In order to make the most effective use of your Linux system, you must understand how Linux organizes data. If you’re familiar with Microsoft Windows or another operating system, you’ll find it easy to learn how Linux organizes data, because most operating systems organize data in rather similar ways. This section explains how Linux organizes data. It also introduces you to several important Linux commands that work with directories and files.
Linux receives data from, sends data to, and stores data on devices. A device usually corresponds to a hardware unit, such as a keyboard or serial port. However, a device may have no hardware counterpart: the kernel creates several pseudodevices that you can access as devices but that have no physical existence. Moreover, a single hardware unit may correspond to several devices—for example, Linux defines each partition of a disk drive as a distinct device. Table 4-2 describes some typical Linux devices; not every system provides all these devices and some systems provide devices not shown in the table.
Table 4-2. Typical Linux Devices
|
Device |
Description |
|---|---|
|
|
Bus mouse |
|
|
Sound card |
|
|
CD-ROM drive |
|
|
Current virtual console |
|
|
Floppy drive
( |
|
|
Streaming tape drive not supporting rewind |
|
|
Non-SCSI hard drive
( |
|
|
Bus mouse |
|
|
Parallel port
( |
|
|
Modem |
|
|
Mouse |
|
|
Streaming tape drive supporting rewind |
|
|
Streaming tape drive
supporting rewind ( |
|
|
Streaming SCSI tape drive
not supporting rewind
( |
|
|
Pseudodevice that accepts unlimited output |
|
|
Printer |
|
|
Auxiliary pointing device, such as a trackball, or the knob on IBM’s Thinkpad |
|
|
Streaming tape drive not
supporting rewind ( |
|
|
SCSI device
( |
|
|
SCSI hard drive
( |
|
|
SCSI CD-ROM
( |
|
|
Streaming SCSI tape drive
supporting rewind ( |
|
|
Virtual console
( |
|
|
Modem
( |
|
|
Pseudodevice that supplies an inexhaustible stream of zero-bytes |
Whether you’re using Microsoft Windows or Linux, you
must format a partition before you can store data on
it. When you format a partition, Linux writes special data,
called a filesystem, on the
partition. The filesystem organizes the available space and
provides a directory that lets you assign a name to each
file, which is a set of stored
data. You can also group files into
directories, which function much like
the folders you create using the Microsoft Windows Explorer:
directories store information about the files they
contain.
Every CD-ROM and floppy diskette must also have a filesystem. The filesystem of a CD-ROM is written when the disk is created; the filesystem of a floppy diskette is rewritten each time you format it.
Microsoft Windows 95 lets you choose to format a partition
as a FAT or FAT32. Linux supports a wider variety of
filesystem types; Table 4-3 summarizes the
most common ones. The most important filesystem types are
ext2; which is used for Linux native partitions,
msdos, which is used for FAT partitions (and
floppy diskettes) of the sort created by MS-DOS and
Microsoft Windows; and iso9660, which is used
for CD-ROMs. Linux also provides the
vfat filesystem, which is used for
FAT32 partitions of the sort created by Microsoft Windows
9x. Linux also supports reading of Windows NT NTFS
filesystems; however, the support for writing such
partitions is not yet stable.
Table 4-3. Common Filesystem Types
|
Filesystem |
Description |
|---|---|
|
coherent |
A filesystem compatible with that used by Coherent Unix |
|
ext |
The predecessor of the
|
|
ext2 |
The standard Linux filesystem |
|
hpfs |
A filesystem compatible with that used by IBM’s OS/2 |
|
iso9660 |
The standard filesystem used on CD-ROMs |
|
minix |
An old Linux filesystem, still occasionally used on floppy diskettes |
|
msdos |
A filesystem compatible with Microsoft’s FAT filesystem, used by MS-DOS and Windows |
|
nfs |
A filesystem compatible with Sun’s Network File System |
|
ntfs |
A filesystem compatible with that used by Microsoft Windows NT’s NTFS filesystem |
|
sysv |
A filesystem compatible with that used by AT&T’s System V Unix |
|
vfat |
A filesystem compatible with Microsoft’s FAT32 filesystem, used by Windows 9x |
|
xenix |
A filesystem compatible with that used by Xenix |
If you’ve used MS-DOS, you’re familiar with the concepts of file and directory, and with various MS-DOS commands that work with files and directories. Under Linux, files and directories work much as they do under MS-DOS.
