Chapter 4. Basic Shell Programming
If you have become familiar with the customization techniques we presented in the previous chapter, you have probably run into various modifications to your environment that you want to make but can’t-yet. Shell programming makes these possible.
The Korn shell has some of the most advanced programming capabilities of any command interpreter of its type. Although its syntax is nowhere near as elegant or consistent as that of most conventional programming languages, its power and flexibility are comparable. In fact, the Korn shell can be used as a complete environment for writing software prototypes.
Some aspects of Korn shell programming are really extensions of the customization techniques we have already seen, while others resemble traditional programming language features. We have structured this chapter so that if you aren’t a programmer, you can read this chapter and do quite a bit more than you could with the information in the previous chapter. Experience with a conventional programming language like Pascal or C is helpful (though not strictly necessary) for subsequent chapters. Throughout the rest of the book, we will encounter occasional programming problems, called tasks, whose solutions make use of the concepts we cover.
Shell Scripts and Functions
A script, or file that contains shell commands, is a shell program. Your .profile and environment files, discussed in Chapter 7 are shell scripts.
You can create a script using the text editor of your choice. Once you have created one, there are two ways to run it. One, which we have already covered, is to type . scriptname (i.e., the command is a dot). This causes the commands in the script to be read and run as if you typed them in.
The second way to run a script is simply to type its name and hit RETURN, just as if you were invoking a built-in command. This, of course, is the more convenient way. This method makes the script look just like any other UNIX command, and in fact several “regular” commands are implemented as shell scripts (i.e., not as programs originally written in C or some other language), including spell, man on some systems, and various commands for system administrators. The resulting lack of distinction between “user command files” and “built-in commands” is one factor in UNIX’s extensibility and, hence, its favored status among programmers.
You can run a script by typing its name only
if . (the current directory) is part of your command
search path, i.e., is included in your PATH variable
(as discussed in Chapter 3). If . isn’t on your path,
you must type ./
scriptname, which is really the
same thing as typing the script’s absolute pathname
(see Chapter 1).
Before you can invoke the shell script by name, you must also give it “execute” permission. If you are familiar with the UNIX filesystem, you know that files have three types of permissions (read, write, and execute) and that those permissions apply to three categories of user (the file’s owner, a group of users, and everyone else). Normally, when you create a file with a text editor, the file is set up with read and write permission for you and read-only permission for everyone else.
Therefore you must give your script execute permission explicitly, by using the chmod(1) command. The simplest way to do this is to type:
$ chmod +x scriptname
Your text editor will preserve this permission if you make subsequent changes to your script. If you don’t add execute permission to the script and you try to invoke it, the shell will print the message:
scriptname: cannot execute.
But there is a more important difference between the two ways of running shell scripts. While the “dot” method causes the commands in the script to be run as if they were part of your login session, the “just the name” method causes the shell to do a series of things. First, it runs another copy of the shell as a subprocess; this is called a subshell. The subshell then takes commands from the script, runs them, and terminates, handing control back to the parent shell.
Figure 4.1 shows how the shell executes scripts. Assume you have a simple shell script called fred that contains the commands bob and dave. In Figure 4.1.a, typing .fred causes the two commands to run in the same shell, just as if you had typed them in by hand. Figure 4.1.b shows what happens when you type just fred: the commands run in the subshell while the parent shell waits for the subshell to finish.
You may find it interesting to compare this with the situation in Figure 4.1.c, which shows what happens when you type fred &. As you will recall from Chapter 1 the & makes the command run in the background, which is really just another term for “subprocess.” It turns out that the only significant difference between Figure 4.1.c and Figure 4.1.b is that you have control of your terminal or workstation while the command runsmdash;you need not wait until it finishes before you can enter further commands.
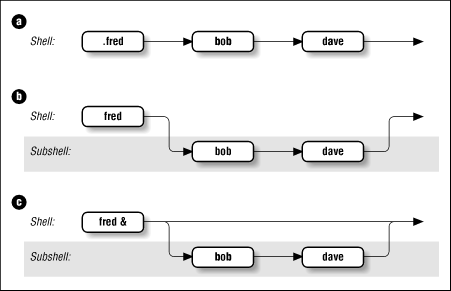
There are many ramifications to using subshells. An important one is that the exported environment variables that we saw in the last chapter (e.g., TERM, LOGNAME, PWD) are known in subshells, whereas other shell variables (such as any that you define in your .profile without an export statement) are not.
Other issues involving subshells are too complex to go into now; see Chapter 7, and Chapter 8, for more details about subshell I/O and process characteristics, respectively. For now, just bear in mind that a script normally runs in a subshell.
Functions
The Korn shell’s function feature is an expanded version of a similar facility in the System V Bourne shell and a few other shells. A function is sort of a script-within-a-script; you use it to define some shell code by name and store it in the shell’s memory, to be invoked and run later.
Functions improve the shell’s programmability significantly, for two main reasons. First, when you invoke a function, it is already in the shell’s memory (except for autoloaded functions; see section Section 4.1.1.1); therefore a function runs faster. Modern computers have plenty of memory, so there is no need to worry about the amount of space a typical function takes up. For this reason, most people define as many functions as possible rather than keep lots of scripts around.
The other advantage of functions is that they are ideal for organizing long shell scripts into modular “chunks” of code that are easier to develop and maintain. If you aren’t a programmer, ask one what life would be like without functions (also called procedures or subroutines in other languages) and you’ll probably get an earful.
To define a function, you can use either one of two forms:
function functname { shell commands }
or:
functname () { shell commands }
There is no difference between the two. Perhaps the first form was created to appeal to Pascal, Modula, and Ada programmers, while the second resembles C; in any case, we will use the first form in this book. You can also delete a function definition with the command unset -f functname.
