Chapter 4. Choosing What to Care About: Attention and Transformers
In this chapter, we explore a fictional example of translating between English and a fantasy language to convey certain underlying concepts surrounding attention mechanisms. We then discuss in more technical terms how attention is achieved, which we will then extrapolate and view through the lens of the Transformer architecture. The task that these architectures will be applied to in this section is machine translation. We will begin with some observations about the human approach to translation. Once the key concepts have been explored, we discuss how attention and the Transformer architecture work from a technical standpoint. Lastly, we discuss key considerations of these models, where they are applicable as a solution, and key takeaways from the chapter.
Communicating Across Languages
Imagine that you are on a cruise to the Bahamas. Upon what you believe to be your arrival, the ship’s captain informs you, in English, that it seems that the ship has gotten lost inside the Bermuda Triangle, and you have instead arrived at an uncharted island. Unfortunately, the cruise vessel does not have enough fuel to return to course, so the captain asks you to go and speak with the islanders.
Upon hearing their native language, you are unable to recognize similarities of any language you are familiar with. You come up with a clever idea: why not point to, or mime, various objects and actions, and both you and the islanders will write the appropriate words in the sand. To you, their written language looks like a bunch of triangles and circles arranged in different configurations, but it clearly has the same concept of words and structure.
You point at yourself, write your name, and say it; an islander does the same. You point at the boat and write “boat,” and so on. Eventually, you have a mapping of their language to several basic English words, though you have little understanding of how to say, pronounce, or produce their language yourself, and some misunderstandings likely occurred during the process. You get to work trying to translate the English sentence, “The boat needs fuel so it can leave,” into their language. After much back and forth, you communicate the basic thought that you must refuel the boat, to which they happily oblige.
When you finally arrive back home, you are able to find a dictionary with their language and check what was said to ultimately get you back home: “Water dragon wants to bloom; it needs food.”1 This is not what you meant, but it had the intended effect. You keep looking through the dictionary and realize a couple of things:
- You were pretty successful communicating about objects. “Water dragon” makes sense as a translation for “boat”; and as a result, “food” makes sense for “fuel” since, ostensibly, dragons need to eat.
- You realize your blunder with “leave” turning into “bloom.” You had pointed to leaves on trees, forgetting that it’s only a quirk of English that “leaves” is both the plural of “leaf” and a conjugation of “to leave.” The islanders thought that you were pointing out what things on trees do, which is bloom. They were probably puzzled as to why you referred to your “water dragon” as blooming but still managed to successfully guess at your meaning.
- You had translated your sentence in chunks. You did not try to get across the entire representation at once. You started with the main topic—the boat—and the two things you wanted to communicate about it: it wanted to leave, and it needed food. You started causing confusion by apparently insisting that your boat needed to bloom. But by the time you moved on to explaining that it wanted food, both you and the islanders were able to set that aside and pay attention to only the agreed-upon fact that there was a boat, and, finally, that it was hungry. In translating the second half of your sentence, you were both paying attention (foreshadowing!) to only the “boat” part of the first half of your sentence.
Figure 4-1 illustrates this point extremely simply. When translating “The boat needs fuel” to “Water dragon needs food,” it is easy to realize which words are aligned for the translation.

Figure 4-1. Simple alignment of words in part of the sample translation.
To summarize, your translation encounter with the islanders had a few notable aspects. First, you focused on only a subset of the text to be translated at a time, so as not to muddle the communication channel with irrelevant information. Second, you used a variation in translation that makes sense: the easiest way to communicate “fuel” was to mime yourself eating, something all creatures do, and so for the translation it did not even matter who was doing the eating, you or the boat. Finally, you used another variation that made sense in only one language but became muddled in the other (the double meaning of “leave”); still, the overall final translation managed to be successful enough.
Attention for Language Modeling: Concentrating on Only the Relevant Input
Let’s now discuss in more technical terms how attention is achieved, specifically through the lens of the Transformer architecture. The motivation for attention is, once again, in the desire to mimic human behavior and our ability to focus on only the relevant context when processing any particular word. How can this be implemented in a neural network? Let’s go back to our Encoder-Decoder architecture in the preceding chapter.
