location without having to read or write all the data that precedes or follows the section of interest.
Channels and buffers are a little more complex than streams and bytes. However, for certain kinds of I/O-bound applications, the performance gains are dramatic and worth the added complexity.
The Ubiquitous IOException
As far as computer operations go, input and output are unreliable. They are subject to problems completely outside the programmer’s control. Disks can develop bad sectors while a file is being read. Construction workers drop their backhoes through the cables that connect your WAN. Users unexpectedly cancel their input. Telephone repair crews shut off your modem line while trying to repair someone else’s. (This last one actually happened to me while writing this chapter. My modem kept dropping the connection and then not getting a dial tone; I had to hunt down the Verizon “repairman” in my building’s basement and explain to him that he was working on the wrong line.)
Because of these potential problems and many more, almost every method that performs input or output is declared to throw an IOException. IOException is a checked exception, so you must either declare that your methods throw it or enclose the call that can throw it in a try/catch block. The only real exceptions to this rule are the PrintStream and PrintWriter classes. Because it would be inconvenient to wrap a try/catch block around each call to System.out.println( ), Sun decided to have PrintStream (and later PrintWriter) catch and eat any exceptions thrown inside a print( ) or println( ) method. If you do want to check for exceptions inside a print( ) or println( ) method, you can call checkError( ):
public boolean checkError( )
The checkError( ) method returns true if an exception has occurred on this print stream, false if one hasn’t. It tells you only that an error occurred. It does not tell you what sort of error occurred. If you need to know more about the error, you’ll have to use a different output stream or writer class.
IOException has many subclasses—15 in java.io alone—and methods often throw a more specific exception that subclasses IOException; for instance, EOFException on an unexpected end of file or UnsupportedEncodingException when you try read text in an unknown character set. However, methods usually declare only that they throw an IOException.
The java.io.IOException class declares no public methods or fields of significance—just the usual two constructors you find in most exception classes:
public IOException( ) public IOException(String message)
The first constructor creates an IOException with an empty message. The second provides more details about what went wrong. Of course, IOException has the usual methods inherited by all exception classes such as toString( ) and printStackTrace( ).
Tip
Java 6 also adds an IOError class that is “Thrown when a serious I/O error has occurred.” Xueming Shen snuck this class in the backdoor solely to avoid declaring that methods in the new Console class throw IOException like they should. I am not sure if this wart will remain in the final version of Java 6 or not. At the time of this writing, I am lobbying strenuously to get this removed, or at least replaced by a runtime exception instead of an error.
The Console: System.out, System.in, and System.err
The console is the default destination for output written to System.out or System.err and the default source of input for System.in. On most platforms the console is the command-line environment from which the Java program was initially launched, perhaps an xterm or a DOS prompt as shown in Figure 1-1. The word console is something of a misnomer, since on Unix systems the console refers to a very specific command-line shell rather than to command-line shells overall.
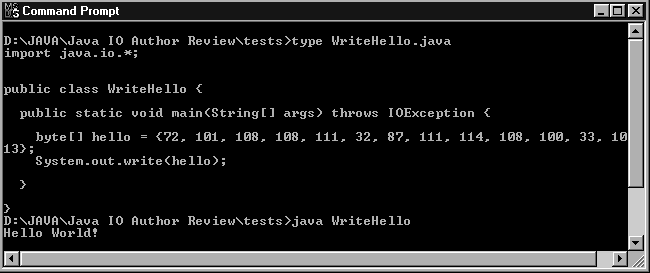
Many common misconceptions about I/O occur because most programmers’ first exposure to I/O is through the console. The console is convenient for quick hacks and toy examples commonly found in textbooks, and I will use it for that in this book, but it’s really a very unusual source of input and destination for output, and good Java programs avoid it. It behaves almost, but not completely, unlike anything else you’d want to read from or write to. While consoles make convenient examples in programming texts like this one, they’re a horrible user interface and really have little place in modern programs. Users are more comfortable with a well-designed GUI. Furthermore, the console is unreliable across platforms. Many smaller devices such as Palm Pilots and cell phones have no console. Web browsers running applets sometimes provide a console that can be used for output. However, this is hidden by default, normally cannot be used for input, and is not available in all browsers on all platforms.
System.out
System.out is the first instance of the OutputStream class most programmers encounter. In fact, it’s often encountered before students know what a class or an output stream is. Specifically, System.out is the static out field of the java.lang.System class. It’s an instance of java.io.PrintStream, a subclass of java.io.OutputStream.