When you login to Linux, you’re placed in a special directory known as your home directory. Generally, each user has a distinct home directory, where the user creates personal files. This makes it simple for the user to find files previously created, because they’re kept separate from the files of other users.
The working directory—or current working directory, as it’s sometimes called—is the directory you’re currently working in. When you login to Linux, your home directory is your working directory. By using the cd command (which you’ll meet in a moment) you can change your working directory.
The directories of a Linux system are organized as a hierarchy. Unlike MS-DOS, which provides a separate hierarchy for each partition, Linux provides a single hierarchy that includes every partition. The topmost directory of the directory tree is the root directory, which is written using a forward slash (/), not the backward slash (\) used by MS-DOS to designate a root directory.
Figure 4-3 shows a hypothetical Linux
directory tree. The root directory contains six
subdirectories:
bin, dev,
etc, home,
tmp, and
usr. The home
directory has two subdirectories; each is the home
directory of a user and has the same name as the user who
owns it. The user named bill has
created two subdirectories in his home directory:
books and
school. The user named
patrick has created a single
subdirectory in his home directory:
school.
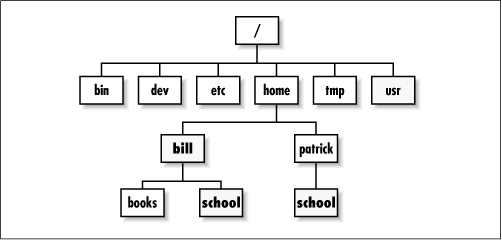
Each directory (other than the root directory) is
contained in a directory known as its parent
directory. For example, the parent directory of the
bill directory is
home.
Notice in the figure that two directories named
school exist: One is a subdirectory
of bill and the other is a
subdirectory of patrick. To avoid
confusion that could result when several directories have
the same name, directories are specified using
pathnames. Two kinds of pathnames
exist: absolute and
relative. The absolute pathname of a
directory traces the location of the directory beginning
at the root directory; you form the pathname as a list of
directories, separated by forward slashes
(/). For example, the absolute pathname of
the unique directory named bill is
/home/bill. The absolute pathname of
the school subdirectory of the
bill directory is
/home/bill/school. The absolute
pathname of the identically named
school subdirectory of the
patrick directory is
/home/patrick/school.
When a subdirectory is many levels below the root
directory, its absolute pathname may be long and
cumbersome. In such a case, it may be more convenient to
use a relative path name, which uses the current
directory, rather than the root directory, as its starting
point. For example, suppose that the
bill directory is the current working
directory; you can refer to its books
subdirectory by the relative pathname
books. Notice that a relative
pathname can never begin with a forward slash, whereas an
absolute pathname must begin with a forward slash. As a
second example, suppose that the home
directory is the current working directory. The relative
pathname of the school subdirectory
of the bill directory would be
bill/school; the relative pathname of
the identically named subdirectory of the
patrick directory would be
patrick/school.
Linux provides two special directory names. Using a
single dot (.) as a directory name is equivalent to
specifying the working directory. Using two dots (..)
within a pathname takes you up one level in the current
path, to the parent directory. For example, if the working
directory is /home/bill, .. refers to
the /home directory. Similarly, the
path ../patrick/school refers to the
directory
/home/patrick/school.
Now that you understand the fundamentals of how Linux organizes data, you’re ready to learn some commands that work with directories. Rather than simply read this section, you should login to your Linux system and try the commands for yourself. Only by doing so will you begin to develop skill in working with shell commands.
To display the current working directory, issue the pwd command. The pwd command requires no options or arguments.
root@desktop:/root# pwd
/rootThe pwd command displays the absolute pathname of the working directory.
To change the working directory, issue the
cd command, specifying the pathname of
the new working directory as an argument. You can use an
absolute or relative pathname. For example, to change the
working directory to the /bin
directory, type:
root@desktop:/root# cd /bin
[root@desktop /bin]#Notice how the prompt changes to indicate that
/bin is now the working
directory.
You can quickly return to your home directory by issuing the cd command without an argument:
[root@desktop /bin]# cd
root@desktop:/root#Again, notice how the prompt changes to indicate the new working directory.
If you attempt to change the working directory to a directory that doesn’t exist, Linux displays an error message:
root@desktop:/root# cd nowhere
bash: nowhere: No such file or directoryTo display the contents of a directory, you use the ls command. The ls command provides many useful options that let you tailor its operation and output to your liking.