Simply put, an attention mechanism is another layer in the neural network that allows the decoder to consult with both the final hidden layer, produced by the encoder, and a select subset of the original input to the encoder. In other words, attention is a filter for the relevant context. The attention layer is trained to decide what is relevant at the same time as the rest of the network is being trained.
Note
Attention acts as a filter for the relevant context for the current input text. It is trained to decide what is relevant at the same time as the rest of the network.
Figure 4-2 highlights the main architectural differences from the Encoder-Decoder architecture in Figure 3-3. The decoder still gets the last state of the hidden layer of the encoder, but it is now augmented with input from the attention layer, which directs the decoder where to look at each of its time steps. By the time the encoder is finished, the hidden layer holds information about the boat, fuel, and the former’s need of the latter. But to translate “boat,” considering anything else in the sentence is not relevant, and so the attention layer here would bring the focus entirely on the input, “boat,” and block out the rest of the input. The example in Figure 4-2 is extremely short, but it is easy to imagine how useful this becomes when the input text is long and convoluted.
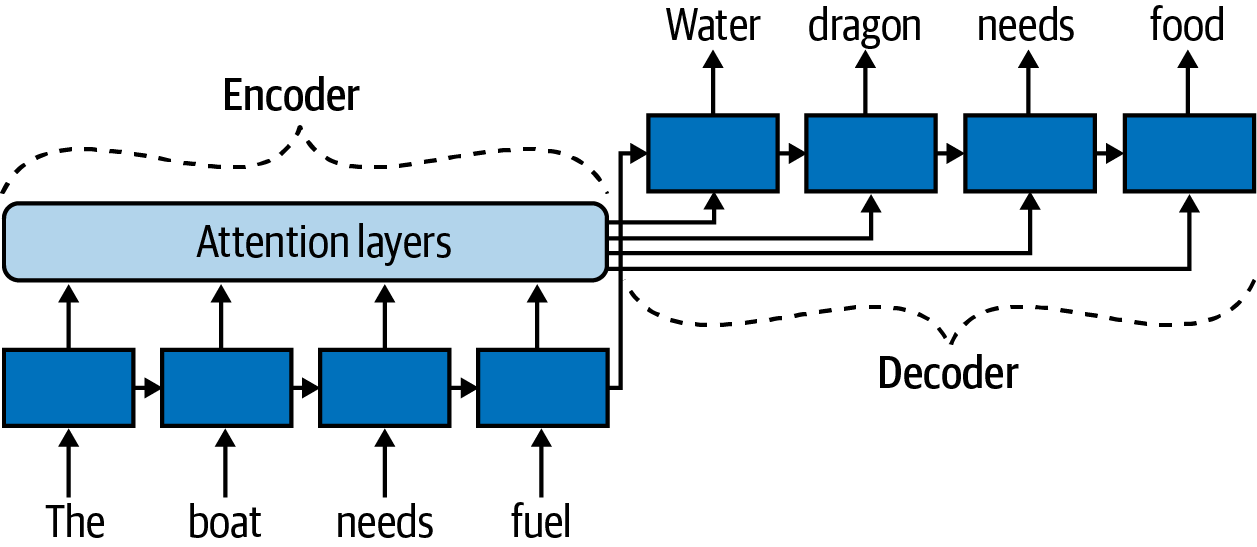
Figure 4-2. Adding an attention layer to an Encoder-Decoder architecture.
Note
We have chosen machine translation as the task through which we explain the attention mechanism, following in the footsteps of the academic paper that introduced attention to the NLP community via machine translation.2
Is Attention Interpretable?
Although we used a translation task to introduce attention, it is a general technique that can be used in many architectures, not only Encoder-Decoder, and, of course, is useful in many tasks beyond machine translation.
An interesting ongoing discussion is whether attention is interpretable, in the sense of providing an explanation for the model’s behavior. Attention does give a sort of soft alignment between input and output. Examining the attention scores at each time step of the decoder shows a particular interpretation of what the model had identified as the relevant context to be in the form of a distribution of scores over the input tokens. Therefore, you might decide that, by consulting this attention distribution, you can understand the decision taken by the decoder to emit that particular token. Alas, as with most aspects of deep learning, things are just not that simple!
