How Do I Get Started?
By now you are chomping at the bit, eager to gallop into XML coding of your own. Let’s take a look at how to set up your own XML authoring and processing environment.
Authoring Documents
The most important item in your XML toolbox is the XML editor. This program lets you read and compose XML, and often comes with services to prevent mistakes and clarify the view of your document. There is a wide spectrum of quality and expense in editors, which makes choosing one that’s right for you a little tricky. In this section, I’ll take you on a tour of different kinds.
Even the lowliest plain-text editor is sufficient to work with XML. You can use Text- Edit on the Mac, NotePad or WordPad on Windows, or vi on Unix. The only limitation is whether it supports the character set used by the document. In most cases, it will be UTF-8. Some of these text editors support an XML “mode” which can highlight markup and assist in inserting tags. Some popular free editors include vim, elvis, and, my personal favorite, emacs.
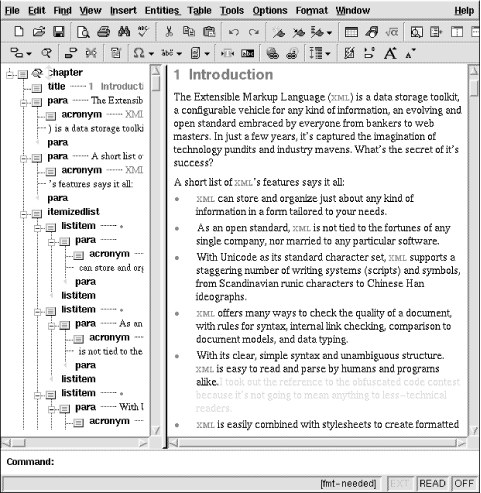
emacs is a powerful text editor with macros and scripted functions. Lennart Stafflin has written an XML plug-in for it called psgml, available at http://www.lysator.liu.se/~lenst/. It adds menus and commands for inserting tags and showing information about a DTD. It even comes with an XML parser that can detect structural mistakes while you’re editing a document. Using psgml and a feature called “font-lock,” you can set up xemacs, an X Window version of emacs, to highlight markup in color. Figure 1-5 is a snapshot of xemacs with an XML document open.
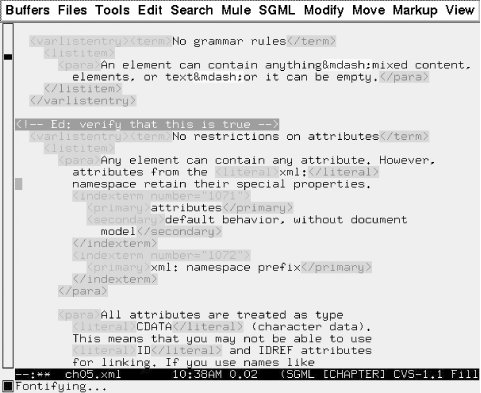
Morphon Technologies’ XMLEditor is a fine example of a graphical user interface. As you can see in Figure 1-6, the window sports several panes. On the left is an outline view of the book, in which you can quickly zoom in on a particular element, open it, collapse it, and move it around. On the right is a view of the text without markup. And below these panes is an attribute editing pane. The layout is easy to customize and easy to use. Note the formatting in the text view, achieved by applying a CSS stylesheet to the document. Morphon’s editor sells for $150 and you can download a 30-day demo at http://www.morphon.com. It’s written in Java, so it supports all computer platforms.
Arbortext’s Epic Editor is a very polished editor that can be integrated with digital asset management systems and high-end compositing systems. A screenshot is shown in Figure 1-7. Like Morphon’s editor, it uses CSS to format the text displayed. There are add-ons to extend functionality such as multiple author collaboration, importing from and exporting to Microsoft Word, formatting for print using a highly detailed stylesheet language called FOSI, and a powerful scripting language. The quality of output using FOSI is good enough for printing books, and you can view how it will look on screen. At around $700 a license, you pay more, but you get your money’s worth with Epic.