The simplest form of the ls command takes no options or arguments. It simply lists the contents of the working directory, including files and subdirectories (your own output will differ, reflecting the files present in your working directory):
root@desktop:/root# ls
GNUstep firewall sniff
Xrootenv.0 linux ssh-1.2.26
audio.cddb mail ssh-1.2.26.tar.gz
audio.wav mirror support
axhome mirror-2.8.tar.gz temp
conf nlxb318l.tar test
corel openn test.doc
drivec.img scan tulip.c
dynip_2.00.tar.gz screen-3.7.6-0.i386.rpm win95
root@desktop:/root#Here, the output is presented in lexical (dictionary) order, as three columns of data. Notice that filenames beginning with uppercase letters appear before those beginning with lowercase letters.
A more sophisticated form of the ls command that includes the –l option displays descriptive information along with the filenames, as shown in Figure 4-4.
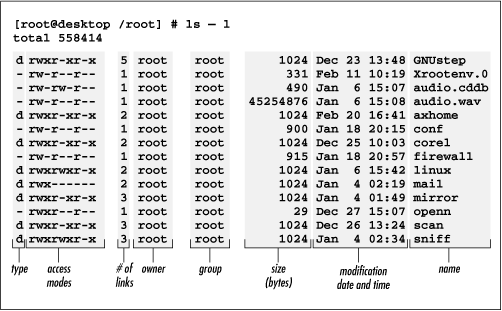
The first line of the output shows the amount of disk space used by the working directory and its subdirectories, measured in 1K blocks. Each remaining line describes a single file or directory. The columns are:
- Type
The type of file: a directory (
d), or an ordinary file (-). If your system supports color, Linux displays output lines that pertain to directories in blue and lines that pertain to files in white.- Access modes
The access mode, which determines the users that can and cannot access the file or directory.
- Links
- Group
- Size
- Modification date
The date and time when the file or directory was last modified.
- Name
You’ll learn more about access modes, links, and groups in subsequent sections of this chapter.
If a directory contains many files, the listing will fill more than one screen. To view the output one screen at a time, use the command:
ls -1 | more
This command employs the pipe redirector (|, explained in Chapter 13), sending output of the ls subcommand to the more subcommand, which presents the output one screen at a time. You can control the operation of the more command by using the following keys:
If you want to list a directory other than the working directory, you can type the name of the directory as an argument of the ls command. Linux displays the contents of the directory, but does not change the working directory. Similarly, you can display information about a file by typing its name as an argument of the ls command. Moreover, the ls command accepts indefinitely many arguments, so you can type a series of directories and filenames as arguments, separating each with one or more spaces or tabs.
When the name of a directory or file begins with a dot (.), the output of the ls command does not normally include the directory or file, which is said to be hidden. To cause the output of the ls command to include hidden directories and files, use the –a option. For example, to list all the files and subdirectories in the current directory—including hidden ones—type:
root@desktop:/root# ls -a -lIf you prefer, you can combine the –a and –l options, typing the command like this:
root@desktop:/root# ls -alA user’s home directory generally includes several
hidden files containing configuration information for
various programs. For example, the
.profile file contains configuration
information for the Linux shell.
The ls command provides a host of additional useful options; see its manual page for details.
You can create directories by using the mkdir command. Just type the name of the new directory as an argument of the command. Linux creates the directory as a subdirectory of the working directory. For example, this command creates a subdirectory named office:
root@desktop:/root# mkdir officeIf you don’t want to create the new directory as
a subdirectory of the working directory, type an absolute
or relative pathname as the argument. For example, to
create a directory named
/root/documents, type:
root@desktop:/root# mkdir /root/documentsThis works regardless of the current working directory.
The name of a directory or file must follow certain
rules. For example, it must not contain a slash
(/) character. Directory and file names usually
include letters (either uppercase or lowercase), digits,
dots, and underscores (_). You can use
other characters, such as spaces, but such names present
problems, because the shell gives them special meaning. If
you simply must use a name containing special characters,
enclose the name within single quotes
('). The quotes don’t become part of
the name that is stored on the disk. This technique is
useful when accessing files on a Microsoft Windows
filesystem; otherwise you’ll have trouble working with
files in directories such as My
Documents, which have names containing spaces.