First, attention can be quite noisy, and the relative importance of the context can vary across seemingly similar examples. Interestingly, especially with tasks such as classification, different attention distributions can nonetheless yield equivalent final predictions.3 In fact, it’s possible to directly interfere with the attention layer and force the model to ignore the most “attended to” tokens, and yet still yield the same output.4
These points should strengthen our intuition against relying on attention as a robust pointer to tokens that are “responsible for” the output of the model. Once again, no actual reasoning is going on, only associations. At best, attention can be thought of as giving a plausible reconstruction of the model’s decision process (it could have happened this way), though there’s no guarantee of faithfulness (what really happened?).
Note
Is attention interpretable? There are reasons to answer both yes and no, and this important discussion is actively ongoing.
Transformer Architecture for Language Modeling
Adding an attention layer to the Encoder-Decoder architecture definitely improves things. But we still have a strange—from our English-language perspective—constraint. Yes, we are trying to go from one sequence to another, but why do these sequences need to be processed left to right? After all, what if our example sentence was, “The boat wants to leave and so it needs fuel”? Does it really matter very much, for the final meaning of the translation, whether the leaving or the fuel is discussed first?
We would like to have access to the whole sentence when considering the context for a particular word. In fact, we often want to go beyond a single sentence. If our running example were two sentences—“The boat needs fuel. It wants to leave.”—we would have to cross sentence boundaries to see that “It” refers to “The boat.”
Yet, recall that when we first introduced neural networks, we pointed out the issues with using word windows, which grab all of the context within a certain number of tokens away. How can we still keep a sequence-to-sequence process, with the clear benefits of working with both long sequences and an attention layer, while breaking free from both the restrictions of fixed-width windows and the forced unidirectional processing of an RNN architecture?
Transformers address these concerns. Here is a broad outline of the Transformer architecture (Figure 4-3): first, stack multiple encoder layers, where each layer is an implementation of the neural network learning to pay attention to itself, by feeding the attention layer back into its own layers (rather than into a decoder layer as in Figure 4-2). The encoder stack is then followed by a stack of decoder layers doing the same thing. To be a little more precise, two attention mechanisms are between every pair of decoder layers, one for paying attention to itself, and one for paying attention to the encoder output. The model has access to the full input text, and the input and output sequences can still be different lengths.
The attention mechanism can now get even trickier. First, self-attention allows the model to understand what information is relevant in specific sequences—no matter their order. Second, instead of one mechanism informing a hidden layer, we can have several (this is called multihead attention). This approach is trying to mimic the fact that there are many reasons for a word to appear as context for another word that go far beyond simple alignment.
The Transformer architecture has three key aspects, in contrast to the architectures we have discussed previously:
- Stacked layers of neural networks
-
This is not a new concept by itself, as you may recall the brief comment on stacking RNNs to improve performance earlier in the report. But precisely how the layers are stacked is different. We are no longer just stacking hidden layers on top of each other like a sleeve of crackers; now we’re making sandwiches.
- Self-attention layer
-
Every encoder now comprises a layer of self-attention as well as a hidden layer, which is an attention mechanism for focusing the current hidden layer on subsets of the previous layer. Every decoder has a hidden layer and two other components—one for self-attention, and the second for paying attention to the encoder. See Figure 4-3 for a simple visualization.
- Multihead self-attention
-
There is now more than one way to focus on word context. Self-attention is now multiheaded.