System.out corresponds to stdout in Unix or C. Normally, output sent to System.out appears on the console. As a general rule, the console converts the numeric byte data System.out sends to it into ASCII or Latin-1 text. Thus, the following lines write the string “Hello World!” on the console:
byte[] hello = {72, 101, 108, 108, 111, 32, 87, 111, 114, 108, 100, 33, 10,
13};
System.out.write(hello);System.err
Unix and C programmers are familiar with stderr, which is commonly used for error messages. stderr is a separate file pointer from stdout, but often means the same thing. Generally, stderr and stdout both send data to the console, whatever that is. However, stdout and stderr can be redirected to different places. For instance, output can be redirected to a file while error messages still appear on the console.
System.err is Java’s version of stderr. Like System.out, System.err is an instance of java.io.PrintStream, a subclass of java.io.OutputStream. System.err is most commonly used inside the catch clause of a try/catch block, as shown here:
try {
// Do something that may throw an exception.
}
catch (Exception ex) {
System.err.println(ex);
}Finished programs shouldn’t have much need for System.err, but it is useful while you’re debugging.
Tip
Libraries should never print anything on System.err. In general, libraries should not talk to the user at all, unless that is their specific purpose. Instead, libraries should inform the client application of any problems they encounter by throwing an exception or invoking a callback method in some sort of error-handler object. Yes, Xerces, I’m talking to you. (The Xerces XML parser, now built into Java 5 has a really annoying habit of reporting even nonfatal errors by printing them on System.err.)
System.in
System.in is the input stream connected to the console, much as System.out is the output stream connected to the console. In Unix or C terms, System.in is stdin and can be redirected from a shell in the same fashion. System.in is the static in field of the java.lang.System class. It’s an instance of java.io.InputStream, at least as far as is documented.
Past what’s documented, System.in is really a java.io.BufferedInputStream. BufferedInputStream doesn’t declare any new methods; it just overrides the ones already declared in java.io.InputStream. Buffered input streams read data in large chunks into a buffer, then parcel it out in requested sizes. This can be more efficient than reading one character at a time. Otherwise, the data is completely transparent to the programmer.
The main significance of this is that bytes are not available to the program at the moment the user types them on System.in. Instead, input enters the program one line at a time. This allows a user typing into the console to backspace over and correct mistakes. Java does not allow you to put the console into “raw mode,” wherein each character becomes available as soon as it’s typed, including characters such as backspace and delete.
The user types into the console using the platform’s default character set, typically ASCII or some superset thereof. The data is converted into numeric bytes when read. For example, if the user types “Hello World!” and hits the Enter key, the following bytes are read from System.in in this order:
72, 101, 108, 108, 111, 32, 87, 111, 114, 108, 100, 33, 10, 13
Many programs that run from the command line and read input from System.in require you to enter the “end of stream” character, also known as the “end of file” or EOF character, to terminate a program normally. How this is entered is platform-dependent. On Unix and the Mac, Ctrl-D generally indicates end of stream. On Windows, Ctrl-Z does. In some cases it may be necessary to type this character alone on a line. That is, you may need to hit Enter/Ctrl-Z or Enter/Ctrl-D before Java will recognize the end of stream.
Redirecting System.out, System.in, and System.err
In a shell, you often redirect stdout, stdin, or stderr. For example, to specify that output from the Java program OptimumBattingOrder goes into the file yankees06.out and that input for that program is read from the file yankees06.tab, you might type:
% java OptimumBattingOrder < yankees06.tab > yankees06.outRedirection in a DOS shell is the same.
It’s sometimes convenient to be able to redirect System.out, System.in, and System.err from inside the running program. The following three static methods in the java.lang.System class do exactly that:
public static void setIn(InputStream in) public static void setOut(PrintStream out) public static void setErr(PrintStream err)
For example, to specify that data written on System.out is sent to the file yankees99.out and that data read from System.in comes from yankees99.tab, you could write:
System.setIn(new FileInputStream("yankees99.tab"));
System.setOut(new PrintStream(new FileOutputStream("yankees99.out")));The Console Class // Java 6
While working on Java 6, Sun finally got tired of all the sniping from the Python and Ruby communities about how hard it was to just read a line of input from the console. This is a one liner in most scripting languages, but traditionally it’s been a little involved in Java.
Tip
The reason reading a line of input from the console is relatively involved in Java compared to some other languages is because in 2006 no one needs to do this outside of a CS 101 course. Real programs use GUIs or the network for user interfaces, not the console, and Java has always been focused on getting real work done rather than enabling toy examples.
Java 6 adds a new java.lang.Console
class that provides a few convenience methods for input and output. This class is a singleton. There’s never more than one instance of it, and it always applies to the same shell that System.in, System.out, and System.err point to. You retrieve the single instance of this class using the static System.console( ) method like so:
Console theConsole = System.console( );
This method returns null if you’re running in an environment such as a cell phone or a web browser that does not have a console.