Most MS-DOS filenames contain a dot, but most Linux
filenames do not. In MS-DOS, the dot separates the main
part of the filename from a part known as the extension,
which denotes the type of the file. For example, the
MS-DOS file memo.txt would contain
text. Most Linux programs determine the type of a file
automatically, so Linux filenames don’t require an
extension.
To remove a directory, use the rmdir command. For example, to remove unwanted, a subdirectory of the working directory, type:
root@desktop:/root# rmdir unwantedIf the directory you want to delete is not a subdirectory of the working directory, remove it by typing an absolute or relative pathname.
You cannot remove a directory that contains files or subdirectories with rmdir; you must first delete the files in the directory and then remove the directory itself. However, the command rm –r will recursively remove the files in a directory and then remove the directory.
Directories contain files and other directories. You use files to store data. This section introduces you to several useful commands for working with files.
Linux files, like Microsoft Windows files, can contain text or binary information. The contents of a binary file are meaningful only to skilled programmers, but you can easily view the contents of a text file. Simply type the cat command, specifying the name of the text file as an argument. For example:
root@desktop:/root# cat /etc/passwddisplays the contents of the
/etc/passwd file, which lists the
valid system logons.
If a file is too large to be displayed on a single screen, the first part of the file will whiz past you and you’ll see only the last few lines of the file. To avoid this, you can use the more command:
root@desktop:/root# more /etc/passwdThis command displays the contents of a file in the same way the man command displays a manual page. You can use Space and the b key to page forward and backward through the file and the q key to exit the command.
To remove a file, type the rm command, specifying the name of the file as an argument. For example:
root@desktop:/root# rm badfileremoves the file named badfile
contained in the working directory. If a file is located
elsewhere, you can remove it by specifying an absolute or
relative pathname.
Warning
Once you remove a Linux file, its contents are lost forever. Be careful to avoid removing a file that contains needed information.
The –i option causes the rm command to prompt you to verify your decision to remove a file. If you don’t trust your typing skills, you may find this option helpful. Linux automatically supplies the –i option even if you don’t type it.
To copy a file, use the cp command, specifying the name (or path) of the file you want to copy and the name (or path) to which you want to copy it. For example:
root@desktop:/root# cp /etc/passwd samplecopies the /etc/passwd file to a
file named sample in the working
directory.
If the destination file already exists, Linux overwrites it. You must therefore be careful to avoid overwriting a file that contains needed data. Before copying a file, use the ls command to ensure that no file will be overwritten; alternatively, use the –i option of the cp command, which prompts you to verify the overwriting of an existing file. Linux automatically supplies the –i option even if you don’t type it.
To rename a file, use the mv command, specifying the name (or path) of the file and the new name (or path). For example:
root@desktop:/root# mv old newrenames the file named old as new. If the destination file already exists, Linux overwrites it, so you must be careful. Before moving a file, use the ls command to ensure that no file will be overwritten; or, use the –i option of the mv command, which prompts you to verify the overwriting of an existing file. Linux automatically supplies the –i option even if you don’t type it.
The mv command can rename a directory, but cannot move a directory from one device to another. To move a directory to a new device, first copy the directory and its contents and then remove the original.
If you know the name of a file, but do not know what directory contains it, you can use the find command to locate the file. For example:
root@desktop:/root# find . -name 'missing' -printattempts to find a file named missing, located in (or beneath) the current working directory (.). If the command finds the file, it displays its absolute pathname.
If you know only part of the file name, you can surround the part you know with asterisks (*):
root@desktop:/root# find / -name '*iss*' -printThis command will find any file whose name includes
the characters iss, searching every
subdirectory of the root directory (that is, the entire
system).
If your system includes a printer, you can print a file by using the lpr command. For example:
root@desktop:/root# lpr /etc/passwdsends the file /etc/passwd to the
printer.
If a file is lengthy, it may require some time to print. You can send other files to the printer while a file is printing. The lpq command lets you see what files are queued to be printed:
root@desktop:/root# lpq
lp is ready and printing
Rank Owner Job Files Total Size
active root 155 /etc/passwd 1030 bytesEach waiting or active file has an assigned print job number. You can use the lprm to cancel printing of a file, by specifying the print job number. For example:
root@desktop:/root# lprm 155cancels printing of job number 155. However, only the user who requested that a file be printed (or the root user) can cancel printing of the file.