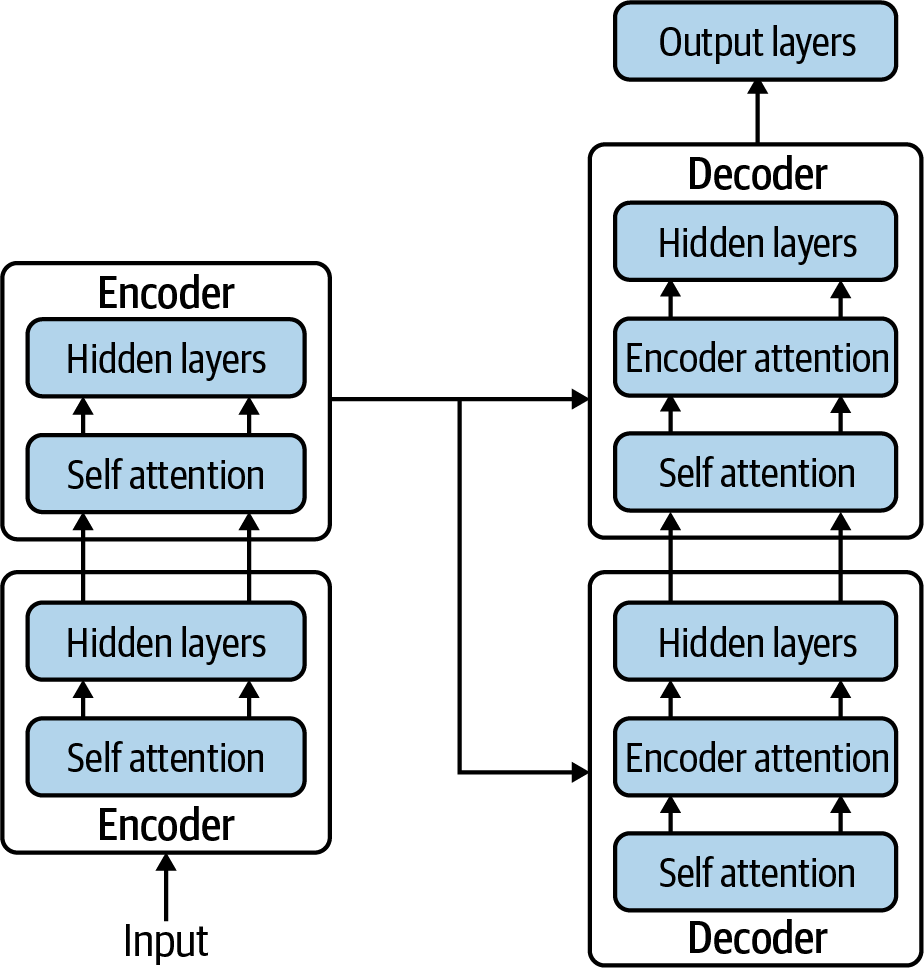
Figure 4-3. The Transformer architecture.
Multihead Attention
To explain the third point, multihead self-attention, with a concrete example, let’s pretend to be translating the sentence “I kicked the ball.” Take a look at Figure 4-4, which shows how we might think of attention information traveling from one layer to another.
Imagine three attention mechanisms working in parallel: the red one focuses on actions, the green one focuses on who does the action, and the blue one focuses on who (or what) the action is done to. Then, for “kicked” in the top layer, red attention focuses on the direct alignment with the same word from the bottom layer; green attention focuses on “I,” blue attention focuses on “ball,” and none of them cares much about the article, “the.”5 In another sentence, “She opened the window,” red attention focuses on “opened,” green attention focuses on “she,” and blue attention focuses on “window.”

Figure 4-4. A multihead attention mechanism (source: “Self-Attention for Generative Models” by Ashish Vaswani and Anna Huang).
Let’s immediately walk back the preceding paragraph. We cannot actually state that, for example, green attention is looking for the semantics of “who” is doing any particular action in a sentence. Again, LMs don’t understand meaning and have no concepts of semantics. This is helpful shorthand for us to represent the way in which a sufficiently large language model will discover associations that align closely with known linguistic structures.
Note
The original paper introducing the Transformer architecture stacked 6 encoders and 6 decoders, to form a deep neural network of 12 layers.6
Considerations on the Use of Transformer Architecture
We’ve explained the Transformer architecture by using the example of machine translation and Encoder-Decoder architecture, and things have already gotten fairly complicated. But we have just one more step to go: how is it that we have also been able to shift from a model that handles seq2seq tasks to the current state of the art: a pretrained language model (you are likely to have heard of BERT, Bidirectional Encoder Representations from Transformers) that can be fine-tuned (tweaked a bit with more training data) to all sorts of other tasks?
What part of the Transformer architecture is still playing “predict the next word”? The decoder. So what happens if we throw out half of the structure and create an architecture of only decoders? Generative Pretrained Transformer (GPT) models, introduced by OpenAI, are providing increasingly interesting results in text generation. But now we’ve gone back to only a unidirectional model! How can we train a Transformer-based model that looks at the full context of a word, both to the left and to the right?