When you define a function, you tell the shell to store its name and definition (i.e., the shell commands it contains) in memory. If you want to run the function later, just type in its name followed by any arguments, as if it were a shell script.
You can find out what functions are defined in your login session by typing functions. [41] The shell will print not just the names but the definitions of all functions, in alphabetical order by function name. Since this may result in long output, you might want to pipe the output through more or redirect it to a file for examination with a text editor.
Apart from the advantages, there are two important differences betweeen functions and scripts. First, functions do not run in separate processes, as scripts are when you invoke them by name; the “semantics” of running a function are more like those of your .profile when you log in or any script when invoked with the “dot” command. Second, if a function has the same name as a script or executable program, the function takes precedence.
This is a good time to show the order of precedence for the various sources of commands. When you type a command to the shell, it looks in the following places until it finds a match:
We’ll examine this process in more detail in the section on command-line processing in Chapter 7.
If you need to know the exact source of a command, there is an option to the whence built-in command that we saw in Chapter 3. whence by itself will print the pathname of a command if the command is a script or executable program, but it will only parrot the command’s name back if it is anything else. But if you type whence -v commandname, you get more complete information, such as:
$ whence -v cd cd is a shell builtin $ whence -v function function is a keyword $ whence -v man man is /usr/bin/man $ whence -v ll ll is an alias for ls -l
We will refer mainly to scripts throughout the remainder of this book, but unless we note otherwise, you should assume that whatever we say applies equally to functions.
Autoloaded functions
The simplest place to put your function definitions is in your .profile or environment file. This is fine for a small number of functions, but if you accumulate lots of them-as many shell programmers eventually do-you may find that logging in or invoking shell scripts (both of which involve processing your environment file) takes an unacceptably long time, and that it’s hard to navigate so many function definitions in a single file.
The Korn shell’s autoload feature addresses these problems. If you put the command autoload fname [43] in your .profile or environment file, instead of the function’s definition, then the shell won’t read in the definition of fname until it’s actually called. autoload can take more than one argument.
How does the shell know where to get the definition of an autoloaded function? It uses the built-in variable FPATH, which is a list of directories like PATH. The shell looks for a file called fname that contains the definition of function fname in each of the directories in FPATH.
For example, assume this code is in your environment file:
FPATH=~/funcs autoload dave
When you invoke the command dave, the shell will look in the directory ~/funcs for a file called dave that has the definition of function dave. If it doesn’t find the file, or if the file exists but doesn’t contain the proper function definition, the shell will complain with a “not found” message, just as if the command didn’t exist at all.
Function autoloading and FPATH are also useful tools for system administrators who need to set up system-wide Korn shell environments. See Chapter 10.
Shell Variables
A major piece of the Korn shell’s programming functionality relates to shell variables. We’ve already seen the basics of variables. To recap briefly: they are named places to store data, usually in the form of character strings, and their values can be obtained by preceding their names with dollar signs ($). Certain variables, called environment variables, are conventionally named in all capital letters, and their values are made known (with the export statement) to subprocesses.
If you are a programmer, you already know that just about every major programming language uses variables in some way; in fact, an important way of characterizing differences between languages is comparing their facilities for variables.
The chief difference between the Korn shell’s variable schema and those of conventional languages is that the Korn shell’s places heavy emphasis on character strings. (Thus it has more in common with a special-purpose language like SNOBOL than a general-purpose one like Pascal.) This is also true of the Bourne shell and the C shell, but the Korn shell goes beyond them by having additional mechanisms for handling integers (explicitly) and simple arrays.
Positional Parameters
As we have already seen, you can define values for variables with statements of the form varname = value, e.g.:
$ fred=bob $ print "$fred" bob
Some environment variables are predefined by the shell when you log in. There are other built-in variables that are vital to shell programming. We will look at a few of them now and save the others for later.
The most important special, built-in variables are called positional parameters. These hold the command-line arguments to scripts when they are invoked. Positional parameters have names 1, 2, 3, etc., meaning that their values are denoted by $1, $2, $3, etc. There is also a positional parameter 0, whose value is the name of the script (i.e., the command typed in to invoke it).
Two special variables contain all of the positional parameters
(except positional parameter 0): * and @.
The difference between them is subtle but important, and
it’s apparent only when they are within double quotes.
"
$*
" is a single string that consists of all of the positional
parameters, separated by the first character in the environment
variable IFS (internal field separator), which is a space, TAB, and
NEWLINE by default. On the other hand, "
$@
" is equal to
"
$1
"
"
$2
"
...
"
$
N
",
where N is the
number of positional parameters. That is, it’s equal to N
separate double-quoted strings, which are separated by spaces.
We’ll explore the ramifications of this difference in a little while.
The variable # holds the number of positional parameters (as a character string). All of these variables are “read-only,” meaning that you can’t assign new values to them within scripts.
For example, assume that you have the following simple shell script:
print "fred: $@" print "$0: $1 and $2" print "$# arguments"
Assume further that the script is called fred. Then if you type fred bob dave, you will see the following output:
fred: bob dave fred: bob and dave 2 arguments
In this case, $3, $4, etc., are all unset, which means that the shell will substitute the empty (or null) string for them. [44]
Positional parameters in functions
Shell functions use positional parameters and special variables
like * and # in exactly the same way as shell scripts do.
If you wanted to define fred as a function, you could put
the following in your .profile or environment file:
function fred {
print "fred: $*"
print "$0: $1 and $2"
print "$# arguments"
}
You will get the same result if you type fred bob dave.
Typically, several shell functions are defined within a single shell script. Therefore each function will need to handle its own arguments, which in turn means that each function needs to keep track of positional parameters separately. Sure enough, each function has its own copies of these variables (even though functions don’t run in their own subshells, as scripts do); we say that such variables are local to the function.
