The world of interapplication communication usually involves more than two parties talking with one another in a point-to-point fashion. A SOAP envelope that represents a business transaction may move from place to place as it goes through the various stages of a business process. Each stage in a multihop process may act upon the envelope, modify its contents, and route it along to the next step in a process.
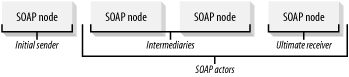
Recognizing that messages may take many hops as they travel from the sender to their final destination, SOAP defines a Message Exchange Model. As illustrated in Figure 4-2, this model defines terminology and roles such as SOAP Node, Intermediary, Actor, the initial SOAP sender, and the ultimate receiver. A node is any object or process performing any of these roles. An intermediary is any node that sits between the initial SOAP sender and the ultimate receiver. An actor is any node that receives a SOAP envelope for processing and can be either an intermediary or the ultimate receiver.
The actor attribute may be used to specify which
blocks of information are intended for each step in the process. Each
node in a multihop process is responsible for digesting and
interpreting the meaning of the actor attribute
for each SOAP block and possibly re-inserting it into the SOAP block
and forwarding it on to the next node for processing. Any SOAP
receiver that encounters a header block without an
actor attribute, or an actor
attribute equivalent to the special URI http://www.w3.org/2001/09/soap-envelope/actor/next,
has to interpret that header block as being intended for it (the
current SOAP node). If the current SOAP node cannot fulfill the
mustUnderstand requirements, it must generate a
SOAP Fault.
An actor attribute with the special value of
http://www.w3.org/2001/09/soap-envelope/actor/none
indicates that this header is not targeted at anything in particular.
This indication is useful for sharing header information across
multiple nodes.
There’s a lot of confusion about URIs, URNs, and URLs, which are seemingly similar concepts used throughout web services and are gradually infiltrating Internet programming in general. In 2001, the W3C published a document that attempts to clarify these three commonly misused acronyms. The full document can be found at http://www.w3.org/TR/2001/NOTE-uri-clarification-20010921/.
1 URI Partitioning
There is some confusion in the web community over the partitioning of URI space, specifically, the relationship among the concepts of URL, URN, and URI. The confusion owes to the incompatibility between two different views of URI partitioning, which we call the “classical” and “contemporary” views.
1.1 Classical View
During the early years of discussion of web identifiers (early to mid 90s), people assumed that an identifer type would be cast into one of two (or possibly more) classes. An identifier might specify the location of a resource (a URL) or its name (a URN) independent of location. Thus a URI was either a URL or a URN. There was discussion about generalizing this by addition of a discrete number of additional classes; for example, a URI might point to metadata rather than the resource itself, in which case the URI would be a URC (citation). URI space was thus viewed as partitioned into subspaces: URL and URN, and additional subspaces, to be defined. The only such additional space ever proposed was URC and there never was any buy-in; so without loss of generality it’s reasonable to say that URI space was thought to be partitioned into two classes: URL and URN. Thus for example, "http:” was a URL scheme, and "isbn:" would (someday) be a URN scheme. Any new scheme would be cast into one or the other of these two classes.
1.2 Contemporary View
Over time, the importance of this additional level of hierarchy seemed to lessen; the view became that an individual scheme does not need to be cast into one of a discrete set of URI types such as “URL”, “URN”, “URC”, etc. Web-identifer schemes are in general URI schemes; a given URI scheme may define subspaces. Thus "http:” is a URI scheme. "urn:” is also a URI scheme; it defines subspaces, called “namespaces”. For example, the set of URNs of the form "urn:isbn:n-nn-nnnnnn-n" is a URN namespace. (”isbn" is an URN namespace identifier. It is not a “URN scheme” nor a “URI scheme”).
Further according to the contemporary view, the term “URL” does not refer to a formal partition of URI space; rather, URL is a useful but informal concept: a URL is a type of URI that identifies a resource via a representation of its primary access mechanism (e.g., its network “location”), rather than by some other attributes it may have. Thus as we noted, "http:” is a URI scheme. An http URI is a URL. The phrase “URL scheme” is now used infrequently, usually to refer to some subclass of URI schemes which exclude URNs.
1.3 Confusion
The body of documents (RFCs, etc.) covering URI architecture, syntax, registration, etc., spans both the classical and contemporary periods. People who are well-versed in URI matters tend to use “URL” and “URI” in ways that seem to be interchangable. Among these experts, this isn’t a problem. But among the Internet community at large, it is. People are not convinced that URI and URL mean the same thing, in documents where they (apparently) do. When one sees an RFC that talks about URI schemes (e.g., [RFC2396]), another that talks about URL schemes (e.g., [RFC2717]), and yet another that talks of URN schemes ([RFC2276]) it is natural to wonder what’s the difference, and how they relate to one another. While RFC 2396 1.2 attempts to address the distinction between URIs, URLs and URNs, it has not been successful in clearing up the confusion.
We hope this clears it up for everyone. The summarized description that we feel is generally acceptable in the industry is this:
A Universal Resource Identifier (URI) is a generic representation that can either be a Universal Resource Locator (URL) or a Universal Resource Name (URN). A URL is something that represents a physical network location and contains things that pertain to a particular protocal, such as http:// or ftp://. A URN is something that does not necessarily resolve to any physical location; generally, it is intended to be used to identify something uniquely, such as a SOAP action or a namespace.
Get Java Web Services now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