There are several ways you might use this class. Most importantly, it has a simple readLine( ) method that returns a single string of text from the console, not including the line-break characters:
public String readLine( ) throws IOError
This method returns null on end of stream. It throws an IOError if any I/O problem is encountered. (Again, this is a design bug, and I am trying to convince Sun to fix this before final release. This method should throw an IOException like any normal method if there’s a problem.)
You can optionally provide a formatted prompt before reading the line:
public String readLine(String prompt, Object... formatting)
The prompt string is interpreted like any printf( ) string and filled with arguments to its right. All this does is format the prompt. This is not a scanf( ) equivalent. The return value is the same as for the no-args readLine( ) method.
Console also has two readPassword( ) methods:
public char[] readPassword( ) public char[] readPassword(String prompt, Object... formatting)
Unlike readLine( ), these do not echo the characters typed back to the screen. Also note that they return an array of chars rather than a String. When you’re finished with the password, you can overwrite the characters in the array with zeros so that the password is not held in memory for longer than it needs to be. This limits the possibility of the password being exposed to memory scanners or stored on the disk due to virtual memory.
For output, Console has two methods, printf( ) and format( ):
public Console format(String format, Object... arguments) public Console printf(String format, Object... arguments)
There is no difference between these two methods. They are synonyms. For example, this code fragment prints a three-column table of the angles between 0 and 360 degrees in degrees, radians, and grads on the console using only printf( ). Each number is exactly five characters wide with one digit after the decimal point.
Console console = System.console( );
for (double degrees = 0.0; degrees < 360.0; degrees++) {
double radians = Math.PI * degrees / 180.0;
double grads = 400 * degrees / 360;
console.printf("%5.1f %5.1f %5.1f\n", degrees, radians, grads);
}Here’s the start of the output:
0.0 0.0 0.0 1.0 0.0 1.1 2.0 0.0 2.2 3.0 0.1 3.3 ...
Chapter 7 explores printf( ) and its formatting arguments in greater detail.
The console normally buffers all output until a line break is seen. You can force data to be written to the screen even before a line break by invoking the flush( ) method:
formatter.flush( ); formatter.close( );
Finally, if these methods aren’t enough for you, you can work directly with the console’s associated PrintWriter and Reader:
public PrintWriter writer( ) public Reader reader( )
Chapter 20 explores these two classes.
Example 1-1 is a simple program that uses the Console class to answer a typical homework assignment: ask the user to enter an integer and print the squares of the numbers from 1 to that integer. In keeping with the nature of such programs, I’ve deliberately left at least three typical student bugs in the code. Identifying and correcting them is left as homework for the reader.
import java.io.*;
class Homework {
public static void main(String[] args) {
Console console = System.console( );
String input = console.readLine(
"Please enter a number between 1 and 10: ");
int max = Integer.parseInt(input);
for (int i = 1; i < max; i++) {
console.printf("%d\n", i*i);
}
}
}Here’s what the program looks like when it runs:
C:\>java HomeworkPlease enter a number between 1 and 10:41 4 9
Security Checks on I/O
One of the original fears about downloading executable content like applets from the Internet was that a hostile applet could erase your hard disk or read your Quicken files. Nothing has happened to change that since Java was introduced. This is why Java applets run under the control of a security manager that checks each operation an applet performs to prevent potentially hostile acts.
The security manager is particularly careful about I/O operations. For the most part, the checks are related to these questions:
Can the program read a particular file?
Can the program write a particular file?
Can the program delete a particular file?
Can the program determine whether a particular file exists?
Can the program make a network connection to a particular host?
Can the program accept an incoming connection from a particular host?
The short answer to all these questions when the program is an applet is “No, it cannot.” A slightly more elaborate answer would specify a few exceptions. Applets can make network connections to the host they came from; applets can read a few very specific files that contain information about the Java environment; and trusted applets may sometimes run without these restrictions. But for almost all practical purposes, the answer is almost always no.
Because of these security issues, you need to be careful when using code fragments and examples from this book in an applet. Everything shown here works when run in an application, but when run in an applet, it may fail with a SecurityException. It’s not always obvious whether a particular method or class will cause problems. The write( ) method of BufferedOutputStream, for instance, is completely safe when the ultimate destination is a byte array. However, that same write( ) method will throw an exception when the destination is a file. An attempt to open a connection to a web server may succeed or fail depending on whether or not the web server you’re connecting to is the same one the applet came from.
Consequently, this book focuses very much on applications. There is very little I/O that can be done from an applet without running afoul of the security manager. The problem may not always be obvious—not all web browsers properly report security exceptions—but it is there. If you can make an applet work when it’s run as a standalone application and you cannot get it to work inside a web browser, the problem is likely a conflict with the browser’s security manager.
Get Java I/O, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