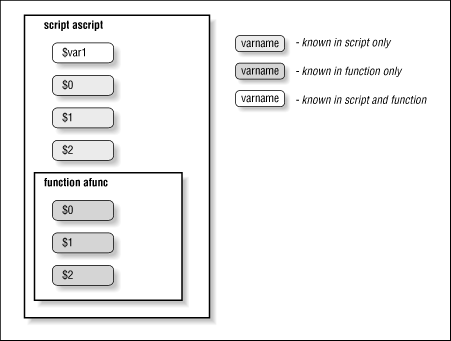
However, other variables defined within functions are not local [45] (they are global), meaning that their values are known throughout the entire shell script. For example, assume that you have a shell script called ascript that contains this:
function afunc {
print in function $0: $1 $2
var1="in function"
}
var1="outside of function"
print var1: $var1
print $0: $1 $2
afunc funcarg1 funcarg2
print var1: $var1
print $0: $1 $2
If you invoke this script by typing ascript arg1 arg2, you will see this output:
var1: outside of function ascript: arg1 arg2 in function afunc: funcarg1 funcarg2 var1: in function ascript: arg1 arg2
In other words, the function afunc changes the value of the variable var1 from “outside of function” to “in function,” and that change is known outside the function, while $0, $1, and $2 have different values in the function and the main script. Figure 4.2 shows this graphically.
It is possible to make other variables local to
functions by using the typeset command, which we’ll see in
Chapter 6.
Now that we have this background,
let’s take a closer look at “$@” and “$
*
". These variables
are two of the shell’s greatest idiosyncracies, so we’ll discuss some
of the most common sources of confusion.
Why are the elements of “$
*" separated by the first character of IFS instead of just spaces? To give you output flexibility. As a simple example, let’s say you want to print a list of positional parameters separated by commas. This script would do it:IFS=, print $*
Changing IFS in a script is fairly risky, but it’s probably OK as long as nothing else in the script depends on it. If this script were called arglist, then the command arglist bob dave ed would produce the output bob,dave,ed. Chapter 10 contains another example of changing IFS.
Why does “$@” act like N separate double-quoted strings? To allow you to use them again as separate values. For example, say you want to call a function within your script with the same list of positional parameters, like this:
function countargs { print "$# args." }Assume your script is called with the same arguments as arglist above. Then if it contains the command countargs
"$*", the function will print 1 args. But if the command is countargs"$@", the function will print 3 args.
More on Variable Syntax
Before we show the many things you can do with shell variables, we have to make a confession: the syntax of $ varname for taking the value of a variable is not quite accurate. Actually, it’s the simple form of the more general syntax, which is ${ varname }.
Why two syntaxes? For one thing, the more general syntax is necessary if your code refers to more than nine positional parameters: you must use ${10} for the tenth instead of $10. Aside from that, consider the example, from Chapter 3, of setting your primary prompt variable (PS1) to your login name:
PS1="($LOGNAME)-> "
This happens to work because the right parenthesis immediately following LOGNAME is “special” (in the sense of the special characters introduced in Chapter 1) so that the shell doesn’t mistake it for part of the variable name. Now suppose that, for some reason, you want your prompt to be your login name followed by an underscore. If you type:
PS1="$LOGNAME_ "
then the shell will try to use “LOGNAME_” as the name of the variable, i.e., to take the value of $LOGNAME_. Since there is no such variable, the value defaults to null (the empty string, “”), and PS1 is set to just a single space.
For this reason, the full syntax for taking the value of a variable is ${ varname }. So if we used
PS1="${LOGNAME}_ "
we would get the desired $ yourname _. It is safe to omit the curly brackets ({}) if the variable name is followed by a character that isn’t a letter, digit, or underscore.
String Operators
The curly-bracket syntax allows for the shell’s string operators. String operators allow you to manipulate values of variables in various useful ways without having to write full-blown programs or resort to external UNIX utilities. You can do a lot with string-handling operators even if you haven’t yet mastered the programming features we’ll see in later chapters.
In particular, string operators let you do the following:
Ensure that variables exist (i.e., are defined and have non-null values)
Set default values for variables
Catch errors that result from variables not being set
Remove portions of variables’ values that match patterns
Syntax of String Operators
The basic idea behind the syntax of string operators is that special characters that denote operations are inserted between the variable’s name and the right curly brackets. Any argument that the operator may need is inserted to the operator’s right.
The first group of string-handling operators tests for the existence of variables and allows substitutions of default values under certain conditions. These are listed in Table 4.1. [46]
| Operator | Substitution |
| ${ varname :- word } |
If varname exists and isn’t null, return its value; otherwise return word. |
| Purpose: |
Returning a default value if the variable is undefined. |
| Example: |
${count:-0} evaluates to 0 if count is undefined. |
| ${ varname := word} |
If varname exists and isn’t null, return its value; otherwise set it to word and then return its value.[a] |
| Purpose: |
Setting a variable to a default value if it is undefined. |
| Example: |
|
${
varname
:?
message
}
|
If varname exists and isn’t null, return its value; otherwise print varname : followed by message, and abort the current command or script. Omitting message produces the default message parameter null or not set. |
| Purpose: |
Catching errors that result from variables being undefined. |
| Example: |
{count
|
${
varname
:+
word
}
|
If varname exists and isn’t null, return word; otherwise return null. |
| Purpose: |
Testing for the existence of a variable. |
| Example: |
${count:+1} returns 1 (which could mean “true”) if count is defined. |
[a] Pascal, Modula, and Ada programmers may find it helpful to recognize the similarity of this to the assignment operators in those languages. | |
The first two of these operators are ideal for setting defaults for command-line arguments in case the user omits them. We’ll use the first one in our first programming task.