These are just a few of the many XML editors available. Table 1-1 lists a few more, along with their features and prices.
editor | tag highlighting | structure checking | validity checking | element menus | macros | unicode support | outline view | formatted display | cost |
Adobe FrameMaker 7.0 | yes | yes | yes | yes | yes | no | yes | yes | $800 Mac and Windows, $1300 Unix |
Arbortext Adept | yes | yes | yes | yes | yes | yes | yes | yes | $700 |
Corel XMetal | yes | yes | yes | yes | yes | yes | yes | yes | $500 |
emacs/psgml | yes | yes | yes | yes | yes | no | no | no | free |
Morphon XMLEditor | yes | yes | yes | yes | yes | no | yes | yes | $150 |
XML Spy | yes | yes | yes | yes | yes | $200 |
The features of structure and validity checking can be taken too far. All XML editors will warn you when there are structural errors or improper element placement (validity errors). A few, like Corel’s XMetal, prevent you from even temporarily making the document invalid. A user who is cutting and pasting sections around may temporarily have to break the validity rules. The editor rejects this, forcing the user to stop and figure out what is going wrong. It’s rather awkward to have your creativity interrupted that way. When choosing an editor, you’ll have to weigh the benefits of enforced structure against the interruptions in the creative process.
A high-quality XML authoring environment is configurable. If you have designed a document type, you should be able to customize the editor to enforce the structure, check validity, and present a selection of valid elements to choose from. You should be able to create macros to automate frequent editing steps and map keys on the keyboard to these macros. The interface should be ergonomic and convenient, providing keyboard shortcuts instead of many mouse clicks for every task. The authoring tool should let you define your own display properties, whether you prefer large type with colors or small type with tags displayed.
Configurability is sometimes at odds with another important feature: ease of maintenance. Having an editor that formats content nicely (for example, making titles large and bold) means that someone must write and maintain a stylesheet. Some editors have a reasonably good stylesheet-editing interface that lets you play around with element styles almost as easily as creating a template in a word processor. Structure enforcement can be another headache, since you may have to create a document type definition (DTD) from scratch. Like a stylesheet, the DTD tells the editor how to handle elements and whether they are allowed in various contexts. You may decide that the extra work is worth it if it saves error-checking and complaints from users down the line.
Editors often come with interfaces for specific types of markup. XML Spy includes many such extensions. It will allow you to create and position graphics, write XSLT stylesheets, create electronic forms, create tables in a special table builder, and create XML Schema. Tables, found in XML applications like HTML and DocBook, are complex structures, and believe me when I tell you they are not fun to work with in markup. To have a specialized table editor is a godsend.
Another nicety many editors provide is automatic conversion to terminal formats. FrameMaker, Epic, and others, can all generate PDF from XML. This high-quality formatting is difficult to achieve, however, and you will spend a lot of time tweaking difficult stylesheets to get just the appearance you’re looking for. There is a lot of variation among editors in how this is achieved. XML Spy uses XSLT, while Epic uses FOSI, and FrameMaker uses its own proprietary mapping tables. Generating HTML is generally a lot easier than PDF due to the lower standards for documents viewed on computer displays, so you will see more editors that can convert to HTML than to PDF.
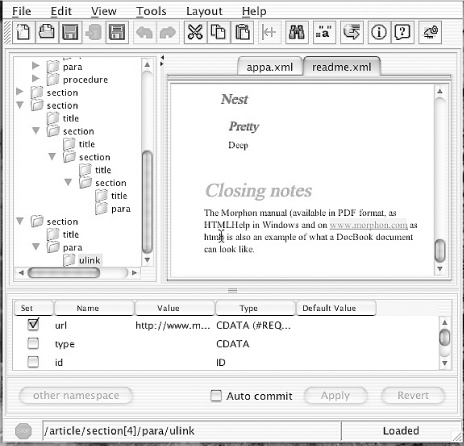
Database integration is another feature to consider. In an environment where data comes from many sources, such as multiple authors in collaboration, or records from databases, an editor that can communicate with a database can be a big deal. Databases can be used as a repository for documents, giving the ability to log changes, mark ownership, and store older versions. Databases are also used to store raw data, such as personnel records and inventory, and you may need to import that information into a document, such as a catalog. Editors like Epic and XML Spy support database input and collaboration. They can update documents in many places when data sources have changed, and they can branch document source text into multiple simultaneous versions. There are many exciting possibilities.
