Chapter 1. Welcome to GraphQL
Before the Queen of England made him a knight, Tim Berners-Lee was a programmer. He worked at CERN, the European particle physics laboratory in Switzerland, and was surrounded by a swath of talented researchers. Berners-Lee wanted to help his colleagues share their ideas, so he decided to create a network in which scientists could post and update information. The project eventually became the first web server and the first web client, and the “WorldWideWeb” browser (later renamed “Nexus”) was rolled out at CERN in December 1990.
With his project, Berners-Lee made it possible for researchers to view and update web content on their own computers. “WorldWideWeb” was HTML, URLs, a browser, and a WYSIWYG interface in which to update content.
Today, the internet isn’t just HTML in a browser. The internet is laptops. It’s wrist watches. It’s smartphones. It’s a radio-frequency identification (RFID) chip in your ski lift ticket. It’s a robot that feeds your cat treats while you’re out of town.
The clients are more numerous today, but we’re still striving to do the same thing: load data somewhere as fast as possible. We need our applications to be performant because our users hold us to a high standard. They expect our apps to work well under any condition: from 2G on feature phones to blazing-fast fiber internet on big-screen desktop computers. Fast apps make it easier for more people to interact with our content. Fast apps make our users happy. And, yes, fast apps make us money.
Getting data from a server to the client quickly and predictably is the story of the web, past, present, and future. Although this book will often dig in to the past for context, we’re here to talk about modern solutions. We’re here to talk about the future. We’re here to talk about GraphQL.
What Is GraphQL?
GraphQL is a query language for your APIs. It’s also a runtime for fulfilling queries with your data. The GraphQL service is transport agnostic but is typically served over HTTP.
To demonstrate a GraphQL query and its response, let’s take a look at SWAPI, the Star Wars API. SWAPI is a Representational State Transfer (REST) API that has been wrapped with GraphQL. We can use it to send queries and receive data.
A GraphQL query asks only for the data that it needs. Figure 1-1 is
an example of a GraphQL query. The query is on the left. We request the
data for a person, Princess Leia. We obtain Leia Organa’s record because we
specify that we want the fifth person (personID:5). Next, we ask for three fields of
data: name, birthYear, and created. On the right is our response: JSON
data formatted to match the shape of our query. This response contains
only the data that we need.
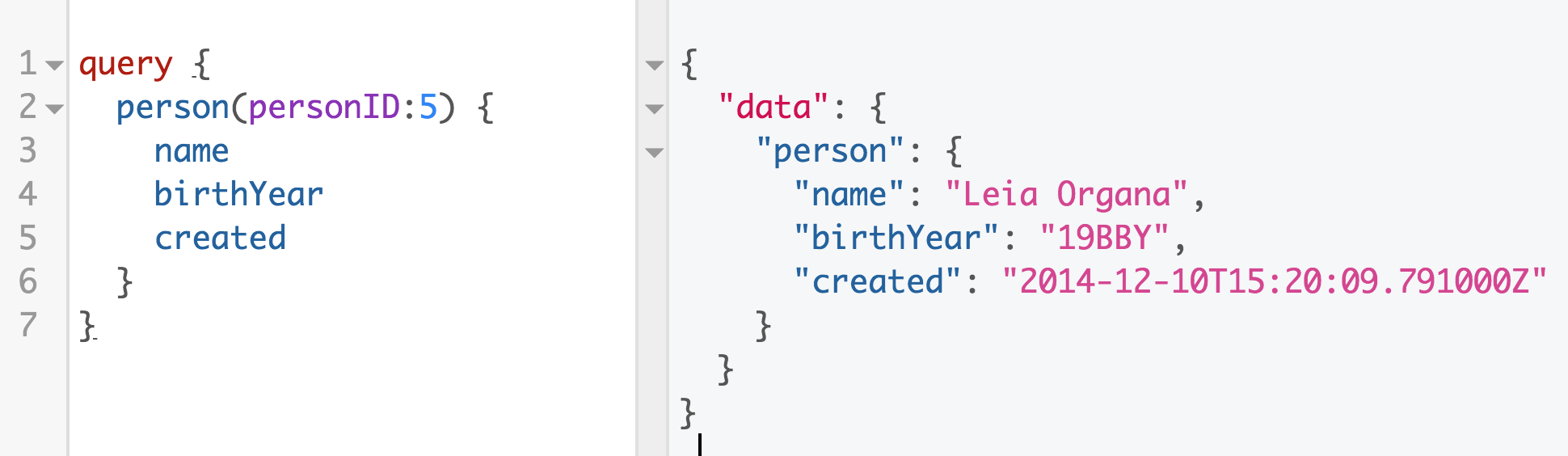
Figure 1-1. Person query for the Star Wars API
We can then adjust the query because queries are interactive. We can
change it and see a new result. If we add the field filmConnection, we
can request the title of each of Leia’s films, as Figure 1-2 shows.