Hold my beer, says BERT.7
Instead of trying to predict the next word while training its encoders, BERT masks, or hides, a small subset of the input text from itself and tries to guess it. BERT is playing fill in the blank. Now the model can look quite far to the left and right of each word as it tries to guess, and it repeats this game millions and millions of times. Having completed this (large-scale, in every sense) training process and built a complex representation of language, the model is now ready to be put to work on other tasks.
We will give a brief overview of how fine-tuning works on one example task: sentence classification. The training data for this fine-tuning step looks just like data for traditional machine learning classifiers, comprising pairs of sentences and labels. The input sequence is constructed from a special token called <CLASS>,8 followed by the sentence, and the output is the label. BERT is tasked with guessing the value of <CLASS>.
The amazing thing is that this approach is quite effective when using the exact same pretrained BERT model across multiple tasks. Furthermore, this approach is frequently more successful than previous (differently structured) models that were constructed and trained to perform specifically on those tasks—while needing significantly less labeled training data (for fine-tuning). The language representation that this Transformer architecture has learned is both useful and flexible. It has transferred its knowledge of English generally from its original fill-in-the-blank training task to the new task (sentence classification or other). This is referred to as transfer learning.
Note
Transfer learning is pretraining one large language model, such as BERT, on a huge amount of unlabeled data, and fine-tuning this single model to many tasks with much smaller sets of labeled data.
Finally, we have come full circle to our first technical topic: embeddings. A pretrained BERT architecture model can be used just like GloVe or ELMo to create contextualized word embeddings, and you can feed these embeddings into your model!9 This is another way to make use of BERT, in contrast to using it as a model directly and fine-tuning it to your task.
We have arrived at the current state of the art in LMs, and they are large, powerful, and resource hungry. In the next (and last) chapter of this report, following our review of key takeaways, we get into the implications of this state of affairs.
Key Takeaways
This chapter has introduced the most recent advancements in neural network architectures for language modeling. We conclude by reemphasizing some important takeaways around the attention mechanism and Transformer architecture:
- Attention usually improves performance on sequence-to-sequence tasks by acting as a filter for only the relevant context for the input text.
- Attention mechanisms have become an expected component in LMs.
- Attention may seem to provide a convenient answer to the lack of interpretability of deep learning models. Alas, as with most aspects of deep learning, things are just not that simple. We must be careful to remember that everything is still an association, not reasoning.
There are three key aspects to Transformer architecture:
Multiple layers of encoders and decoders are stacked, with each decoder paying individual attention to the output from the encoder stack.
A self-attention layer is sandwiched between each pair in the encoder stack and each layer in the decoder stack. Self-attention allows the model to understand what information is relevant in specific sequences, no matter the order.
Inside these self-attention layers, multihead self-attention provides parallel attention mechanisms for focusing on word context in different ways.
- BERT is a powerful Transformer-based language model that doesn’t play “predict the next word” to train; it plays “fill in the blank.”
- Transfer learning is the use of a single pretrained model, such as BERT, on many NLP tasks (such as classification, question answering, translation, and summarization) by fine-tuning. This approach can outperform other models constructed to perform specifically on those tasks, while needing a significantly smaller amount of labeled data (as BERT is pretrained entirely on unlabeled data, only the fine-tuning step requires labeled data).
1 Yes, this is all reminiscent of an episode of The Twilight Zone.
2 Dzmitry Bahdanau et al., “Neural Machine Translation by Jointly Learning to Align and Translate,” ICLR 2015.
3 For further details, see “Attention Is Not Explanation” by Sarthak Jain and Byron C. Wallace, NAACL-HT 2019.
4 For further details, see “Learning to Deceive with Attention-Based Explanations,” by Danish Pruthi et al., 2020.
5 In a real Transformer architecture, some part of the attention mechanism will care about articles to ensure a grammatical output.
6 Ashish Vaswani et al., “Attention Is All You Need,” 2017.
7 A huge hat tip to Jay Alammar and his blog post, “The Illustrated BERT, ELMo, and Co.”, in particular. If this expression is new to you, you can read about “Hold My Beer” on Know Your Meme.
8 Recall the <START> and <STOP> tokens mentioned in the previous chapter.
9 Of course, there are variations of embeddings; researchers have been busy!
Get Language Models in Plain English now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