Which editor you use will depend a lot on your budget. You can spend nothing and get a very decent editor like emacs. It doesn’t have much of a graphical interface, and there is a learning curve, but it’s worked quite well for me. Or, for just a couple hundred dollars, you can get a nice editor with a GUI and parsing ability like Morphon XMLEdit. You probably wouldn’t need to spend more unless you’re in a corporate environment where the needs for high-quality formatting and collaboration justify the cost and maintenance requirements. Then you might buy into a suite of high-end editing systems like Epic or FrameMaker. With XML, there is no shortage of choices.
Viewing Documents
If the ultimate purpose of your XML is to give someone something to look at, then you may be interested in checking out some document viewers. You’ve already seen examples of editors displaying XML documents. You can display XML in web browsers too. Of course, all web browsers support XHTML. But Internet Explorer can handle any well-formed XML.
Since version 5.0 on Macintosh and 5.1 on Windows, Internet Explorer has had the ability to read and display XML. It has a built-in validating XML parser. If you specify a DTD in the document, IE will check it for validity. If there are errors, it will tell you so and highlight the affected areas. Viewing a document in IE looks like Figure 1-8.
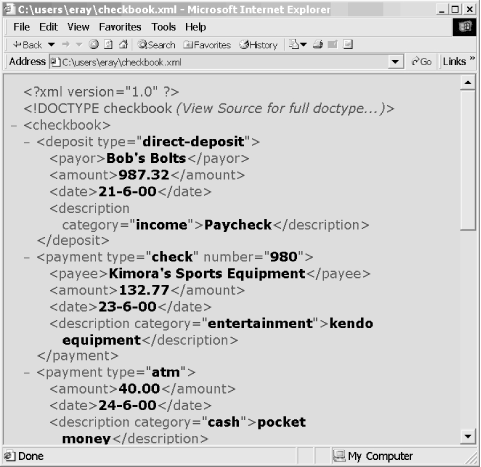
You may have noticed that the outline view in IE looks a lot like the outline view in Morphon XMLEdit. It works the same way. The whole document is the root of a tree, with branches for elements. Click on one of the minus icons and it will collapse the element, hiding all of its contents. The icon will become a plus symbol which you can click on to open up the element again. It’s a very useful tool for navigating a document quickly.
For displaying formatted documents on computer monitors, the best technology is CSS. CSS has a rich set of style attributes for setting colors, typefaces, rules, and margins. How much of the CSS standard is implemented, however, varies considerably across browsers. There are three separate recommendations, with the first being quite widely implemented, the second and more advanced less so, and the third rarely.
IE also contains an XSLT transformation engine. This gives yet another way to format an XML document. The XSLT script pointed to by your document transforms it into XHTML which IE already knows how to display. So you have two ways inside IE to generate decent presentation, making it an invaluable development tool. Since not all browsers implement CSS and XSLT for XML documents, it’s risky to serve XML documents and expect end user clients to format them correctly. This may change soon, as more browsers catch up to IE, but at the moment it’s safer to do the transformation on the server side and just serve HTML.
There are a bunch of browsers capable of working with XML in full or limited fashion. The following list describes a few of the more popular and interesting ones. Some technologies, like DOM and CSS, are broken up into three levels representing the relative sophistication of features. Most browsers completely implement the first level of CSS (CSS1), a few CSS2, and hardly any completely support the third tier of CSS.
- Amaya
Amaya is a project by the W3C to demonstrate technologies working together. It’s both a browser and an editor with built-in XML parsing and validating. It supports XHTML 1.1, CSS1 and parts of CSS2, MathML, and much of SVG. It is not able to format other kinds of XML, however.
- Konquerer
Available for flavors of Unix, this browser has lovely HTML formatting, but only limited support for XML. Its standards set includes HTML 4, most of CSS1 and part of CSS2, DOM1, DOM2, and part of DOM3.
- Microsoft Internet Explorer
Microsoft has tried very hard to play ball with the open standards community and it shows with this browser. XML parsing is excellent, along with strong support for DTDs, XSLT, CSS1, SVG (with plug-in), and DOM.
Strangely, Internet Explorer is split into two completely different code bases, with versions for Windows and Macintosh independent from each other. This has led to wacky situations such as the Mac version being for a time more advanced than its Windows cousin. The best versions (and perhaps last) available are 6.0 on Windows and 5.1 for Macintosh.