Figure 1-2. Connection query
The query is nested, and when it is executed, can traverse related objects. This allows us to make one HTTP request for two types of data. We don’t need to make several round trips to drill down into multiple objects. We don’t receive additional unwanted data about those types. With GraphQL, our clients can obtain all of the data they need in one request.
Whenever a query is executed against a GraphQL server, it is validated
against a type system. Every GraphQL service defines types in a GraphQL
schema. You can think of a type system as a blueprint for your API’s
data, backed by a list of objects that you define. For example, the
person query from earlier is backed by a Person object:
type Person {
id: ID!
name: String
birthYear: String
eyeColor: String
gender: String
hairColor: String
height: Int
mass: Float
skinColor: String
homeworld: Planet
species: Species
filmConnection: PersonFilmsConnection
starshipConnection: PersonStarshipConnection
vehicleConnection: PersonVehiclesConnection
created: String
edited: String
}
The Person type defines all of the fields, along with their types, that
are available to query on Princess Leia. In Chapter 3, we dig deeper into the schema and GraphQL’s type system.
GraphQL is often referred to as a declarative data-fetching language. By that, we mean that developers will list their data requirements as what data they need without focusing on how they’re going to get it. GraphQL server libraries exist in a variety of different languages including C#, Clojure, Elixir, Erlang, Go, Groovy, Java, JavaScript, .NET, PHP, Python, Scala, and Ruby.1
In this book, we focus on how to build GraphQL services with JavaScript. All of the techniques that we discuss throughout this book are applicable to GraphQL in any language.
The GraphQL Specification
GraphQL is a specification (spec) for client-server communication. What is a spec? A spec describes the capabilities and characteristics of a language. We benefit from language specifications because they supply a common vocabulary and best practices for the community’s use of the language.
A fairly notable example of a software spec is the ECMAScript spec. Every once in a while, a group of representatives from browser companies, tech companies, and the community at large get together and devise what should be included in (and left out of) the ECMAScript spec. The same is true for GraphQL. A group of individuals got together and wrote what should be included in (and left out of) the language. This serves as a guideline for all of the implementations of GraphQL.
When the spec was released, the creators of GraphQL also shared a reference implementation of a GraphQL server in JavaScript—graphql.js. This is useful as a blueprint, but the goal of this reference implementation is not to mandate which language you use to implement your service. It’s merely a guide. After you have an understanding of the query language and the type system, you can build your server in any language you’d like.
If a spec and an implementation are different, what is actually in the spec? The spec describes the language and grammar you should use when writing queries. It also sets up a type system plus the execution and validation engines of that type system. Beyond that, the spec isn’t particularly bossy. GraphQL doesn’t dictate which language to use, how the data should be stored, or which clients to support. The query language has guidelines but the actual design of your project is up to you. (If you’d like to dig into the whole thing, you can explore the documentation.)
Design Principles of GraphQL
Even though GraphQL is not controlling about how you build your API, it does offer some guidelines for how to think about a service:2
- Hierarchical
-
A GraphQL query is hierarchical. Fields are nested within other fields and the query is shaped like the data that it returns.
- Product centric
-
GraphQL is driven by the data needs of the client and the language and runtime that support the client.
- Strong typing
-
A GraphQL server is backed by the GraphQL type system. In the schema, each data point has a specific type against which it will be validated.
- Client-specified queries
-
A GraphQL server provides the capabilities that the clients are allowed to consume.
- Introspective
-
The GraphQL language is able to query the GraphQL server’s type system.
Now that we have an introductory understanding of what the GraphQL spec is, let’s look at why it was created.
