The first thing a peer must do is discover its surrounding environment. Peers discover resources, support themselves, access needed services, and expand their horizons in their surrounding environments. In the case of a RestoPeer, the first thing it must do is discover and join the RestoNet peergroup. There is, of course, no guarantee that the RestoNet peergroup already exists, so the RestoPeer must be prepared to create it as well.
JXTA discovery is closely related to the peergroup concept: discovery in JXTA is performed within the context of a peergroup. We have seen that every peer joins the NetPeerGroup. Discovery performed within the context of the NetPeerGroup enables any peer to potentially discover any advertisements published in the NetPeerGroup. Due to the large number of advertisements in the NetPeerGroup, it is impractical to perform discovery within the context of the NetPeerGroup; peers should attempt to discover peergroups within the NetPeerGroup context and then attempt to discover other resources within a smaller peergroup.
The discovery scope of a peer corresponds to the peergroup context in which discovery is performed. For example, in Figure 4-3, if discovery is performed within the context of Peergroup 2, only advertisements stored on peers that are members of the Peergroup 2 can be discovered. The peergroup context enables a peer to scope discovery operations and reduces the risk of overwhelming the network.
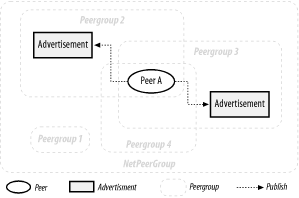
Note that a peer may belong to multiple peergroups (shown as intersecting peergroups in Figure 4-3). When publishing advertisements, the publishing peer defines the scope of discovery by selecting which peergroup the advertisement is published in. The same advertisement may be published in multiple peergroups. In Figure 4-3, Peer A publishes an advertisement in both Peergroup 2 and Peergroup 3. This means that only members of Peergroups 2 and 3 can discover the advertisement; members of Peergroup 1 cannot discover the advertisement. Each peergroup corresponds to a different discovery scope.
The JXTA discovery API uses an asynchronous mechanism for discovering advertisements. A peer that wants to discover a resource propagates a discovery request within a chosen peergroup scope. Responses are received asynchronously. No guarantee is made regarding when (or if) a response will be received: multiple responses may be received, or no responses may be received. Peers may have cached advertisements that represent resources that are no longer reachable: the peer itself may be down, or no routes to the peer may be available. A discovery request may be sent using endpoint transports with different latencies, leading to unpredictable behaviors. The unpredictability and unreliability of a P2P network such as JXTA makes it difficult to specify time-out or predictable behaviors. It is ultimately the responsibility of an application to decide how long it should wait to get a response.
An asynchronous programming model is best suited for this unreliable P2P network environment. Asynchronicity greatly simplifies error recovery, since errors are handled as normal cases rather than as exceptions.
A peer that wants to discover a particular advertisement must specify the following:
- Type
The type of advertisement that the peer wants to discover (e.g., a peergroup advertisement or a peer advertisement). As we’ve mentioned, there are core advertisement types (e.g., peer, peergroup, pipe, and so on); the type itself is based on the root element of the XML document that comprises the advertisement.
- Attribute and value
The advertisement must contain an XML tag that corresponds to the given attribute and contains the given value. For example, the service advertisement for the rendezvous service contains an XML tag:
<Name>jxta.service.rendezvous</Name>. So a peer that wants to discover a rendezvous service would supply an attribute ofNameand a value ofjxta.service.rendezvous.- Threshold
Some methods of the discovery API allow a peer to specify a threshold that defines an upper limit for the number of matching advertisements that should be returned to the requesting peer. This allows the peer to control the size of the responses it will receive; small memory devices may be able to store only a few advertisements in memory.
Advertisements are cached in local storage by a peer; as they are asynchronously discovered, a background thread automatically places them in the cache. Therefore, even though discovery is an asynchronous process, the developer does not need to worry about threads or any other asynchronous technique; she simply sends the discovery request and later checks back to see if there were any responses.[3]
The cache of previously discovered advertisements is often held in persistent storage; this is certainly the case with the Java 1.0 JXTA implementation for desktop systems and servers, though other implementations (particularly on small devices) may not have this option. Therefore, an application that looks for responses in the local cache may find responses that were cached from its previous runs as well as any new ones it finds while running.
All discovery operations are handled
by the discovery service, one of the core JXTA services. As we saw in
Chapter 3, a handle to the discovery service may
be obtained by calling the getDiscovery( ) method
of the peergroup object with which the application is initialized;
this method returns a Discovery object
(net.jxta.discovery.Discovery). This class has two
main methods for discovering advertisements:
-
public Enumeration getLocalAdvertisements(int type, String attribute, String value) throws IOException This method is used to search the local cache for already discovered advertisements. Even though there are six core advertisement types, the type passed to this method must be one of these three values:
PEER(peer advertisement),PEERGROUP(peergroup advertisement), orADV(all other advertisements).-
public void getRemoteAdvertisements(String peerid, int type, String attribute, String value, int threshold) This method is used to send a discovery request to members of the peergroup. Remember that in most cases the discovery request will not be able to reach all members: some peers may be down or not reachable. It is also not practical or realistic to expect all peers to respond to a discovery request.
If a peer ID is passed to this method, only that peer will be contacted, and only the matching advertisements known to that peer will be returned; this is often used with rendezvous peers.
If
nullis passed as the peer ID, then the peer will attempt to contact all known rendezvous peers. In addition, any broadcasting capabilities available in the underlying endpoint transports will be used to propagate a request. In the case of TCP/IP, IP multicast is used to propagate a request to all member peers in the same subnet. This approach limits the scope of discovery to a subnet, as most routers are configured to block multicast packets. HTTP does not have a propagate capability.
Let’s apply all of this to the restaurant auctioning
example. We’ll first look at the
RestoPeer class.
Get JXTA in a Nutshell now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

