Chapter 4. Workload Runtime Security
Note
This chapter talks about pod security policies (PSP), a feature that has been deprecated in Kubernetes v1.25 (October 2022) and replaced with pod security admission (PSA). We’ve left the sections of this chapter that discuss PSP intact, as we recognize that not all developers will be moving to v1.25 right away. For more information, see Kubernetes’s updated documentation on pod security policies.
Kubernetes’ default pod provisioning mechanism has a wide attack surface that can be used by adversaries to exploit the cluster or escape the container. In this chapter you will learn how to implement pod security policies (PSPs) to limit the attack surface of the pods and how to monitor processes (e.g., process privileges), file access, and runtime security for your workloads. Here are a few specifics of what we will discuss:
-
We will cover the implementation details of PSPs, like pod security contexts, and also explain the limitations of PSPs. Note PSPs are deprecated as of Kubernetes v1.21; however, we will cover this topic in this chapter as we are aware that PSPs are widely used.
-
We will discuss process monitoring, which focuses on the need for Kubernetes-native monitoring to detect suspicious activities. We will cover runtime monitoring and enforcement using kernel security features like seccomp, SELinux, and AppArmor to prevent containers from accessing host resources.
-
We will cover both detection and runtime defense against vulnerabilities, workload isolation, and a blast radius containment.
Pod Security Policies
Kubernetes provides a way to securely onboard your pods and containers by using PSPs. They are a cluster-scoped resource that checks for a set of conditions before a pod is admitted and scheduled to run in a cluster. This is achieved via a Kubernetes admission controller, which evaluates every pod creation request for compliance with the PSP assigned to the pod.
Please note that PSPs are deprecated with Kubernetes release 1.21 and are scheduled to be removed in release 1.25. They are widely used in production clusters, though, and therefore this section will help you understand how they work and what best practices are for implementing PSPs.
PSPs let you enforce rules with controls like pods should not run as root or pods should not use host network, host namespace, or run as privileged. The policies are enforced at pod creation time. By using PSPs you can make sure pods are created with the minimum privileges needed for operation, which reduces the attack surface for your application. Additionally, this mechanism helps you to be compliant with various standards like PCI, SOC 2, or HIPAA, which mandates the use of principle of least privilege access. As the name suggests, the principle requires that any process, user, or, in our case, workload be granted the least amount of privileges necessary for it to function.
Using Pod Security Policies
Kubernetes PSPs are recommended but implemented via an optional admission controller. The enforcement of PSPs can be turned on by enabling an admission controller. That means the Kubernetes API server manifest should have a PodSecurityPolicy plug-in in its --enable-admission-plugins list. Many Kubernetes distros do not support or by default disable PSPs, so it’s worth checking while choosing the Kubernetes distros.
Once the PSPs are enabled, it’s a three-step process to apply PSPs, as shown in Figure 4-1. A best practice is to apply PSPs to groups rather than individual service accounts.
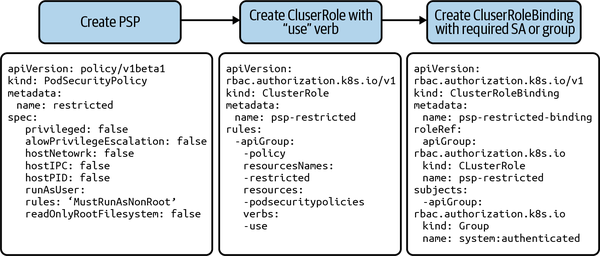
Figure 4-1. Process to apply PSPs
Step 1 is to create a PSP. Step 2 is to create ClusterRole with the use verb, which authorizes pod deployment controllers to use the policies. Then step 3 is to create ClusterRoleBindings, which is used to enforce policy for the groups (i.e., system:authenticated or system:unauthenticated) or service accounts.