To save disk space and expedite downloads, you can
compress a data file. By convention, compressed files are
named ending in .gz; however, Linux
doesn’t require or enforce this convention.
To expand a compressed file, use the
gunzip command. For example, suppose
the file bigfile.gz has been
compressed. Typing the command:
root@desktop:/root# gunzip bigfile.gzextracts the file bigfile and
removes the file bigfile.gz.
To compress a file, use the gzip
command. For example, to compress the file
bigfile, type the command:
root@desktop:/root# gzip bigfileThe command creates the file
bigfile.gz and removes the file
bigfile.
Sometimes it’s convenient to store several files (or the contents of several subdirectories) in a single file. This is useful, for example, in creating a backup or archive copy of files. The Linux tar command creates a single file that contains data from several files. Unlike the gzip command, the tar command doesn’t disturb the original files. To create a tar file, as a file created by the tar command is called, a command like this:
tar -cvf tarfile files-or-directories
Substitute tarfile with the
name of the tar file you want to create and
files-or-directories with a list
of files and directories, separating the list elements by
one or more spaces or tabs. You can use absolute or
relative pathnames to specify the files or directories. By
convention, the name of a tar file ends with
.tar, but Linux does not require or
enforce this convention.
For example, to create a tar file named
backup.tar that contains all the
files in all subdirectories of the directory
/home/bill, type:
tar -cvf backup.tar /home/bill
The command creates the file
backup.tar in the current working
directory.
You can list the contents of a tar file by using a command that follows this pattern:
tar -tvf tarfile | moreThe | more causes the output to be
sent to the more command, so that you
can page through multiple pages. If the tar file holds
only a few files, you can omit the | more.
To extract the contents of a tar file, use a command that follows this pattern:
tar -xvf tarfileThis command expands the files and directories contained within the tar file as files and subdirectories of the working directory. If a file or subdirectory already exists, it is silently overwritten.
The tar command provides a host of useful options; see its manual page for details.
It’s common to compress a tar file. You can easily
accomplish this by specifying the options
–czvf instead of
–cvf. Compressed tar files are
conventionally named ending with
.tgz. To expand a compressed tar
file, specify the options –xzvf instead
of –xvf.
The tar command doesn’t use the common ZIP method of compression common in the Microsoft Windows world. However, Linux can easily work with, or even create, ZIP files. To create a ZIP file that holds compressed files or directories, issue a command like this one:
zip -r zipfile files_to_zipwhere zipfile names the ZIP
file that will be created and
files_to_zip specifies the
files and directories to be included in the ZIP
file.
To expand an existing ZIP file, issue a command like this one:
unzip zipfileMicrosoft Windows 9x supports shortcuts, which let you refer to a file or directory (folder) by several names. Shortcuts also let you include a file in several directories or a subdirectory within multiple parent directories. In Linux, you accomplish these results by using the ln command, which links multiple names to a single file or directory. These names are called symbolic links, soft links, or simply links.
To link a new name to an existing file or directory, type a command that follows this pattern:
ln -s old newFor example, suppose that the current working directory contains the file william. To be able to refer to this same file by the alternative name bill, type the command:
root@desktop:/root# ln -s william billThe ls command shows the result:
root@desktop:/root# ls -l
lrwxrwxrwx 1 root root 7 Feb 27 13:58 bill->william
-rw-r--r-- 1 root root 1030 Feb 27 13:26 williamThe new file (bill) has type l,
which indicates it’s a link, rather than a file or
directory. Moreover, the ls command
helpfully shows the name of the file to which the link
refers (william).
If you omit the –s option, Linux creates what’s called a hard link. A hard link must be stored on the same filesystem as the file to which it refers, a restriction that does not apply to symbolic links. The link count displayed by the ls command reflects only hard links; symbolic links are ignored.
Unlike Windows 98, but like other varieties of Unix and Windows NT, Linux is a multi-user operating system. Therefore, it includes mechanisms that protect data from unauthorized access. The primary protection mechanism restricts access to directories and files, based on the identity of the user who requests access and on access modes assigned to each directory and file, which are often called permissions.
Each directory and file has an associated user, called the owner, who created the directory or file. Each user belongs to one or more sets of users known as groups. Each directory and file has an associated group, which is assigned when the directory or file is created.