- Mozilla 1.4
Mozilla is an open source project to develop an excellent free browser that supports all the major standards. At Mozilla’s heart is a rendering engine, code-named Gecko, that parses markup and churns out formatted pages. It’s also the foundation for Netscape Navigator and IBM’s Web Browser for OS/2.
How is it for compliance? Mozilla fully supports XML using James Clark’s Expat parser, a free and high-quality tool. Other standards it implements include HTML 4, XHTML, CSS1, CSS2, SVG (with plug-in), XSLT, XLink, XPath, MathML (with plug-in), RDF, and Unicode. Some standards are only partially supported, such as XBase, XLink, and CSS3. For more information about XML in Mozilla, go to the Web at http://mozilla.org/newlayout/xml.
- Netscape Navigator
As of version 6, Navigator has been based on the Mozilla browsers internal workings. Therefore, it supports all the same standards.
- Opera
Opera is a fast and efficient browser whose lead designer was one of the codevelopers of CSS1. Standard support varies with platform, the Windows version being strongest. It implements XML parsing, CSS up to level 2, WAP and WML (media for wireless devices such as cell phones), and Unicode. An exciting new joint venture with IBM has formed recently to develop a multimodal browser that will handle speech as well as keyboard/mouse control. Opera’s weakest point is DOM, with only limited support.
- X-Smiles
This fascinating tool describes itself as “an open XML browser for exotic devices.” It supports some standards no other browsers have touched yet, including SMIL, XForms, X3D (three-dimensional graphics) and XML Signature. Using a Java-based plug-in, it can parse XML and do transformations with XSLT.
You can see browsers vary considerably in their support for standards. CSS implementation is particularly spotty, as shown in Eric Meyer’s Master Compatibility Chart at http://www.webreview.com/style/css1/charts/mastergrid.shtml. People aren’t taking the situation lying down, however. The Web Standards Project (http://www.webstandards.org/ monitors browser vendors and advocates greater compliance with standards.
Things get really interesting when you mix together different XML applications in one document. Example 1-9 is a document that combines three applications in one: XHTML which forms the shell and handles basic text processing, SVG for a vector graphic, and MathML to include an equation at the end. Figure 1-9 shows how it looks in the Amaya browser.
<?xml version="1.0"?>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>T E L E G R A M</title>
<!-- CSS stylesheet -->
<style>
body { background-color: tan; font-family: sans-serif; }
.telegram { border: thick solid wheat; }
.message { color: maroon; }
.head { color: blue; }
.name { font-weight: bold; color: green; }
.villain { font-weight: bold; color: red; }
</style>
</head>
<body>
<div class="telegram">
<h1>Telegram</h1>
<h2><span class="head">To:</span> Sarah Bellum</h2>
<h2><span class="head">From:</span> Colonel Timeslip</h2>
<h2><span class="head">Subj:</span> Robot-sitting instructions</h2>
<!-- SVG Picture of Zonky -->
<svg xmlns="http://www.w3.org/2000/svg" width="100" height="100">
<rect x="5" y="5" width="90" height="95" fill="none"
stroke="black" stroke-width="1"/>
<rect x="25" y="75" width="50" height="25" fill="gray"
stroke="black" stroke-width="2"/>
<rect x="30" y="70" width="40" height="30" fill="blue"
stroke="black" stroke-width="2"/>
<circle cx="50" cy="50" r="20" fill="blue" stroke="black"
stroke-width="2"/>
<circle cx="43" cy="50" r="5" fill="yellow" stroke="brown"/>
<circle cx="57" cy="50" r="5" fill="yellow" stroke="brown"/>
<text x="25%" y="25%" fill="purple" font-size="18pt"
font-weight="bold" font-style="italic">Zonky</text>
<text x="40" y="85" fill="white" font-family="sans-serif">Z-1</text>
</svg>
<!-- Message -->
<div class="message">
<p>Thanks for watching my robot pal
<span class="name">Zonky</span> while I'm away.