A good starting point is the PSP template from the Kubernetes project:
apiVersion:policy/v1beta1kind:PodSecurityPolicymetadata:name:restrictedannotations:seccomp.security.alpha.kubernetes.io/allowedProfileNames:|'docker/default,runtime/default'apparmor.security.beta.kubernetes.io/allowedProfileNames:'runtime/default'seccomp.security.alpha.kubernetes.io/defaultProfileName:'runtime/default'apparmor.security.beta.kubernetes.io/defaultProfileName:'runtime/default'spec:privileged:false# Required to prevent escalations to root.allowPrivilegeEscalation:false# This is redundant with non-root + disallow privilege escalation,# but we can provide it for defense in depth.requiredDropCapabilities:-ALL# Allow core volume types.volumes:-'configMap'-'emptyDir'-'projected'-'secret'-'downwardAPI'# Assume that persistentVolumes set up by the cluster admin are safe to use.-'persistentVolumeClaim'hostNetwork:falsehostIPC:falsehostPID:falserunAsUser:# Require the container to run without root privileges.rule:'MustRunAsNonRoot'seLinux:# This policy assumes the nodes are using AppArmor rather than SELinux.rule:'RunAsAny'supplementalGroups:rule:'MustRunAs'ranges:# Forbid adding the root group.-min:1max:65535fsGroup:rule:'MustRunAs'ranges:# Forbid adding the root group.-min:1max:65535readOnlyRootFilesystem:false
In the following example, you apply this policy to all authenticated users using Kubernetes role-based access control:
apiVersion:rbac.authorization.k8s.io/v1kind:ClusterRole Policymetadata:name:psp-restrictedrules:-apiGroups:-policyresourceNames:-restrictedresources:-podsecuritypoliciesverbs:-use---apiVersion:rbac.authorization.k8s.io/v1kind:ClusterRoleBindingmetadata:name:psp-restricted-bindingroleRef:apiGroup:rbac.authorization.k8s.iokind:ClusterRolename:psp-restrictedsubjects:-apiGroup:rbac.authorization.k8s.iokind:Groupname:system:authenticated
Pod Security Policy Capabilities
Let’s focus on the capabilities provided by PSPs that you can utilize as required by your use case and internal threat model. You can follow the example PSP template we just discussed to build your own PSPs. In this template most of the PSP capabilities are utilized to formulate a restrictive policy.
To explain the impact of a capability, let’s take a look at an example where you see capabilities granted to the pod created with privileged:true and with privileged:false. A Linux utility capsh can be used to evaluate the permissions of containerized root users. As you can see in Figure 4-2, the privileged pod has a plethora of capabilities in its Linux namespace, which translates to a wider attack surface for an attacker to escape your container.

Figure 4-2. Pod capabilities for default and privileged pods
Table 4-1 summarizes the capabilities for pods as described in the Kubernetes PSP documentation.
| Field | Uses |
|---|---|
| privileged | Allow containers to gain capabilities that include access to host mounts, filesystem to change settings, and many more. You can check capabilities with command capsh --print. |
| hostPID, hostIPC | Give container access to host namespaces where process and Ethernet interfaces are visible to it. |
| hostNetwork, hostPorts | Give container IP access to the host network and ports. |
| volumes | Allow volumes types like configMap, emtyDir, or secret. |
| allowedHostPaths | Allow the whitelisting of host paths that can be used by hostPath volumes (i.e., /tmp). |
| allowedFlexVolumes | Allow specific FlexVolume drivers (i.e., azure/kv). |
| fsGroup | Set a GID or range of GID that owns the pod’s volumes. |
| readOnlyRootFilesystem | Set the container’s root filesystem to read-only. |
| runAsUser, runAsGroup, supplementalGroups | Define containers UID and GID. Here you can specify non-root user or groups. |
| allowPrivilegeEscalation, defaultAllowPrivilegeEscalation | Restrict privilege escalation by process. |
| defaultAddCapabilities, requiredDropCapabilities, allowedCapabilities | Add or drop Linux capabilities as needed. |
| SELinux | Define the SELinux context of the container. |
| allowedProcMountTypes | Allowed proc mount types by container. |
| forbiddenSysctls,allowedUnsafeSysctls | Set the sysctl profile used by the container. |
| annotations | Set the AppArmor and seccomp profiles used by containers. |
AppArmor and seccomp profiles are used with PSP annotation where you can use the runtime’s (Docker, CRI) default profile or choose a custom profile loaded on the host by you. You will see more about these defenses in “Process Monitoring”.