Groups can be used to let users other than
root perform system administration tasks or other
restricted tasks. For example, Debian GNU/Linux defines the group
dialout; only members of this group—and
root, of course—can access the system’s modem
and initiate a dial-up connection. By allowing only the members of a
particular group access to a program file, you can establish a
flexible, yet effective security policy.
To restrict access to a file or directory, you set its permissions. Table 4-4 lists the possible permissions and explains the meaning of each. Notice that permissions work differently for directories than for files. For example, permission r denotes the ability to list the contents of a directory or read the contents of a file. A directory or file can have more than one permission. Only the listed permissions are granted; any other operations are prohibited. For example, a user who had file permission rw could read or write the file, but could not execute it.
Table 4-4. Access Permissions
|
Permission |
Meaning for directory |
Meaning for file |
|---|---|---|
|
r |
List the directory |
Read contents |
|
w |
Create or remove files |
Write contents |
|
x |
Access files and subdirectories |
Execute |
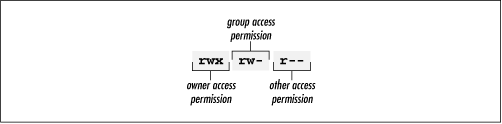
The access modes of a directory of file consist of three permissions:
The ls command lists the file access modes in the second column of its long output format, as shown in Figure 4-5. The column contains nine characters: the first three specify the access allowed the owner of the directory or file, the second three specify the access allowed users in the same group as the directory or file, and the final three specify the access allowed to other users (see Figure 4-6).
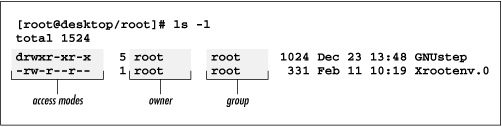
You set the access modes of a directory or file by using the chmod command, which has the following pattern:
chmod nnn directory-or-fileThe argument nnn is a
three-digit number, which gives the access mode for the
owner, group, and other users. Table 4-5
shows each possible digit and the equivalent access
permission. For example, the argument 751 is equivalent to
rwxr–x––x, which
gives the owner every possible permission, gives the group
read and execute permission, and gives other users execute
permission.
Table 4-5. Numerical Access Mode Values
|
Value |
Meaning |
|---|---|
|
0 |
|
|
1 |
|
|
2 |
|
|
3 |
|
|
4 |
|
|
5 |
|
|
6 |
|
|
7 |
|
If you’re the owner of a file or directory (or if
you’re the root user), you can change its ownership by
using the chown command. For example,
the following command assigns newuser
as the owner of the file
hotpotato:
root@desktop:/root# chown newuser hotpotatoThe owner of a file or directory (and the root user)
can also change the group of a file. For example, the
following command assigns newgroup as
the new group of the file
hotpotato:
root@desktop:/root# chgrp newgroup hotpotatoThe group you assign to a file or directory must have
been previously established by the root user. The valid
groups appear in the file /etc/group,
which only the root user can alter.
The root user can assign each user to one or more
groups. When you log on to the system, you are assigned to
one of these groups—your login
group—by default. To change to another of
your assigned groups, you can use the
newgrp command. For example, to change
to the group named secondgroup, use
the following command:
root@desktop:/root# newgrp secondgroupIf you attempt to change to a group that does not exist, or to which you have not been assigned, your command will fail. When you create a file or directory, it is automatically assigned your current group as its owning group.
In Linux, as in MS-DOS and Microsoft Windows, programs are stored in files. Often, you can launch a program by simply typing its filename. However, this assumes that the file is stored in one of a series of directories known as the path. A directory included in this series is said to be on the path. If you’ve worked with MS-DOS, you’re familiar with the MS-DOS path, which works much like the Linux path. You’ll learn more about working with the Linux path in Chapter 13.
If the file you want to launch is not stored in a directory on the path, you can simply type the absolute pathname of the file. Linux will then launch the program even though it’s not on the path. If the file you want to launch is stored in the working directory, type ./ followed by the name of the program file. Again, Linux will launch the program even though it’s not on the path.
For example, suppose the program
bigdeal is stored in the directory
/home/bob, which is the current
directory and which happens to be on the path. You could
launch the program any of these ways:
bigdeal ./bigdeal /home/bob/bigdeal
The first command assumes that the program is on the path. The second assumes that the program resides in the current working directory. The third makes no assumptions about the location of the file.
Get Learning Debian GNU/Linux now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