Origins of GraphQL
In 2012, Facebook decided that it needed to rebuild the application’s native mobile apps. The company’s iOS and Android apps were just thin wrappers around the views of the mobile website. Facebook had a RESTful server and FQL (Facebook’s version of SQL) data tables. Performance was struggling and the apps often crashed. At that point, engineers realized they needed to improve the way that data was being sent to their client applications.3
The team of Lee Byron, Nick Schrock, and Dan Schafer decided to rethink their data from the client side. They set out to build GraphQL, a query language that would describe the capabilities and requirements of data models for the company’s client/server applications.
In July 2015, the team released its initial GraphQL specification and a reference implementation of GraphQL in JavaScript called graphql.js. In September 2016, GraphQL left its “technical preview” stage. This meant that GraphQL was officially production-ready, even though it already had been used for years in production at Facebook. Today, GraphQL now powers almost all of Facebook’s data fetching and is used in production by IBM, Intuit, Airbnb, and more.
History of Data Transport
GraphQL presents some very new ideas but all should be understood in a historical context of data transport. When we think about data transport, we’re trying to make sense of how to pass data back and forth between computers. We request some data from a remote system and expect a response.
Remote Procedure Call
In the 1960s, remote procedure call (RPC) was invented. An RPC was initiated by the client, which sent a request message to a remote computer to do something. The remote computer sent a response to the client. These computers were different from clients and servers that we use today, but the flow of information was basically the same: request some data from the client, get a response from the server.
Simple Object Access Protocol
In the late 1990s, Simple Object Access Protocol (SOAP) emerged at Microsoft. SOAP used XML to encode a message and HTTP as a transport. SOAP also used a type system and introduced the concept of resource-oriented calls for data. SOAP offered fairly predictable results but caused frustration because SOAP implementations were fairly complicated.
REST
The API paradigm that you’re probably most familiar with today is REST. REST was defined in 2000 in Roy Fielding’s doctoral dissertation at University of California–Irvine. He described a resource-oriented architecture in which users would progress through web resources by performing operations such as GET, PUT, POST, and DELETE. The network of resources can be thought of as a virtual state machine, and the actions (GET, PUT, POST, DELETE) are state changes within the machine. We might take it for granted today, but this was pretty huge. (Oh, and Fielding did get his Ph.D.)
In a RESTful architecture, routes represent information. For example, requesting information from each of these routes will yield a specific response:
/api/food/hot-dog /api/sport/skiing /api/city/Lisbon
REST allows us to create a data model with a variety of endpoints, a far simpler approach than previous architectures. It provided a new way to handle data on the increasingly complex web but didn’t enforce a specific data response format. Initially, REST was used with XML. AJAX was originally an acronym that stood for Asynchronous JavaScript And XML, because the response data from an Ajax request was formatted as XML (it is now a freestanding word, spelled “Ajax”). This created a painful step for web developers: the need to parse XML responses before the data could be used in JavaScript.
Soon after, JavaScript Object Notation (JSON) was developed and standardized by Douglas Crockford. JSON is language agnostic and provides an elegant data format that many different languages can parse and consume. Crockford went on to write the seminal JavaScript: The Good Parts (O’Reilly, 2008) in which he let us know that JSON was one of the good parts.
The influence of REST is undeniable. It’s used to build countless APIs. Developers up and down the stack have benefitted from it. There are even devotees so interested in arguing about what is and is not RESTful that they’ve been dubbed RESTafarians. So, if that’s the case, why did Byron, Schrock, and Schafer embark on their journey to create something new? We can find the answer in some of REST’s shortcomings.
REST Drawbacks
When GraphQL was first released, some touted it as a replacement to REST. “REST is dead!” early adopters cried, and then encouraged us all to throw a shovel in the trunk and drive our unsuspecting REST APIs out to the woods. This was great for getting clicks on blogs and starting conversations at conferences, but painting GraphQL as a REST killer is an oversimplification. A more nuanced take is that as the web has evolved, REST has shown signs of strain under certain conditions. GraphQL was built to ease the strain.