Pod Security Context
Unlike PSPs, which are defined cluster-wide, a pod securityContext can be defined at runtime while creating a deployment or pod. Here is a simple example of pod securityContext in action, where the pod is created with the root user (uid=0) and allows only four capabilities:
kind:PodapiVersion:v1metadata:name:attacker-privileged-testnamespace:defaultlabels:app:normal-appspec:containers:-name:attacker-containerimage:alpine:latestargs:["sleep","10000"]securityContext:runAsUser:0capabilities:drop:-alladd:-SYS_CHROOT-NET_BIND_SERVICE-SETGID-SETUID
This code snippet shows how you can create a pod running a root but limited to a subset of capabilities by specifying a security context. Figure 4-3 shows commands you can run to verify that the pod runs as root with the limited set of capabilities.

Figure 4-3. Four allowed pod capabilities
Pod securityContext, as shown in Figure 4-3, can be used without enabling PSPs cluster-wide, but once the PSPs are enabled, you need to define securityContext to make sure pods are created properly. Since the securityContext has a PSP construct, all the PSPs’ capabilities apply to securityContext.
Limitations of PSPs
Some of the limitations of PSPs include:
-
PodSecurityPolicySpec has references to allowedCapabilities, privileged, or hostNetwork. These enforcements can work only on Linux-based runtimes.
-
If you are creating a pod using controllers (e.g., replication controller), it’s worth checking if PSPs are authorized for use by those controllers.
-
Once PSPs are enabled cluster-wide and a pod doesn’t start because of an incorrect PSP, it becomes hectic to troubleshoot the issue. Moreover, if PSPs are enabled cluster-wide in production clusters, you need to test each and every component in your cluster, including dependencies like mutating admission controllers and conflicting verdicts.
-
Azure Kubernetes Service (AKS) has deprecated support for PSPs and preferred OPA Gatekeeper for policy enforcement to support more flexible policies using the OPA engine.
-
PSP are deprecated and scheduled to be removed by Kubernetes v1.25.
-
Kubernetes can have edge cases where PSPs can be bypassed (e.g., TOB-K8S-038).
Now that you understand PSPs, best practices to implement them, and the limitations of PSPs, let’s look at process monitoring.
Process Monitoring
When you containerize a workload and run it on a host with an orchestrator like Kubernetes, there are a number of layers you need to take into consideration for monitoring a process inside a container. These start with container process logs and artifacts, filesystem access, network connections, system calls required, kernel permission (specialized workload), Kubernetes artifacts, and cloud infrastructure artifacts. Usually your organization’s security posture depends on how good your solutions are in stitching together these various log contexts. And this is where the traditional monitoring system fails measurably and a need for Kubernetes’ native monitoring and observability arises. Traditional solutions, like endpoint detection and response (EDR) and endpoint protection systems, have the following limitations when used in Kubernetes clusters:
-
They are not container aware.
-
They are not aware of container networking and typically see activity from the host perspective, which can lead to false negatives on attackers’ lateral movements.
-
They are blind to traffic between containers and don’t have any sight of underlays like IPIP or VXLAN.
-
They are not aware of process privileges and file permissions of containers accessing the underlying host.
-
They are not aware of the Kubernetes container runtime interface (CRI) or its intricacies and security issues, which can lead to containers being able to access resources on the host. This is also known as privilege escalation.
In the following sections, we will go over various techniques you can use for process monitoring. First we look at monitoring using various logs available in Kubernetes; then we explore seccomp, SELinux, and AppArmor features that allow you to control what a process can access (e.g., system calls, filesystem, etc.)
Kubernetes Native Monitoring
As shown in Figure 4-4, each layer leading up to your containerized application process introduces monitoring and logging requirements and a new attack surface that is different from what traditional IT security practitioners are used to for monitoring networks and applications. The challenge is to reduce this monitoring overhead, as it can get really expensive for the storage and compute resources. The topic of metric collection and how to do this efficiently is covered in detail in Chapter 5.

Figure 4-4. Kubernetes native monitoring
In order to build defenses in each layer, the following are some options you should consider incorporating while choosing solutions:
-
Ability to block processes spawned by each container or Kubernetes orchestration creating containers.
-
Monitor kernel system calls used by each container process and ability to filter, block, and alert on suspicious calls to prevent containers accessing host resources.