By far the best approach to this type of script is to use built-in UNIX utilities, combining them with I/O redirectors and pipes. This is the classic “building-block” philosophy of UNIX that is another reason for its great popularity with programmers. The building-block technique lets us write a first version of the script that is only one line long:
sort -nr $1 | head -${2:-10}
Here is how this works: the sort(1) program sorts the data in the file whose name is given as the first argument ($1). The -n option tells sort to interpret the first word on each line as a number (instead of as a character string); the -r tells it to reverse the comparisons, so as to sort in descending order.
The output of sort is piped into the head(1) utility, which, when given the argument - N, prints the first N lines of its input on the standard output. The expression -${2:-10} evaluates to a dash (-) followed by the second argument if it is given, or to -10 if it’s not; notice that the variable in this expression is 2, which is the second positional parameter.
Assume the script we want to write is called highest. Then if the user types highest myfile, the line that actually runs is:
sort -nr myfile | head -10
Or if the user types highest myfile 22, the line that runs is:
sort -nr myfile | head -22
Make sure you understand how the :- string operator provides a default value.
This is a perfectly good, runnable script-but it has a few problems. First, its one line is a bit cryptic. While this isn’t much of a problem for such a tiny script, it’s not wise to write long, elaborate scripts in this manner. A few minor changes will make the code more readable.
First, we can add comments to the code; anything between # and the end of a line is a comment. At a minimum, the script should start with a few comment lines that indicate what the script does and what arguments it accepts. Second, we can improve the variable names by assigning the values of the positional parameters to regular variables with mnemonic names. Finally, we can add blank lines to space things out; blank lines, like comments, are ignored. Here is a more readable version:
#
# highest filename [howmany]
#
# Print howmany highest-numbered lines in file filename.
# The input file is assumed to have lines that start with
# numbers. Default for howmany is 10.
#
filename=$1
howmany=${2:-10}
sort -nr $filename | head -$howmany
The square brackets around howmany in the comments adhere to the convention in UNIX documentation that square brackets denote optional arguments.
The changes we just made improve the code’s readability but not how it runs. What if the user were to invoke the script without any arguments? Remember that positional parameters default to null if they aren’t defined. If there are no arguments, then $1 and $2 are both null. The variable howmany ($2) is set up to default to 10, but there is no default for filename ($1). The result would be that this command runs:
sort -nr | head -10
As it happens, if sort is called without a filename argument, it expects input to come from standard input, e.g., a pipe (|) or a user’s terminal. Since it doesn’t have the pipe, it will expect the terminal. This means that the script will appear to hang! Although you could always type CTRL-D or CTRL-C to get out of the script, a naive user might not know this.
Therefore we need to make sure that the user supplies at least one argument. There are a few ways of doing this; one of them involves another string operator. We’ll replace the line:
filename=$1
with:
filename=${1:?"filename missing."}
This will cause two things to happen if a user invokes the script without any arguments: first the shell will print the somewhat unfortunate message:
highest: 1: filename missing.
to the standard error output. Second, the script will exit without running the remaining code.
With a somewhat “kludgy” modification, we can get a slightly better error message. Consider this code:
filename=$1
filename=${filename:?"missing."}
This results in the message:
highest: filename: missing.
(Make sure you understand why.) Of course, there are ways of printing whatever message is desired; we’ll find out how in Chapter 5.
Before we move on, we’ll look more closely at the two remaining operators in Table 4.1 and see how we can incorporate them into our task solution. The := operator does roughly the same thing as :-, except that it has the “side effect” of setting the value of the variable to the given word if the variable doesn’t exist.
Therefore we would like to use := in our script in place of :-, but we can’t; we’d be trying to set the value of a positional parameter, which is not allowed. But if we replaced:
howmany=${2:-10}
with just:
howmany=$2
and moved the substitution down to the actual command line (as we did at the start), then we could use the := operator:
sort -nr $filename | head -${howmany:=10}
Using := has the added benefit of setting the value of howmany to 10 in case we need it afterwards in later versions of the script.
The final substitution operator is :+. Here is how we can use it in our example: Let’s say we want to give the user the option of adding a header line to the script’s output. If he or she types the option -h, then the output will be preceded by the line:
ALBUMS ARTIST
Assume further that this option ends up in the variable header, i.e., $header is -h if the option is set or null if not. (Later we will see how to do this without disturbing the other positional parameters.)
The expression:
${header:+"ALBUMS ARTIST\n"}
yields null if the variable header is null, or ALBUMS ARTIST\n if it is non-null. This means that we can put the line:
print -n ${header:+"ALBUMS ARTIST\n"}
right before the command line that does the actual work. The -n option to print causes it not to print a LINEFEED after printing its arguments. Therefore this print statement will print nothing-not even a blank line-if header is null; otherwise it will print the header line and a LINEFEED (\n).
Patterns and Regular Expressions
We’ll continue refining our solution to Task 4-1 later in this chapter.
The next type of string operator is used to match portions of a
variable’s string value against patterns.
Patterns, as we saw in Chapter 1 are strings that can contain
wildcard characters (*, ?, and [] for character sets and ranges).
Wildcards have been standard features of all UNIX shells going back (at least) to the Version 6 Bourne shell. But the Korn shell is the first shell to add to their capabilities. It adds a set of operators, called regular expression (or regexp for short) operators, that give it much of the string-matching power of advanced UNIX utilities like awk(1), egrep(1) (extended grep(1)) and the emacs editor, albeit with a different syntax. These capabilities go beyond those that you may be used to in other UNIX utilities like grep, sed(1) and vi(1).
Advanced UNIX users will find the Korn shell’s regular expression capabilities occasionally useful for script writing, although they border on overkill. (Part of the problem is the inevitable syntactic clash with the shell’s myriad other special characters.) Therefore we won’t go into great detail about regular expressions here. For more comprehensive information, the “last word” on practical regular expressions in UNIX is sed & awk, an O’Reilly Nutshell Handbook by Dale Dougherty. If you are already comfortable with awk or egrep, you may want to skip the following introductory section and go to Section 4.3.2.2 below, where we explain the shell’s regular expression mechanism by comparing it with the syntax used in those two utilities. Otherwise, read on.