He needs to be recharged <em>twice a
day</em> and if he starts to get cranky,
give him a quart of oil. I'll be back soon,
after I've tracked down that evil
mastermind <span class="villain">Dr. Indigo
Riceway</span>.</p>
<p>P.S. Your homework for this week is to prove
Newton's theory of gravitation:
<!-- MathML Equation -->
<math xmlns="http://www.w3.org/1998/Math/MathML">
<mrow>
<mi>F</mi>
<mo>=</mo>
<mi>G</mi>
<mo>⁢</mo>
<mfrac>
<mrow>
<mi>M</mi>
<mo>⁢</mo>
<mi>m</mi>
</mrow>
<mrow>
<msup>
<mi>r</mi>
<mn>2</mn>
</msup>
</mrow>
</mfrac>
</mrow>
</math>
</p>
</div>
</div>
</body>
</html>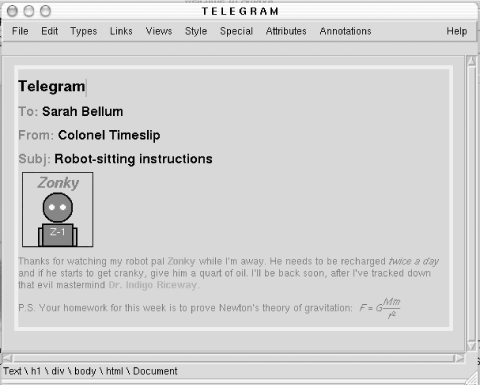
Parsing
If you’re going to be using XML from error-prone sources such as human authors, you will probably want to have a parser (preferably with good error reporting) in your XML toolkit. XML’s strict rules protect programs from unpredictable input that can cause them to crash or produce strange results. So you need to make sure that your data is clean and syntactically correct. Before I talk about these tools, let me first explain how parsing works. With a little theoretical grounding, you’ll be in good shape for understanding the need for parsers and knowing how to use them.
Every program that works with XML first has to parse it.
Parsing is a process where XML text is
collected and broken down into separate, manageable parts. As Figure 1-10 shows, there are
several levels. At the lowest level are characters in the input
stream. Certain characters are special, like <, >, and &. They tell the parser when it is
reading a tag, character data, or some other markup symbol.
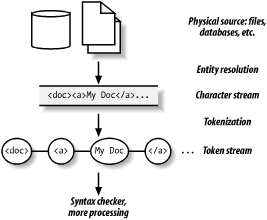
The next level of parsing occurs when the tags and symbols have been identified and now affect the internal checking mechanisms of the parser. The well-formedness rules now direct the parser in how to handle tokens. For example, an element start tag tells the parser to store the name of the element in a memory structure called a stack. When an element end tag comes along, it’s checked against the name in the stack. If they match, the element is popped out of the stack and parsing resumes. Otherwise, something must have gone wrong, and the parser needs to report the error.
One kind of symbol, called an entity reference , is a placeholder for content from another source. It may be a single character, or it could be a huge file. The parser looks up the source and pops it into the document for parsing. If there are entity references inside that new piece of content, they have to be resolved too. XML can come from many sources, including files, databases, program output, and places online.
Above this level is the structure checking, also called
validation . This is optional, and not all parsers can do it, but
it is a very useful capability. Say, for example, you are writing a
book in XML and you want to make sure that every section has a title.
If the DTD requires a title element at the beginning of the section
element, then the parser will expect to find it in the document. If a
<section> start tag is
followed by something other than a <title> start tag, the parser knows
something is wrong and will report it.
Parsers are often used in conjunction with some other processing, feeding a stream of tokens and representative data objects to be further manipulated. At the moment, however, we’re interested in parsing tools that check syntax in a document. Instead of passing on digested XML to another program, standalone parsers, also called well-formedness checkers, tell you when markup is good or bad, and usually give you hints about what went wrong. Let’s look at an example. In Example 1-10 I’ve written a test document with a bunch of syntax errors, guaranteed to annoy any XML parser.