Overfetching
Suppose that we’re building an app that uses data from the REST version of SWAPI. First, we need to load some data about character number 1, Luke Skywalker.4 We can make a GET request for this information by visiting https://swapi.co/api/people/1/. The response is this JSON data:
{"name":"Luke Skywalker","height":"172","mass":"77","hair_color":"blond","skin_color":"fair","eye_color":"blue","birth_year":"19BBY","gender":"male","homeworld":"https://swapi.co/api/planets/1/","films":["https://swapi.co/api/films/2/","https://swapi.co/api/films/6/","https://swapi.co/api/films/3/","https://swapi.co/api/films/1/","https://swapi.co/api/films/7/"],"species":["https://swapi.co/api/species/1/"],"vehicles":["https://swapi.co/api/vehicles/14/","https://swapi.co/api/vehicles/30/"],"starships":["https://swapi.co/api/starships/12/","https://swapi.co/api/starships/22/"],"created":"2014-12-09T13:50:51.644000Z","edited":"2014-12-20T21:17:56.891000Z","url":"https://swapi.co/api/people/1/"}
This is a huge response. The response exceeds our app’s data needs. We just need the information for name, mass, and height:
{"name":"Luke Skywalker","height":"172","mass":"77"}
This is a clear case of overfetching—we’re getting a lot of data back that we don’t need. The client requires three data points, but we’re getting back an object with 16 keys and sending information over the network that is useless.
In a GraphQL application, how would this request look? We still want Luke Skywalker’s name, height, and mass here in Figure 1-3.
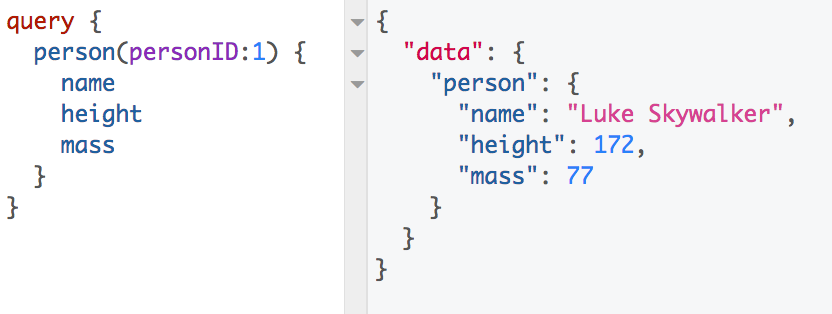
Figure 1-3. Luke Skywalker query
On the left, we issue our GraphQL query. We ask for only the fields that we want. On the right, we receive a JSON response, this time containing only the data that we requested, not 13 extra fields that are required to travel from a cell tower to a phone for no reason at all. We ask for data in a certain shape, we receive the data back in that shape. Nothing more, nothing less. This is more declarative and will likely yield a faster response given that extraneous data is not being fetched.
Underfetching
Our project manager just showed up at our desk and wants to add another feature to the Star Wars app. In addition to name, height, and mass, we now need to display a list of movie titles for all films that Luke Skywalker is in. After we request the data from https://swapi.co/api/people/1/, we still need to make additional requests for more data. This means we underfetched.
To get the title of each film, we need to fetch data from each of the routes in the films array:
"films":["https://swapi.co/api/films/2/","https://swapi.co/api/films/6/","https://swapi.co/api/films/3/","https://swapi.co/api/films/1/","https://swapi.co/api/films/7/"]
Getting this data requires one request for Luke Skywalker
(https://swapi.co/api/people/1/) and then five more for each of the
films. For each film, we get another large object. This time, we
use only one value.
{"title":"The Empire Strikes Back","episode_id":5,"opening_crawl":"...","director":"Irvin Kershner","producer":"Gary Kurtz, Rick McCallum","release_date":"1980-05-17","characters":["https://swapi.co/api/people/1/","https://swapi.co/api/people/2/","https://swapi.co/api/people/3/","https://swapi.co/api/people/4/","https://swapi.co/api/people/5/","https://swapi.co/api/people/10/","https://swapi.co/api/people/13/","https://swapi.co/api/people/14/","https://swapi.co/api/people/18/","https://swapi.co/api/people/20/","https://swapi.co/api/people/21/","https://swapi.co/api/people/22/","https://swapi.co/api/people/23/","https://swapi.co/api/people/24/","https://swapi.co/api/people/25/","https://swapi.co/api/people/26/"],"planets":[//...Longlistofroutes],"starships":[//...Longlistofroutes],"vehicles":[//...Longlistofroutes],"species":[//...Longlistofroutes],"created":"2014-12-12T11:26:24.656000Z","edited":"2017-04-19T10:57:29.544256Z","url":"https://swapi.co/api/films/2/"}
If we wanted to list the characters that are part of this movie, we’d need to make a lot more requests. In this case, we’d need to hit 16 more routes and make 16 more roundtrips to the client. Each HTTP request uses client resources and overfetches data. The result is a slower user experience, and users with slower network speeds or slower devices might not be able to view the content at all.