Regular expression basics
Think of regular expressions as strings that match patterns more powerfully than the standard shell wildcard schema. Regular expressions began as an idea in theoretical computer science, but they have found their way into many nooks and crannies of everyday, practical computing. The syntax used to represent them may vary, but the concepts are very much the same.
A shell regular expression can contain regular characters, standard wildcard characters, and additional operators that are more powerful than wildcards. Each such operator has the form x(exp ), where x is the particular operator and exp is any regular expression (often simply a regular string). The operator determines how many occurrences of exp a string that matches the pattern can contain. See Table 4.2 and Table 4.3.
| Operator | Meaning |
*(exp) | 0 or more occurrences of exp |
+(exp) | 1 or more occurrences of exp |
?(exp) | 0 or 1 occurrences of exp |
| @(exp1|exp2|...) | exp1 or exp2 or... |
| !(exp) |
Anything that doesn’t match exp [a] |
[a] Actually, !( exp) is not a regular expression operator by the standard technical definition, though it is a handy extension. | |
| Expression | Matches |
| x | x |
*(x) | Null string, x, xx, xxx, ... |
+(x) | x, xx, xxx, ... |
?(x) | Null string, x |
!(x) | Any string except x |
@(x) | x (see below) |
Regular expressions are extremely useful when dealing with arbitrary text, as you already know if you have used grep or the regular-expression capabilities of any UNIX editor. They aren’t nearly as useful for matching filenames and other simple types of information with which shell users typically work. Furthermore, most things you can do with the shell’s regular expression operators can also be done (though possibly with more keystrokes and less efficiency) by piping the output of a shell command through grep or egrep.
Nevertheless, here are a few examples of how shell regular expressions can solve filename-listing problems. Some of these will come in handy in later chapters as pieces of solutions to larger tasks.
The emacs editor supports customization files whose names end in .el (for Emacs LISP) or .elc (for Emacs LISP Compiled). List all emacs customization files in the current directory.
In a directory of C source code, list all files that are not necessary. Assume that “necessary” files end in .c or .h, or are named Makefile or README.
Filenames in the VAX/VMS operating system end in a semicolon followed by a version number, e.g., fred.bob;23. List all VAX/VMS-style filenames in the current directory.
Here are the solutions:
In the first of these, we are looking for files that end in .el with an optional c. The expression that matches this is
*.el?(c).The second example depends on the four standard subexpressions
*.c,*.h, Makefile, and README. The entire expression is !(*.c|*.h|Makefile|README), which matches anything that does not match any of the four possibilities.The solution to the third example starts with
*\;: the shell wildcard*followed by a backslash-escaped semicolon. Then, we could use the regular expression +([0-9]), which matches one or more characters in the range [0-9], i.e., one or more digits. This is almost correct (and probably close enough), but it doesn’t take into account that the first digit cannot be 0. Therefore the correct expression is*\;[1-9]*([0-9]), which matches anything that ends with a semicolon, a digit from 1 to 9, and zero or more digits from 0 to 9.
Regular expression operators are an interesting addition to the Korn shell’s features, but you can get along well without them-even if you intend to do a substantial amount of shell programming.
In our opinion, the shell’s authors missed an opportunity to build into the wildcard mechanism the ability to match files by type (regular, directory, executable, etc., as in some of the conditional tests we will see in Chapter 5) as well as by name component. We feel that shell programmers would have found this more useful than arcane regular expression operators.
The following section compares Korn shell regular expressions to analogous features in awk and egrep. If you aren’t familiar with these, skip to the section Section 4.3.3
Korn shell versus awk/egrep regular expressions
Table 4.4 is an expansion of Table 4.2: the middle column shows the equivalents in awk/egrep of the shell’s regular expression operators.
| Korn Shell | egrep/awk | Meaning |
*(exp) |
exp
*
| 0 or more occurrences of exp |
| +(exp) | exp+ | 1 or more occurrences of exp |
?(exp) |
exp
?
| 0 or 1 occurrences of exp |
| @(exp1|exp2|...) | exp1|exp2|... | exp1 or exp2 or... |
| !(exp) | (none) | Anything that doesn’t match exp |
These equivalents are close but not quite exact. Actually, an exp within any of the Korn shell operators can be a series of exp1|exp2|... alternates. But because the shell would interpret an expression like dave|fred|bob as a pipeline of commands, you must use @(dave|fred|bob) for alternates by themselves.
For example:
@(dave|fred|bob) matches dave, fred, or bob.
*(dave|fred|bob) means, “0 or more occurrences of dave, fred, or bob“. This expression matches strings like the null string, dave, davedave, fred, bobfred, bobbobdavefredbobfred, etc.+(dave|fred|bob) matches any of the above except the null string.
?(dave|fred|bob) matches the null string, dave, fred, or bob.
!(dave|fred|bob) matches anything except dave, fred, or bob.
It is worth re-emphasizing that shell regular expressions can still
contain standard shell wildcards.
Thus, the shell wildcard ?
(match any single character) is the equivalent to . in
egrep or awk, and the shell’s character set operator
[...] is the same as in those utilities.
[47]
For example, the expression +([0-9]) matches a number, i.e.,
one or more digits. The shell wildcard character * is equivalent
to the shell regular expression *
(?).
A few egrep and awk regexp operators do not have equivalents in the Korn shell. These include:
The beginning- and end-of-line operators ^ and $.
The beginning- and end-of-word operators \< and \>.
Repeat factors like \{ N \} and \{ M , N \}.