<!-- This document is not well-formed and will invoke an error
condition from an XML parser. -->
<testdoc>
<e1>overlapping <e2> elements </e1> here </e2>
<e3>missing end tag
<e4>illegal character (<) </e4>
</testdoc>Any parser worth its salt should complain noisily about the errors in this example. You should expect to see a stream of error messages something like this:
$ xwf ex4_noparse.xml
ex4_noparse.xml:5: error: Opening and ending tag mismatch: e2 and e1
<e1>overlapping <e2> elements </e1> here </e2>
^
ex4_noparse.xml:5: error: Opening and ending tag mismatch: e1 and e2
<e1>overlapping <e2> elements </e1> here </e2>
^
ex4_noparse.xml:7: error: xmlParseStartTag: invalid element name
<e4>illegal character (<) </e4>
^
ex4_noparse.xml:8: error: Opening and ending tag mismatch: e3 and
testdoc
</testdoc>
^The tool helpfully points out all the places where it thinks the XML is broken and needs to be fixed, along with a short message indicating what’s wrong. “Ending tag mismatch,” for example, means that the end tag in question doesn’t match the most recently found element start tag, which is a violation. Many parsing tools will also validate if you supply a DTD for them to check against.
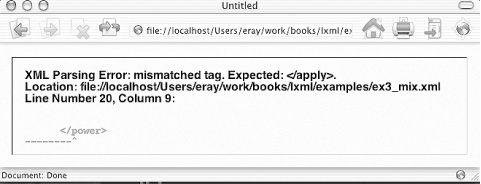
Where can you get a tool like this? The easiest way is to get an XML-aware web browser and open up an XML file with it. It will point out well-formedness errors for you (though often just one at a time) and can also validate against a DTD. Figure 1-11 shows the result of trying to load a badly formed XML document in Mozilla.
If you prefer a command-line tool, like I do, you can find one online. James Clark’s nsgmls at http://www.jclark.com/sp/, originally written for SGML, has served me well for many years.
If you are a developer, it is not hard to use XML parsers in
your code. Example 1-11
is a Perl script that uses the XML::LibXML module to create a handy
command-line validation tool.
#!/usr/bin/perl
use XML::LibXML; # import parser library
my $parser = new XML::LibXML; # create a parser object
$parser->validation(1); # turn on validation
$parser->load_ext_dtd(1); # read the external DTD
my $doc = $parser->parse_file( shift @ARGV ); # parse the file
if( $@ ) { # test for errors
print STDERR "PARSE ERRORS\n", $@;
} else {
print "The document '$file' is valid.\n";
}XML::LibXML is an interface
to a C library called libxml2, where the real parsing work is done.
There are XML libraries for Java, C, Python, and almost any other
programming language you can think of.
The parser in the this example goes beyond just well-formedness checking. It’s called a validating parser because it checks the grammar (types and order of elements) of the document to make sure it is a valid instance of a document type. For example, I could have it check a document to make sure it conforms to the DTD for XHTML 1.0. To do this, I need to place a line in the XML document that looks like this:
<!DOCTYPE html PUBLIC "..." "...">
This tells the parser that it needs to find a DTD, read its declarations, and then be mindful of element types and usage as it parses the document. The location of the DTD is specified in two ways. The first is the public identifier , inside the first set of quotes above. This is like saying, “go and read the Magna Carta,” which is an unambiguous command, but still requires you to hunt around for a copy of it. In this case, the parser has to look up the actual location in a concordance called a catalog . Your program has to tell the parser where to find a catalog. The other way to specify a DTD is to give a system identifier . This is a plain ordinary URL or filesystem path.
Transformation
The act of changing XML from one form to another is called transformation. This is a very powerful technique, employed in such processes as print formatting and conversion to HTML. Although most often used to add presentation to a document, it can be used to alter a document for special purposes. For example, you can use a transformation to generate a table of contents, construct an excerpt, or tabulate a column of numbers.
Transformation requires two things: the source document and a transformation stylesheet. The stylesheet is a recipe for how to “cook” the XML and arrive at a desired result. The oven in this metaphor is a transformation program that reads the stylesheet and input document and outputs a result document. Several languages have been developed for transformations. The Document Style Semantics and Specification Language (DSSSL) uses the programming language Lisp to describe transformations functionally. However, because DSSSL is rather complex and difficult to work with, a simpler language emerged: the very popular XSLT.
XSLT didn’t start off as a general-purpose transformation language. A few years ago, there was a project in the W3C, led by James Clark, to develop a high-quality style description language. The Extensible Style Language (XSL) quickly evolved into two components. The first, XSLT, concentrated on transforming any XML instance into a presentational format. The other component of XSL, XSL-FO (the FO stands for Formatting Objects), describes that format.