The GraphQL solution to underfetching is to define a nested query and then request the data all in one fetch, as Figure 1-4 shows.
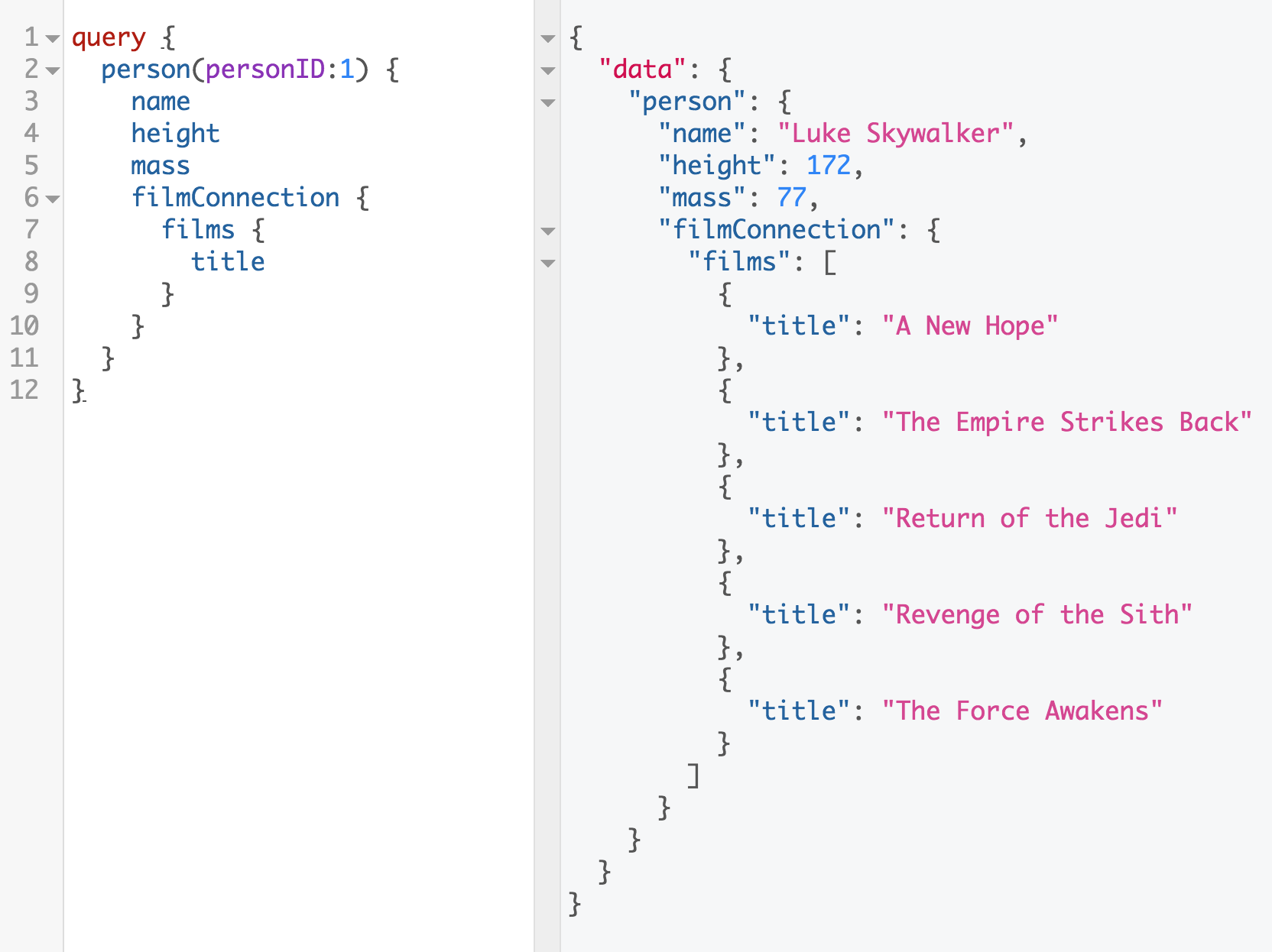
Figure 1-4. Films connection
Here, we receive only the data that we need in one request. And, as always, the shape of the query matches the shape of the returned data.