The first two pairs are hardly necessary, since the Korn shell doesn’t normally operate on text files and does parse strings into words itself.
Pattern-matching Operators
Table 4.5 lists the Korn shell’s pattern-matching operators.
| Operator | Meaning |
| ${variable#pattern} |
If the pattern matches the beginning of the variable’s value, delete the shortest part that matches and return the rest. |
| ${variable##pattern} |
If the pattern matches the beginning of the variable’s value, delete the longest part that matches and return the rest. |
| ${variable%pattern} |
If the pattern matches the end of the variable’s value, delete the shortest part that matches and return the rest. |
| ${variable%%pattern} |
If the pattern matches the end of the variable’s value, delete the longest part that matches and return the rest. |
These can be hard to remember, so here’s a handy mnemonic device: # matches the front because number signs precede numbers; % matches the rear because percent signs follow numbers.
The classic use for pattern-matching operators is in stripping off components of pathnames, such as directory prefixes and filename suffixes. With that in mind, here is an example that shows how all of the operators work. Assume that the variable path has the value /home /billr/mem/long.file.name; then:
Expression Result
${path##/*/} long.file.name
${path#/*/} billr/mem/long.file.name
$path /home/billr/mem/long.file.name
${path%.*} /home/billr/mem/long.file
${path%%.*} /home/billr/mem/long
The two patterns used here are /*/, which matches anything between
two slashes, and .
*, which matches a dot followed by anything.
We will incorporate one of these operators into our next programming task.
Think of a C compiler as a pipeline of data processing components. C source code is input to the beginning of the pipeline, and object code comes out of the end; there are several steps in between. The shell script’s task, among many other things, is to control the flow of data through the components and to designate output files.
You need to write the part of the script that takes the name of the input C source file and creates from it the name of the output object code file. That is, you must take a filename ending in .c and create a filename that is similar except that it ends in .o.
The task at hand is to strip the .c off the filename and append .o. A single shell statement will do it:
objname=${filename%.c}.o
This tells the shell to look at the end of filename for .c. If there is a match, return $filename with the match deleted. So if filename had the value fred.c, the expression ${filename%.c} would return fred. The .o is appended to make the desired fred.o, which is stored in the variable objname.
If filename had an inappropriate value (without .c) such as fred.a, the above expression would evaluate to fred.a.o: since there was no match, nothing is deleted from the value of filename, and .o is appended anyway. And, if filename contained more than one dot-e.g., if it were the y.tab.c that is so infamous among compiler writers-the expression would still produce the desired y.tab.o. Notice that this would not be true if we used %% in the expression instead of %. The former operator uses the longest match instead of the shortest, so it would match .tab.o and evaluate to y.o rather than y.tab.o. So the single % is correct in this case.
A longest-match deletion would be preferable, however, in the following task.
Clearly the objective is to remove the directory prefix from the pathname. The following line will do it:
bannername=${pathname##*/}
This solution is similar to the first line in the examples shown before.
If pathname were just a filename, the pattern *
/ (anything
followed by a slash) would not match and the value of the expression
would be pathname untouched. If pathname were something like
fred/bob, the prefix fred/ would match the pattern and be deleted,
leaving just bob as the expression’s value. The same thing would
happen if pathname were something like /dave/pete/fred/bob:
since the ## deletes the longest match, it deletes the
entire /dave/pete/fred/.
If we used
#
*
/
instead of ##
*
/, the expression
would have the incorrect value dave/pete/fred/bob, because the
shortest instance of “anything followed by a slash” at the beginning
of the string is just a slash (/).
The construct
${variable
##
*
/} is actually equivalent
to the UNIX utility basename(1).
basename takes a pathname
as argument and returns the filename only; it is meant to be used
with the shell’s command substitution mechanism (see below). basename is
less efficient than
${variable
##/
*
} because it runs in its own separate process rather than
within the shell.
Another utility, dirname(1), does essentially
the opposite of basename: it returns the directory prefix only.
It is equivalent to the Korn shell expression
${variable
%/
*
}
and is less efficient for the same reason.
Length Operator
There are two remaining operators on variables.
One is
${#varname}, which
returns the length of the value of the variable as a character
string. (In Chapter 6 we will see how to treat this
and similar values as actual numbers so they can be used
in arithmetic expressions.) For example,
if filename has the value fred.c, then
${#filename} would have the value 6.
The other operator
(${#array
[
*
]}) has to do with array variables, which are also discussed
in Chapter 6.
Command Substitution
From the discussion so far, we’ve seen two ways of getting values into variables: by assignment statements and by the user supplying them as command-line arguments (positional parameters). There is another way: command substitution, which allows you to use the standard output of a command as if it were the value of a variable. You will soon see how powerful this feature is.
The syntax of command substitution is: [49]
$(UNIX command)
The command inside the parenthesis is run, and anything the command writes to standard output is returned as the value of the expression. These constructs can be nested, i.e., the UNIX command can contain command substitutions.
Here are some simple examples:
The value of $(pwd) is the current directory (same as the environment variable $PWD).
The value of $(ls) is the names of all files in the current directory, separated by NEWLINEs.
To find out detailed information about a command if you don’t know where its file resides, type ls -l $(whence -p command). The -p option forces whence to do a pathname lookup and not consider keywords, built-ins, etc.
To get the contents of a file into a variable, you can use varname =$(< filename). $(cat filename) will do the same thing, but the shell catches the former as a built-in shorthand and runs it more efficiently.
If you want to edit (with emacs) every chapter of your book on the Korn shell that has the phrase “command substitution,” assuming that your chapter files all begin with ch, you could type:
emacs $(grep -l 'command substitution' ch*)The -l option to grep prints only the names of files that contain matches.
Command substitution, like variable and tilde expansion, is done within double quotes. Therefore, our rule in Chapter 1 and Chapter 3, about using single quotes for strings unless they contain variables will now be extended: “When in doubt, use single quotes, unless the string contains variables or command substitutions, in which case use double quotes.”