It soon became obvious that XSLT was useful in a wider context than just formatting documents. It can be used to turn an XML document into just about any form you can imagine. The language is generic, using rules and templates to describe what to output for various element types. Mr. Clark has expressed surprise that XSLT is being used in so many other applications, but it is testament to the excellent design of this standard that it has worked so well.
XSLT is an application of XML. This means you can easily write XSLT in any non-validating XML editor. You cannot validate XSLT because there is no DTD for it. An XSLT script contains many elements that you define yourself, and DTDs do not provide that kind of flexibility. However, you could use an XML Schema. I usually just check well-formedness and rely on the XSLT processor to tell me when it thinks the grammar is wrong.
An XSLT processor is a program that takes an XML document and an XSLT stylesheet as input and outputs a transformed document. Thanks to the enthusiasm for XSLT, there are many implementations available. Microsoft’s MSXML system is probably the most commonly used. Saxon (http://saxon.sourceforge.net/) is the most compliant and advanced. Others include Apache’s Xalan (http://xml.apache.org/xalan-j/index.html) and GNOME’s libxslt (http://www.xmlsoft.org/XSLT.html).
Besides using a programming library or command-line tool, you could also use a web browser for its built-in XSLT transformer. Simply add a line like this to the XML document to tell the browser to transform it:
<?xml-stylesheet type="text/xsl" href="/path/to/stylesheet"?>Replace /path/to/stylesheet with a
URL for the actual location of the XSLT stylesheet. This method is
frequently used to transform more
complex XML languages into simpler, presentational HTML.
Formatting for Print
Technology pundits have been predicting for a long time the coming of the paperless office. All data would be stored on computer, read on monitors and passed around through the network. But the truth is, people use paper now more than ever. For reading a long document, there is still no substitute for paper. Therefore, XML has had to embrace print.
Formatting for print begins with a transformation. Your XML document, which is marked up for describing structure and information, says nothing about the appearance. It needs to be converted into a presentational format that describes how things should look: typefaces, colors, positions on the page, and so on. There are many such formats, like TEX, PostScript and PDF. The trick is how to get from your XML to one of these formats.
You could, theoretically, write a transformation stylesheet to mutate your XML into PostScript, but this will give you nightmares and a head full of gray hairs. PostScript is UGLY. So are most other presentational formats like troff, RTF, and MIF. The fact that they are text (not binary) doesn’t make them much easier to understand. Any transformation stylesheet you write will require such intimate knowledge of byzantine rules and obscure syntactic conventions that it will quickly lead to madness. Believe me, I’ve done it.
Fortunately, somebody has had the brilliant idea to develop a formatting language based on plain English, using XML for its structural markup. XSL-FO, the cousin of XSLT, uses the same terminology as CSS to describe typefaces, inline styles, blocks, margins, and all the concepts you need to create a nice-looking page. You can look at an XSL-FO document and easily see the details for how it will be rendered. You can edit it directly and it won’t blow up in your face. Best of all, it works wonderfully with XSLT.
In the XSL process (see Figure 1-4), you give the XSLT transformer a stylesheet and an input document. It spits out an XSL-FO document that contains the data plus style information. A formatter takes the XSL-FO instance and renders that into a terminal format like PDF which you can print or view on a computer screen. Although you could edit the XSL-FO directly, it’s unlikely you would want to do that. Much better would be to edit the original XML source or the XSLT stylesheet and treat the XSL-FO as a temporary intermediate file. In fact, some implementations won’t even output the XSL-FO unless you request it.
My favorite XSL-FO formatter is called FOP (Formatting Object Processor) and it’s a project of the prodigious Apache XML Project (http://xml.apache.org/fop/). FOP is written in Java and comes bundled with a Java-based parser (Xerces) and a Java-based XSLT transformer (Xalan). The whole thing runs as a pipeline, very smooth and clean.
As an example, I wrote the XSLT script in Example 1-12. Unlike Example 1-6, which transforms
its source into HTML, this transforms into XSL-FO. Notice the use of
namespace qualifiers (the element name parts to
the left of colons) to distinguish between XSLT instructions and
XSL-FO style directives. The elements that start with xsl: are XSLT commands and elements that
start with fo: are formatting
object tags.