Managing REST Endpoints
Another common complaint about REST APIs is the lack of flexibility. As the needs on the client change, you usually have to create new endpoints, and those endpoints can begin to multiply quickly. To paraphrase Oprah, “You get a route! You get a route! Every! Body! Gets! A! Route!”
With the SWAPI REST API, we had to make requests to numerous routes. Larger
apps typically utilize custom endpoints to minimize HTTP requests. You
might see endpoints like /api/character-with-movie-title begin popping
up. Development speed can be slow because setting up new endpoints often
means that frontend and backend teams have more planning and
communication to do with each other.
With GraphQL, the typical architecture involves a single endpoint. The single endpoint can act as a gateway and orchestrate several data sources, but the one endpoint still makes organization of data easier.
In this discussion of REST drawbacks, it’s important to note that many organizations use GraphQL and REST together. Setting up a GraphQL endpoint that fetches data from REST endpoints is a perfectly valid way to use GraphQL. It can be a great way to incrementally adopt GraphQL at your organization.
GraphQL in the Real World
GraphQL is used by a variety of companies to power their apps, websites, and APIs. One of the most visible early adopters of GraphQL was GitHub. Its REST API went through three iterations, and version 4 of its public API uses GraphQL. As it mentions on the website, GitHub found that “the ability to define precisely the data you want-and only the data you want-is a powerful advantage over the REST API v3 endpoints.”
Other companies, like The New York Times, IBM, Twitter, and Yelp, have put their faith in GraphQL, as well, and developers from those teams are often found evangelizing the benefits of GraphQL at conferences.
There are at least three conferences devoted to GraphQL specifically: GraphQL Summit in San Francisco, GraphQL Finland in Helsinki, and GraphQL Europe in Berlin. The community continues to grow via local meetups and a variety of software conferences.
GraphQL Clients
As we’ve said numerous times, GraphQL is just a spec. It doesn’t care whether you’re using it with React or Vue or JavaScript or even a browser. GraphQL has opinions about a few specific topics, but beyond that, your architectural decisions are up to you. This has led to the emergence of tools to enforce some choices beyond the spec. Enter GraphQL clients.
GraphQL clients have emerged to speed the workflow for developer teams and improve the efficiency and performance of applications. They handle tasks like network requests, data caching, and injecting data into the user interface. There are many GraphQL clients, but the leaders in the space are Relay and Apollo.
Relay is Facebook’s client that works with React and React Native. Relay aims to be the connective tissue between React components and the data that is fetched from the GraphQL server. Relay is used by Facebook, GitHub, Twitch, and more.
Apollo Client was developed at Meteor Development Group and is a community-driven effort to build more comprehensive tooling around GraphQL. Apollo Client supports all major frontend development platforms and is framework agnostic. Apollo also develops tools that assist with the creation of GraphQL services, the performance enhancement of backend services, and tools to monitor the performance of GraphQL APIs. Companies, including Airbnb, CNBC, The New York Times, and Ticketmaster use Apollo Client in production.
The ecosystem is large and continues to change, but the good news is that the GraphQL spec is a pretty stable standard. In upcoming chapters, we discuss how to write a schema and create a GraphQL server. Along the way, there are learning resources to support your journey in this book’s GitHub repository: https://github.com/moonhighway/learning-graphql/. There you’ll find helpful links, samples, and all of the project files by chapter.
Before we dig in to the tactics of working with GraphQL, let’s talk a bit about graph theory and the rich history of the ideas found in GraphQL.
1 See the GraphQL Server Libraries at https://graphql.org/code/.
2 See the GraphQL Spec, June 2018.
3 See “Data Fetching for React Applications” by Dan Schafer and Jing Chen, https://www.youtube.com/watch?v=9sc8Pyc51uU.
4 Note that the SWAPI data doesn’t include the most recent Star Wars films.
Get Learning GraphQL now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