-
Monitor each network connection (socket) originated by a container process and ability to enforce network policy.
-
Ability to isolate a container using network policy (or a node running this container) and pause it to investigate suspicious activities and collect forensics data in Kubernetes. The
pausecommand for Docker-based containers suspends processes in a container to allow for detailed analysis. Note that pausing a container will cause the container to suspend normal operation and should be used as a response to an event (e.g., security incident). -
Monitor filesystem reads and writes to know filesystem changes (binaries, packages) and additional isolation through mandatory access control (MAC) to prevent privilege escalations.
-
Monitor the Kubernetes audit log to know what Kubernetes API requests clients are making and detect suspicious activity.
-
Enable a cloud provider’s logging for your infrastructure and ability to detect suspicious activity in the cloud provider’s infrastructure.
There are many enterprise and open source solutions (e.g., Falco) that target groups of layers using various tools and mechanisms (like ebpf, kprobes, ptrace, tracepoints, etc.) to help build defense at various layers. You should look at their threat model and choose solutions that fulfill their requirements.
In the next section you will see some of the mechanisms that are offered by Kubernetes by bringing Linux defenses closer to the container, which will help you in monitoring and reducing the attack surface at various layers. The previous section focused on monitoring to allow you to detect unintended (malicious) behavior. The following mechanisms allow you to set controls to prevent unintended (malicious) behavior.
Kernel security features like seccomp, AppArmor, and SELinux can control what system calls are required for your containerized application, virtually isolate and customize each container for the workload it is running, and use MAC to provide access to resources like volume or filesystem that prevent container breakouts efficiently. Just using the feature with default settings can tremendously reduce the attack surface throughout your cluster. In the following sections you will look at each defense in depth and how it works in the Kubernetes cluster so that you can choose the best option for your threat model.
Seccomp
Seccomp is a Linux kernel feature that can filter system calls executed by the container on a granular basis. Kubernetes lets you automatically apply seccomp profiles loaded onto a node by Kubernetes runtimes like Docker, podman, or CRI-O. A simple seccomp profile consists of a list of syscalls and the appropriate action to take when a syscall is invoked. This action reduces the attack surface to only allowed syscalls, reducing the risk of privilege escalation and container escape.
In the following seccomp profile, a default action is SCMP_ACT_ERRNO, which denies a system call. But defaultAction for syscall chmod is overwritten with SCMP_ACT_ALLOW. Usually seccomp profiles are loaded into the directory /var/lib/kubelet/seccomp on all nodes by your runtimes. You can add your custom profile at the same place:
{"defaultAction":"SCMP_ACT_ERRNO","architectures":["SCMP_ARCH_X86_64","SCMP_ARCH_X86","SCMP_ARCH_X32"],"syscalls":[{"names":["chmod",],"action":"SCMP_ACT_ALLOW"}]}
To find the system calls used by your application, you can use strace as shown in the next example. For this example, you can list syscalls used by curl utility as follows:
$ strace -c -S name curl -sS google.com% time seconds usecs/call calls errors syscall------ ----------- ----------- --------- --------- ----------------4.56 0.000242 6 43 43 access0.06 0.000003 3 1 arch_prctl1.28 0.000068 10 7 brk0.28 0.000015 15 1 clone4.62 0.000245 5 48 close1.38 0.000073 73 1 1 connect0.00 0.000000 0 1 execve0.36 0.000019 10 2 fcntl4.20 0.000223 5 48 fstat0.66 0.000035 3 11 futex0.23 0.000012 12 1 getpeername0.13 0.000007 7 1 getrandom0.19 0.000010 10 1 getsockname0.24 0.000013 13 1 getsockopt0.15 0.000008 4 2 ioctl13.96 0.000741 7 108 mmap11.94 0.000634 7 85 mprotect0.32 0.000017 17 1 munmap11.02 0.000585 13 45 1 openat0.11 0.000006 6 1 pipe19.50 0.001035 115 9 poll0.08 0.000004 4 1 prlimit645.43 0.000288 6 45 read0.41 0.000022 22 1 recvfrom11.47 0.000609 17 36 rt_sigaction0.08 0.000004 4 1 rt_sigprocmask1.00 0.000053 53 1 sendto0.06 0.000003 3 1 set_robust_list0.04 0.000002 2 1 set_tid_address2.22 0.000118 30 4 setsockopt1.60 0.000085 43 2 socket0.08 0.000004 4 1 1 stat2.35 0.000125 21 6 write------ ----------- ----------- --------- --------- ----------------100.00 0.005308 518 46 total
The default seccomp profiles provided by the Kubernetes runtime contain a list of common syscalls that are used by most of the applications. Just enabling this feature forbids the use of dangerous system calls, which can lead to a kernel exploit and a container escape. The default Docker runtime seccomp profile is available for your reference.