You will undoubtedly think of many ways to use command substitution as you gain experience with the Korn shell. One that is a bit more complex than those mentioned previously relates to a customization task that we saw in Chapter 3: personalizing your prompt string.
Recall that you can personalize your prompt string by assigning a value to the variable PS1. If you are on a network of computers, and you use different machines from time to time, you may find it handy to have the name of the machine you’re on in your prompt string. Most newer versions of UNIX have the command hostname(1), which prints the network name of the machine you are on to standard output. (If you do not have this command, you may have a similar one like gethostname.) This command enables you to get the machine name into your prompt string by putting a line like this in your .profile or environment file:
PS1="$(hostname) \$ "
(The second dollar sign must be preceded by a backslash so that the shell will take it literally.) For example, if your machine had the name coltrane, then this statement would set your prompt string to "coltrane $ ”.
Command substitution helps us with the solution to the next programming task, which relates to the album database in Task 4-1.
The cut(1) utility is a natural for this task. cut is a data filter: it extracts columns from tabular data. [50] If you supply the numbers of columns you want to extract from the input, cut will print only those columns on the standard output. Columns can be character positions or-relevant in this example-fields that are separated by TAB characters or other delimiters.
Assume that the data table in our task is a file called albums and that it looks like this:
Coltrane, John|Giant Steps|Atlantic|1960|Ja Coltrane, John|Coltrane Jazz|Atlantic|1960|Ja Coltrane, John|My Favorite Things|Atlantic|1961|Ja Coltrane, John|Coltrane Plays the Blues|Atlantic|1961|Ja ...
Here is how we would use cut to extract the fourth (year) column:
cut -f4 -d\| albums
The -d argument is used to specify the character used as field delimiter (TAB is the default). The vertical bar must be backslash-escaped so that the shell doesn’t try to interpret it as a pipe.
From this line of code and the getfield routine, we can easily derive the solution to the task. Assume that the first argument to getfield is the name of the field the user wants to extract. Then the solution is:
fieldname=$1 cut -f$(getfield $fieldname) -d\| albums
If we called this script with the argument year, the output would be:
1960 1960 1961 1961 ...
Here’s another small task that makes use of cut.
The command who(1) tells you who is logged in (as well as which terminal they’re on and when they logged in). Its output looks like this:
billr console May 22 07:57 fred tty02 May 22 08:31 bob tty04 May 22 08:12
The fields are separated by spaces, not TABs. Since we need the first field, we can get away with using a space as the field separator in the cut command. (Otherwise we’d have to use the option to cut that uses character columns instead of fields.) To provide a space character as an argument on a command line, you can surround it by quotes:
$ who | cut -d' ' -f1
With the above who output, this command’s output would look like this:
billr fred bob
This leads directly to a solution to the task. Just type:
$ mail $(who | cut -d' ' -f1)
The command mail billr fred bob will run and then you can type your message.
Here is another task that shows how useful command pipelines can be in command substitution.
This task was inspired by the feature of the VAX/VMS operating system that lets you specify files by date with BEFORE and SINCE parameters. We’ll do this in a limited way now and add features in the next chapter.
Here is a function that allows you to list all files that were last modified on the date you give as argument. Once again, we choose a function for speed reasons. No pun is intended by the function’s name:
function lsd {
date=$1
ls -l | grep -i '^.\{41\}$date' | cut -c55-
}
This function depends on the column layout of the ls -l command. In particular, it depends on dates starting in column 42 and filenames starting in column 55. If this isn’t the case in your version of UNIX, you will need to adjust the column numbers. [51]
We use the grep search utility to match the date given
as argument (in the form Mon
DD, e.g., Jan 15 or
Oct 6, the latter having two spaces) to the output
of ls -l. This gives us a long listing of only those files
whose dates match the argument. The -i option to grep
allows you to use all lowercase letters in the month name, while
the rather fancy argument means, “Match any line that contains 41
characters followed by the function argument.”
For example, typing
lsd
'
jan 15
' causes grep to search for lines
that match any 41 characters followed by jan
15 (or Jan
15).
[52]
The output of grep is piped through our ubiquitous friend cut to retrieve the filenames only. The argument to cut tells it to extract characters in column 55 through the end of the line.
With command substitution, you can use this function with any command that accepts filename arguments. For example, if you want to print all files in your current directory that were last modified today, and today is January 15th, you could type:
$ lp $(lsd 'jan 15')
The output of lsd is on multiple lines (one for each filename), but LINEFEEDs are legal field separators for the lp command, because the environment variable IFS (see earlier in this chapter) contains LINEFEED by default.
Advanced Examples: pushd and popd
We will conclude this chapter with a couple of functions that you may find handy in your everyday UNIX use.
We will start by implementing a significant subset of their capabilities and finish the implementation in Chapter 6.
If you don’t know what a stack is, think of a spring-loaded dish receptacle in a cafeteria. When you place dishes on the receptacle, the spring compresses so that the top stays at roughly the same level. The dish most recently placed on the stack is the first to be taken when someone wants food; thus, the stack is known as a “last-in, first-out” or LIFO structure. [53] Putting something onto a stack is known in computer science parlance as pushing, and taking something off the top is called popping.
A stack is very handy for remembering directories, as we will see; it can “hold your place” up to an arbitrary number of times. The cd - form of the cd command does this, but only to one level. For example: if you are in firstdir and then you change to seconddir, you can type cd - to go back. But if you start out in firstdir, then change to seconddir, and then go to thirddir, you can use cd - only to go back to seconddir. If you type cd - again, you will be back in thirddir, because it is the previous directory. [54]
If you want the “nested” remember-and-change functionality that will take you back to firstdir, you need a stack of directories along with the pushd and popd commands. Here is how these work: [55]
The first time pushd dir is called, pushd cds to dir and pushes the current directory followed by dir onto the stack.