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:fo="http://www.w3.org/1999/XSL/Format">
<xsl:template match="/">
<fo:root>
<fo:layout-master-set>
<fo:simple-page-master master-name="only">
<fo:region-body region-name="xsl-region-body"
margin="1.0in"
padding="10pt"/>
<fo:region-before region-name="xsl-region-before"
extent="1.0in"
display-align="before"/>
<fo:region-after region-name="xsl-region-after"
extent="1.0in"
display-align="after"/>
</fo:simple-page-master>
</fo:layout-master-set>
<fo:page-sequence master-reference="only">
<fo:flow flow-name="xsl-region-body">
<xsl:apply-templates/>
</fo:flow>
</fo:page-sequence>
</fo:root>
</xsl:template>
<xsl:template match="telegram">
<fo:block font-size="18pt"
font-family="monospace"
line-height="24pt"
space-after.optimum="15pt"
background-color="blue"
color="white"
text-align="center"
padding-top="0pt">
<xsl:text>TELEGRAM</xsl:text>
</fo:block>
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="to">
<fo:block font-family="sans-serif" font-size="14pt">
<xsl:text>To: </xsl:text>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="from">
<fo:block font-family="sans-serif" font-size="14pt">
<xsl:text>From: </xsl:text>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="subject">
<fo:block font-family="sans-serif" font-size="14pt">
<xsl:text>Subj: </xsl:text>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="message">
<fo:block font-family="monospace"
font-size="10pt"
text-align="justify">
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="emphasis">
<fo:inline font-style="italic">
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
<xsl:template match="name">
<fo:inline color="green">
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
<xsl:template match="villain">
<fo:inline color="red">
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
</xsl:stylesheet>After running the telegram example through FOP with this stylesheet, Figure 1-12 is the result. FOP outputs PDF by default, but other formats will be available soon. There is work right now to add MIF and PostScript as formats.

Programming
When all else fails, you can write a program.
Parsers are the front line for any program that works with XML. There are several strategies available, depending on how you want to use the XML. The “push” technique, where data drives your program, is like a one-way tape drive. The parser reads the XML and calls on your program to handle each new item in the stream, hence the name stream processing. Though fast and efficient, stream processing is limited by the fact that the parser can’t stop and go back to retrieve information from earlier in the stream. If you need to access information out of order, you have to save it in memory.
The “pull” technique allows the program to access parts of the document in any order. The parser typically reads in a document and stores it in a data structure. The structure resembles a tree, with the outermost element as the root, and its contents branching out to the innermost text which are like leaves. Tree processing, as we call it, gives you a long-lasting representation of the document’s data and markup. It requires more memory and computation, but is often the most convenient way to accomplish a task.
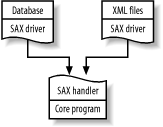
Developers have come up with standard programming interfaces for each of these techniques. The Simple API for XML (SAX) specifies how a parser should interact with a program for stream processing. This allows programs to use interchangeable modules, greatly enhancing flexibility. It’s possible to write drivers, programs that simulate parsers but get their input data from databases or non-XML formats, and know that any SAX-enabled program will be able to handle it. This is illustrated in Figure 1-13.
What SAX does for stream processing, the Document Object Model (DOM) does for tree processing. It describes a wide variety of accessor methods for objects containing parts of an XML document. With DOM, you can crawl over all the elements in a document in any order, rearrange them, add or subtract parts, and extract any data you want. Many web browsers have built-in support for DOM, allowing you to select and repackage information from a server using Java or JavaScript.
SOAP is a way for browsers to trade complex data packages with servers. Unlike HTML, which marks up data based on appearance, it describes its contents as data objects with types, names, and values, which is much more handy for computer processing.
Extracting data from deep inside a document is a common task for
developers. DOM and SAX are often too complex for a simple query like
this. XPath is a shorthand for locating a point inside an XML
document. It is used in XPointers and also in places like XSLT and
some DOM implementations to provide a quick way to move around a
document. XPointer extends XPath to create a way to specify the
location of a document anywhere on the Internet, extending
the notion of URLs you
know from the a element in
HTML.
Get Learning XML, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