Note
At the time of writing, the Docker/default profile was deprecated, so we recommend you use runtime/default as the seccomp profile instead.
Table 4-2 shows the options for deploying seccomp profile in Kubernetes via PSP annotations.
| Value | Description |
|---|---|
| runtime/default | Default container runtime profile |
| unconfined | No seccomp profile—this option is default in Kubernetes |
| localhost/<path> | Your own profile located on node, usually in /var/lib/kubelet/seccomp directory |
SELinux
In the recent past, every container runtime breakout (container escape or privilege escalation) was some kind of filesystem breakout (i.e., CVE-2019-5736, CVE-2016-9962, CVE-2015-3627, and more). SELinux mitigates these issues by providing control over who can access the filesystem and the interaction between resources (i.e., user, files, directories, memory, sockets, and more). In the cloud computing context, it makes sense to apply SELinux profiles to workloads to get better isolation and reduce attack surface by limiting filesystem access by the host kernel.
SELinux was originally developed by the National Security Agency in the early 2000s and is predominantly used on Red Hat- and centOS-based distros. The reason SELinux is effective is it provides a MAC, which greatly augments the traditional Linux discretionary access control (DAC) system.
Traditionally with the Linux DAC, users have the ability to change permissions on files, directories, and the process owned by them. And a root user has access to everything. But with SELinux (MAC), each OS resource is assigned a label by the kernel, which is stored as extended file attributes. These labels are used to evaluate SELinux policies inside the kernel to allow any interaction. With SELinux enabled, even a root user in a container won’t be able to access a host’s files in a mounted volume if the labels are not accurate.
SELinux operates in three modes: Enforcing, Permissive, and Disabled. Enforcing enables SELinux policy enforcement, Permissive provides warnings, and Disabled is to no longer use SELinux policies. The SELinux policies themselves can be further categorized into Targeted and Strict, where Targeted policies apply to particular processes and Strict policies apply to all processes.
The following is the SELinux label for Docker binaries on a host, which consists of <user:role:type:level>. Here you will see the type, which is container_runtime_exec_t:
$ ls -Z /usr/bin/docker*-rwxr-xr-x. root root system_u:object_r:container_runtime_exec_t:s0/usr/bin/docker-rwxr-xr-x. root root system_u:object_r:container_runtime_exec_t:s0/usr/bin/docker-current-rwxr-xr-x. root root system_u:object_r:container_runtime_exec_t:s0/usr/bin/docker-storage-setup
To further enhance SELinux, multicategory security (MCS) is used to allow users to label resources with a category. So a file labeled with a category can be accessed by only users or processes of that category.
Once SELinux is enabled, a container runtime like Docker, podman, or CRI-O picks a random MCS label to run the container. These MCS labels consist of two random numbers between 1 and 1023, and they are prefixed with the character “c” (category) and a sensitivity level (i.e., s0). So a complete MCS label looks like “s0:c1,c2.” As shown in Figure 4-5, a container won’t be able to access a file on a host or Kubernetes volume unless it is labeled correctly as needed. This provides an important isolation between resource interaction, which prevents many security vulnerabilities targeted toward escaping containers.