Subsequent calls to pushd cd to dir and push dir only onto the stack.
popd removes the top directory off the stack, revealing a new top. Then it cds to the new top directory.
For example, consider the series of events in Table 4.6. Assume that you have just logged in, and that you are in your home directory (/home/you).
We will implement a stack as an environment variable containing a list of directories separated by spaces.
| Command | Stack Contents | Result Directory |
| pushd fred | /home/you/fred /home/you | /home/you/fred |
| pushd /etc | /etc /home/you/fred /home/you | /etc |
| popd | /home/you/fred /home/you | /home/you/fred |
| popd | /home/you | /home/you |
| popd | <empty> | (error) |
Your directory stack should be initialized to the null string when you log in. To do this, put this in your .profile:
DIRSTACK="" export DIRSTACK
Do not put this in your environment file if you have one. The export statement guarantees that DIRSTACK is known to all subprocesses; you want to initialize it only once. If you put this code in an environment file, it will get reinitialized in every subshell, which you probably don’t want.
Next, we need to implement pushd and popd as functions. Here are our initial versions:
function pushd { # push current directory onto stack
dirname=$1
cd ${dirname:?"missing directory name."}
DIRSTACK="$dirname ${DIRSTACK:-$PWD}"
print "$DIRSTACK"
}
function popd { # pop directory off stack, cd to new top
DIRSTACK=${DIRSTACK#* }
cd ${DIRSTACK%% *}
print "$PWD"
}
Notice that there isn’t much code! Let’s go through the two functions and see how they work, starting with pushd. The first line merely saves the first argument in the variable dirname for readability reasons.
The second line’s main purpose is to change to the new directory.
We use the :? operator to handle the error when the argument is
missing: if the argument is given, then the expression
${dirname
:?"
missing directory name.
"} evaluates to
$
dirname, but if
it is not given, the shell will print the message
pushd: dirname: missing directory name and exit from the function.
The third line of the function pushes the new directory onto the
stack.
The expression
${DIRSTACK
:
-$PWD} evaluates to
$DIRSTACK if it is non-null
or
$PWD
(the current directory)
if it is null. The expression within double quotes, then,
consists of the argument given, followed by a single space, followed
by DIRSTACK or the current directory. The double quotes ensure
that all of this is packaged into a single string for assignment
back to DIRSTACK. Thus, this line of code handles the
special initial case (when the stack is empty) as well as the more
usual case (when it’s not empty).
The last line merely prints the contents of the stack, with the implication that the leftmost directory is both the current directory and at the top of the stack. (This is why we chose spaces to separate directories, rather than the more customary colons as in PATH and MAILPATH.)
The popd function makes yet another
use of the shell’s pattern-matching operators.
Its first line uses the # operator, which tries to delete
the shortest match of the pattern "*" (anything followed by a space)
from the value of DIRSTACK. The result is that the top directory
(and the space following it) is deleted from the stack.
The second line of popd uses the pattern-matching operator
%% to delete the longest match to the pattern “ *" (a
space followed by anything) from DIRSTACK. This extracts
the top directory as argument to cd, but doesn’t affect the
value of DIRSTACK because there is no assignment.
The final line just prints a confirmation message.
This code is deficient in three ways: first, it has no provision for errors. For example:
What if the user tries to push a directory that doesn’t exist or is invalid?
What if the user tries popd and the stack is empty?
Test your understanding of the code by figuring out how it would respond to these error conditions. The second deficiency is that it implements only some of the functionality of the C shell’s pushd and popd commands-albeit the most useful parts. In the next chapter, we will see how to overcome both of these deficiencies.
The third problem with the code is that it will not work if, for some reason, a directory name contains a space. The code will treat the space as a separator character. We’ll accept this deficiency for now. However, when you read about arrays in Chapter 6, Command-line Options and Typed Variables, think about how you might use them to rewrite this code and eliminate the problem.
[42] However, it is possible to define an alias for a keyword, e.g., alias aslongas=while. See Chapter 7 for more details.
[44] Unless the option nounset is turned on.
[45] However, see the section on typeset in Chapter 6 for a way of making variables local to functions.
[46] The colon (:) in each of these operators is actually optional.
If the colon is omitted, then change “exists and isn’t null”
to “exists” in each definition, i.e., the
operator tests for existence only.
[47] And, for that matter, the same as in grep, sed, ed, vi, etc.
[48] Don’t laugh-many UNIX compilers have shell scripts as front-ends.
[49]
Bourne and C shell users should note that the command substitution
syntax of those shells,
`
UNIX command
` (with backward
quotes, a.k.a. grave accents),
is also supported by the Korn
shell for backward compatibility reasons. However, Korn shell documentation
considers this syntax archaic. It is harder to read and less
conducive to nesting.
[50] Some older BSD-derived systems don’t have cut, but you can use awk instead. Whenever you see a command of the form:
cut -fN -dC filename
Use this instead:
awk -FC '{print $N}' filename
[51] For example, ls -l on SunOS 4.1.x has dates starting in column 33 and filenames starting in column 46.
[52] Some older BSD-derived versions of UNIX (without System V extensions) do not support the \{ N \} option. For this example, use 41 periods in a row instead of .\{41\}.
[53] Victims of the early-90s recession will also recognize this mechanism in the context of corporate layoff policies.
[54] Think of cd - as a synonym for cd $OLDPWD; see the previous chapter.
[55] More accurately, this is how the C shell does it, and yes, it is somewhat counterintuitive. A more intuitive way would be:
pushd dir: push dir (by itself) onto the stack.
popd: cd to the top directory, then pop it off.
Get Learning the Korn Shell now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