Figure 4-5. SELinux enforcing filesystem access
Next is an example of a pod deployed with SELinux profile; this pod won’t be able to access any host volume mount files unless they are labeled so:c123,c456 on host. Even though you see the entire host, the filesystem is mounted on the pod:
apiVersion:v1metadata:name:pod-se-linux-labelnamespace:defaultlabels:app:normal-appspec:containers:-name:app-containerimage:alpine:latestargs:["sleep","10000"]securityContext:seLinuxOptions:level:"s0:c123,c456"volumes:-name:rootfshostPath:path:/
Table 4-3 lists the CVEs pertaining to container escape that are prevented just by enabling SELinux on hosts. Though SELinux policies can be challenging to maintain, they are critical for a defense-in-depth strategy. Openshift, a Kubernetes distribution, comes with SELinux enabled in its default configuration with targeted policies; for other distros it’s worth checking the status.
| CVE | Description | Blocked by SELinux |
|---|---|---|
| CVE-2019-5736 | Allows attackers to overwrite host runc binary and consequently obtain host root access | Yes |
| CVE-2016-9962 | RunC exec vulnerability | Yes |
| CVE-2015-3627 | Insecure file-descriptor exploitation | Yes |
Kubernetes provides the following options to enforce SELinux in PSPs:
| Value | Description |
|---|---|
| MustRunAs | Need to have seLinuxOptions configured as shown in Figure 4-5. |
| RunAsAny | No defaults are provided in PSP (can be optionally configured on pod and deployments) |
AppArmor
Like SELinux, AppArmor was developed for Debian and Ubuntu operating systems. AppArmor works in a similar way to SELinux, where an AppArmor profile defines what a process has access to. Let’s look at an example of an AppArmor profile:
#include <tunables/global>/{usr/,}bin/ping flags=(complain) {#include <abstractions/base>#include <abstractions/consoles>#include <abstractions/nameservice>capability net_raw,capability setuid,network inet raw,/bin/ping mixr,/etc/modules.conf r,# Site-specific additions and overrides. See local/README for details.#include <local/bin.ping>}
Here a ping utility has only three capabilities (i.e., net_raw, setuid, and inet raw and read access to /etc/modules.conf). With these permissions a ping utility cannot modify or write to the filesystem (keys, binaries, settings, persistence) or load any modules, which reduces attack surface for the ping utility to perform any malicious activity in case of a compromise.
By default, your Kubernetes runtime like Docker, podman, or CRI-O provides an AppArmor profile. Docker’s runtime profile is provided for your reference.
Since AppArmor is much more flexible and easy to work with, we recommend having a policy per microservice. Kubernetes provides the following options to enforce these policies via PSP annotations:
| Value | Description |
|---|---|
| runtime/default | Runtime’s default policy |
| localhost/<profile_name> | Apply profile loaded on host, usually in directory /sys/kernel/security/apparmor/profiles |
| unconfined | No profile will be loaded |
Sysctl
Kubernetes sysctl allows you to use the sysctl interface to use and configure kernel parameters in your cluster. An example of using sysctls is to manage containers with resource-hungry workloads that need to handle a large number of concurrent connections or need a special parameter set (i.e., IPv6 forwarding) to run efficiently. In such cases, sysctl provides a way to modify kernel behavior only for those workloads without affecting the rest of the cluster.
The sysctls are categorized into two buckets: safe and unsafe. Safe sysctl only affects the containers, but unsafe sysctl affects the container and node it is running on. Sysctl lets administrators set both the sysctl buckets at their discretion.
Let’s take an example where a containerized web server needs to handle a high number of concurrent connections and needs to set the net.core.somaxconn value to a higher number than the kernel default. In this case it can be set as follows:
apiVersion:v1kind:Podmetadata:name:sysctl-examplespec:securityContext:sysctls:-name:net.core.somaxconnvalue:"1024"
Please note that we recommend that you use node affinity to schedule workloads on nodes that have the sysctl applied, in case you need to use a sysctl that applies to the node. The following example shows how PSPs allow sysctls to be forbidden or allowed:
apiVersion:policy/v1beta1kind:PodSecurityPolicymetadata:name:sysctl-pspspec:allowedUnsafeSysctls:-kernel.msg*forbiddenSysctls:-kernel.shm_rmid_forced
Conclusion
In this chapter we covered tools and best practices for defining and implementing your workload runtime security. The most important takeaways are:
-
Pod security policies are an excellent way to enable workload controls at workload creation time. They have limitations but can be used effectively.
-
You need to pick a solution that is native to Kubernetes for monitoring processes and implement controls based on your threat model for your workloads.
-
We recommend you review the various security options that are available in the Linux kernel and leverage the right set of features based on your use case.
Get Kubernetes Security and Observability now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

